Test-Time Adaptation의 목적은 추론 단계에서 소스 도메인 모델을 테스트 데이터에 적응시키는 것이며, 알려지지 않은 이미지 손상 필드에 적응하는 데 탁월한 결과를 얻었습니다. 그러나 현재의 많은 방법에는 실제 시나리오의 테스트 데이터 흐름에 대한 고려가 부족합니다. 예:
- 테스트 데이터 흐름은 시간에 따라 변하는 분포여야 합니다(기존 도메인 적응의 고정 분포가 아님).
- 테스트 데이터 스트림에 (완전히 독립적이고 동일하게 분산된 샘플링이 아닌) 로컬 클래스 상관 관계가 있을 수 있습니다.
- 테스트 데이터 스트림은 여전히 오랫동안 글로벌 클래스 불균형을 보여줍니다
최근 , South China University of Technology, A*STAR 및 CUHK-Shenzhen 팀은 이러한 실제 시나리오에서 데이터 스트림을 테스트하면 기존 방법에 큰 어려움을 초래할 것이라는 광범위한 실험을 통해 입증했습니다. 연구팀은 최첨단 방법의 실패가 먼저 불균형한 테스트 데이터를 기반으로 정규화 계층을 무분별하게 조정함으로써 발생한다고 믿고 있습니다. 이를 위해 연구팀은 추론 단계에서 기존 배치 정규화 계층을 대체할 혁신적인 Balanced BatchNorm 계층을 제안했습니다. 동시에 그들은 알려지지 않은 테스트 데이터 스트림에서 학습하기 위해 자체 훈련(ST)에만 의존하면 과도한 적응(의사 레이블 카테고리 불균형, 대상 도메인이 고정 도메인이 아님)으로 쉽게 이어질 수 있음을 발견했습니다. 변화하는 도메인에서의 성능. 따라서 팀에서는
고정 손실(Anchored Loss)을 통해 모델 업데이트를 정규화하여 지속적인 도메인 이전에서 자체 학습을 개선하고 모델의 견고성을 크게 향상시키는 데 도움을 줄 것을 권장합니다. 결국 모델 TRIBE는 4개의 데이터 세트와 다양한 실제 테스트 데이터 스트림 설정에서 안정적으로 최첨단 성능을 달성했으며 기존의 고급 방법을 크게 능가했습니다. 연구 논문이 AAAI 2024에 승인되었습니다. 
논문 링크: https://arxiv.org/abs/2309.14949
코드 링크: https://github.com/Gorilla-Lab-SCUT/TRIBE
Depth 신경망의 성공은 훈련된 모델을 테스트 도메인의 i.i.d 가정으로 일반화하는 데 달려 있습니다. 그러나 실제 응용에서는 다양한 조명 조건이나 악천후로 인한 시각적 손상과 같은 분포 외 테스트 데이터의 견고성이 문제가 됩니다. 최근 연구에 따르면 이러한 데이터 손실은 사전 훈련된 모델의 성능에 심각한 영향을 미칠 수 있습니다. 중요한 것은 테스트 데이터의 손상(분포)을 알 수 없는 경우가 많으며 배포 전에는 예측할 수 없는 경우도 있다는 것입니다.
따라서 추론 단계에서 테스트 데이터 분포에 맞게 사전 훈련된 모델을 조정하는 것은 TTA(테스트 시간 도메인 적응)라는 귀중한 새로운 주제입니다. 이전에는 TTA가 주로 분포 정렬(TTAC++, TTT++), 자가 지도 학습(AdaContrast) 및 자가 학습(Conjugate PL)을 통해 구현되었으며, 이를 통해 다양한 시각적 손상 테스트 데이터가 크게 향상되었습니다.
기존 TTA(테스트 시간 도메인 적응) 방법은 일반적으로 안정적인 클래스 분포, 샘플이 독립적이고 동일하게 분산된 샘플링 및 고정 도메인 오프셋을 따르는 엄격한 테스트 데이터 가정을 기반으로 합니다. 이러한 가정은 많은 연구자들이 CoTTA, NOTE, SAR 및 RoTTA와 같은 실제 테스트 데이터 흐름을 탐색하도록 영감을 주었습니다.
최근 SAR(ICLR 2023) 및 RoTTA(CVPR 2023)와 같은 실제 TTA 연구는 주로 지역 계층 불균형과 TTA로의 지속적인 영역 전환으로 인한 문제에 중점을 둡니다. 로컬 클래스 불균형은 일반적으로 테스트 데이터가 독립적으로 동일하게 분포되어 샘플링되지 않는다는 사실로 인해 발생합니다. 직접적인 무분별한 도메인 적응은 편향된 분포 추정으로 이어집니다.
최근 연구에서는 이 문제를 해결하기 위해 지수 업데이트 배치 정규화 통계(RoTTA) 또는 인스턴스 수준 차별적 업데이트 배치 정규화 통계(NOTE)를 제안했습니다. 연구 목표는 테스트 데이터의 전체 분포가 심각하게 불균형할 수 있고 클래스 분포도 시간이 지남에 따라 변경될 수 있다는 점을 고려하여 로컬 클래스 불균형 문제를 극복하는 것입니다. 보다 어려운 시나리오의 다이어그램은 아래 그림 1에서 볼 수 있습니다.
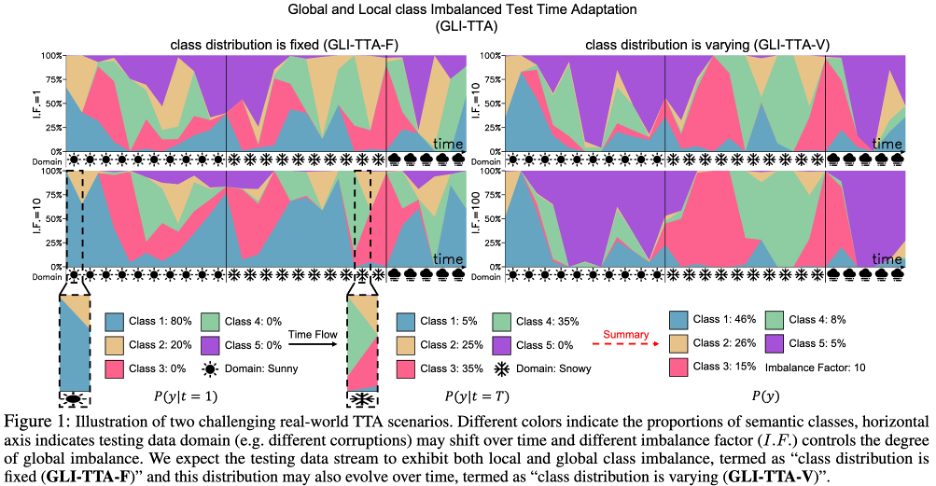 추론 단계 이전에는 테스트 데이터 내 클래스 출현도를 알 수 없고, 블라인드 테스트 시간 조정을 통해 모델이 다수 클래스 쪽으로 편향될 수 있으므로 기존 TTA 방법은 효과적이지 않습니다. 경험적 관찰에 따르면 이 문제는 정규화 계층(BN, PL, TENT, CoTTA 등) 업데이트를 위한 전역 통계를 추정하기 위해 현재 데이터 배치에 의존하는 방법에서 특히 두드러집니다. 이는 주로 다음과 같은 이유로 인해 발생합니다. 1. 현재 데이터 배치는 로컬 클래스 불균형의 영향을 받아 편향된 전체 분포 추정이 발생합니다. 2. 단일 전역 분포가 없으면 전역 분포가 쉽게 다수 클래스로 편향되어 내부 공변량 이동이 발생할 수 있습니다. 편향된 배치 정규화(BN)를 방지하기 위해 팀에서는 각 개별 범주의 분포를 모델링하고 클래스 분포에서 전역 분포를 추출하는 균형 잡힌 배치 정규화 계층(Balanced Batch Normalization Layer)을 제안했습니다. 균형 배치 정규화 계층을 사용하면 로컬 및 전역 클래스 불균형 테스트 데이터 스트림에서 클래스 균형 분포 추정치를 얻을 수 있습니다.
추론 단계 이전에는 테스트 데이터 내 클래스 출현도를 알 수 없고, 블라인드 테스트 시간 조정을 통해 모델이 다수 클래스 쪽으로 편향될 수 있으므로 기존 TTA 방법은 효과적이지 않습니다. 경험적 관찰에 따르면 이 문제는 정규화 계층(BN, PL, TENT, CoTTA 등) 업데이트를 위한 전역 통계를 추정하기 위해 현재 데이터 배치에 의존하는 방법에서 특히 두드러집니다. 이는 주로 다음과 같은 이유로 인해 발생합니다. 1. 현재 데이터 배치는 로컬 클래스 불균형의 영향을 받아 편향된 전체 분포 추정이 발생합니다. 2. 단일 전역 분포가 없으면 전역 분포가 쉽게 다수 클래스로 편향되어 내부 공변량 이동이 발생할 수 있습니다. 편향된 배치 정규화(BN)를 방지하기 위해 팀에서는 각 개별 범주의 분포를 모델링하고 클래스 분포에서 전역 분포를 추출하는 균형 잡힌 배치 정규화 계층(Balanced Batch Normalization Layer)을 제안했습니다. 균형 배치 정규화 계층을 사용하면 로컬 및 전역 클래스 불균형 테스트 데이터 스트림에서 클래스 균형 분포 추정치를 얻을 수 있습니다.
조명/날씨 조건의 점진적인 변화와 같이 시간이 지남에 따라 실제 테스트 데이터에서 도메인 이동이 자주 발생합니다. 이는 도메인 A에 대한 과적합으로 인해 도메인 A에서 도메인 B로 전환할 때 TTA 모델이 일관성이 없게 될 수 있는 기존 TTA 방법에 또 다른 과제를 안겨줍니다.
특정 단기 도메인에 대한 과잉 적응을 완화하기 위해 CoTTA는 매개변수를 무작위로 복원하고, EATA는 피셔 정보를 사용하여 매개변수를 정규화합니다. 그럼에도 불구하고 이러한 방법은 여전히 테스트 데이터 분야에서 새로운 과제를 명시적으로 해결하지 못합니다.
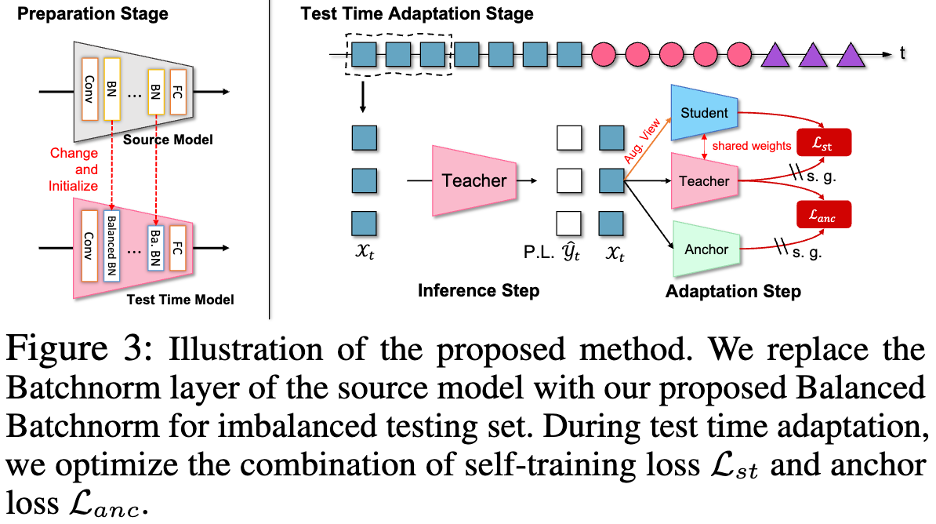
이 기사에서는 2개 분기 자체 학습 아키텍처를 기반으로 3네트워크 자체 학습 모델(Tri-Net Self-Training)을 형성하기 위한 앵커 네트워크(Anchor Network)를 소개합니다. 앵커 네트워크는 동결된 소스 모델이지만 테스트 샘플을 통해 배치 정규화 계층의 매개변수 대신 통계 튜닝을 허용합니다. 그리고 앵커 네트워크의 출력을 사용하여 교사 모델의 출력을 정규화하여 네트워크가 로컬 분포에 과도하게 적응하는 것을 방지하는 앵커링 손실이 제안되었습니다.
최종 모델은 3-net self-training 모델과 균형 배치 정규화 계층(TRI-net self-training with BalanceEd Normalization, TRIBE)을 결합하여 더 넓은 범위의 조정 가능한 학습률에서 일관되게 우수한 성능을 보여줍니다. 4개의 데이터 세트와 여러 실제 데이터 스트림에서 상당한 성능 향상을 보여주며 고유한 안정성과 견고성을 보여줍니다.
TTA 프로토콜 in the real world
저자는 현실 세계의 로컬 클래스 불균형과 글로벌 클래스 불균형으로 데이터 흐름을 테스트하기 위해 수학적 확률 모델을 채택했으며, Domain 시간에 따른 분포를 모델링했습니다. 아래 그림 2와 같습니다. 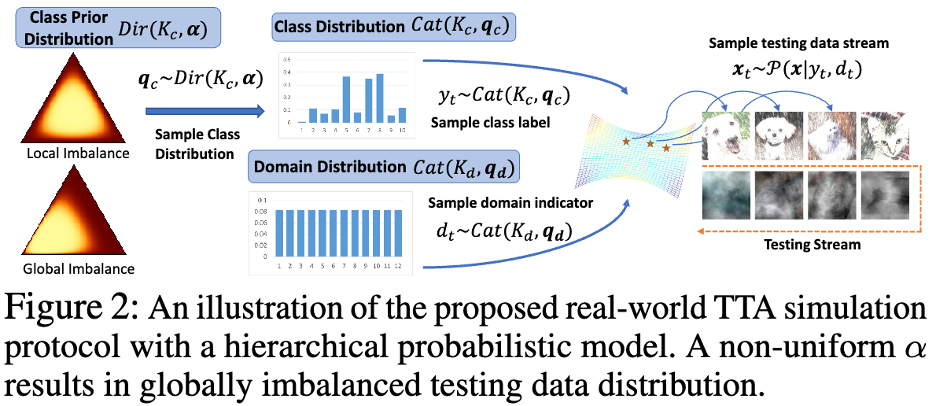
균형 배치 정규화
BN 통계에 대한 불균형 테스트 데이터에 의해 생성된 추정된 편향을 수정하기 위해 저자는 각 BN 통계에 대한 균형 배치 정규화 레이어를 제안합니다. 의미 클래스는 한 쌍의 통계를 유지합니다. 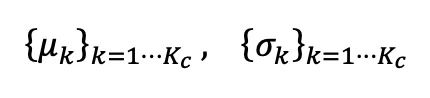 범주 통계를 업데이트하기 위해 저자는 아래와 같이 의사 레이블 예측을 사용하여 효율적인 반복 업데이트 방법을 적용합니다.
범주 통계를 업데이트하기 위해 저자는 아래와 같이 의사 레이블 예측을 사용하여 효율적인 반복 업데이트 방법을 적용합니다.
각 데이터 카테고리의 샘플링 포인트는 의사 라벨을 통해 별도로 계산되며, 카테고리 균형에 따른 전체 분포 통계는 다음 공식을 통해 다시 얻어지며, 학습된 특징 공간을 카테고리 균형 소스 데이터와 정렬합니다. . 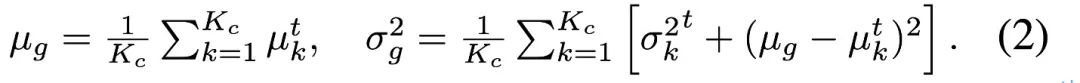 일부 특별한 경우에 저자는 카테고리 수가 많거나
일부 특별한 경우에 저자는 카테고리 수가 많거나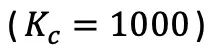 의사 라벨 정확도가 낮은 경우(정확도
의사 라벨 정확도가 낮은 경우(정확도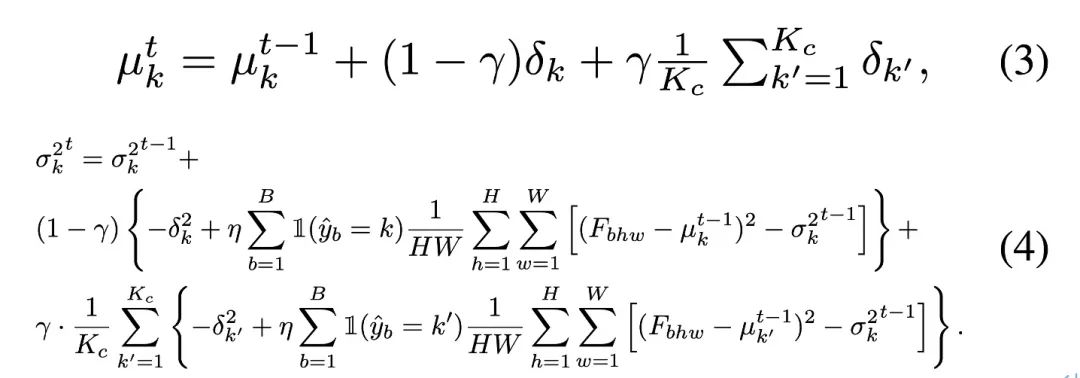
추가 분석 및 관찰을 통해 저자는 γ=1일 때 전체 업데이트가 RoTTA로 변질되는 전략 γ=0일 때 RobustBN의 업데이트 전략은 순전히 카테고리 독립적인 업데이트 전략입니다. 따라서 γ가 0~1의 값을 취하면 다양한 상황에 적용할 수 있습니다. Three-network self-training model저자는 기존 학생-교사 모델을 기반으로 앵커링 네트워크 분기를 추가하고 앵커링 손실을 도입하여 교사 네트워크의 예측 분포를 제한했습니다. 이 디자인은 TTAC++에서 영감을 받았습니다. TTAC++는 테스트 데이터 스트림에 대한 자체 학습에만 의존하면 쉽게 확인 편향이 축적될 수 있다고 지적합니다. 이 문제는 이 기사의 실제 테스트 데이터 스트림에서 더 심각합니다. TTAC++는 원본 도메인에서 수집된 통계 정보를 사용하여 도메인 정렬 정규화를 구현하지만 Fully TTA 설정의 경우 이 원본 도메인 정보를 수집할 수 없습니다. 동시에 저자는 또 다른 계시를 얻었습니다. 감독되지 않은 도메인 정렬의 성공은 두 도메인 분포가 상대적으로 높다는 가정에 기초합니다. 따라서 저자는 교사 모델의 예측 분포가 소스 모델의 예측 분포에서 너무 멀리 벗어나는 것을 피하기 위해 교사 모델을 정규화하기 위해 BN 통계의 동결된 소스 도메인 모델만 조정했습니다(이로 인해 이전의 높은 일치율 경험이 파괴되었습니다). 두 분포 사이) 관찰). 수많은 실험을 통해 이 기사의 발견과 혁신이 정확하고 강력하다는 것이 입증되었습니다. 앵커링 손실의 표현은 다음과 같습니다. 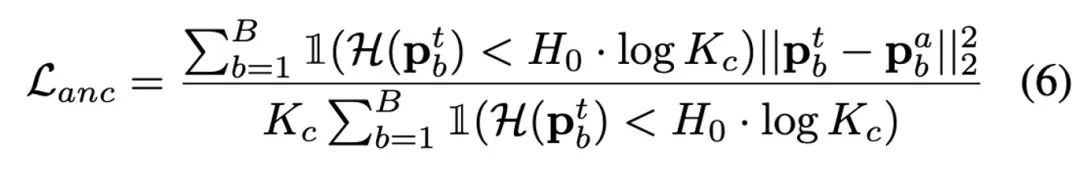
다음 그림은 TRIBE 네트워크의 프레임 다이어그램을 보여줍니다.
논문의 저자는 4개의 데이터를 사용했습니다. TRIBE로 설정된 두 가지 실제 TTA 프로토콜을 벤치마크로 사용하여 검증되었습니다. 두 가지 실제 TTA 프로토콜은 전역 클래스 분포가 고정된 GLI-TTA-F와 전역 클래스 분포가 고정되지 않은 GLI-TTA-V입니다. 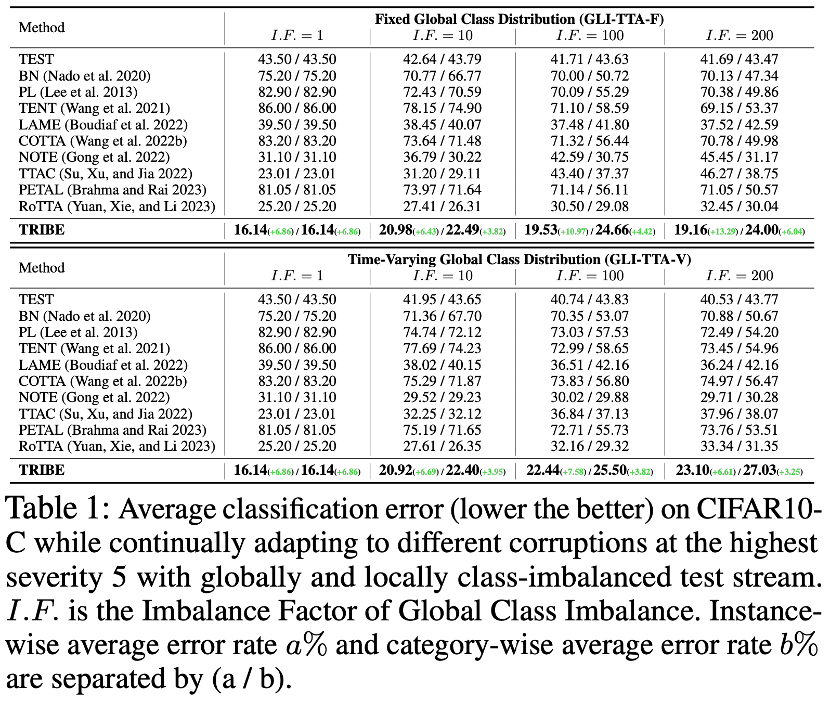
위 표는 서로 다른 불균형 계수 하에서 CIFAR10-C 데이터 세트의 두 프로토콜의 성능을 보여줍니다. 1 LAME, TTAC, NOTE, RoTTA 및 TRIBE만 제안되었습니다. 이 논문은 TEST의 기준선을 초과하여 실제 테스트 흐름에서 보다 강력한 TTA 방법의 필요성을 보여줍니다. 2. 글로벌 클래스 불균형은 기존 TTA 방식에 큰 도전을 가져왔습니다. 예를 들어 이전 SOTA 방식인 RoTTA는 I.F.=1일 때 25.20%의 오류율을 보였지만 I.F.=일 때 25.20%로 오류율이 증가했습니다. 200. 32.45%에 비해 TRIBE는 상대적으로 좋은 성능을 안정적으로 보여줄 수 있다. 3. TRIBE의 일관성은 이전의 모든 방법을 능가하는 절대적인 이점을 가지고 있으며, 글로벌 클래스 밸런스(I.F.=1) 설정에서 이전 SOTA(TTAC)를 약 7% 능가합니다. 어려움 글로벌 클래스 불균형(I.F.=200) 설정에서 약 13%의 성능 향상을 달성했습니다. 4. I.F.=10에서 I.F.=200까지, 다른 TTA 방법은 불균형 정도가 증가함에 따라 성능이 저하되는 경향을 나타냅니다. TRIBE는 비교적 안정적인 성능을 유지할 수 있습니다. 이는 심각한 클래스 불균형과 앵커링 손실을 더 잘 설명하는 균형 잡힌 배치 정규화 계층을 도입하여 다양한 도메인에 걸쳐 과도한 적응을 방지하기 때문입니다. 더 많은 데이터 세트 결과를 보려면 원본 논문을 참조하세요. 또한 표 4는 다음과 같은 관찰 결론과 함께 자세한 모듈식 절제를 보여줍니다. 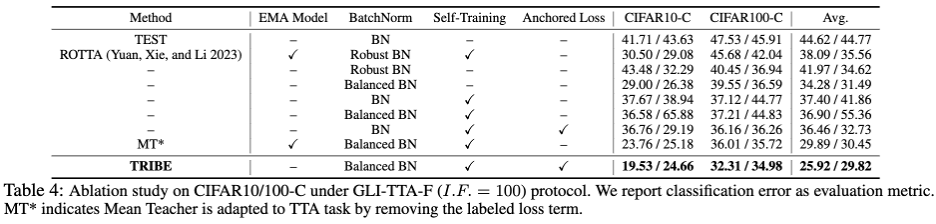
1 모델 매개변수를 업데이트하지 않고 BN을 균형 잡힌 배치 정규화 계층(균형 BN)으로만 대체합니다. Forward를 통해 BN 통계를 업데이트하는 것만으로 10.24%(44.62 -> 34.28)의 성능 향상을 가져올 수 있으며 Robust BN의 오류율 41.97%를 능가합니다. 2. 이전 BN 구조이든 최신 Balanced BN 구조이든 Self-Training과 결합된 Anchored Loss는 성능이 향상되었으며 EMA 모델의 정규화 효과를 능가했습니다. 이 기사의 나머지 부분과 9페이지 분량의 부록에서는 마침내 17개의 상세한 표 결과를 제시하여 다차원에서 TRIBE의 안정성, 견고성 및 우수성을 보여줍니다. 부록에는 균형 배치 정규화 계층에 대한 보다 자세한 이론적 도출 및 설명도 포함되어 있습니다. Non-i.i.d. 테스트 데이터 흐름, 글로벌 클래스 불균형 및 지속적인 도메인 이전과 같은 많은 실제 문제를 해결하기 위해 연구팀은 어떻게 시간 영역 적응 알고리즘의 테스트 견고성을 향상시킵니다. 저자는 불균형 테스트 데이터에 적응하기 위해 편견 없는 통계 추정을 달성하기 위해 Balanced Batchnorm Layer를 제안하고 표준화를 위해 학생 네트워크, 교사 네트워크 및 앵커 네트워크를 포함하는 네트워크를 제안했습니다. 자가 훈련을 기반으로 한 TTA. 하지만 이 글은 여전히 부족함과 개선의 여지가 있습니다. 많은 실험과 출발점이 분류 작업과 BN 모듈을 기반으로 하기 때문에 다른 작업과 Transformer 기반 모델에 대한 적응 정도는 아직 알 수 없습니다. 이러한 문제는 후속 작업에서 추가 연구와 탐구가 필요합니다.
위 내용은 TRIBE는 도메인 적응 견고성을 달성하고 여러 실제 시나리오에서 SOTA의 AAAII 2024에 도달합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

