
Meta, 음성 및 텍스트 동시 입력 지원하는 AI 오디오 모델 Audiobox 출시

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-12-04 17:25:561474검색
Meta는 최근 Audiobox라는 AI 사운드 생성 모델을 출시했습니다. 이 모델은 음성 및 텍스트 입력을 모두 받을 수 있으며, 사용자는 음성 및 텍스트 설명을 통해 필요한 오디오를 생성할 수 있습니다
이 모델은 메타가 올해 6월 출시한 보이스박스 AI 모델을 기반으로 다양한 환경음과 자연스러운 대화 음성을 생성할 수 있으며, 사용자가 자유롭게 생성할 수 있도록 오디오 생성 및 편집 기능을 통합한 것으로 전해진다. 그들에게 필요한 오디오.
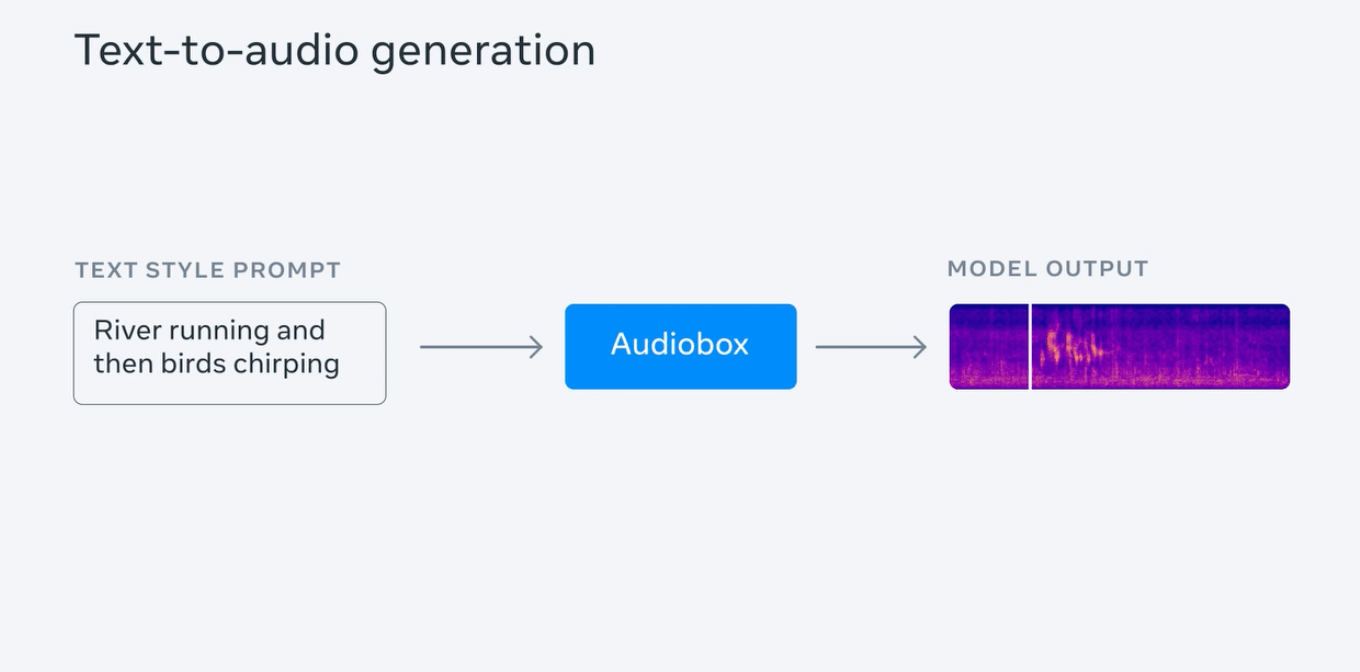
Meta는 고품질 오디오를 생성하려면 수많은 오디오 라이브러리와 깊은 도메인 지식이 필요하지만 이러한 리소스는 대중이 얻기 어렵다고 말했습니다. 회사는 사운드 생성의 문턱을 낮추고 누구나 쉽게 만들 수 있도록 이 모델을 출시했습니다. 다른 응용 프로그램 시나리오에 대한 비디오 및 게임 사운드 효과를 만듭니다.
IT House는 이 Audiobox 모델이 목표 오디오 생성을 용이하게 하기 위해 Voicebox의 "안내 사운드" 메커니즘을 기반으로 하며 "오디오 입력" 기능을 달성하기 위해 "흐름 일치" 확산 모델 생성 방법과 협력하여 멀티 생성을 수행한다는 사실을 발견했습니다. -레이어 오디오.
메타 테스트는 천둥소리와 함께 빗소리를 생성하고 "흐르는 물소리에 새소리가 난다", "젊은 여자가 고음과 빠른 리듬으로 말하는 것" 등 시연을 위한 일련의 프롬프트 문장을 입력합니다. .; 또한 감정("슬프고 느린")과 배경음(교회에 있는 것)이 포함된 음성을 생성하기 위해 사람들의 오디오 및 텍스트 프롬프트의 동시 입력을 테스트합니다.
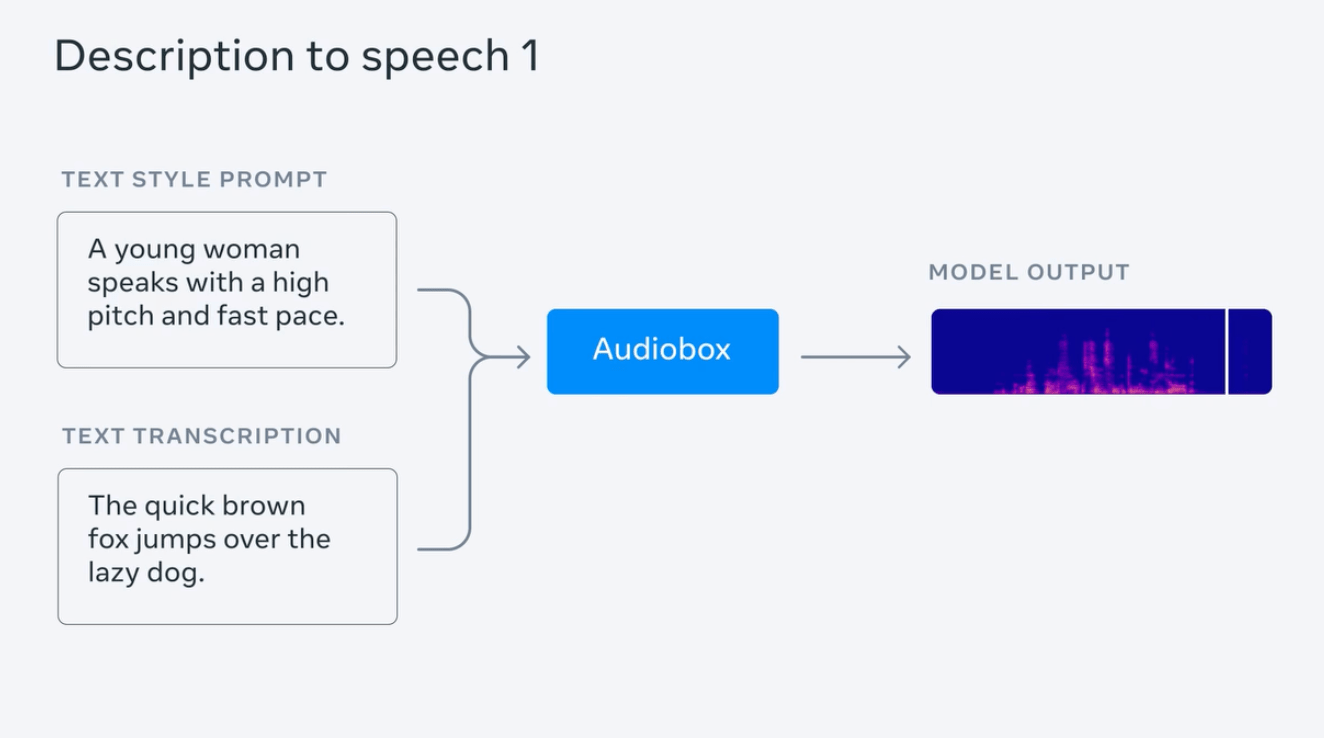
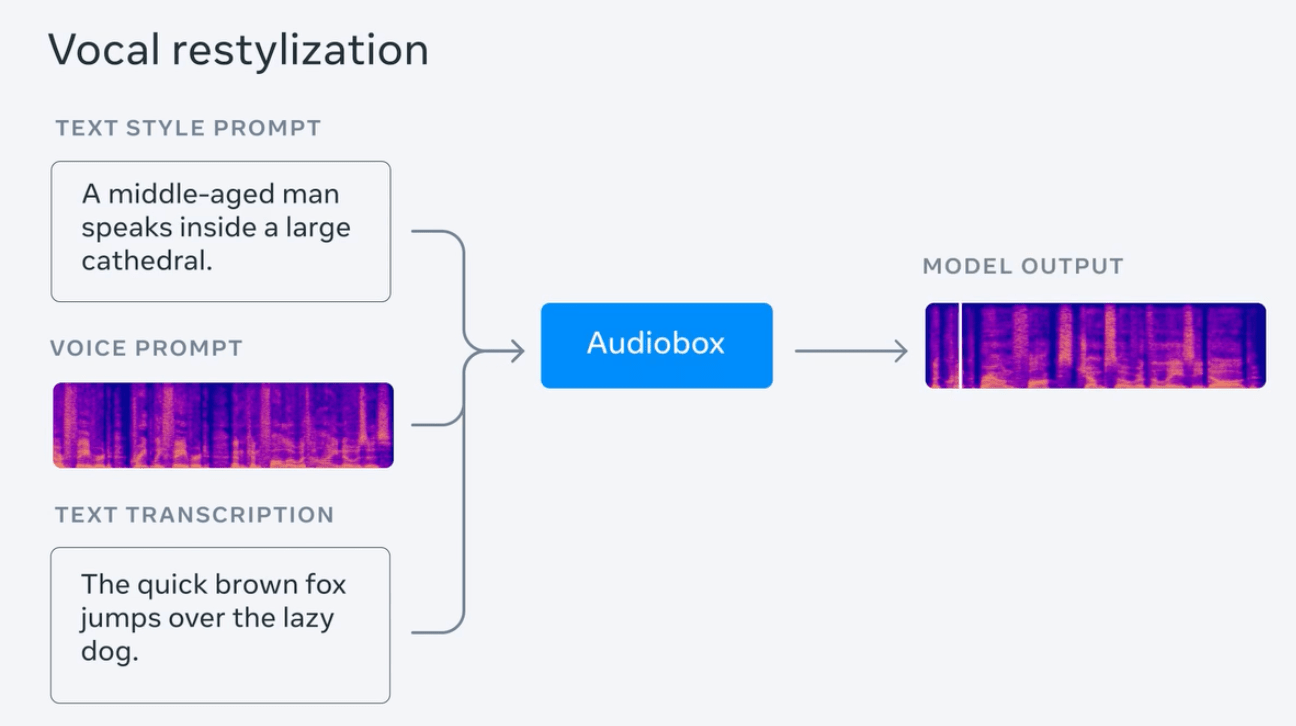
Meta는 Audiobox가 음질 및 "생성된 콘텐츠의 정확성" 측면에서 AudioLDM2, VoiceLDM 및 TANGO를 성공적으로 이겨 기존 최고의 오디오 생성 모델을 능가한다고 주장합니다.
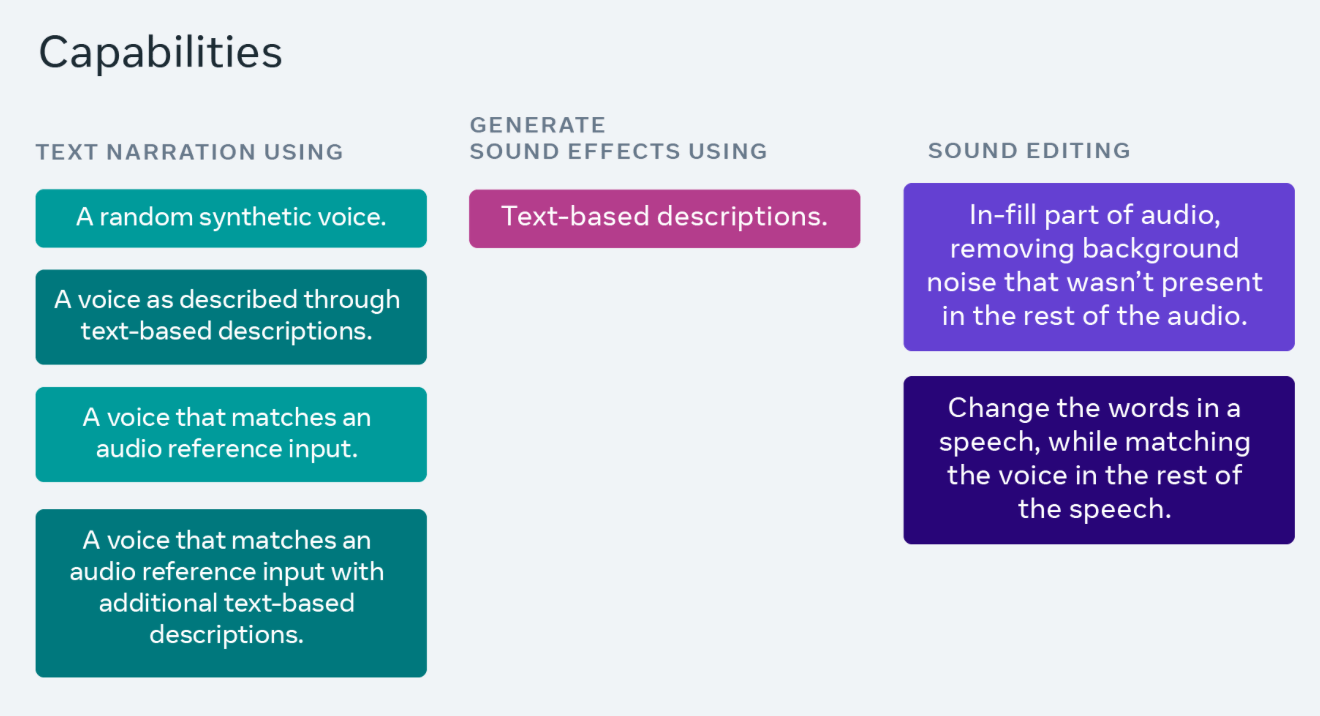
Audiobox는 현재 모델의 품질과 안전성을 테스트하기 위한 시험 사용을 위해 특정 연구원 및 학계에 공개되어 있습니다. Meta는 "모델을 몇 주 안에 대중에게 완전히 공개할 계획"이라고 주장합니다.
위 내용은 Meta, 음성 및 텍스트 동시 입력 지원하는 AI 오디오 모델 Audiobox 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!