모바일 단말기로 몰려드는 대형 모델의 물결이 점점 거세지고 있고, 마침내 누군가가 멀티모달 대형 모델을 모바일 단말기로 옮겨왔습니다. 최근 메이투안(Meituan), 저장대학교(Zhejiang University) 등에서는 LLM 기반 훈련, SFT, VLM의 전 과정을 포함해 모바일 단말기에 배치할 수 있는 다중 모드 대형 모델을 출시했습니다. 아마도 가까운 미래에는 누구나 자신만의 대형 모델을 편리하고 신속하며 저렴한 비용으로 소유할 수 있을 것입니다.
MobileVLM은 모바일 장치용으로 설계된 빠르고 강력하며 개방형 시각적 언어 도우미입니다. 처음부터 훈련된 1.4B 및 2.7B 매개변수 언어 모델, CLIP 방식으로 사전 훈련된 다중 모드 비전 모델, 프로젝션을 통한 효율적인 교차 모드 상호 작용을 포함하여 모바일 장치용 아키텍처 설계와 기술을 결합합니다. MobileVLM의 성능은 다양한 시각적 언어 벤치마크에서 대형 모델과 비슷합니다. 또한 Qualcomm Snapdragon 888 CPU 및 NVIDIA Jeston Orin GPU에서 가장 빠른 추론 속도를 보여줍니다. 
- 논문 주소: https://arxiv.org/pdf/2312.16886.pdf
- 코드 주소: https://github.com/Meituan-AutoML/MobileVLM
LMM(대규모 다중 모드 모델), 특히 VLM(시각 언어 모델) 제품군은 인식 및 추론 능력이 크게 향상되어 범용 보조 장치 구축을 위한 유망한 연구 방향이 되었습니다. 하지만 사전 훈련된 LLM(Large Language Model)과 시각적 모델의 표현을 어떻게 연결하고, 크로스 모달 특징을 추출하며, 시각적 질문 답변, 이미지 자막, 시각적 지식 추론, 대화 등의 작업을 완료하는 방법은 항상 문제였습니다. . 이 작업에서 GPT-4V와 Gemini의 뛰어난 성능은 여러 번 입증되었습니다. 그러나 이러한 독점 모델의 기술적 구현 세부 사항은 아직까지 잘 알려져 있지 않습니다. 동시에 연구계에서는 일련의 언어 조정 방법도 제안했습니다. 예를 들어, Flamingo는 시각적 토큰을 활용하여 게이트 교차 주의 레이어를 통해 고정된 언어 모델을 조정합니다. BLIP-2는 이러한 상호 작용이 불충분하다고 간주하고 고정된 시각적 인코더에서 가장 유용한 기능을 추출하여 LLM의 고정에 직접 공급하는 경량 쿼리 변환기(Q-Former라고 함)를 도입합니다. MiniGPT-4는 프로젝션 레이어를 통해 BLIP-2의 고정된 시각적 인코더와 고정된 언어 모델 Vicuna를 연결합니다. 또한 LLaVA는 간단한 훈련 가능한 매핑 네트워크를 적용하여 시각적 특징을 언어 모델에서 처리할 단어 임베딩과 동일한 차원을 가진 임베딩 토큰으로 변환합니다. 대규모 다중 모드 데이터의 다양성에 적응하기 위해 훈련 전략이 점차 변화하고 있다는 점은 주목할 가치가 있습니다. LLaVA는 LLM의 명령어 튜닝 패러다임을 다중 모드 시나리오에 복제하려는 첫 번째 시도일 수 있습니다. 다중 모드 명령어 추적 데이터를 생성하기 위해 LLaVA는 이미지의 설명 문장, 이미지의 경계 상자 좌표와 같은 텍스트 정보를 순수 언어 모델 GPT-4에 입력합니다. MiniGPT-4는 먼저 이미지 설명 문장의 포괄적인 데이터 세트에 대해 훈련을 받은 다음 [이미지-텍스트] 쌍의 교정 데이터 세트에 대해 미세 조정됩니다. InstructBLIP은 사전 훈련된 BLIP-2 모델을 기반으로 시각적 언어 명령 튜닝을 수행하고, Q-Former는 명령 튜닝 형식으로 구성된 다양한 데이터 세트에 대해 훈련됩니다. mPLUG-Owl은 2단계 학습 전략을 도입합니다. 먼저 시각적 부분을 사전 학습한 다음 LoRA를 사용하여 다양한 소스의 명령 데이터를 기반으로 대규모 언어 모델 LLaMA를 미세 조정합니다. 위에서 언급한 VLM의 발전에도 불구하고 제한된 컴퓨팅 리소스 하에서 크로스 모달 기능을 사용할 필요도 있습니다. Gemini는 다양한 다중 모드 벤치마크에서 sota를 능가하고 저메모리 장치를 위한 1.8B 및 3.25B 매개변수를 갖춘 모바일급 VLM을 도입했습니다. 그리고 Gemini는 증류 및 양자화와 같은 일반적인 압축 기술도 사용합니다. 본 문서의 목표는 시각적 인식 및 추론을 위해 공개 데이터 세트와 사용 가능한 기술을 사용하여 훈련되고 리소스가 제한된 플랫폼에 맞게 맞춤화된 최초의 개방형 모바일 등급 VLM을 구축하는 것입니다. 이 기사의 기여는 다음과 같습니다.
- 이 기사에서는 모바일 시나리오에 맞게 사용자 정의된 다중 모달 시각적 언어 모델의 전체 스택 변환인 MobileVLM을 제안합니다. 저자에 따르면 이는 처음부터 상세하고 재현 가능하며 강력한 성능을 제공하는 최초의 시각적 언어 모델입니다. 연구자들은 통제된 오픈 소스 데이터 세트를 통해 고성능 기본 언어 모델과 다중 모드 모델 세트를 구축했습니다.
- 이 문서에서는 시각적 인코더 설계에 대한 광범위한 절제 실험을 수행하고 다양한 교육 패러다임, 입력 해상도 및 모델 크기에 대한 VLM의 성능 민감도를 체계적으로 평가합니다.
- 이 기사에서는 추론 소비를 줄이면서 다중 모달 기능을 더 잘 정렬할 수 있는 시각적 기능과 텍스트 기능 간의 효율적인 매핑 네트워크를 설계합니다.
- 이 기사에서 설계된 모델은 Qualcomm의 모바일 CPU 및 65.5인치 프로세서에서 측정된 속도가 21.5토큰/초로 저전력 모바일 장치에서 효율적으로 실행될 수 있습니다.
- MobileVLM과 다수의 다중 모드 대형 모델은 벤치마크에서 동일한 성능을 발휘하여 많은 실제 작업에서 적용 가능성을 입증했습니다. 이 문서는 엣지 시나리오에 중점을 두고 있지만 MobileVLM은 클라우드의 강력한 GPU에서만 지원할 수 있는 많은 최첨단 VLM보다 성능이 뛰어납니다. LMoBilevlmo 전체 아키텍처 설계
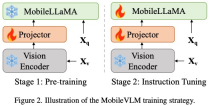
제한된 자원으로 한계 장비에 대한 효율적인 시각적 인식 및 추론을 달성한다는 주요 목표를 고려하여 연구원들은 Mobilevlm을 설계했습니다. 그림 1과 같이 전체 아키텍처 모델에는 세 가지 구성 요소가 포함됩니다. 1) 시각적 인코더, 2) 맞춤형 LLM 에지 장치(MobileLLaMA), 3) 시각적 공간과 텍스트 공간을 정렬하기 위한 효율적인 매핑 네트워크(논문에서는 "경량 다운샘플링 매핑", LDP라고 함)입니다.
이미지를 입력으로 사용하면 시각적 인코더 F_enc는 이미지 인식을 위해 이미지에서 시각적 임베딩 을 추출합니다. 여기서 N_v = HW/P^2는 이미지 패치 수를 나타내고 D_v는 시각적 임베딩의 숨겨진 레이어 크기를 나타냅니다. 이미지 토큰 처리의 효율성 문제를 완화하기 위해 연구원들은 시각적 특징 압축 및 시각적 텍스트 모달 정렬을 위한 경량 매핑 네트워크 P를 설계했습니다. f를 단어 임베딩 공간으로 변환하고 다음과 같이 후속 언어 모델에 적합한 입력 차원을 제공합니다.
이러한 방식으로 이미지 토큰과 텍스트 토큰을 얻습니다. 여기서 N_t는 텍스트 토큰 수, D_t는 단어 임베딩 공간의 크기를 나타냅니다. 현재 MLLM 설계 패러다임에서 LLM은 가장 많은 양의 계산 및 메모리 소비를 가지고 있습니다. 이러한 관점에서 이 기사에서는 속도 측면에서 상당한 이점을 갖고 자동 회귀 방법을 수행할 수 있는 일련의 추론 친화적인 LLM을 맞춤화했습니다. 다중 모드 입력 , 여기서 L은 출력 토큰의 길이를 나타냅니다. 이 과정은 로 표현할 수 있습니다. 원문의 5.1절의 실증적 분석에 따르면, 연구원은 사전 훈련된 CLIP ViT-L/14를 336×336 해상도로 사용했습니다. 시각적 인코더 F_enc . ViT(Visual Transformer)는 이미지를 균일한 크기의 이미지 블록으로 나누고 각 이미지 블록에 대해 선형 임베딩을 수행합니다. 이어서 위치 인코딩과 통합된 결과 벡터 시퀀스는 일반 변환 인코더에 공급됩니다. 일반적으로 분류에 사용되는 토큰은 후속 분류 작업을 위한 시퀀스에 추가됩니다. 언어 모델의 경우 이 기사에서는 LLaMA의 크기를 줄여 배포를 용이하게 합니다. 즉, 이 기사에서 제안하는 모델은 거의 모든 널리 사용되는 추론 프레임워크를 완벽하게 지원할 수 있습니다. 또한 연구원들은 적절한 모델 아키텍처를 선택하기 위해 에지 장치의 모델 대기 시간도 평가했습니다. NAS(Neural Architecture Search)는 좋은 선택이지만 현재 연구자들은 이를 현재 모델에 즉시 적용하지 않았습니다. 표 2는 본 논문의 아키텍처에 대한 세부 설정을 보여줍니다. 구체적으로 이 기사에서는 어휘 크기가 32000인 LLaMA2의 문장 조각 토크나이저를 사용하고 임베딩 레이어를 처음부터 훈련합니다. 이는 후속 증류를 촉진합니다. 제한된 리소스로 인해 사전 학습 단계의 모든 모델에서 사용되는 컨텍스트 길이는 2k입니다. 그러나 "위치 보간을 통해 대규모 언어 모델의 컨텍스트 창 확장"에서 설명한 것처럼 추론 중 컨텍스트 창을 8k까지 더 확장할 수 있습니다. 기타 구성요소의 세부 설정은 다음과 같습니다.
- 훈련을 안정화하려면 사전 정규화를 적용하세요. 구체적으로 본 논문에서는 레이어 정규화 대신 RMSNorm을 사용하고, MLP 확장 비율은 4 대신 8/3을 사용합니다.
- GELU 대신 SwiGLU 활성화 기능을 사용하세요.
비주얼 인코더와 언어 모델 간의 매핑 네트워크는 다중 모드 기능을 정렬하는 데 중요합니다. Q-Former와 MLP 프로젝션이라는 두 가지 기존 모드가 있습니다. Q-Former는 각 쿼리에 포함된 시각적 토큰의 수를 명시적으로 제어하여 가장 관련성이 높은 시각적 정보를 강제로 추출합니다. 그러나 이 방법은 필연적으로 토큰의 공간적 위치 정보를 잃어버리고 수렴 속도도 느리다. 또한 에지 장치에 대한 추론에는 효율적이지 않습니다. 대조적으로, MLP는 공간 정보를 보존하지만 배경과 같은 쓸모없는 토큰을 포함하는 경우가 많습니다. 패치 크기가 P인 이미지의 경우 N_v = HW/P^2 시각적 토큰을 LLM에 주입해야 하므로 전체 추론 속도가 크게 감소됩니다. ViT의 조건부 위치 코딩 알고리즘 CPVT에서 영감을 받아 연구원들은 컨볼루션을 사용하여 위치 정보를 향상시키고 시각적 인코더의 로컬 상호 작용을 장려합니다. 구체적으로 우리는 다양한 엣지 장치에서 효율적이고 잘 지원되는 딥 컨볼루션(PEG의 가장 간단한 형태)을 기반으로 하는 모바일 친화적인 작업을 조사했습니다. 공간 정보를 보존하고 계산 비용을 최소화하기 위해 이 기사에서는 스트라이드 2의 컨볼루션을 사용하여 시각적 토큰 수를 75% 줄입니다. 이 디자인은 전반적인 추론 속도를 크게 향상시킵니다. 그러나 실험 결과에 따르면 토큰 샘플 수를 줄이면 OCR과 같은 다운스트림 작업의 성능이 심각하게 저하되는 것으로 나타났습니다. 이러한 효과를 완화하기 위해 연구원들은 단일 PEG를 대체할 수 있는 보다 강력한 네트워크를 설계했습니다. LDP(Lightweight Downsampling Mapping)라고 하는 효율적인 매핑 네트워크의 세부 아키텍처가 그림 2에 나와 있습니다. 특히 이 매핑 네트워크에는 2천만 개 미만의 매개변수가 포함되어 있으며 시각적 인코더보다 약 81배 빠르게 실행됩니다.
이 문서에서는 훈련이 배치 크기의 영향을 받지 않도록 "배치 정규화" 대신 "레이어 정규화"를 사용합니다. 공식적으로 LDP(P로 표시됨)는 시각적 임베딩을 입력으로 사용하여 효율적으로 추출 및 정렬된 시각적 토큰을 출력합니다.
표 3에서 연구진은 자연어 벤치마크에서 검토되었습니다. 제안된 모델은 언어 이해와 상식 추론을 각각 목표로 하는 두 가지 벤치마크에서 광범위하게 평가되었습니다. 전자의 평가에서 이 기사에서는 언어 모델 평가 하네스를 사용합니다. 실험 결과에 따르면 MobileLLaMA 1.4B는 TinyLLaMA 1.1B, Galactica 1.3B, OPT 1.3B 및 Pythia 1.4B와 같은 최신 오픈 소스 모델과 동등한 수준입니다. MobileLLaMA 1.4B는 2T 레벨 토큰으로 훈련되었으며 MobileLLaMA 1.4B보다 두 배 빠른 TinyLLaMA 1.1B보다 성능이 뛰어나다는 점은 주목할 가치가 있습니다. 3B 수준에서 MobileLLaMA 2.7B는 표 5에 표시된 대로 INCITE 3B(V1) 및 OpenLLaMA 3B(V1)와 비슷한 성능을 보여줍니다. Snapdragon 888 CPU에서 MobileLLaMA 2.7B는 OpenLLaMA 3B보다 약 40% 더 빠릅니다.
이 문서에서는 GQA, ScienceQA, TextVQA, POPE 및 MME에서 LLaVA의 다중 모드 성능을 평가합니다. 또한 본 논문에서는 MMBench를 이용하여 종합적인 비교도 실시한다. 표 4에서 볼 수 있듯이 MobileVLM은 감소된 매개변수와 제한된 교육 데이터에도 불구하고 경쟁력 있는 성능을 달성합니다. 경우에 따라 해당 측정항목은 이전의 최첨단 다중 모드 시각적 언어 모델보다 성능이 뛰어납니다.
LoRA(낮은 순위 적응)는 더 적은 수의 훈련 가능한 매개변수를 사용하여 완전히 미세 조정된 LLM과 동일하거나 더 나은 성능을 달성할 수 있습니다. 본 논문에서는 다중 모드 성능을 검증하기 위해 이 관행에 대한 실증적 연구를 수행합니다. 특히 VLM 시각적 명령 조정 단계에서 이 문서에서는 LoRA 매트릭스를 제외한 모든 LLM 매개변수를 고정합니다. MobileLLaMA 1.4B 및 MobileLLaMA 2.7B에서 업데이트된 매개변수는 각각 전체 LLM의 8.87% 및 7.41%에 불과합니다. LoRA의 경우 이 기사에서는 lora_r을 128로, lora_α를 256으로 설정합니다. 결과는 표 4에 나와 있습니다. LoRA가 포함된 MobileVLM은 6개 벤치마크에서 전체 미세 조정과 비슷한 성능을 달성하는 것을 볼 수 있으며 이는 LoRA의 결과와 일치합니다. 연구원들은 Realme GT 휴대폰과 NVIDIA Jetson AGX Orin 플랫폼에서 MobileLLaMA 및 MobileVLM의 추론 대기 시간을 평가했습니다. 이 전화기는 Snapdragon 888 SoC와 8GB RAM으로 구동되어 26 TOPS의 컴퓨팅 성능을 제공합니다. Orin은 32GB 메모리와 함께 제공되며 놀라운 275 TOPS의 컴퓨팅 성능을 제공합니다. CUDA 버전 11.4를 사용하고 향상된 성능을 위해 최신 병렬 컴퓨팅 기술을 지원합니다. 표 7에서 연구원들은 다양한 규모와 다양한 수의 시각적 토큰에서 다중 모드 성능을 비교했습니다. 모든 실험에서는 CLIP ViT를 시각적 인코더로 사용했습니다.
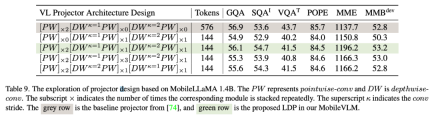
특징 상호 작용과 토큰 상호 작용 모두 유익하기 때문에 연구원들은 전자에 깊이 컨볼루션을 사용하고 후자에 포인트 컨볼루션을 사용했습니다. 표 9는 다양한 VL 매핑 네트워크의 성능을 보여줍니다. 표 9의 행 1은 LLaVA에서 사용되는 모듈로, 두 개의 선형 레이어를 통해서만 특징 공간을 변환합니다. 2행에서는 토큰 상호 작용을 위해 각 PW(점별) 앞에 DW(깊이별) 컨볼루션을 추가합니다. 이는 스트라이드가 2인 2배 다운샘플링을 사용합니다. 두 개의 프런트 엔드 PW 레이어를 추가하면 더 많은 기능 수준 상호 작용이 발생하므로 토큰 감소로 인한 성능 손실이 보상됩니다. 4행과 5행은 더 많은 매개변수를 추가해도 원하는 효과를 얻을 수 없음을 보여줍니다. 4행과 6행은 매핑 네트워크 끝에서 토큰을 다운샘플링하는 것이 긍정적인 효과가 있음을 보여줍니다.
시각적 토큰 수는 전체 다중 모드 모델의 추론 속도에 직접적인 영향을 미치므로 이 기사에서는 두 가지 설계 옵션을 비교합니다. 입력 해상도(RIR) 감소 ) 및 LDP(Lightweight Downsampling Projector)를 사용합니다. LLaMA에서 미세 조정된 Vicuna는 대형 멀티모달 모델에 널리 사용됩니다. 표 10은 두 가지 일반적인 SFT 패러다임인 Alpaca와 Vicuna를 비교합니다. 연구원들은 SQA, VQA, MME 및 MMBench의 점수가 모두 크게 향상되었음을 발견했습니다. 이는 Vicuna 대화 모드에서 ShareGPT의 데이터를 사용하여 대규모 언어 모델을 미세 조정하면 궁극적으로 최고의 성능을 얻을 수 있음을 보여줍니다. SFT의 프롬프트 형식을 다운스트림 작업 교육과 더 잘 통합하기 위해 이 문서에서는 MobileVLM에서 대화 모드를 제거하고 vicunav1이 가장 잘 수행된다는 것을 확인했습니다.
간단히 말하면 MobileVLM은 모바일 및 IoT 장치에 맞게 맞춤화된 효율적이고 강력한 모바일 시각적 언어 모델 세트입니다. 본 논문에서는 언어 모델과 시각적 매핑 네트워크를 재설정합니다. 연구진은 언어 모델 SFT(사전 훈련 및 지시 조정을 포함하는 2단계 훈련 전략) 및 LoRA 미세화와 같은 훈련 솔루션을 통해 적절한 시각적 백본 네트워크를 선택하고 효율적인 매핑 네트워크를 설계하며 모델 성능을 향상시키기 위해 광범위한 실험을 수행했습니다. 튜닝. 연구원들은 주류 VLM 벤치마크에서 MobileVLM의 성능을 엄격하게 평가했습니다. MobileVLM은 또한 일반적인 모바일 및 IoT 장치에서 전례 없는 속도를 보여줍니다. 연구원들은 MobileVLM이 모바일 장치나 자율주행차에 배포된 다중 모드 보조 장치는 물론 더 광범위한 인공 지능 로봇과 같은 광범위한 애플리케이션에 대한 새로운 가능성을 열어줄 것이라고 믿습니다. 위 내용은 Meituan, Zhejiang University 및 기타 업체가 협력하여 실시간으로 실행되고 Snapdragon 888 프로세서를 사용하는 전체 프로세스 모바일 다중 모드 대형 모델 MobileVLM을 만듭니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 기술 주변기기
기술 주변기기

 를 입력으로 사용하면 시각적 인코더 F_enc는 이미지 인식을 위해 이미지에서 시각적 임베딩
를 입력으로 사용하면 시각적 인코더 F_enc는 이미지 인식을 위해 이미지에서 시각적 임베딩  을 추출합니다. 여기서 N_v = HW/P^2는 이미지 패치 수를 나타내고 D_v는 시각적 임베딩의 숨겨진 레이어 크기를 나타냅니다. 이미지 토큰 처리의 효율성 문제를 완화하기 위해 연구원들은 시각적 특징 압축 및 시각적 텍스트 모달 정렬을 위한 경량 매핑 네트워크 P를 설계했습니다. f를 단어 임베딩 공간으로 변환하고 다음과 같이 후속 언어 모델에 적합한 입력 차원을 제공합니다.
을 추출합니다. 여기서 N_v = HW/P^2는 이미지 패치 수를 나타내고 D_v는 시각적 임베딩의 숨겨진 레이어 크기를 나타냅니다. 이미지 토큰 처리의 효율성 문제를 완화하기 위해 연구원들은 시각적 특징 압축 및 시각적 텍스트 모달 정렬을 위한 경량 매핑 네트워크 P를 설계했습니다. f를 단어 임베딩 공간으로 변환하고 다음과 같이 후속 언어 모델에 적합한 입력 차원을 제공합니다. 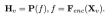
 과 텍스트 토큰
과 텍스트 토큰 을 얻습니다. 여기서 N_t는 텍스트 토큰 수, D_t는 단어 임베딩 공간의 크기를 나타냅니다. 현재 MLLM 설계 패러다임에서 LLM은 가장 많은 양의 계산 및 메모리 소비를 가지고 있습니다. 이러한 관점에서 이 기사에서는 속도 측면에서 상당한 이점을 갖고 자동 회귀 방법을 수행할 수 있는 일련의 추론 친화적인 LLM을 맞춤화했습니다. 다중 모드 입력
을 얻습니다. 여기서 N_t는 텍스트 토큰 수, D_t는 단어 임베딩 공간의 크기를 나타냅니다. 현재 MLLM 설계 패러다임에서 LLM은 가장 많은 양의 계산 및 메모리 소비를 가지고 있습니다. 이러한 관점에서 이 기사에서는 속도 측면에서 상당한 이점을 갖고 자동 회귀 방법을 수행할 수 있는 일련의 추론 친화적인 LLM을 맞춤화했습니다. 다중 모드 입력  , 여기서 L은 출력 토큰의 길이를 나타냅니다. 이 과정은
, 여기서 L은 출력 토큰의 길이를 나타냅니다. 이 과정은 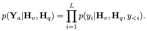 로 표현할 수 있습니다.
로 표현할 수 있습니다. 
 을 입력으로 사용하여 효율적으로 추출 및 정렬된 시각적 토큰
을 입력으로 사용하여 효율적으로 추출 및 정렬된 시각적 토큰 을 출력합니다.
을 출력합니다. 






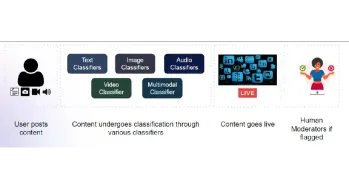 콘텐츠 중재를위한 멀티 모달 모델 구축Apr 12, 2025 am 10:51 AM
콘텐츠 중재를위한 멀티 모달 모델 구축Apr 12, 2025 am 10:51 AM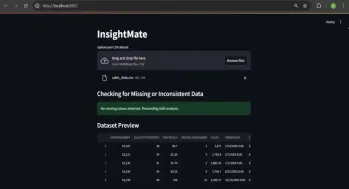 InsightMate를 사용하여 데이터 통찰력을 자동화하십시오Apr 12, 2025 am 10:44 AM
InsightMate를 사용하여 데이터 통찰력을 자동화하십시오Apr 12, 2025 am 10:44 AM 벡터 스트리밍 : 녹이있는 메모리 효율적인 인덱싱Apr 12, 2025 am 10:42 AM
벡터 스트리밍 : 녹이있는 메모리 효율적인 인덱싱Apr 12, 2025 am 10:42 AM REPLIT 에이전트 란 무엇입니까? | 입문 안내서 -Anuceics VidhyaApr 12, 2025 am 10:40 AM
REPLIT 에이전트 란 무엇입니까? | 입문 안내서 -Anuceics VidhyaApr 12, 2025 am 10:40 AM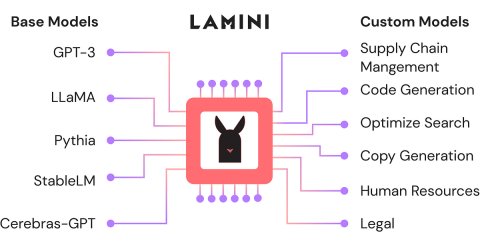 Lamini- 분석 Vidhya를 사용한 미세 조정 오픈 소스 LLMApr 12, 2025 am 10:20 AM
Lamini- 분석 Vidhya를 사용한 미세 조정 오픈 소스 LLMApr 12, 2025 am 10:20 AM Python의 Opencv 및 Roboflow를 사용한 성별 탐지 - 분석 VidhyaApr 12, 2025 am 10:19 AM
Python의 Opencv 및 Roboflow를 사용한 성별 탐지 - 분석 VidhyaApr 12, 2025 am 10:19 AM 광고 컨텐츠를 개인화하는 데 생성 AI의 역할은 무엇입니까?Apr 12, 2025 am 10:18 AM
광고 컨텐츠를 개인화하는 데 생성 AI의 역할은 무엇입니까?Apr 12, 2025 am 10:18 AM Openai ' s O1- 프리뷰 vs o1-mini : Agi 로의 한 걸음Apr 12, 2025 am 10:04 AM
Openai ' s O1- 프리뷰 vs o1-mini : Agi 로의 한 걸음Apr 12, 2025 am 10:04 AM













