



오늘은 머신러닝에서 흔히 볼 수 있는 비지도 학습 클러스터링 방법을 공유하고자 합니다
비지도 학습에서는 데이터에 라벨이 없으므로 비지도 학습에서 해야 할 일은 다음과 같습니다. 알고리즘에 입력하면 알고리즘은 데이터에 내재된 일부 구조를 찾을 수 있습니다. 아래 그림의 데이터를 통해 찾을 수 있는 구조 중 하나는 데이터 세트의 포인트가 두 개의 별도 포인트 세트로 나눌 수 있다는 것입니다. .(클러스터), 이러한 클러스터(cluster)를 순환할 수 있는 알고리즘을 클러스터링 알고리즘이라고 합니다.
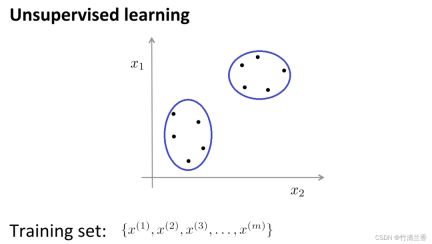
클러스터링 알고리즘 적용
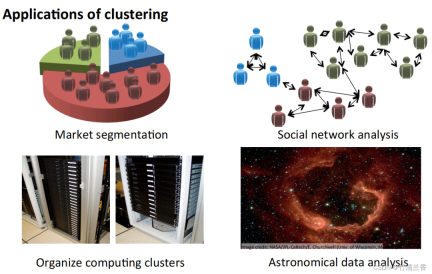
- 시장 세분화: 시장에 따라 데이터베이스의 고객 정보를 그룹화하여 다양한 시장에 따라 별도의 판매 또는 서비스 개선을 달성합니다.
- 소셜 네트워크 분석: 가장 자주 연락하는 사람과 가장 자주 연락하는 사람에게 이메일을 보내 가까운 그룹을 찾으세요.
- 컴퓨터 클러스터 구성: 데이터 센터에서 컴퓨터 클러스터는 종종 함께 작동하며 리소스 재구성, 네트워크 재배치, 데이터 센터 최적화 및 데이터 통신에 사용될 수 있습니다.
- 은하수의 구성을 이해하세요. 이 정보를 사용하여 천문학에 대해 알아보세요.
군집 분석의 목표는 관측치를 그룹("군집")으로 나누어 동일한 군집에 할당된 관측치 간의 쌍별 차이가 다른 군집에 있는 관측치 간의 차이보다 작은 경향이 있도록 하는 것입니다. 클러스터링 알고리즘은 조합 알고리즘, 하이브리드 모델링 및 패턴 검색의 세 가지 유형으로 구분됩니다.
몇 가지 일반적인 클러스터링 알고리즘은 다음과 같습니다.
- K-평균 클러스터링
- 계층적 클러스터링
- 집합 클러스터링
- 친화성 전파
- 평균 이동 클러스터링
- K-평균을 이분화
- DBSCAN
- 광학
- 자작나무
K-평균
K-평균 알고리즘은 현재 가장 널리 사용되는 클러스터링 방법 중 하나입니다.
K-수단은 1957년 Bell Labs의 Stuart Lloyd가 제안했습니다. 원래는 펄스 코드 변조에 사용되었으며 1982년이 되어서야 이 알고리즘이 대중에게 발표되었습니다. 1965년에 Edward W. Forgy가 동일한 알고리즘을 발표했기 때문에 K-Means를 Lloyd-Forgy라고도 합니다.
클러스터링 문제는 일반적으로 레이블이 없는 데이터 세트 세트를 처리해야 하며 이러한 데이터를 밀접하게 관련된 하위 세트 또는 클러스터로 자동으로 나누는 알고리즘이 필요합니다. 현재 가장 인기 있고 널리 사용되는 클러스터링 알고리즘은 K-평균 알고리즘입니다.
K-평균 알고리즘에 대한 직관적인 이해:
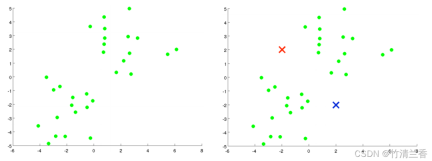
레이블이 지정되지 않은 데이터 세트가 있다고 가정합니다(그림 왼쪽). 위), 이를 두 개의 클러스터로 나누고 싶다면 이제 K-평균 알고리즘을 실행하십시오. 구체적인 작업은 다음과 같습니다. 데이터를 두 가지 범주로 나눕니다)(위 그림의 오른쪽). 이 두 점을 군집 중심이라고 합니다.
- 두 번째 단계는 K-평균 알고리즘의 내부 루프를 수행하는 것입니다. K-평균 알고리즘은 두 가지 작업을 수행하는 반복 알고리즘입니다. 첫 번째는 클러스터 할당이고 두 번째는 중심 이동입니다.
- 내부 루프의 첫 번째 단계는 클러스터 할당을 수행하는 것입니다. 즉, 각 샘플을 순회한 다음 각 포인트에서 클러스터 중심까지의 거리를 기준으로 각 포인트를 다른 클러스터 중심에 할당합니다. 이 경우는 데이터 세트를 반복하고 각 지점을 빨간색 또는 파란색으로 색칠하는 것입니다.
내부 루프의 두 번째 단계는 빨간색과 파란색 클러스터 중심이 자신이 속한 포인트의 평균 위치로 이동하도록 클러스터 중심을 이동하는 것입니다.
새 클러스터 중심에 따라 모든 포인트를 만듭니다. 클러스터 할당은 거리를 기준으로 이루어지며, 이 과정은 반복에 따라 클러스터 중심의 위치가 더 이상 변하지 않고, 포인트의 색상도 더 이상 변하지 않을 때까지 반복됩니다. 이때 K-means는 Aggregation을 완료했다고 할 수 있다. 이 알고리즘은 데이터에서 두 개의 클러스터를 찾는 데 매우 효과적입니다
간단하고 이해하기 쉽고, 계산 속도가 빠르며, 대규모 데이터 세트에 적합합니다. 계층적 군집화는 샘플 세트를 특정 수준에 따라 군집화하는 작업입니다. 여기서 레벨은 실제로 일정한 거리에 대한 정의를 의미합니다 클러스터링의 궁극적인 목적은 분류 수를 줄이는 것이므로 리프 노드에서 루트 노드로 점진적으로 접근하는 덴드로그램 프로세스와 동작이 유사합니다. 이러한 종류의 동작은 "상향식"이라고도 합니다 더 일반적으로 계층적 클러스터링은 초기화된 클러스터를 트리 노드로 처리합니다. 각 반복 단계에서 두 개의 유사한 클러스터가 병합되어 새로운 대규모 클러스터가 생성됩니다. 이 프로세스는 마지막으로 하나의 클러스터(루트 노드)만 남을 때까지 반복됩니다. 계층적 클러스터링 전략은 집계(상향식)와 분할(하향식)이라는 두 가지 기본 패러다임으로 나뉩니다. 계층적 클러스터링의 반대는 DIANA(분할 분석)라고도 알려진 분할 클러스터링으로, 동작 프로세스가 "하향식"입니다. K-평균 알고리즘의 결과는 검색하기 위해 선택한 클러스터에 따라 달라집니다. . 클래스 수 할당 및 시작 구성. 대조적으로, 계층적 클러스터링 방법에는 그러한 사양이 필요하지 않습니다. 대신, 사용자는 두 관측치 세트 간의 쌍별 비유사성을 기반으로 관측치 그룹 간의 비유사성 척도를 지정해야 합니다. 이름에서 알 수 있듯이 계층적 클러스터링 방법은 다음 하위 수준의 클러스터를 병합하여 각 수준의 클러스터가 생성되는 계층적 표현을 생성합니다. 가장 낮은 수준에서 각 클러스터에는 하나의 관측치가 포함됩니다. 최고 수준에서는 하나의 클러스터에만 모든 데이터가 포함됩니다.
이동 클러스터링은 밀도 기반 비모수적 클러스터링 알고리즘으로, 기본 아이디어는 데이터 포인트 밀도가 가장 높은 위치("로컬 최대값" 또는 "피크"라고 함)를 찾는 것입니다. , 데이터에서 클러스터를 식별합니다. 이 알고리즘의 핵심은 각 데이터 포인트의 국소 밀도를 추정하고, 밀도 추정 결과를 사용하여 데이터 포인트의 이동 방향과 거리를 계산하는 것입니다. K-평균 이등분은 K-평균 알고리즘을 기반으로 하는 계층적 클러스터링 알고리즘의 기본 아이디어는 모든 데이터 포인트를 클러스터로 나눈 다음 클러스터를 두 개의 하위 클러스터로 나누는 것입니다. , 각 하위 클러스터에 별도로 K-Means 알고리즘을 적용하고 미리 정해진 클러스터 수에 도달할 때까지 이 과정을 반복합니다. 알고리즘은 먼저 모든 데이터 포인트를 초기 클러스터로 처리한 다음 K-Means 알고리즘을 클러스터에 적용하고 클러스터를 두 개의 하위 클러스터로 나누고 각 하위 클러스터에 대해 SSE(제곱 오류 합계)를 계산합니다. 무리. 그런 다음 오차 제곱합이 가장 큰 하위 클러스터를 선택하여 다시 두 개의 하위 클러스터로 나누는 과정을 미리 정해진 클러스터 수에 도달할 때까지 반복합니다. 밀도 기반 공간 클러스터링 알고리즘인 DBSCAN(Density-Based Spatial Clustering of Application with Noise)은 노이즈가 있는 일반적인 클러스터링 방법입니다. 밀도 방법은 거리 특성에 의존하지 않지만 의존적입니다. 밀도에. 따라서 거리 기반 알고리즘은 "구형" 클러스터만 찾을 수 있다는 단점을 극복할 수 있습니다 DBSCAN 알고리즘의 핵심 아이디어는 다음과 같습니다. 특정 데이터 포인트에 대해 밀도가 특정 임계값에 도달하면 해당 클러스터는 클러스터에서는 그렇지 않으면 노이즈 지점으로 간주됩니다. OPTICS(Ordering Points To 식별 the Clustering Structure)는 자동으로 클러스터 수를 결정하고 모든 형태의 클러스터를 검색할 수 있으며 노이즈가 있는 데이터를 처리할 수 있는 밀도 기반 클러스터링 알고리즘입니다. OPTICS 알고리즘의 핵심 아이디어는 주어진 데이터 포인트와 다른 포인트 사이의 거리를 계산하여 밀도에 대한 도달 가능성을 결정하고 밀도 기반 거리 맵을 구성하는 것입니다. 그런 다음 이 거리 지도를 스캔하면 자동으로 클러스터 수를 결정하고 각 클러스터를 나눕니다 장점: 장점:
K-Means 알고리즘의 장점:
단점:
계층적 군집화
거리 및 규칙 유사성은 정의하기 쉽고 제한이 거의 없습니다.
다시 작성된 내용은 다음과 같습니다. Agglomerative Clustering은 각 데이터 포인트를 초기 클러스터로 처리하고 점차적으로 병합하는 상향식 클러스터링 알고리즘입니다. 중지 조건이 충족될 때까지 더 큰 클러스터를 형성합니다. 이 알고리즘에서 각 데이터 포인트는 처음에는 별도의 클러스터로 처리된 다음 모든 데이터 포인트가 하나의 큰 클러스터로 병합될 때까지 클러스터가 점차적으로 병합됩니다.
장점:
단점:
계산 복잡도가 높으며, 특히 대규모 데이터 세트를 처리할 때는 많은 컴퓨팅 리소스와 저장 공간이 필요합니다. 이 알고리즘은 초기 클러스터 선택에도 민감하므로 클러스터링 결과가 달라질 수 있습니다.
Affinity Propagation은 그래프 이론에 기반한 클러스터링 알고리즘으로, "모범"을 식별하는 것을 목표로 합니다. "(대표점) 및 "클러스터"(클러스터)를 데이터에 포함합니다. K-Means와 같은 기존 군집화 알고리즘과 달리 Affinity Propagation은 군집 수를 미리 지정할 필요가 없고 군집 중심을 무작위로 초기화할 필요도 없으며 대신 데이터 포인트 간의 유사성을 계산하여 최종 군집화 결과를 얻습니다.
장점:
단점:
평균 이동 클러스터링
장점:
단점:
K-평균 이등분
장점:
단점:
DBSCAN
장점:
단점:
OPTICS
자동으로 클러스터 수를 결정하고 모든 모양의 클러스터를 처리할 수 있으며 가능합니다. 시끄러운 데이터를 효과적으로 처리합니다.
계산 복잡도가 높으며, 특히 대규모 데이터 세트를 처리할 때는 많은 컴퓨팅 리소스와 저장 공간이 필요합니다.
BIRCH(Balanced Iterative Reduction and Hierarchical Clustering)는 대규모 데이터 세트를 효율적으로 처리하고 모든 형태의 클러스터에 대해 좋은 결과를 얻을 수 있는 계층적 클러스터링 기반 클러스터링 알고리즘입니다. BIRCH 알고리즘은 데이터 세트의 계층적 클러스터링을 통해 데이터의 크기를 점진적으로 줄이고 최종적으로 클러스터 구조를 얻는 것입니다. BIRCH 알고리즘은 CF 트리라고 하는 B-트리와 유사한 구조를 사용합니다. 이 구조는 하위 클러스터를 빠르게 삽입 및 삭제할 수 있으며 자동으로 균형을 맞춰 클러스터의 품질과 효율성을 보장할 수 있습니다
대규모 데이터 세트를 빠르게 처리할 수 있으며 임의 모양의 클러스터에 대해 좋은 결과를 얻을 수 있습니다.
이 알고리즘은 시끄러운 데이터와 이상값에 대한 내결함성도 우수합니다.
밀도 차이가 큰 데이터 세트의 경우 클러스터링 결과가 좋지 않을 수 있습니다.
고차원 데이터 세트에 대한 효과도 다른 알고리즘만큼 좋지 않습니다. .
위 내용은 비지도 기계 학습을 탐색하기 위한 9가지 클러스터링 알고리즘의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 생성 엔진 최적화에 대한 비즈니스 리더 안내서 (GEO)May 03, 2025 am 11:14 AM
생성 엔진 최적화에 대한 비즈니스 리더 안내서 (GEO)May 03, 2025 am 11:14 AMGoogle은 이러한 변화를 이끌고 있습니다. "AI 개요"기능은 이미 10 억 명 이상의 사용자에게 제공되며, 누군가가 링크를 클릭하기 전에 완전한 답변을 제공합니다. [^2] 다른 플레이어들도 빨리지면을 얻고 있습니다. Chatgpt, Microsoft Copilot 및 PE
 이 스타트 업은 AI 에이전트를 사용하여 악의적 인 광고와 가장하는 계정과 싸우고 있습니다.May 03, 2025 am 11:13 AM
이 스타트 업은 AI 에이전트를 사용하여 악의적 인 광고와 가장하는 계정과 싸우고 있습니다.May 03, 2025 am 11:13 AM2022 년에 그는 사회 공학 방어 스타트 업 도플을 설립하여 바로 그렇게했습니다. 그리고 사이버 범죄자들이 공격을 터보 차지하기 위해 더욱 진보 된 AI 모델을 활용함에 따라 Doppel의 AI 시스템은 비즈니스가 더 빠르게 빠르게 그리고 더 빠르게 그리고 규모로 싸우는 데 도움이되었습니다.
 세계 모델이 생성 AI 및 LLM의 미래를 근본적으로 재구성하는 방법May 03, 2025 am 11:12 AM
세계 모델이 생성 AI 및 LLM의 미래를 근본적으로 재구성하는 방법May 03, 2025 am 11:12 AMVoila는 적합한 세계 모델과 상호 작용하여 생성 AI 및 LLM을 실질적으로 향상시킬 수 있습니다. 그것에 대해 이야기합시다. 혁신적인 AI 혁신에 대한이 분석은
 2050 년 5 월 : 우리는 무엇을 축하하기 위해 떠났습니까?May 03, 2025 am 11:11 AM
2050 년 5 월 : 우리는 무엇을 축하하기 위해 떠났습니까?May 03, 2025 am 11:11 AM노동당 2050 년. 전국의 공원은 전통적인 바베큐를 즐기는 가족들로 가득 차고 향수를 불러 일으키는 퍼레이드는 도시 거리를 통해 바람을 피 웁니다. 그러나 축하 행사는 이제 박물관과 같은 품질을 가지고 있습니다.
 98% 정확한 것을 들어 본 적이없는 Deepfake 탐지기May 03, 2025 am 11:10 AM
98% 정확한 것을 들어 본 적이없는 Deepfake 탐지기May 03, 2025 am 11:10 AM이 긴급하고 불안정한 트렌드를 해결하기 위해 2025 년 2 월 Tem Journal의 동료 검토 기사는 기술 심해가 현재 어디에 있는지에 대한 가장 명확하고 데이터 중심 평가 중 하나를 제공합니다. 연구원
 양자 재능 전쟁 : 숨겨진 위기 위협 기술 기술May 03, 2025 am 11:09 AM
양자 재능 전쟁 : 숨겨진 위기 위협 기술 기술May 03, 2025 am 11:09 AM신약을 공식화하는 데 걸리는 시간을 크게 줄이는 것부터 녹색 에너지 생성에 이르기까지 기업이 새로운 지평을 열 수있는 큰 기회가있을 것입니다. 그래도 큰 문제가 있습니다. 기술을 가진 사람들이 심각하게 부족합니다.
 프로토 타입 :이 박테리아는 전기를 생성 할 수 있습니다May 03, 2025 am 11:08 AM
프로토 타입 :이 박테리아는 전기를 생성 할 수 있습니다May 03, 2025 am 11:08 AM몇 년 전, 과학자들은 특정 종류의 박테리아가 산소를 섭취하기보다는 전기를 생성하여 호흡하는 것처럼 보이지만, 그렇게 한 방법은 미스터리였습니다. 저널 Cell에 발표 된 새로운 연구는 이런 일이 어떻게 발생하는지 식별합니다 : Microb
 AI 및 사이버 보안 : 새로운 행정부의 100 일 계산May 03, 2025 am 11:07 AM
AI 및 사이버 보안 : 새로운 행정부의 100 일 계산May 03, 2025 am 11:07 AM이번 주 RSAC 2025 컨퍼런스에서 Snyk은 All-Star 라인업을 특징으로하는 AI, AI, Policy & Cybersecurity Collide "라는 제목의 적시 패널을 주최했습니다. Jen Easterly, 전 CISA 디렉터; Nicole Perlroth, 전 기자이자 Partne


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

Dreamweaver Mac版
시각적 웹 개발 도구

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

