



语法:LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[CHARACTER SET charset_name]
[FIELDS
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number LINES]
[(col_name_or_user_var,...)]
[SET col_name = expr,...]
导入表中的某一列数据
数据格式:北京 上海 深圳 广州 长沙 郑州 合肥 西安 南昌 南京 杭州 成都
sql代码:
LOAD DATA LOCAL INFILE 'C:\\Users\\XXX\\Desktop\\code.txt' INTO TABLE sys_sensitiveword_t(cityname);
导入整个表数据
创建stu表:create table stu_other(id int auto_increment primary key,stu_name varchar(50),age int);然后创建一个文本文件“stu.txt”,每行包含一个记录,放在C盘的根目录下。默认的字段分隔符是(tab),你可以更改,下面说明。并且以CREATE TABLE语句中列出的列次序给出。对于丢失的值(例如未知的性别,或仍然活着的动物的死亡日期),你可以使用NULL值。为了在你的文本文件中表示这些内容,使用/N(反斜线,字母N)。 如stu.txt的内容如下:
100001 FLB100001 100001 100002 FLB100002 100002 100003 FLB100003 100003 100004 FLB100004 100004 100005 FLB100005 100005 100006 FLB100006 100006 100007 FLB100007 100007 100008 FLB100008 100008
这里我用的是table分开。 要想将文本文件“stu.txt”装载到stu表中,使用这个命令:
LOAD DATA LOCAL INFILE 'c://stu.txt' INTO TABLE stu;这里没有指定字段分隔符,以及行的终止符,默认情况下是这样的: 字段分隔符:
<pre class="prebrush">FIELDS TERMINATED BY '/t' ENCLOSED BY '' ESCAPED BY '//'
其中的'/t'就表示是字段分隔符为tab键,如果不想更改,那就把FIELDS TERMINATED BY '/t'中的'/t'改在你自己的分隔符。将执行命令改成这样:
LOAD DATA LOCAL INFILE 'c:/stu.txt' INTO TABLE stu fields terminated by ‘ ‘;这里我用的是空格。 行终止符:
<pre class="prebrush">LINES TERMINATED BY '/n' STARTING BY ''请注意如果用Windows中的编辑器(使用/r/n做为行的结束符)创建文件,应使用:
LOAD DATA LOCAL INFILE 'C://stu.txt' INTO TABLE stu LINES TERMINATED BY '/r/n';(在运行OS X的Apple机上,应使用行结束符'/r'。) 如果你愿意,你能明确地在LOAD DATA语句中指出列值的分隔符和行尾标记,但是默认标记是定位符和换行符。这对读入文件“stu.txt”的语句已经足够。
导出表数据
select * from stu_t into outfile "c://stu_t.txt";不过,没有按记录自动分行 这样才能够换行:
select * from stu_t into outfile "c://stu_t.txt" lines terminated by '/r/n';

 pptm是什么格式Jan 11, 2021 pm 02:46 PM
pptm是什么格式Jan 11, 2021 pm 02:46 PMpptm是office办公套件中powerpoint的一种文件格式,全名是“启用宏的PowerPoint演示文稿”。pptm文件只能用2007及以上版本的office软件打开,如果用其他版本软件打开会出现无法编辑、图片不完整等问题。
 试用新的铃声和文本提示音:在 iOS 17 的 iPhone 上体验最新的声音提醒功能Oct 12, 2023 pm 11:41 PM
试用新的铃声和文本提示音:在 iOS 17 的 iPhone 上体验最新的声音提醒功能Oct 12, 2023 pm 11:41 PM在iOS17中,Apple彻底改变了其全部铃声和文本音调选择,提供了20多种可用于电话、短信、闹钟等的新声音。以下是查看它们的方法。与旧铃声相比,许多新铃声的长度更长,听起来更现代。它们包括琶音、破碎、树冠、小木屋、啁啾、黎明、出发、多洛普、旅程、水壶、水星、银河系、四边形、径向、清道夫、幼苗、庇护所、洒水、台阶、故事时间、戏弄、倾斜、展开和山谷。反射仍然是默认铃声选项。还有10多种新的文本提示音可用于传入短信、语音邮件、传入邮件警报、提醒警报等。要访问新的铃声和文本铃声,首先,请确保您的iPh
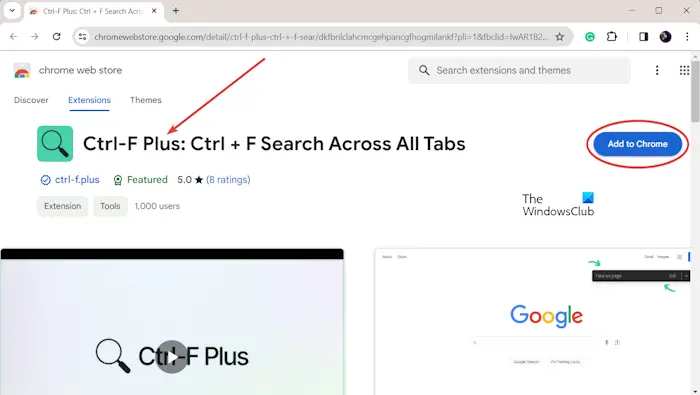 如何在Chrome和Edge的所有选项卡中搜索文本Feb 19, 2024 am 11:30 AM
如何在Chrome和Edge的所有选项卡中搜索文本Feb 19, 2024 am 11:30 AM本教程向您展示了如何在Windows的Chrome或Edge中找到所有打开的标签页上的特定文本或短语。有没有办法在Chrome中所有打开的标签页上进行文本搜索?是的,您可以使用Chrome中的免费外部Web扩展在所有打开的标签上执行文本搜索,无需手动切换标签。一些扩展如TabSearch和Ctrl-FPlus可以帮助您轻松实现这一功能。如何在GoogleChrome的所有选项卡中搜索文本?Ctrl-FPlus是一个免费的扩展,它方便用户在浏览器窗口的所有选项卡中搜索特定的单词、短语或文本。这个扩
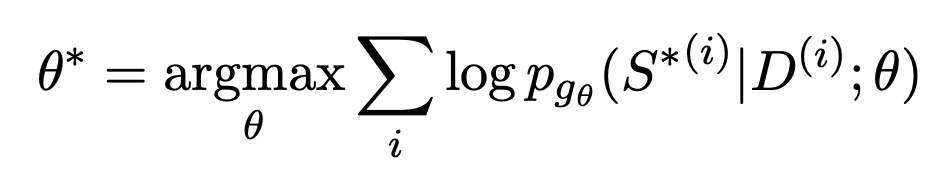 利用大模型打造文本摘要训练新范式Jun 10, 2023 am 09:43 AM
利用大模型打造文本摘要训练新范式Jun 10, 2023 am 09:43 AM1、文本任务这篇文章主要讨论的是生成式文本摘要的方法,如何利用对比学习和大模型实现最新的生成式文本摘要训练范式。主要涉及两篇文章,一篇是BRIO:BringingOrdertoAbstractiveSummarization(2022),利用对比学习在生成模型中引入ranking任务;另一篇是OnLearningtoSummarizewithLargeLanguageModelsasReferences(2023),在BRIO基础上进一步引入大模型生成高质量训练数据。2、生成式文本摘要训练方法和
 win7系统无法打开txt文本怎么办Jul 06, 2023 pm 04:45 PM
win7系统无法打开txt文本怎么办Jul 06, 2023 pm 04:45 PMwin7系统无法打开txt文本怎么办?我们电脑中需要进行文本文件的编辑时,最简单的方式就是去使用文本工具。但是有的用户却发现自己的电脑无法打开txt文本文件了,那么这样的问题要怎么去解决呢?一起来看看详细的解决win7系统无法打开txt文本教程吧。解决win7系统无法打开txt文本教程 1、在桌面上右键点击桌面的任意一个txt文件,如果没有的可以右键点击新建一个文本文档,然后选择属性,如下图所示: 2、在打开的txt属性窗口中,常规选项下找到更改按钮,如下图所示: 3、在弹出的打开方式设置
 网聊一个月,杀猪盘骗子竟被AI整破防!200万网友大呼震撼Apr 12, 2023 am 09:40 AM
网聊一个月,杀猪盘骗子竟被AI整破防!200万网友大呼震撼Apr 12, 2023 am 09:40 AM说起「杀猪盘」,大家肯定都恨得牙痒痒。在这类交友婚恋类网络诈骗中,骗子会提前物色好容易上钩的受害者,而她们,往往是单纯善良、对爱情怀有美好幻想的高知乖乖女。而为了能和这些骗子大战500回合,B站大名鼎鼎的科技圈up主「图灵的猫」训练了一个聊起天来频出爆梗,甚至比真人还6的AI。结果,随着AI的一通操作,骗子竟然被这个以假乱真的小姐姐搞得方寸大乱,直接给「她」转了520。更好笑的是,发现根本无机可乘的骗子,最后不仅自己破了防,还被AI附送一段「名句」:视频一出,立刻爆火,在B站冲浪的小伙伴们纷纷被
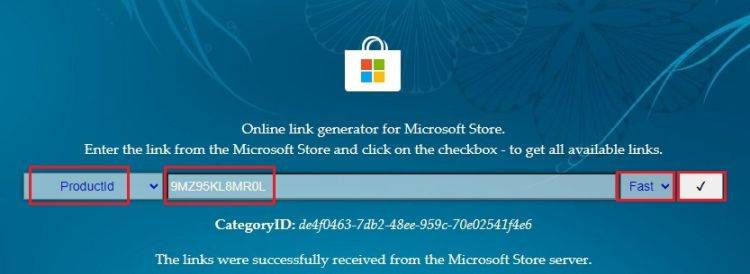 如何在 Windows 11 上从屏幕截图中复制文本Sep 20, 2023 pm 05:57 PM
如何在 Windows 11 上从屏幕截图中复制文本Sep 20, 2023 pm 05:57 PM下载带有文本操作的新截图工具尽管新的截图工具仅限于开发和金丝雀版本,但如果您不想等待,可以立即安装更新的Windows11截图工具(版本号11.2308.33.0)。这是如何工作的:1.继续在您的WindowsPC上打开此网站(访问)。2.接下来,选择“产品ID”并将“9MZ95KL8MR0L”粘贴到文本字段中。3.从右侧下拉菜单切换到“快速”环,然后单击搜索。4.现在,在出现的搜索结果中查找此版本“2022.2308.33.0”。5.右键单击具有MSIXBUNDLE扩展名的那个,然后在上下文菜
 png是矢量图格式吗Sep 15, 2022 pm 03:14 PM
png是矢量图格式吗Sep 15, 2022 pm 03:14 PMpng不是矢量图格式;png格式指的是便携式网络图形,是一种采用无损压缩算法的位图格式,而矢量图片一般是指用制图软件或矢量工具绘制出的图片文件,也称为面向对象的图像或绘图图像,在数学上定义为一系列由线连接的点。


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.
뜨거운 주제
 1371
1371 523819
523819