
소규모, 고효율: DeepMind, 다중 모드 솔루션 Mirasol 3B 출시

- PHPz앞으로
- 2023-11-28 14:19:291058검색
다중 모드 학습이 직면한 주요 과제 중 하나는 텍스트, 오디오, 비디오와 같은 이질적인 양식을 융합해야 한다는 것입니다. 다중 모드 모델은 다양한 소스의 신호를 결합해야 합니다. 그러나 이러한 방식은 서로 다른 특성을 갖고 있어 단일 모델을 통해 결합하기가 어렵습니다. 예를 들어, 비디오와 텍스트의 샘플링 속도는 다릅니다
최근 Google DeepMind의 연구팀은 다중 모드 모델을 여러 개의 독립적이고 특수화된 자동 회귀 모델로 분리하여 다양한 모드 입력의 특성에 따라 처리했습니다.
구체적으로 연구에서는 Mirasol3B라는 다중 모드 모델을 제안합니다. Mirasol3B는 오디오 및 비디오를 위한 시간 동기화 자동 회귀 구성 요소와 상황별 양식을 위한 자동 회귀 구성 요소로 구성됩니다. 이러한 양식은 반드시 시간적으로 정렬될 필요는 없지만 순차적으로 배열됩니다

문서 주소: https://arxiv.org/abs/2311.05698
Mirasol3B는 다중 모드 벤치마크 수준에서 SOTA를 달성하여 대형 모델을 능가합니다. Mirasol3B는 보다 컴팩트한 표현을 학습하고, 오디오-비디오 기능 표현의 시퀀스 길이를 제어하고, 시간적 대응을 기반으로 모델링함으로써 다중 모드 입력의 높은 계산 요구 사항을 효과적으로 충족할 수 있습니다.
방법 소개
Mirasol3B는 자동 회귀 모델링이 시간 정렬 양식(예: 오디오, 비디오)에 대한 자동 회귀 구성 요소로 분리되고 시간 정렬된 비 자동 회귀 구성 요소에 대한 오디오-비디오-텍스트 다중 모달 모델입니다. 상황에 맞는 양식(예: 텍스트) Mirasol3B는 교차 어텐션 가중치를 사용하여 이러한 구성 요소의 학습 프로세스를 조정합니다. 이러한 분리는 모델 내의 매개변수 분포를 보다 합리적으로 만들고 양식(비디오 및 오디오)에 충분한 용량을 할당하며 전체 모델을 더 가볍게 만듭니다.
그림 1에 표시된 것처럼 Mirasol3B는 자동 회귀 구성 요소와 입력 조합 구성 요소라는 두 가지 주요 학습 구성 요소로 구성됩니다. 그중 자동회귀 구성요소는 시기적절한 입력 조합을 위해 비디오 및 오디오와 같은 다중 모드 입력을 거의 동시에 처리하도록 설계되었습니다


콘텐츠를 다시 작성할 때 원래 의미는 변경되지 않고 유지되어야 하며, 언어를 중국어로 바꿔보세요. 이 연구에서는 시간적으로 정렬된 양식을 시간 세그먼트로 분할하고 시간 세그먼트에서 오디오-비디오 결합 표현을 학습할 것을 제안합니다. 구체적으로 본 연구에서는 "Combiner"라는 모달 공동 특징 학습 메커니즘을 제안합니다. "Combiner"는 동일한 기간 내의 모달 특징을 융합하여 보다 컴팩트한 표현을 생성합니다
"Combiner"는 원본 모달 입력에서 기본 시공간 표현을 추출하고 비디오의 동적 특성을 캡처한 후 공통 모델과 결합할 수 있습니다. 다양한 속도로 다중 모드 입력을 수신하고 긴 비디오를 처리할 때 우수한 성능을 발휘합니다.
"Combiner"는 모달 표현이 효율적이고 유익해야 한다는 요구 사항을 효과적으로 충족합니다. 비디오 및 기타 동시 양식의 이벤트와 활동을 완전히 다룰 수 있으며 후속 자동 회귀 모델에서 장기적인 종속성을 학습하는 데 사용할 수 있습니다.

비디오 및 오디오 신호를 처리하고 더 긴 비디오/오디오 입력에 적응하기 위해 (거의 시간에 따라 동기화된) 작은 조각으로 분할된 다음 "Combiner"를 통해 공동 시청각 표현을 학습합니다. . 두 번째 구성 요소는 컨텍스트 또는 종종 여전히 연속적인 전역 텍스트 정보와 같이 시간적으로 잘못 정렬된 신호를 처리합니다. 또한 자동 회귀적이며 결합된 잠재 공간을 교차 주의 입력으로 사용합니다.
학습 구성 요소에는 비디오와 오디오가 포함되어 있으며 매개 변수는 3B이고 오디오가 없는 구성 요소는 2.9B입니다. 그 중 대부분의 매개 변수는 오디오 및 비디오 자동 회귀 모델에 사용됩니다. Mirasol3B는 일반적으로 128프레임 비디오를 처리하며 파티션 설계 및 "Combiner" 모델 아키텍처로 인해 더 많은 프레임을 추가하거나 블록 크기 및 수를 늘리는 등의 이유로 512프레임과 같은 더 긴 비디오도 처리할 수 있습니다. 매개변수만 약간 증가하여 긴 동영상에 더 많은 매개변수와 더 큰 메모리가 필요한 문제를 해결합니다.
실험 및 결과
이 연구에서는 표준 VideoQA 벤치마크, 긴 비디오 VideoQA 벤치마크 및 오디오+비디오 벤치마크에서 Mirasol3B를 평가했습니다.
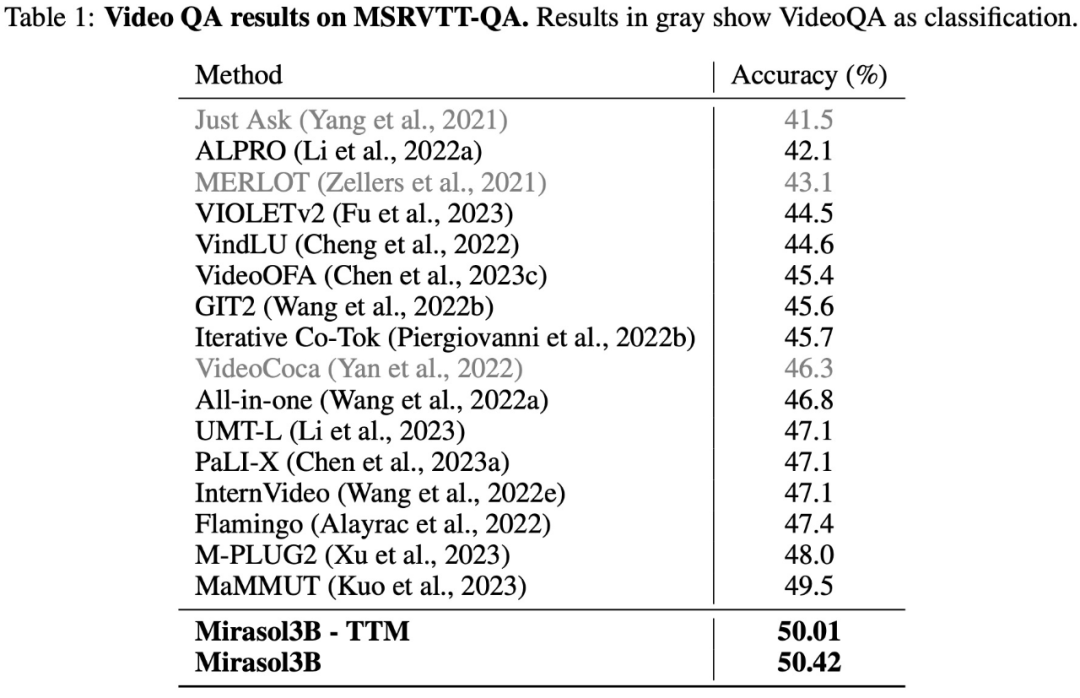
VideoQA 데이터 세트 MSRVTTQA의 테스트 결과는 아래 표 1에 나와 있습니다. Mirasol3B는 현재 SOTA 모델은 물론 PaLI-X 및 Flamingo와 같은 대형 모델도 능가합니다.
긴 동영상 질문과 답변의 경우 본 연구에서는 ActivityNet-QA 및 NExTQA 데이터 세트에서 Mirasol3B를 테스트하고 평가했습니다. 결과는 아래 표 2에 나와 있습니다.

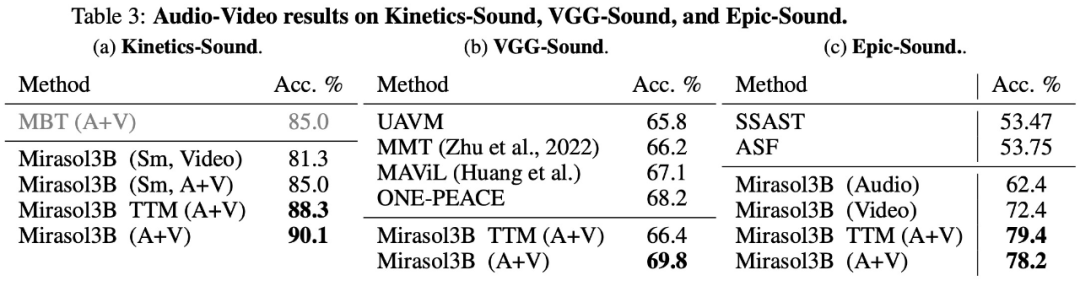
에서는 결국 오디오-비디오 벤치마킹을 위해 KineticsSound, VGG-Sound 및 Epic-Sound 연구를 선택하고 개방형 평가를 채택했습니다. 실험 결과는 아래 표 3에 나와 있습니다.
관심 있는 독자는 논문의 원문을 읽고 연구 내용에 대해 자세히 알아볼 수 있습니다.
위 내용은 소규모, 고효율: DeepMind, 다중 모드 솔루션 Mirasol 3B 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!