
강력한 기본 엔진인 CoDi-2를 사용하여 모든 텍스트, 시각적, 오디오 혼합 생성, 멀티모달

- PHPz앞으로
- 2023-12-04 12:39:58865검색
연구원들은 CoDi-2가 포괄적인 멀티모달 기본 모델 개발 분야에서 획기적인 발전을 이루었다고 지적했습니다.
올해 5월 채플힐에 있는 노스캐롤라이나 대학과 마이크로소프트는 컴포저블 확산(Composable Diffusion, Composable Diffusion)을 제안했습니다. 확산(CoDi이라고도 함) 모델을 사용하면 하나의 모델이 여러 양식을 통합할 수 있습니다. CoDi는 단일 모드에서 단일 모드 생성을 지원할 뿐만 아니라 다중 조건부 입력 및 다중 모드 결합 생성도 수신할 수 있습니다.
최근 UC Berkeley, Microsoft Azure AI, Zoom 및 University of North Carolina at Chapel Hill의 많은 연구원들이 CoDi 시스템을 CoDi-2 버전으로 업그레이드했습니다

논문 주소: https:// arxiv.org/pdf/2311.18775.pdf
프로젝트 주소: https://codi-2.github.io/

원래 의미를 바꾸지 않고 내용을 다시 작성해야 합니다. 중국어로 다시 작성하면 원래 문장이 나타날 필요가 없습니다
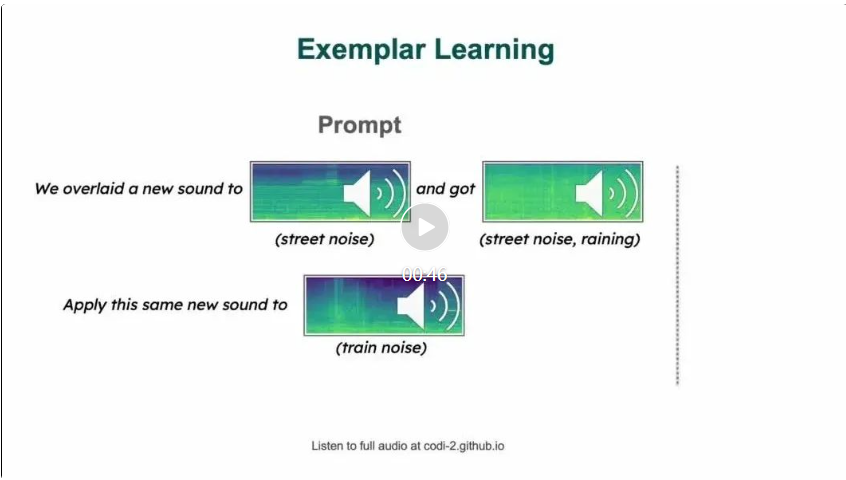
Zineng Tang의 논문에 따르면 CoDi-2는 복잡한 다중 모달 인터리빙된 상황별 지침을 따라 제로샷 또는 제로샷 또는 퓨샷 상호작용

이 링크는 이미지 출처입니다: https://twitter.com/ZinengTang/status/1730658941414371820
다양하고 인터랙티브한 멀티모달 대형 언어라고 할 수 있습니다 모델(MLLM)인 CoDi-2는 모든 입력-출력 모달 패러다임에서 상황별 학습, 추론, 채팅, 편집 및 기타 작업을 수행할 수 있습니다. CoDi-2는 인코딩 및 생성 중에 양식과 언어를 정렬함으로써 LLM이 복잡한 모달 인터리빙 지침 및 상황별 예제를 이해할 수 있을 뿐만 아니라 연속적인 기능 공간 내에서 합리적이고 일관된 다중 모달 출력을 자동 회귀적으로 생성할 수 있도록 합니다.
CoDi-2를 교육하기 위해 연구원들은 텍스트, 시각적 및 오디오 전반에 걸쳐 상황에 맞는 다중 모드 지침이 포함된 대규모 생성 데이터 세트를 구축했습니다. CoDi-2는 여러 라운드의 대화형 대화를 통해 상황별 학습, 추론 및 모든 모달 생성 조합과 같은 다중 모드 생성을 위한 다양한 제로샷 기능을 보여줍니다. 그 중 주제 중심의 이미지 생성, 시각적 변환, 오디오 편집 등의 작업에서 이전 도메인 특정 모델을 능가합니다.

인간과 CoDi-2 간의 여러 차례의 대화는 이미지 편집을 위한 상황에 맞는 다중 모드 지침을 제공합니다.
다시 작성해야 할 것은 모델 아키텍처입니다.
CoDi-2는 상황에 맞는 학습을 촉진하고 해당 텍스트를 생성하기 위해 특정 지침을 사용하여 상황에 맞는 텍스트, 이미지 및 오디오와 같은 다중 모드 입력을 처리하도록 설계되었습니다. , 이미지 및 오디오 출력. CoDi-2에 대해 다시 작성해야 할 사항은 다음과 같습니다. 모델 아키텍처 다이어그램은 다음과 같습니다.
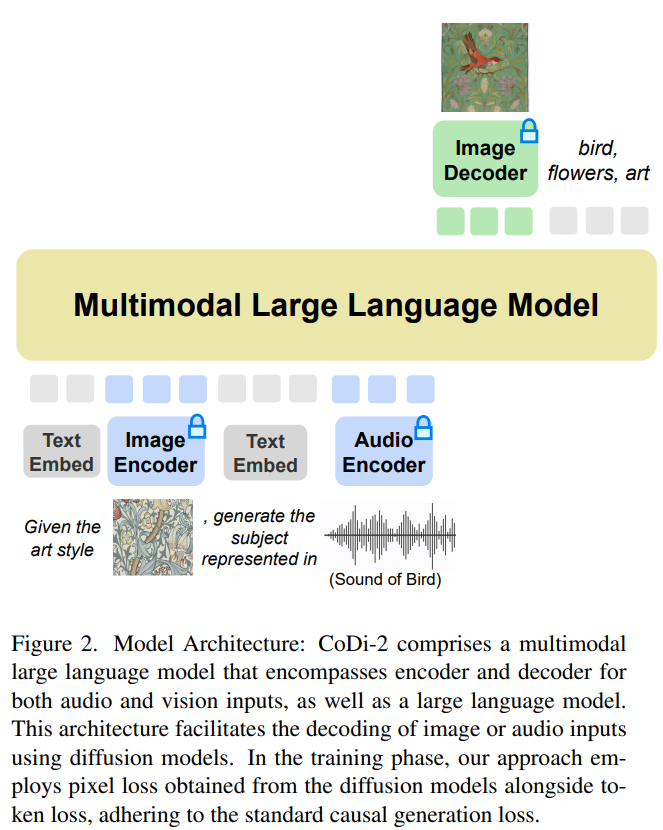
다중 모달 대형 언어 모델을 기본 엔진으로 사용
이 다대다 기본 모델은 인터리브 모달 입력을 소화하고 복잡한 지침(예: 다중 회전 대화, 상황별)을 이해하고 추론할 수 있습니다. 예), 다중 모드 디퓨저와 상호 작용합니다. 이 모든 것을 달성하기 위한 전제 조건은 강력한 기본 엔진입니다. 연구원들은 텍스트 전용 LLM에 대한 다중 모드 인식을 제공하기 위해 구축된 이 엔진으로 MLLM을 제안했습니다.
정렬된 다중 모달 인코더 매핑을 사용하여 연구원은 LLM이 모달 인터리브된 입력 시퀀스를 원활하게 인식하도록 할 수 있습니다. 구체적으로, 멀티모달 입력 시퀀스를 처리할 때 먼저 멀티모달 인코더를 사용하여 멀티모달 데이터를 특징 시퀀스에 매핑한 다음 '〈오디오〉 [오디오 기능 시퀀스와 같은 특수 토큰이 특징 시퀀스 앞뒤에 추가됩니다. " ] 〈/audio〉”.
다중 모드 생성의 기본은 MLLM입니다
연구원들은 확산 모델(DM)을 MLLM에 통합하여 다중 모드 출력을 생성할 것을 제안했습니다. 이 프로세스 동안 자세한 다중 모드 인터리브 지침과 프롬프트가 따랐습니다. 확산 모델의 훈련 목표는 다음과 같습니다.
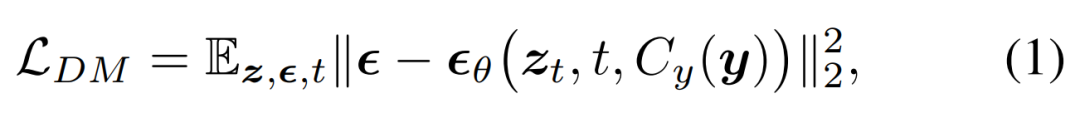
그런 다음 그들은 목표 출력 x를 합성하기 위해 확산 모델에 공급되는 조건부 특징 c = C_y(y)를 생성하도록 MLLM을 훈련할 것을 제안했습니다. 이러한 방식으로 확산 모델의 생성 손실은 MLLM을 훈련하는 데 사용됩니다.
작업 유형
모델은 다음 예제 작업 유형에서 강력한 기능을 보여줍니다. 이는 모델이 텍스트, 이미지, 오디오, 비디오 및 그 내용을 포함하여 상황에 따라 다중 모달 콘텐츠를 생성하거나 변환하도록 유도하는 고유한 접근 방식을 제공합니다. 조합
다시 작성된 내용은 다음과 같습니다. 1. 제로 샘플 추론. 제로샷 추론 작업에서는 모델이 이전 예제 없이 새로운 콘텐츠를 추론하고 생성해야 합니다.
2. 하나 또는 몇 개의 샘플 프롬프트는 유사한 작업을 수행하기 전에 배울 수 있는 하나 이상의 예를 모델에 제공합니다. 이러한 접근 방식은 모델이 한 이미지에서 다른 이미지로 학습한 개념을 적용하거나 제공된 예에 설명된 스타일을 이해하여 새로운 작품을 만드는 작업에서 분명하게 드러납니다.
실험 및 결과
모델 설정
이 문서의 모델 구현은 Llama2, 특히 Llama-2-7b-chat-hf를 기반으로 합니다. 연구원들은 이미지, 비디오, 오디오, 텍스트, 깊이, 열 및 IMU 모드 인코더를 정렬한 ImageBind를 사용했습니다. 우리는 ImageBind를 사용하여 이미지 및 오디오 기능을 인코딩하고 이를 다층 퍼셉트론(MLP)을 통해 LLM(Llama-2-7b-chat-hf)의 입력 차원에 투영합니다. MLP는 선형 매핑, 활성화, 정규화 및 다른 선형 매핑으로 구성됩니다. LLM이 이미지 또는 오디오 기능을 생성하면 이를 다른 MLP를 통해 ImageBind 기능 차원으로 다시 투영합니다. 이 기사의 이미지 확산 모델은 StableDiffusion2.1(stabilityai/stable-diffusion-2-1-unclip), AudioLDM2 및 zeroscope v2를 기반으로 합니다.
더 높은 충실도의 원본 입력 이미지나 오디오를 얻기 위해 연구자들은 이를 확산 모델에 입력하고 확산 노이즈를 연결하여 특징을 생성합니다. 이 방법은 매우 효과적입니다. 입력 콘텐츠의 지각적 특성을 최대한 보존할 수 있으며, 새로운 콘텐츠를 추가하거나 스타일 및 기타 명령 편집을 변경할 수 있습니다.
다시 작성해야 하는 콘텐츠는 다음과 같습니다. 이미지 생성 평가
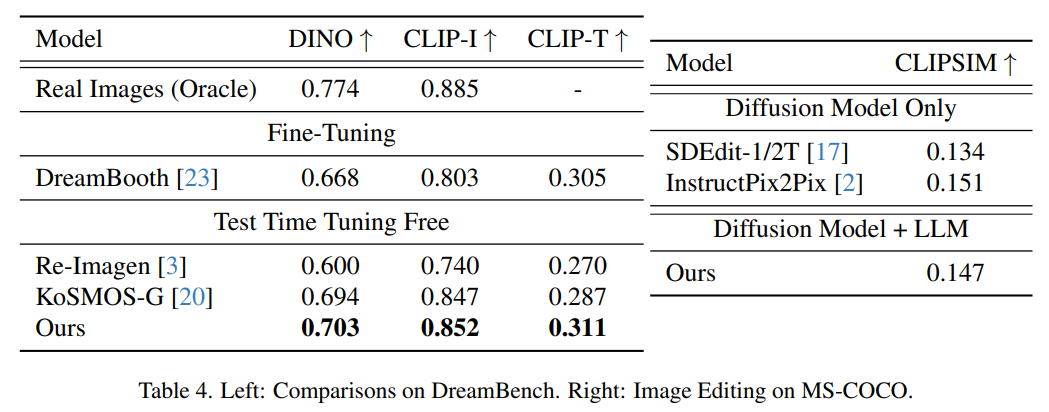
다음 그림은 드림벤치의 주제 중심 이미지 생성 평가 결과와 MSCOCO의 FID 점수를 보여줍니다. 본 논문의 방법은 매우 경쟁적인 제로샷 성능을 달성하여 알려지지 않은 새로운 작업에 대한 일반화 능력을 보여줍니다.
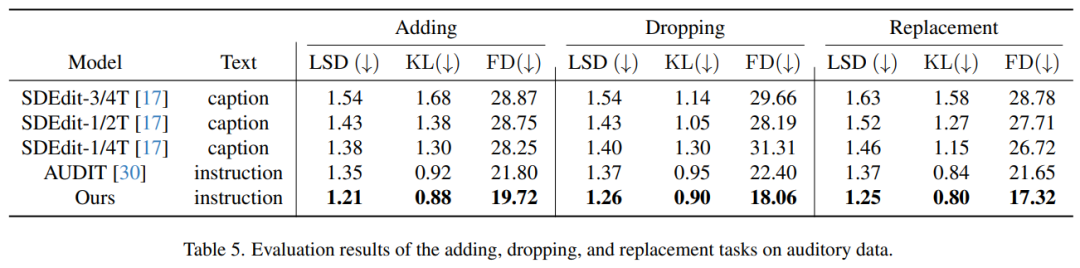
오디오 생성 평가
표 5는 오디오 처리 작업, 즉 오디오 트랙의 요소 추가, 삭제 및 교체에 대한 평가 결과를 보여줍니다. 표를 보면 우리의 방법이 이전 방법에 비해 우수한 성능을 보인다는 것을 알 수 있습니다. 특히, 세 가지 편집 작업 모두 LSD(로그 스펙트럼 거리), KL(Kullback-Leibler) 발산 및 FD(Fréchet 거리) 등 모든 지표에서 가장 낮은 점수를 달성했습니다.
자세한 기술을 알아보려면 원본 기사를 읽어보세요. 세부.
위 내용은 강력한 기본 엔진인 CoDi-2를 사용하여 모든 텍스트, 시각적, 오디오 혼합 생성, 멀티모달의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
관련 기사
더보기- 기술을 통해 패션 산업에 힘을 실어주고 푸텐구가 '베이 지역 패션 본부 센터'를 건립하도록 돕습니다.
- 럭스쉐어 프리시전(Luxshare Precision): 휴머노이드 로봇 등 신흥 산업 진출을 위한 성숙한 역량과 사업 기반을 갖추고 있다.
- 산업정보기술부, 뇌-컴퓨터 인터페이스 산업 발전 가속화 발표
- 우리나라 컴퓨팅 산업 규모는 2조 6천억 위안에 달하며, 지난 6년간 범용 서버는 2,091만 대, AI 서버는 82만 대가 출하됐다.
- 2023년 인공 지능 컴퓨팅 컨퍼런스 AICC가 베이징에서 개최되어 대규모 모델과 지능형 컴퓨팅 성능에 대한 업계의 뜨거운 논의에 중점을 두었습니다.