
휴대폰은 27억 개의 매개변수가 있는 대형 모델보다 Microsoft의 소형 모델을 더 잘 실행합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-12-14 22:45:471474검색
Microsoft CEO Nadella는 지난달 Ignite 컨퍼런스에서 Phi-2 소규모 모델이 완전한 오픈 소스가 될 것이라고 발표했습니다. 이러한 움직임은 상식 추론, 언어 이해 및 논리적 추론의 성능을 크게 향상시킬 것입니다.

오늘 Microsoft는 Phi-2 모델과 새로운 프롬프트 기술 프롬프트 베이스에 대한 자세한 내용을 발표했습니다. 27억 개의 매개변수만 있는 이 모델은 Llama2 7B, Llama2 13B, Mistral 7B보다 성능이 뛰어나며 대부분의 상식 추론, 언어 이해, 수학 및 코딩 작업에서 Llama2 70B와의 격차를 줄입니다(또는 그 이상).
동시에 작은 크기의 Phi-2는 노트북, 휴대폰 등의 모바일 장치에서 실행될 수 있습니다. Nadella는 Microsoft가 동급 최고의 SLM(소형 언어 모델) 및 SOTA 프롬프트 기술을 R&D 개발자와 공유하게 되어 매우 기쁘다고 말했습니다.
Microsoft는 올해 6월에 7B 마커만 포함된 "교과서 품질" 데이터를 사용하여 1.3B 매개변수, 즉 phi-1이 있는 모델을 교육하는 "Just a Textbook"이라는 논문을 발표했습니다. 경쟁사보다 훨씬 작은 데이터 세트와 모델 크기에도 불구하고 phi-1은 HumanEval에서 50.6%의 첫 번째 통과율과 MBPP에서 55.5%의 정확도를 달성했습니다. phi-1은 고품질의 "작은 데이터"라도 모델이 좋은 성능을 발휘할 수 있음을 입증했습니다
Microsoft는 이후 9월에 고품질의 잠재력에 초점을 맞춘 "Just a Textbook II: Phi-1.5 기술 보고서"를 발표했습니다. '작은 데이터'에 대한 추가 조사가 이루어졌습니다. 이 기사에서는 QA Q&A, 코딩 및 기타 시나리오에 적합하고 13억 규모에 도달할 수 있는 Phi-1.5를 제안합니다
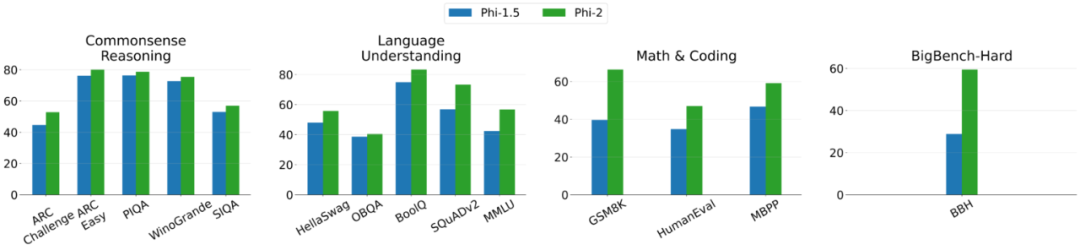
요즘 27억 개의 매개변수를 가진 Phi-2는 다시 한번 "작은 몸체"를 사용하여 제공합니다. 탁월한 추론 및 언어 이해 능력으로 130억 매개변수 미만의 기본 언어 모델에서 SOTA 성능을 입증합니다. 모델 확장 및 교육 데이터 관리의 혁신 덕분에 Phi-2는 복잡한 벤치마크에서 자체 크기의 25배에 해당하는 모델과 일치하거나 초과합니다.
Microsoft는 Phi-2가 연구원들이 해석 가능성 탐색, 보안 개선 또는 다양한 작업에 대한 미세 조정 실험을 수행하는 데 이상적인 모델이 될 것이라고 말합니다. Microsoft는 언어 모델 개발을 용이하게 하기 위해 Azure AI Studio 모델 카탈로그에서 Phi-2를 사용할 수 있도록 했습니다.
Phi-2 주요 특징
언어 모델의 크기가 수천억 개의 매개변수로 증가하면서 실제로 많은 새로운 기능이 출시되었고 자연어 처리의 환경이 재정의되었습니다. 그러나 질문은 남아 있습니다. 이러한 새로운 기능은 훈련 전략 선택(예: 데이터 선택)을 통해 소규모 모델에서도 달성될 수 있습니까?
Microsoft에서 제공하는 솔루션은 Phi 시리즈 모델을 사용하여 소규모 언어 모델을 학습시켜 대규모 모델과 유사한 성능을 달성하는 것입니다. Phi-2는 두 가지 측면에서 전통적인 언어 모델의 확장 규칙을 깨뜨립니다.
첫째, 훈련 데이터의 품질은 모델 성능에 중요한 역할을 합니다. Microsoft는 "교과서 품질" 데이터에 중점을 두어 이러한 이해를 최대한 활용합니다. 그들의 훈련 데이터는 과학, 일상 활동, 심리학과 같은 상식 지식과 추론을 모델에 가르치는 특별히 생성된 포괄적인 데이터 세트로 구성됩니다. 또한 교육적 가치와 콘텐츠 품질을 심사한 엄선된 웹 데이터를 사용하여 교육 자료를 더욱 확장했습니다.
두 번째로 Microsoft는 혁신적인 기술을 사용하여 13억 개의 매개변수로 Phi-1.5에서 확장했습니다. 처음에는 지식이 점차 내장되었습니다. 27억 개의 매개변수를 갖는 Phi-2로 변환됩니다. 이러한 확장된 지식 이전은 교육 융합을 가속화하고 Phi-2의 벤치마크 점수를 크게 향상시킵니다.
다음은 Phi-2와 Phi-1.5의 비교 그래프입니다. 단, BBH(3-shot CoT)와 MMLU(5-shot)을 제외하고 다른 모든 작업은 0-shot을 사용하여 평가됩니다
훈련 세부정보
Phi-2는 다음 단어를 예측하는 것이 목표인 Transformer 기반 모델입니다. 96개의 A100 GPU를 사용하여 합성 및 네트워크 데이터 세트에 대해 훈련되었으며 14일이 걸렸습니다.
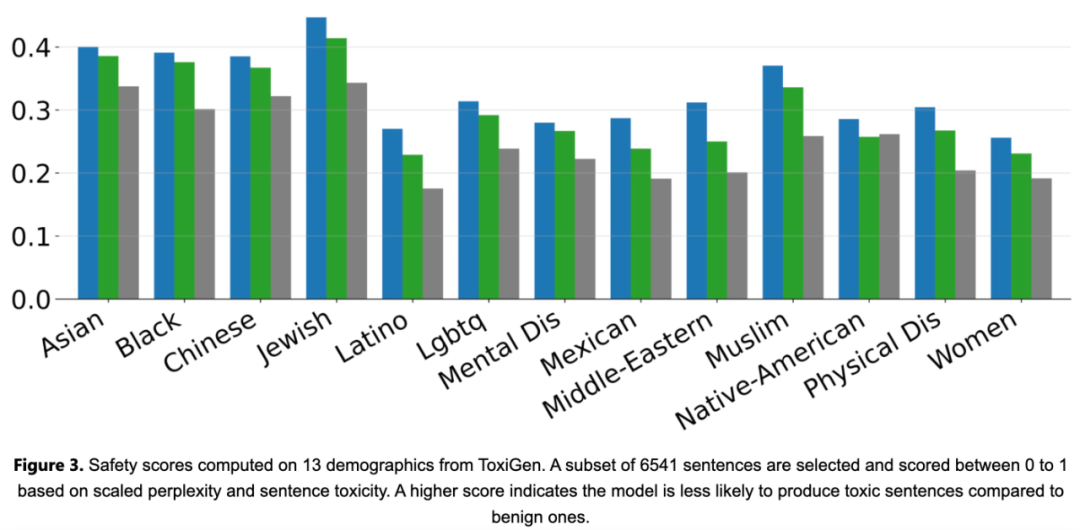
Phi-2는 RLHF(Reinforcement Learning with Human Feedback) 정렬이 없고 지침 미세 조정이 없는 기본 모델입니다. 그럼에도 불구하고 Phi-2는 아래 그림 3과 같이 조정된 기존 오픈 소스 모델에 비해 독성 및 편향 측면에서 여전히 더 나은 성능을 보였습니다.
실험 평가
먼저, 이 연구는 Phi-2를 학술 벤치마크에서 공통 언어 모델과 실험적으로 비교했으며 다음을 포함하여 여러 범주를 포괄합니다.
- Big Bench Hard(BBH)(CoT로 3샷) )
- 상식추론(PIQA, WinoGrande, ARC easy and Challenge, SIQA),
- 언어이해(HellaSwag, OpenBookQA, MMLU(5샷), SQuADv2(2샷), BoolQ)
- 수학(GSM8k(8샷))
- 인코딩(HumanEval, MBPP(3샷))
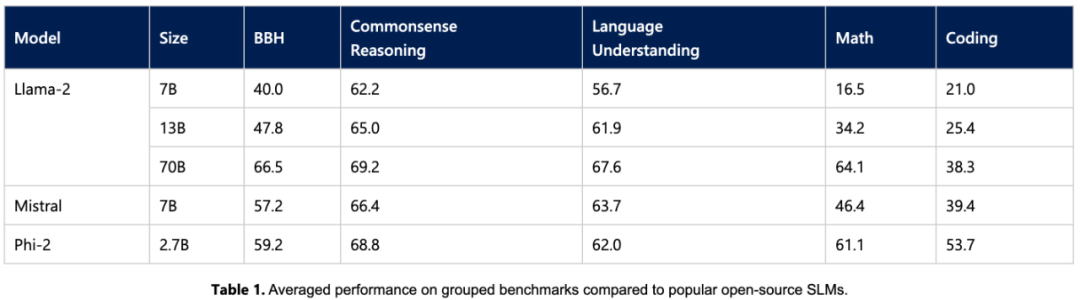
Phi-2 모델은 27억 개의 매개변수만 가지고 있지만 다양한 집계로 벤치마크에서 , 성능은 7B 및 13B Mistral 모델과 Llama2 모델을 능가합니다. Phi-2는 부피가 큰 25x Llama2-70B 모델에 비해 다단계 추론 작업(예: 코딩 및 수학)에서 더 나은 성능을 발휘한다는 점을 언급할 가치가 있습니다. 또한, 작은 크기에도 불구하고 Phi-2 2의 성능은 다음과 비슷합니다. Google이 최근 출시한 Gemini Nano 2. 많은 공개 벤치마크가 훈련 데이터에 유출될 수 있기 때문에 연구팀은 언어 모델의 성능을 테스트하는 가장 좋은 방법은 특정 사용 사례에서 테스트하는 것이라고 믿습니다. 따라서 이 연구에서는 여러 내부 Microsoft 독점 데이터 세트 및 작업을 사용하여 Phi-2를 평가하고 이를 Mistral 및 Llama-2와 다시 비교했습니다. 평균적으로 Phi-2는 Mistral-7B보다 성능이 뛰어나고 Mistral -7B는 Llama2 모델보다 성능이 뛰어납니다(7B, 13B, 70B).
위 내용은 휴대폰은 27억 개의 매개변수가 있는 대형 모델보다 Microsoft의 소형 모델을 더 잘 실행합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!