
LLM은 서로 싸우는 법을 배우고 기본 모델은 그룹 혁신을 가져올 수 있습니다

- 王林앞으로
- 2024-01-08 19:34:011239검색
진용의 무술소설에는 좌우격투라는 독특한 무술이 있습니다. 10년 넘게 복숭아꽃 섬의 동굴에서 열심히 수행한 주보통이 창안한 무술이었습니다. 자신의 오락을 위해 왼손과 오른손 사이에서 싸우는 것입니다. 이 아이디어는 무술을 연습하는 데 사용될 수 있을 뿐만 아니라 지난 몇 년 동안 인기를 끌었던 GAN(Generative Adversarial Network)과 같은 기계 학습 모델을 훈련하는 데에도 사용될 수 있습니다.
오늘날의 대형 모델(LLM) 시대에 연구자들은 왼쪽과 오른쪽 상호 작용의 미묘한 사용을 발견했습니다. 최근 캘리포니아 대학교 로스앤젤레스 캠퍼스의 Gu Quanquan 팀은 SPIN(Self-Play Fine-Tuning)이라는 새로운 방법을 제안했습니다. 이 방법은 추가적인 미세 조정 데이터를 사용하지 않고 셀프 게임만으로 LLM의 성능을 크게 향상시킬 수 있습니다. Gu Quanquan 교수는 "낚시하는 법을 가르치는 것보다 낚시하는 법을 가르치는 것이 더 좋습니다. 자체 게임 미세 조정(SPIN)을 통해 모든 대형 모델을 약한 상태에서 강한 상태로 향상시킬 수 있습니다!"라고 말했습니다. 이 연구는 소셜 네트워크에서도 많은 논의를 불러일으켰습니다. 예를 들어 펜실베니아 대학 와튼 스쿨의 Ethan Mollick 교수는 "AI가 인간이 만들어낸 양에 의해 제한되지 않을 것이라는 증거가 더 많습니다. 이 논문은 생성된 데이터를 AI 트레이닝에 활용하면 인간이 생성한 데이터만 사용하는 것보다 더 높은 품질의 결과를 얻을 수 있음을 다시 한 번 보여줍니다.” 는 이 방법에 큰 기대를 갖고 있으며 2024년 관련 방향으로의 발전을 기대하고 있습니다. 진행 상황은 큰 기대를 불러일으킵니다. Gu Quanquan 교수는 Machine Heart에 다음과 같이 말했습니다. "GPT-4 이상의 대형 모델을 훈련하고 싶다면 이것은 확실히 시도해 볼 가치가 있는 기술입니다."
논문 주소는 https://arxiv/pdf입니다. /2401.01335.pdf.
LLM의 주요 발전은 훈련 후 정렬 프로세스입니다. 이를 통해 모델이 요구 사항에 더 부합하게 작동할 수 있지만 이 프로세스는 비용이 많이 드는 사람이 레이블을 지정한 데이터에 의존하는 경우가 많습니다. 고전적인 정렬 방법에는 인간 시연을 기반으로 한 지도 미세 조정(SFT)과 인간 선호 피드백(RLHF)을 기반으로 한 강화 학습이 포함됩니다.

그리고 이러한 정렬 방법에는 모두 사람이 라벨을 붙인 대량의 데이터가 필요합니다. 따라서 정렬 프로세스를 간소화하기 위해 연구자들은 인간 데이터를 효과적으로 활용하는 미세 조정 방법을 개발하기를 희망합니다.
이 연구의 목표이기도 합니다. 미세 조정된 모델이 계속해서 더 강력해질 수 있도록 새로운 미세 조정 방법을 개발하는 것입니다. 이 미세 조정 프로세스에는 외부에서 사람이 라벨링한 데이터를 사용할 필요가 없습니다. 미세 조정 데이터 세트.
사실, 기계 학습 커뮤니티는 추가 교육 데이터를 사용하지 않고 약한 모델을 강력한 모델로 개선하는 방법에 대해 항상 고민해 왔습니다. 이 분야의 연구는 부스팅 알고리즘까지 추적할 수 있습니다. 자가 훈련 알고리즘이 추가적인 레이블 데이터 없이도 하이브리드 모델에서 약한 학습자를 강한 학습자로 변환할 수 있다는 연구 결과도 있습니다. 그러나 외부 지침 없이 LLM을 자동으로 개선하는 기능은 복잡하고 제대로 연구되지 않았습니다. 이는 다음과 같은 질문을 불러일으킵니다:
사람이 라벨을 붙인 추가 데이터 없이 LLM 자체 개선을 할 수 있습니까?
방법
기술적으로 세부적으로 이전 반복의 LLM을 pθt로 표시할 수 있습니다. 이는 사람이 라벨링한 SFT 데이터세트의 프롬프트 x에 대한 응답 y'를 생성합니다. 다음 목표는 pθt에 의해 생성된 응답 y'와 사람이 제공한 응답 y를 구별할 수 있는 새로운 LLM pθ{t+1}을 찾는 것입니다. 이 프로세스는 두 플레이어 간의 게임 프로세스로 볼 수 있습니다. 메인 플레이어는 새로운 LLM pθ{t+1}이며, 그 목표는 상대 플레이어 pθt의 반응을 인간이 생성한 반응과 구별하는 것입니다. 상대 플레이어는 이전 LLM pθt이며, 그의 임무는 인간이 라벨링한 SFT 데이터 세트에 최대한 가까운 응답을 생성하는 것입니다.
새로운 LLM pθ{t+1}은 이전 LLM pθt를 미세 조정하여 얻습니다. 학습 프로세스는 새로운 LLM pθ{t+1}가 pθt에 의해 생성된 응답 y'를 구별하는 좋은 능력을 갖도록 만드는 것입니다. 그리고 인간의 반응 y. 그리고 이 훈련을 통해 새로운 LLM pθ{t+1}는 주 플레이어로서 좋은 식별 능력을 달성할 수 있을 뿐만 아니라 새로운 LLM pθ{t+1}가 다음 반복에서 상대 플레이어로서 더 나은 정렬을 제공할 수 있습니다. SFT 데이터 세트의 응답. 다음 반복에서는 새로 얻은 LLM pθ{t+1}가 상대 플레이어의 응답 생성이 됩니다.
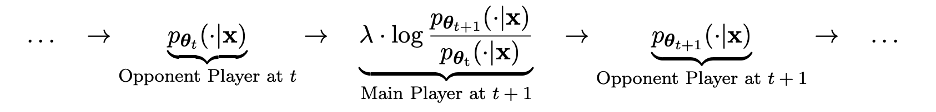

이 셀프 게임 프로세스의 목표는 LLM이 결국 pθ*=p_data로 수렴하여 존재할 수 있는 가장 강력한 LLM에 의해 생성된 응답이 더 이상 다르지 않도록 하는 것입니다. 이전 버전과 인간의 생성된 응답이 다릅니다.
흥미롭게도 이 새로운 방법은 최근 Rafailov et al.이 제안한 DPO(Direct Preference Optimization) 방법과 유사성을 보이지만, 새로운 방법의 명백한 차이점은 자체 게임 메커니즘을 사용한다는 것입니다. 따라서 이 새로운 방법은 추가적인 인간 선호도 데이터가 필요하지 않다는 중요한 이점을 가지고 있습니다.
또한 새로운 방법의 판별자(주 플레이어)와 생성자(상대)가 동일한 LLM이라는 점을 제외하면 이 새로운 방법과 GAN(Generative Adversarial Network) 사이의 유사성을 명확하게 볼 수 있습니다. 두 번의 인접한 반복 후에.
팀은 이 새로운 방법에 대한 이론적 증명도 수행했으며, 그 결과 LLM의 분포가 목표 데이터 분포, 즉 p_θ_t=p_data와 동일한 경우에만 이 방법이 수렴할 수 있음을 보여주었습니다.
Experiment
실험에서 팀은 Mistral-7B 미세 조정을 기반으로 하는 LLM 인스턴스 zephyr-7b-sft-full을 사용했습니다.
결과는 새로운 방법이 지속적인 반복에서 zephyr-7b-sft-full을 지속적으로 향상시킬 수 있음을 보여줍니다. 이에 비해 SFT 방법을 SFT 데이터 세트 Ultrachat200k에 대한 지속적인 교육에 사용하면 평가 점수가 성능에 도달합니다. 병목 현상이 발생했습니다.
더욱 흥미로운 점은 새로운 방법에 사용된 데이터세트가 Ultrachat200k 데이터세트의 50k 하위 집합에 불과하다는 것입니다!
새로운 방법인 SPIN에는 또 다른 성과가 있습니다. HuggingFace Open LLM 순위에서 기본 모델 zephyr-7b-sft-full의 평균 점수를 58.14에서 63.16으로 효과적으로 향상시킬 수 있으며 그중 GSM8k에서 더 나은 결과를 얻을 수 있습니다. 및 TruthfulQA 10% 이상의 놀라운 개선으로 MT-Bench에서는 5.94에서 6.78로 향상될 수도 있습니다.
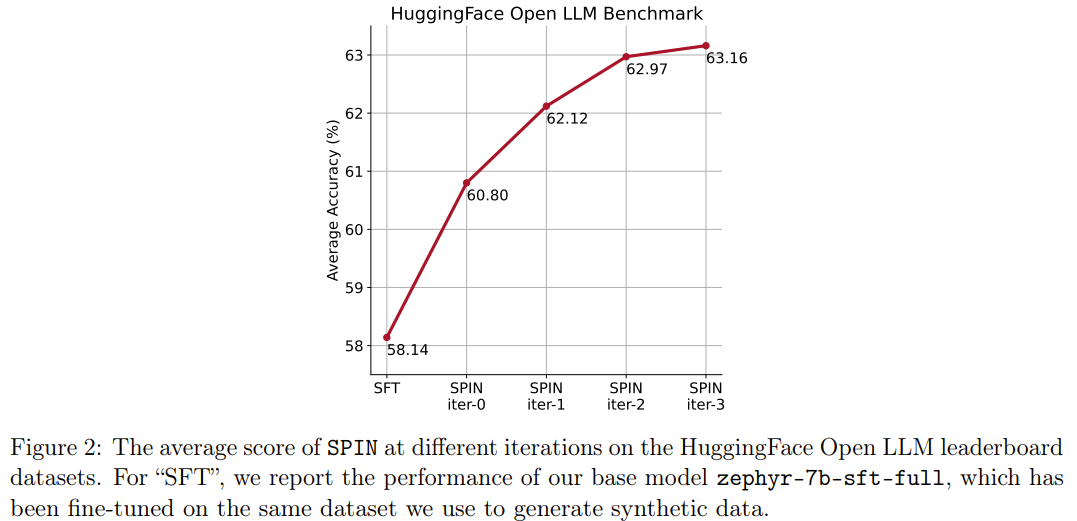
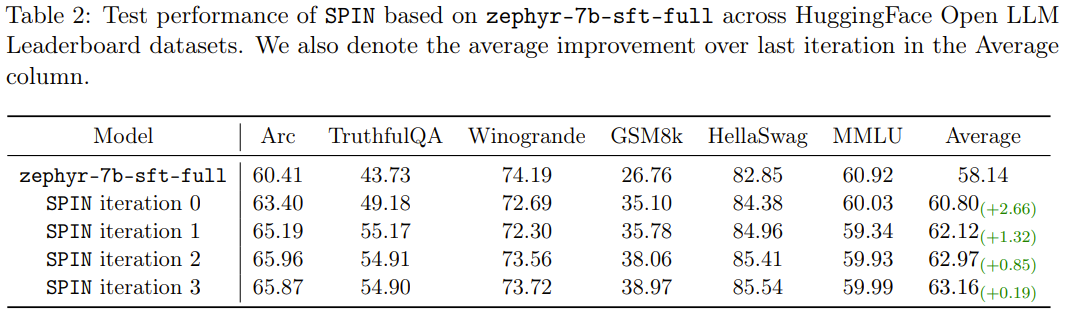
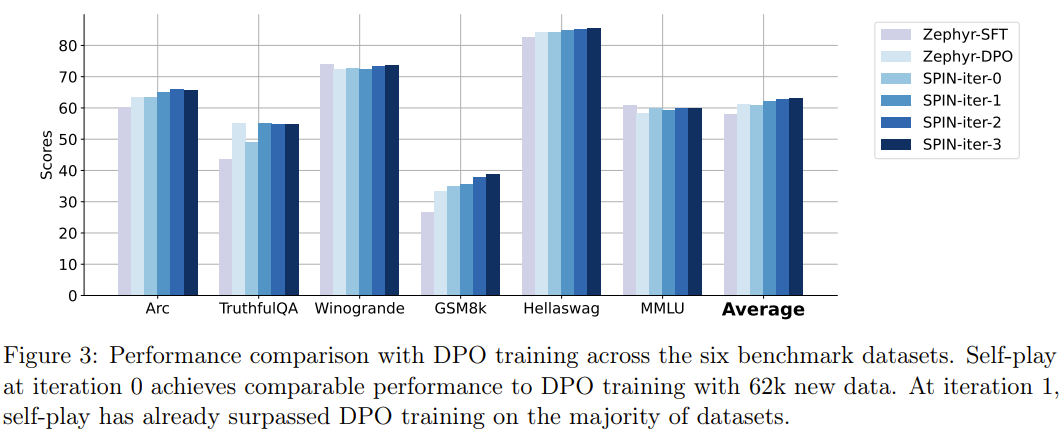
특히 Open LLM 리더보드에서 SPIN으로 미세 조정된 모델은 추가 62k 기본 설정 데이터 세트로 훈련된 모델과 비슷합니다.
결론
사람이 주석을 추가한 데이터를 최대한 활용함으로써 SPIN은 셀프 플레이를 통해 대형 모델을 약한 모델에서 강한 모델로 변경할 수 있습니다. RLHF(인간 선호 피드백)를 기반으로 하는 강화 학습과 비교하여 SPIN을 사용하면 LLM이 추가 인간 피드백이나 더 강력한 LLM 피드백 없이 자체 개선이 가능합니다. HuggingFace Open LLM 리더보드를 포함한 여러 벤치마크 데이터세트에 대한 실험에서 SPIN은 LLM의 성능을 상당히 안정적으로 향상시켰으며, 심지어 추가 AI 피드백으로 훈련된 모델보다 성능이 뛰어났습니다.
SPIN이 대형 모델의 진화와 개선에 도움을 주고, 궁극적으로는 인간 수준을 뛰어넘는 인공지능을 달성할 수 있을 것으로 기대합니다.
위 내용은 LLM은 서로 싸우는 법을 배우고 기본 모델은 그룹 혁신을 가져올 수 있습니다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!