
비디오 타이밍 포지셔닝에서 Tsinghua University가 개발한 LLM4VG 벤치마크의 성능을 평가합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-01-04 22:38:141273검색

12월 29일자 대규모 언어 모델(LLM)의 범위가 단순한 자연어 처리에서 텍스트, 오디오, 비디오 등 다중 모드 분야로 확장되었습니다. 그리고 그 핵심 중 하나가 비디오 타이밍 포지셔닝입니다. (비디오 접지, VG).
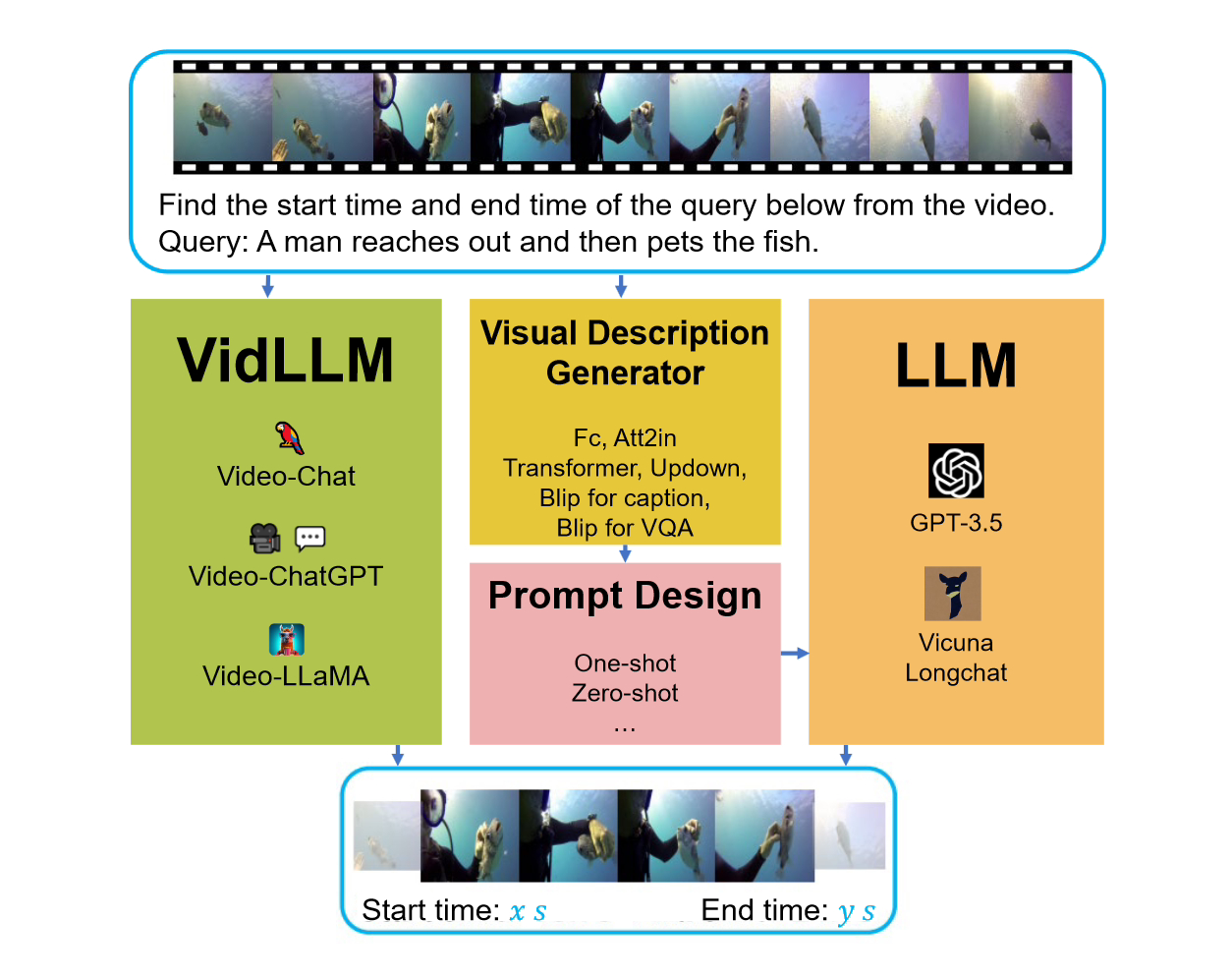
VG 작업의 목표는 주어진 쿼리를 기반으로 대상 비디오 세그먼트의 시작 및 종료 시간을 찾는 것입니다. 이 작업의 핵심 과제는 시간 경계를 정확하게 결정하는 것입니다.
칭화대학교 연구팀은 최근 VG 작업에서 LLM의 성능을 평가하기 위해 특별히 설계된 "LLM4VG" 벤치마크를 출시했습니다.
이 벤치마크를 고려할 때 고려된 두 가지 주요 전략이 있습니다. 첫 번째 전략은 텍스트 비디오 데이터 세트(VidLLM)에서 직접 비디오 언어 모델(LLM)을 교육하는 것입니다. 이 방법은 모델의 성능을 향상시키기 위해 대규모 비디오 데이터 세트를 학습하여 비디오와 언어 간의 연관성을 학습합니다. 두 번째 전략은 기존 언어 모델(LLM)을 사전 훈련된 비전 모델과 결합하는 것입니다. 이 방법은 비디오의 시각적 특성을 결합한 사전 훈련된 시각적 모델을 기반으로 합니다. 한 전략에서 VidLLM 모델은 비디오 콘텐츠와 VG 작업 지침을 직접 처리하고 훈련 출력을 기반으로 텍스트-비디오 관계를 예측합니다. 관계.
두 번째 전략은 더 복잡하며 LLM(언어 및 비전 모델) 및 시각적 설명 모델을 사용합니다. 이러한 모델은 VG(비디오 게임) 작업 지침과 결합된 비디오 콘텐츠에 대한 텍스트 설명을 생성할 수 있으며 이러한 설명은 신중하게 설계된 프롬프트를 통해 구현됩니다. 
그리고 두 번째 전략은 VidLLM보다 더 나은 미래 연구의 유망한 방향을 제시합니다. 이 전략은 주로 시각적 모델과 큐 단어 디자인의 한계로 인해 제한되므로 상세하고 정확한 비디오 설명을 생성할 수 있으므로 보다 세련된 그래픽 모델은 LLM의 VG 성능을 크게 향상시킬 수 있습니다.

요약하자면, 이 연구는 LLM을 VG 작업에 적용하는 방법에 대한 획기적인 평가를 제공하며, 모델 훈련 및 큐 디자인에서 보다 정교한 방법의 필요성을 강조합니다.
논문의 참조 주소는 이 사이트에 첨부되어 있습니다: 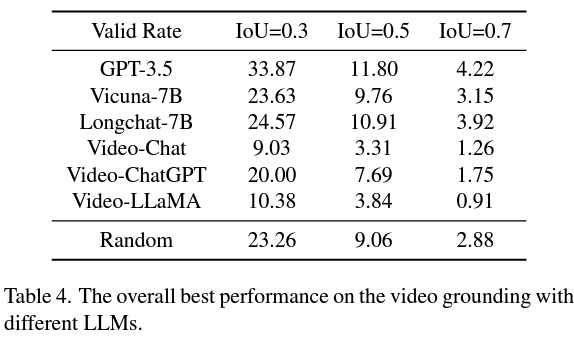
위 내용은 비디오 타이밍 포지셔닝에서 Tsinghua University가 개발한 LLM4VG 벤치마크의 성능을 평가합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!