
퓨샷 학습에서는 텍스트 분류를 위해 SetFit을 사용합니다.

- 王林앞으로
- 2023-11-28 11:14:281782검색
번역가 | Chen Jun
Reviewer | Chonglou
이번 글에서는 "퓨샷(Few-shot) 학습"에 대해 소개하겠습니다. , 텍스트 분류에 널리 사용되는 SetFit 방법에 중점을 둡니다.

전통적인 기계 학습(ML)
지도(Supervised) 기계 학습에서는 모델을 연마하기 위해 대규모 데이터 세트를 모델 훈련에 사용합니다. 정확하게 예측하세요. 훈련 과정을 마친 후에는 테스트 데이터를 사용하여 모델의 예측 결과를 얻을 수 있습니다. 그러나 이러한 전통적인 지도 학습 접근 방식에는 심각한 단점이 있습니다. 즉, 오류가 없는 대규모 교육 데이터 세트가 필요하다는 것입니다. 그러나 모든 분야에서 오류 없는 데이터 세트를 제공할 수 있는 것은 아닙니다. 그래서 '퓨샷 학습(few-shot learning)'이라는 개념이 탄생하게 됐다.
Sentence Transformer 미세 조정(SetFit)을 살펴보기 전에 자연어 처리(자연어 처리, NLP)를 간략하게 검토해야 합니다. )의 중요한 측면은 "퓨샷 학습"입니다.
퓨샷 학습
퓨샷 학습이란 제한된 훈련 데이터 세트를 사용하여 모델을 훈련하는 것을 의미합니다. 모델은 지원 세트라고 하는 이러한 작은 컬렉션에서 지식을 얻을 수 있습니다. 이러한 유형의 학습은 학습 데이터의 유사점과 차이점을 인식하도록 퓨샷 모델을 가르치는 것을 목표로 합니다. 예를 들어 모델에게 주어진 이미지를 고양이나 개로 분류하도록 지시하는 대신, 다양한 동물 간의 공통점과 차이점을 파악하도록 지시합니다. 보시다시피, 이 접근 방식은 입력 데이터의 유사점과 차이점을 이해하는 데 중점을 둡니다. 따라서 이를 메타러닝(meta-learning) 또는 학습을 위한 학습(learning-to-learn)이라고도 합니다.
Few-shot 학습 지원 세트를 k to (k-way) n 샘플(n-shot) 학습이라고도 부른다는 점은 언급할 가치가 있습니다. 그 중 "k"은 지원 세트의 카테고리 수를 나타냅니다. 예를 들어 이진 분류에서 k 는 2과 같습니다. 그리고 "n"은 지원 세트의 각 카테고리에 사용 가능한 샘플 수를 나타냅니다. 예를 들어 긍정적인 분류에 10 데이터 포인트가 있고 부정적인 분류에도 10 데이터 포인트가 있는 경우 n은 10과 같습니다. 요약하면 이 지원 세트는 양방향 10 샘플 학습으로 설명할 수 있습니다.
이제 퓨샷 학습에 대한 기본적인 이해를 마쳤으니 SetFit을 사용하여 빠르게 학습하고 실제 응용에서 전자상거래 데이터 세트에 대한 텍스트 분류를 수행해 보겠습니다.
SetFitArchitecture
은 Hugging Face 팀과 Intel Labs SetFit이 공동으로 개발한 오픈 소스 도구입니다. -샘플 사진 분류 . 프로젝트 라이브러리 링크(https://github.com/huggingface/setfit?ref=hackernoon.com)에서 SetFit에 대한 포괄적인 정보를 찾을 수 있습니다.
출력 측면에서 SetFit은 고객 리뷰(고객 리뷰, CR) 감정 분석 데이터세트의 각 카테고리에 대해 주석이 달린 8개의 예만 사용합니다. 결과는 3,000개의 예제로 구성된 전체 훈련 세트에서 조정된 RoBERTa Large의 결과와 동일합니다. 볼륨 측면에서 약간 최적화된 RoBERTa 모델이 SetFit 모델보다 3배 더 크다는 점을 강조할 가치가 있습니다. 아래 그림은 SetFit 아키텍처를 보여줍니다.
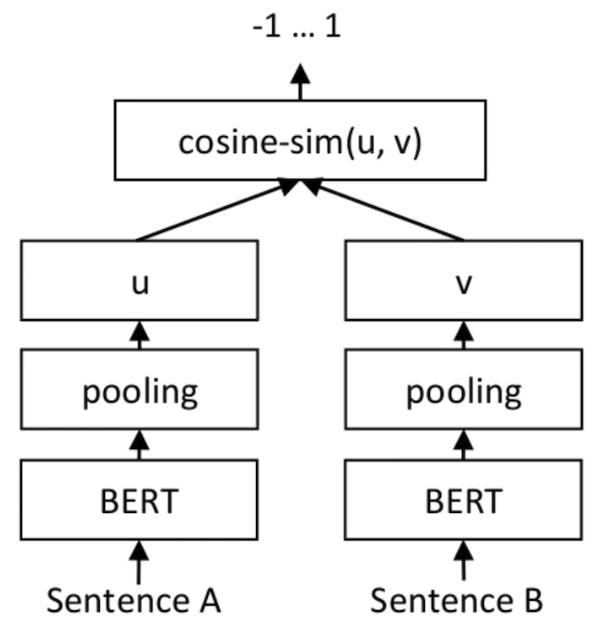
사진 출처: https://www.php.cn/link/2456b9cd2668fa69e3c7ecd6f51866bf
SetFit으로 달성 빠른 학습
SetFit 훈련은 매우 빠르고 효율적입니다. GPT-3, T-FEW 등 대형 모델에 비해 성능 경쟁력이 매우 뛰어납니다. 아래 이미지를 참조하세요:
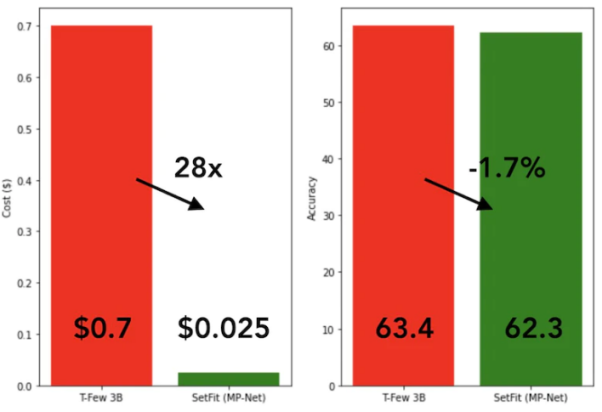 SetFit과 T-Few 3B 모델
SetFit과 T-Few 3B 모델
의 비교 아래 그림과 같이 Few-Shot 학습에서는 SetFit이 RoBERTa보다 성능이 좋습니다.
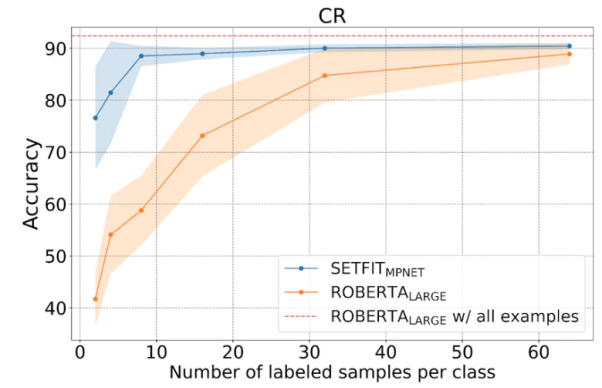
SetFit과 RoBERT의 비교, 사진 출처: https://www.php.cn/link/3ff4cea152080fd7d692a8286a587a67
Dataset
아래, 우리는 책, 의류 및 액세서리, 전자제품, 가정용 가구 등 4가지 카테고리로 구성된 고유한 전자 상거래 데이터 세트를 사용할 것입니다. 이 데이터세트의 주요 목적은 전자상거래 웹사이트의 제품 설명을 지정된 태그로 분류하는 것입니다.
소표본 학습 방법의 사용을 용이하게 하기 위해 4개 범주 각각에서 8개의 샘플을 선택하여 총 32개의 학습 샘플을 생성합니다. 나머지 샘플은 테스트 목적으로 예약됩니다. 간단히 말해서, 여기서 사용하는 지원 세트는 8 샘플에서 학습하는 4입니다. 아래 그림은 사용자 정의 전자 상거래 데이터 세트의 예를 보여줍니다.
 사용자 정의 전자 상거래 데이터 세트 샘플
사용자 정의 전자 상거래 데이터 세트 샘플
이름은 "all-mpnet-base-v2"을 사용합니다. Sentence Transformers는 텍스트 데이터를 다양한 벡터 임베딩으로 변환하기 위해 사전 훈련된 모델입니다. 이 모델은 입력 텍스트에 대해 768 차원의 벡터 임베딩을 생성할 수 있습니다.
다음 명령과 같이 conda 환경(오픈 소스 패키지 관리 시스템 및 환경 관리 시스템) 구현에 필요한 패키지를 설치하여 SetFit을 시작합니다.
!pip3 install SetFit !pip3 install sklearn !pip3 install transformers !pip3 install sentence-transformers
소프트웨어 패키지를 설치한 후 다음 코드를 통해 데이터 세트를 로드할 수 있습니다.
from datasets import load_datasetdataset = load_dataset('csv', data_files={"train": 'E_Commerce_Dataset_Train.csv',"test": 'E_Commerce_Dataset_Test.csv'})
아래 그림을 참조하여 훈련 샘플과 테스트 샘플의 개수를 확인해보세요.
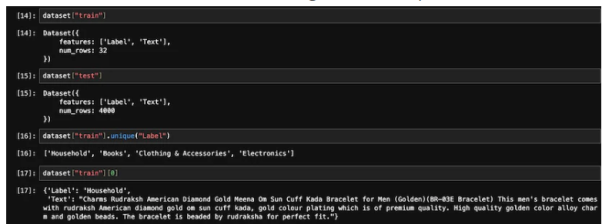 훈련 및 테스트 데이터
훈련 및 테스트 데이터
우리는 sklearn 패키지의 LabelEncoder을 사용하여 텍스트 레이블을 인코딩된 레이블로 변환합니다.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder()
LabelEncoder를 사용하여 학습 및 테스트 데이터세트를 인코딩하고 인코딩된 라벨을 데이터세트의 '레이블' 열에 추가합니다. 아래 코드를 참조하세요.
Encoded_Product = le.fit_transform(dataset["train"]['Label']) dataset["train"] = dataset["train"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["train"].features)Encoded_Product = le.fit_transform(dataset["test"]['Label']) dataset["test"] = dataset["test"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["test"].features)
아래에서는 SetFit 모델과 문장 변환기 모델을 초기화하겠습니다.
from setfit import SetFitModel, SetFitTrainer from sentence_transformers.losses import CosineSimilarityLossmodel_id = "sentence-transformers/all-mpnet-base-v2" model = SetFitModel.from_pretrained(model_id)trainer = SetFitTrainer( model=model, train_dataset=dataset["train"], eval_dataset=dataset["test"], loss_class=CosineSimilarityLoss, metric="accuracy", batch_size=64, num_iteratinotallow=20, num_epochs=2, column_mapping={"Text": "text", "Label": "label"})
두 모델을 초기화한 후 이제 훈련 프로그램을 호출할 수 있습니다.
trainer.train()
2 훈련 라운드(에포크)를 완료한 후 eval_dataset에서 훈련된 모델을 평가합니다.
trainer.evaluate()
테스트 후 우리의 훈련 모델은 87.5%라는 가장 높은 정확도를 달성했습니다. 87.5%의 정확도는 높지 않지만 결국 우리 모델은 훈련에 32개의 샘플만 사용했습니다. 즉, 데이터 세트의 제한된 크기를 고려하면 테스트 데이터 세트에서 87.5%의 정확도를 달성하는 것은 실제로 상당히 인상적입니다.
또한 SetFit은 향후 예측을 위해 디스크에서 후속 로드를 위해 훈련된 모델을 로컬 저장소에 저장할 수도 있습니다.
trainer.model._save_pretrained(save_directory="SetFit_ECommerce_Output/")model=SetFitModel.from_pretrained("SetFit_ECommerce_Output/", local_files_notallow=True)
다음 코드는 새로운 데이터를 기반으로 한 예측 결과를 보여줍니다.
input = ["Campus Sutra Men's Sports Jersey T-Shirt Cool-Gear: Our Proprietary Moisture Management technology. Helps to absorb and evaporate sweat quickly. Keeps you Cool & Dry. Ultra-Fresh: Fabrics treated with Ultra-Fresh Antimicrobial Technology. Ultra-Fresh is a trademark of (TRA) Inc, Ontario, Canada. Keeps you odour free."]output = model(input)
예측 출력은 1이고 라벨의 LabelEncoded 값은 "Clothing and and 액세서리" . 기존 AI 모델은 안정적인 수준의 결과를 생성하기 위해 많은 양의 교육 리소스(시간 및 데이터 포함)가 필요합니다. 대조적으로, 우리 모델은 정확하고 효율적입니다.
이제 '퓨샷 학습'의 개념과 SetFit을 사용하여 텍스트 분류 및 기타 응용 프로그램을 사용하는 방법을 기본적으로 마스터했다고 믿습니다. 물론 더 깊은 이해를 위해서는 실제 시나리오를 선택하고, 데이터 세트를 생성하고, 해당 코드를 작성하고, 제로샷 학습과 싱글샷 학습으로 프로세스를 확장하는 것을 강력히 권장합니다.
번역자 소개
Julian Chen은 51CTO 커뮤니티의 편집자입니다. 그는 IT 프로젝트 구현 분야에서 10년 이상의 경험을 갖고 있으며 내부 및 외부 자원과 위험을 잘 관리하고 집중하고 있습니다. 네트워크 및 정보 보안에 대한 지식과 경험을 전파하기 위해
원제: Mastering Few-Shot Learning with SetFit for Text Classification, 저자: Shyam Ganesh S)
위 내용은 퓨샷 학습에서는 텍스트 분류를 위해 SetFit을 사용합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!