
GPT-4 및 Claude2.1 잠금 해제: 한 문장으로 100,000개 이상의 컨텍스트 대형 모델의 진정한 힘을 깨닫고 점수를 27에서 98로 높일 수 있습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-12-15 11:37:37827검색
메이저 모델 제조사마다 컨텍스트 창을 차례차례 롤업하고 있습니다. Llama-1의 표준 구성은 여전히 2k였지만, 이제 100k 미만인 사람들은 나가기에는 너무 당황스럽습니다.
그러나 Goose의 극단적인 테스트 결과 대부분의 사람들이 이를 잘못 사용하여 AI의 적절한 힘을 발휘하지 못하는 것으로 나타났습니다.
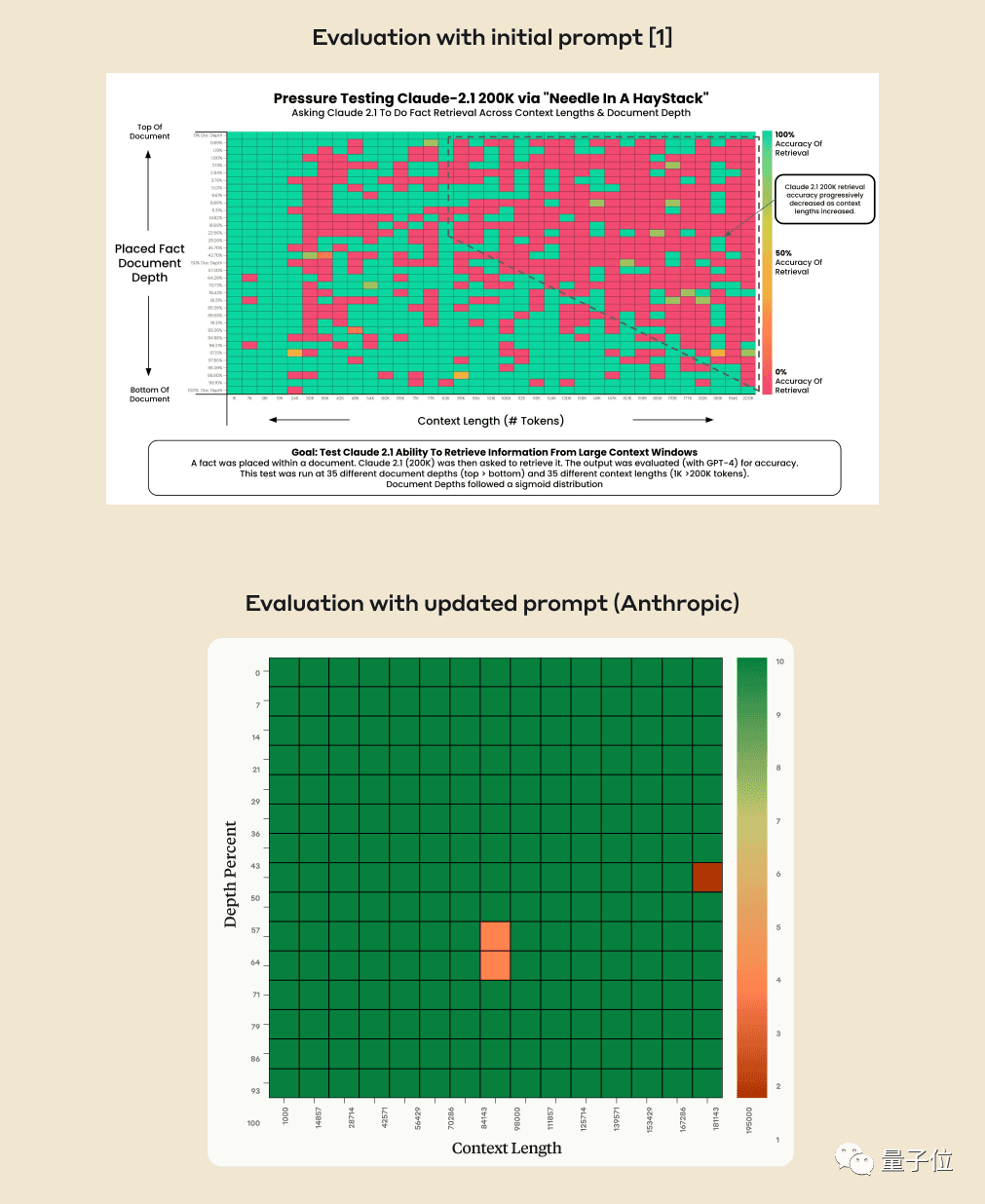
AI가 수십만 단어에서 핵심 사실을 정말 정확하게 찾을 수 있을까요? 색이 빨간색일수록 AI가 실수를 더 많이 하는 것입니다.
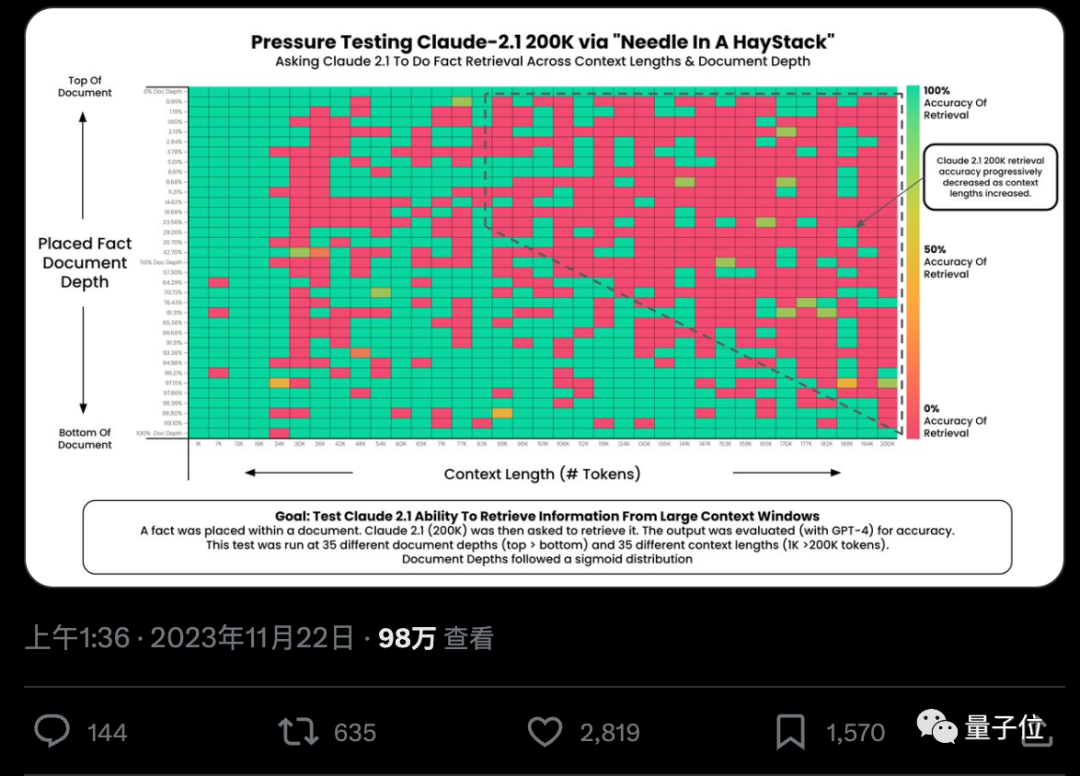
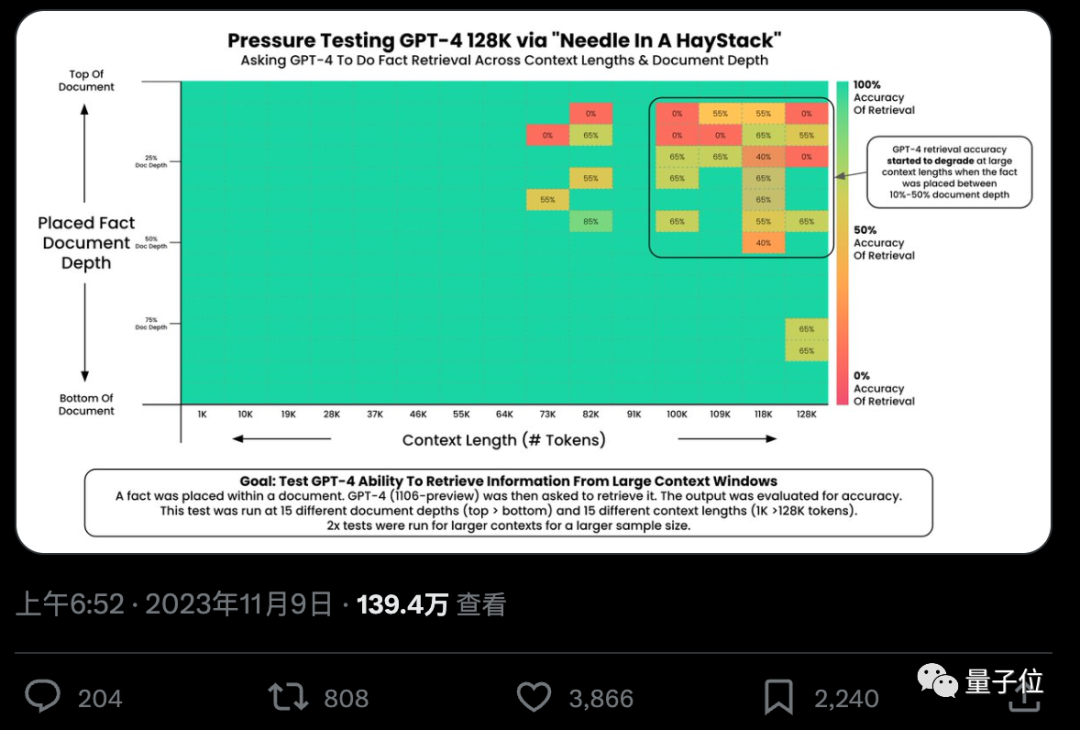
기본적으로 GPT-4-128k 및 최신 출시된 Claude2.1-200k 결과는 이상적이지 않습니다.
그러나 클로드 팀은 상황을 이해한 후, 한 문장을 추가하여 점수를 27%에서 98%로 직접 높이는 초간단 해결책을 생각해 냈습니다.
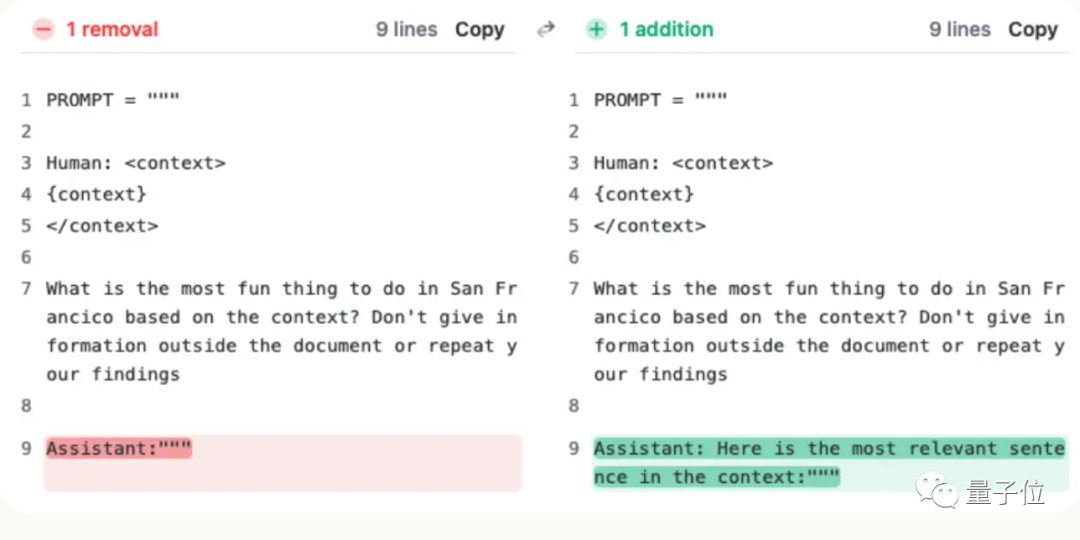
이 문장이 사용자의 질문에 추가되지 않은 것뿐입니다. 대신 AI가 답변 시작 부분에 다음과 같이 말했습니다.
“문맥에서 가장 관련성이 높은 문장은 다음과 같습니다.”
(문맥상 가장 관련성이 높은 문장입니다.)
큰 모델이 건초 더미에서 바늘을 찾도록 하세요.
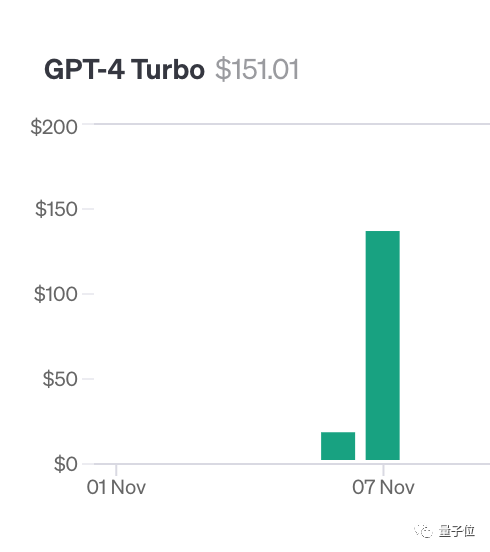
이 테스트를 수행하기 위해 저자 Greg Kamradt는 최소한 $150의 개인 돈을 썼습니다.
Claude2.1을 테스트할 때 Anthropic은 그에게 무료 할당량을 제공했습니다. 다행히 추가로 1,016달러를 지출할 필요가 없었습니다.
사실 테스트 방법은 모두 218개를 사용했습니다. YC 창립자 Paul Graham의 블로그 게시물이 테스트 데이터로 사용되었습니다.
문서의 다양한 위치에 특정 문장 추가: 샌프란시스코의 가장 좋은 점은 화창한 날 돌로레스 공원에 앉아 샌드위치를 즐기는 것입니다.
질문에 답하려면 제공된 문맥을 사용하세요. 다양한 문맥 길이와 문서를 사용하세요. 다른 위치에 추가된 GPT-4와 Claude2.1은 반복적으로 테스트되었습니다

마지막으로 Langchain Evals 라이브러리를 사용하여 결과를 평가했습니다
저자는 이 테스트 세트를 "건초 더미에서 바늘 찾기"라고 명명했습니다. 건초더미 속의 바늘'이라는 코드를 공개하고 GitHub에서 코드를 오픈소스로 공개했으며 별 200개 이상을 받았으며 한 회사가 차세대 대형 모델의 테스트를 후원했다는 사실을 밝혔습니다.
AI 회사는 자체적으로 해결책을 찾았습니다.
몇 주 후 Claude의 뒤에 있는 회사Anthropic 주의 깊게 분석한 결과 AI가 단지 질문에 대답하기를 꺼리는 것으로 나타났습니다. 문서의 한 문장을 기준으로 하며, 특히 이 문장이 나중에 삽입된 경우, 전체 기사와 관련이 거의 없는 경우에는 더욱 그렇습니다.
즉, AI가 이 문장이 기사의 주제와 관련이 없다고 판단하면 문장 전체를 검색하지 않는 방식을 취하게 됩니다

이 때, AI를 통과하고 Claude에게 답변 시작 부분에 이를 추가하도록 요청하는 것을 의미합니다. "문맥에서 가장 관련성이 높은 문장은 다음과 같습니다."라는 문장을 해결할 수 있습니다.
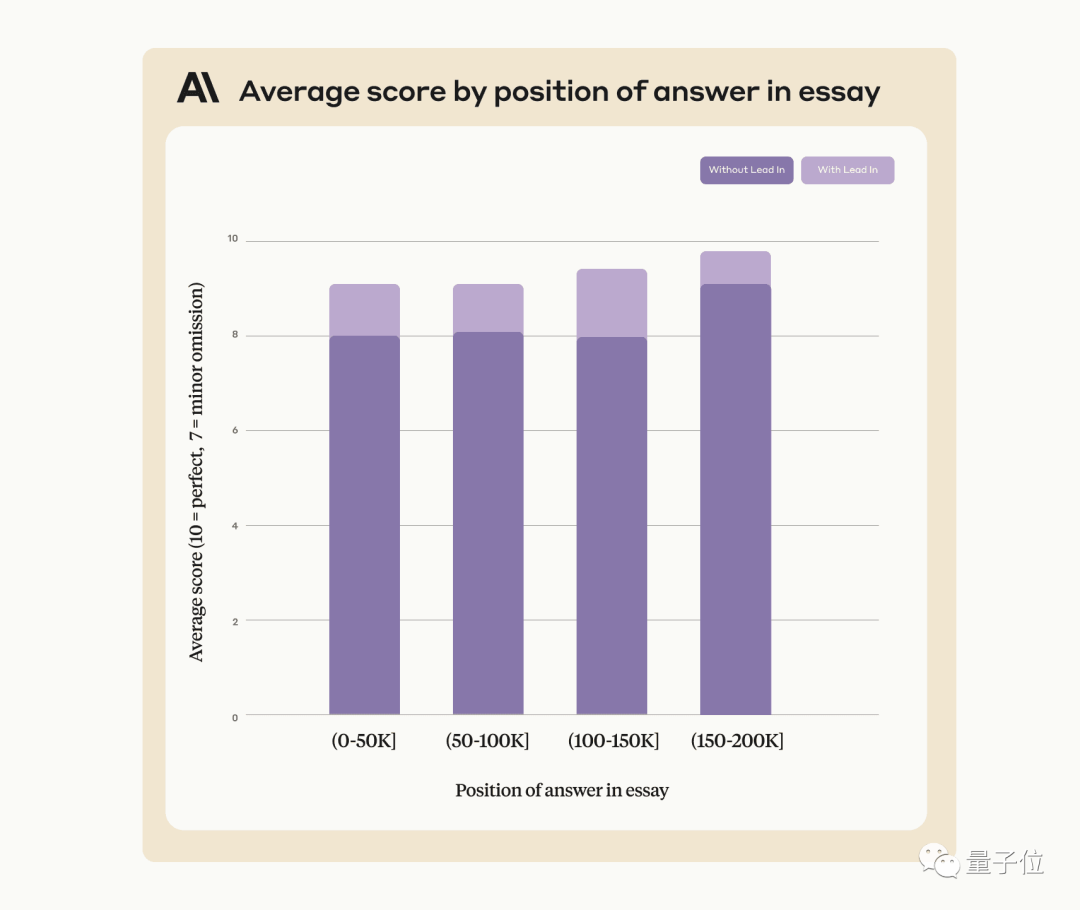
이 방법을 사용하면 원문에 인위적으로 추가되지 않은 문장을 찾는 경우에도 Claude의 성능을 향상시킬 수 있습니다
Anthropic은 Claude를 더욱 유능하게 만들기 위해 앞으로도 계속 훈련할 것이라고 말했습니다. 그러한 작업에 적합합니다.
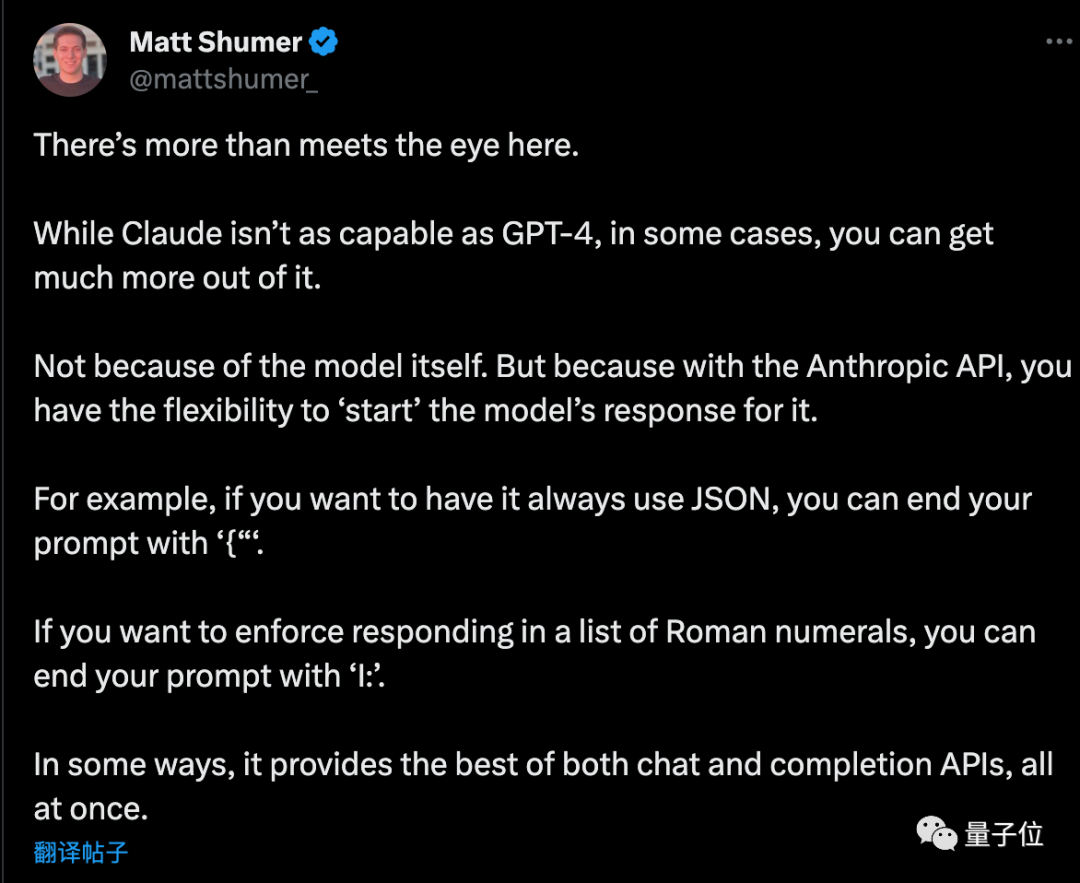
API를 사용할 때 AI에게 특정 시작으로 대답하도록 요청하면 다른 영리한 용도도 있을 수 있습니다
기업가인 Matt Shumer가 계획을 읽은 후 몇 가지 추가 팁을 제공했습니다
AI가 순수 JSON 형식을 출력하도록 하려면 프롬프트 단어가 "{"로 끝납니다. 마찬가지로 AI가 로마 숫자를 나열하도록 하려면 프롬프트 단어가 "I:"로 끝날 수 있습니다.
하지만 아직 끝나지 않았습니다...
국내 대기업들도 이 테스트에 주목하기 시작했고 자사의 대형 모델이 통과할 수 있는지
또한 매우 긴 컨텍스트를 가지고 있는지 달의 어두운 면 키미 대형 모델 팀도 문제점을 발견했지만, 다른 해결책을 제시해 좋은 결과를 얻었습니다.

원래 의미를 바꾸지 않고 다시 작성해야 하는 내용은 다음과 같습니다. AI에게 답변에 문장을 추가하도록 요청하는 것보다 사용자 질문 프롬프트를 수정하는 것이 더 쉽다는 점, 특히 API가 호출되지 않는 경우에는 챗봇 제품을 직접 사용
달 뒷면에서 GPT-4 및 Claude2.1을 테스트하는 데 도움이 되는 새로운 방법을 사용했으며 그 결과 GPT-4가 상당한 개선을 이룬 것으로 나타났습니다. Claude2.1은 약간만 개선됨
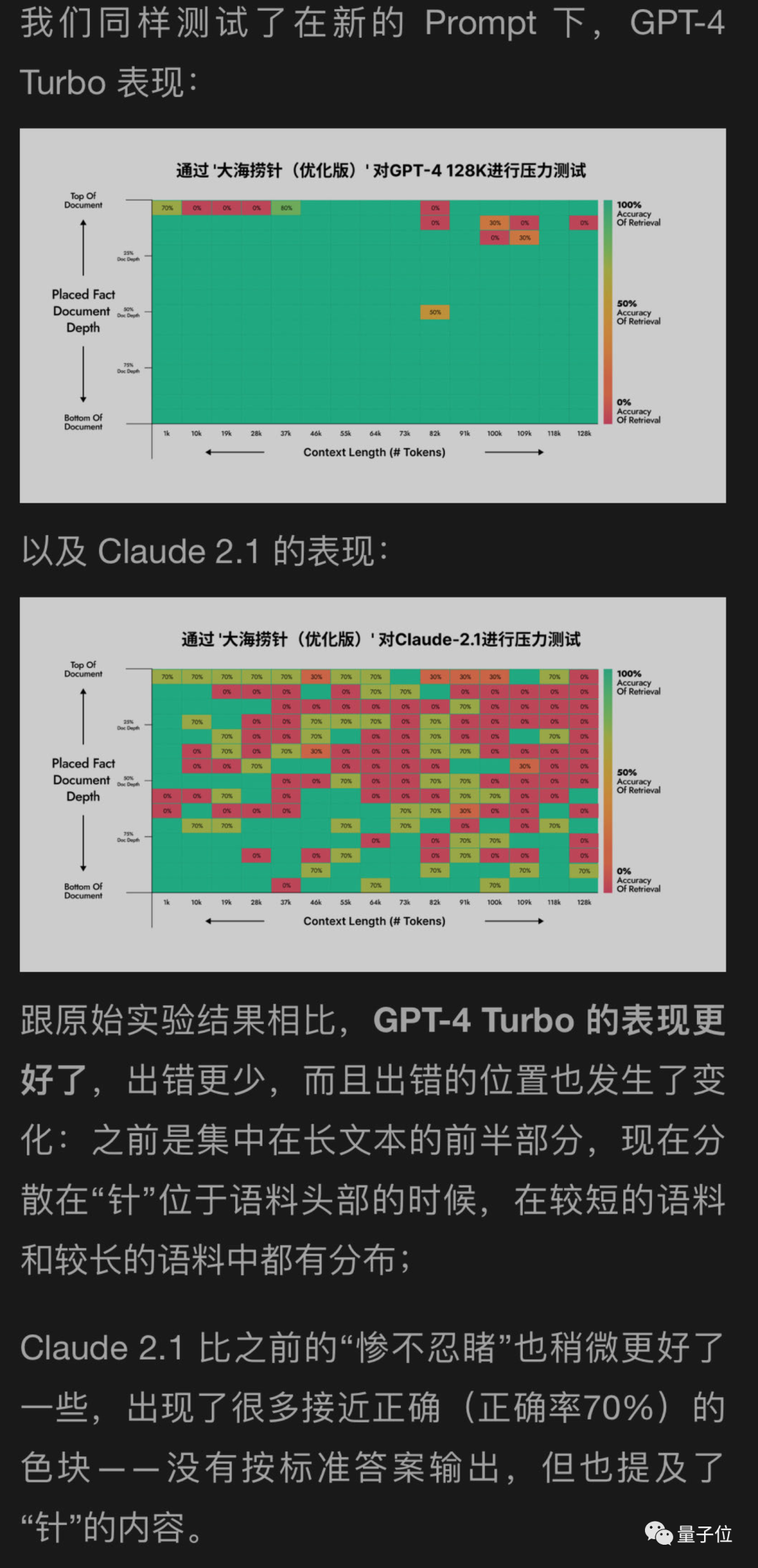
이 실험 자체에는 특정 한계가 있는 것으로 보이며 이는 자체 정렬과 관련이 있을 수 있으므로 Constituional AI에서 제공하는 방법을 사용하는 것이 좋습니다. 인류 그 자체.
이후 달 뒷면의 엔지니어들은 계속해서 더 많은 실험을 진행했고, 그 실험 중 하나는 실제로...

앗, 테스트 데이터로 바뀌었어요
위 내용은 GPT-4 및 Claude2.1 잠금 해제: 한 문장으로 100,000개 이상의 컨텍스트 대형 모델의 진정한 힘을 깨닫고 점수를 27에서 98로 높일 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!