
새로운 주의 메커니즘 Meta는 대형 모델을 인간의 두뇌와 더욱 유사하게 만들어 작업과 관련 없는 정보를 자동으로 필터링함으로써 정확도를 27% 높입니다.

- 王林앞으로
- 2023-11-27 14:39:13836검색
메타는 대형 모델의 어텐션 메커니즘에 대한 새로운 연구를 수행했습니다
모델의 어텐션 메커니즘을 조정하고 관련 없는 정보의 간섭을 필터링함으로써 새로운 메커니즘은 대형 모델의 정확도를 더욱 향상시킵니다
그리고 이 메커니즘은 그렇지 않습니다. 미세 조정이나 훈련이 필요하며 프롬프트만으로도 대형 모델의 정확도를 27% 높일 수 있습니다.
저자는 2002년 노벨 경제학상 수상자인 다니엘 카너먼(Daniel Kahneman)의 베스트셀러 저서 『생각하기(Thinking)』에서 이 주의 메커니즘을 '시스템 2 주의(System 2 Attention)'(S2A)라고 명명했다. and Slow" - 이중 시스템 사고 모델의 "시스템 2"
소위 시스템 2는 단순한 무의식적 직관인 시스템 1과 달리 복잡한 의식적 추론을 의미합니다.
S2A는 Transformer의 주의 메커니즘을 "조정"하고 프롬프트 단어를 사용하여 모델의 전반적인 사고를 시스템 2에 더 가깝게 만듭니다.
일부 네티즌은 이 메커니즘을 AI에 "고글" 레이어를 추가하는 것으로 설명했습니다.
또한 저자는 논문 제목에서 대형 모델뿐만 아니라 이러한 사고 방식도 인간 스스로 학습해야 할 수도 있다고 밝혔습니다.

그럼 이 방법은 어떻게 구현되나요?
대형 모델이 "오도"되는 것을 방지하세요
기존 대형 모델에서 일반적으로 사용되는 Transformer 아키텍처는 소프트 어텐션 메커니즘을 사용합니다. 이는 각 단어(토큰)에 0과 1 사이의 어텐션 값을 할당합니다.
해당 개념은 입력 시퀀스의 특정 또는 특정 하위 집합에만 초점을 맞추고 이미지 처리에 더 일반적으로 사용되는 하드 어텐션 메커니즘입니다.
S2A 메커니즘은 두 가지 모드의 조합으로 이해될 수 있습니다. 핵심은 여전히 소프트 어텐션이지만 여기에 "하드" 심사 프로세스가 추가됩니다.
구체적인 작업 측면에서 S2A는 모델 자체를 조정할 필요는 없지만 프롬프트 단어를 사용하여 모델이 문제를 해결하기 전에 "주의를 기울이지 말아야 할 콘텐츠"를 제거하도록 허용합니다.
이렇게 하면 주관적이거나 관련성이 없는 정보가 포함된 프롬프트 단어를 처리할 때 대형 모델이 오도될 확률을 줄일 수 있어 모델의 추론 능력과 실제 적용 가치를 향상시킬 수 있습니다.

대형 모델의 답변은 프롬프트의 단어에 큰 영향을 받는다는 것을 배웠습니다. 정확성을 높이기 위해 S2A는 간섭을 일으킬 수 있는 정보를 제거하기로 결정했습니다
예를 들어 대형 모델에 다음과 같은 질문을 하면:
도시 A는 X 주의 도시로 산과 많은 공원으로 둘러싸여 있습니다. 여기에는 뛰어난 사람들이 많이 있고, 많은 유명한 사람들이 City A에서 태어났습니다.
X주 B시 시장 Y는 어디에서 태어났나요?
이때 GPT와 Llama의 답변은 모두 질문에 언급된 A 도시이지만, 사실 Y의 출생지는 C 도시입니다.

처음 질문했을 때 모델은 도시 C로 정확하게 대답할 수 있었습니다. 그러나 프롬프트 단어에 도시 A가 반복적으로 등장했기 때문에 모델의 '주의'를 끌었고 최종 답변은 A가 되었습니다
또 다른 대안 What 사람들이 질문을 할 때 "가능한 답변"을 떠올리는 경우가 발생합니다.
M밴드에 가수 겸 배우도 있나요? A일 수도 있을 것 같은데 잘 모르겠네요
결과적으로 빅모델이 유저들에게 칭찬을 받기 시작했지요. A입니다. 그런데 이 사람은 사실 B입니다.
마찬가지로, 사람의 신원을 직접 물어보면 모델이 정확하게 대답할 수 있습니다

이 기능 때문에 저자는 새로운 S2A 메커니즘을 고민하고 사용자 입력을 세분화하기 위한 프롬프트 단어 세트를 설계했습니다

상영 전과 후의 효과를 자세히 살펴보겠습니다.
Q: Mary는 Megan보다 사탕을 3배나 많이 가지고 있습니다. Mary는 사탕 10개를 더 가져갔습니다. Max는 Mary보다 1,000권 더 많은 책을 소유하고 있습니다. Megan이 5개의 사탕을 가지고 있다면 Mary는 총 몇 개의 사탕을 가지고 있습니까?
A: Max는 Mary보다 1,000권의 책을 더 가지고 있으므로 Max는 1,000+x+10개의 사탕을 가지고 있습니다. 다음과 같은 방정식을 만들 수 있습니다.
1000+3x+10=3(5)+10
… S2A, 질문은 다음 상황이 됩니다.
Q: Mary는 Megan보다 3배 많은 사탕을 가지고 있습니다. Mary는 사탕 10개를 더 가져갔습니다. Megan이 5개의 사탕을 가지고 있다면 Mary는 총 몇 개의 사탕을 가지고 있습니까?
질문(질문은 여기 프롬프트에 직접 작성되어 있습니다.): 메리는 총 몇 개의 사탕을 가지고 있나요?
재작성 내용: A: 메건은 5위안, 메리는 메건의 3배인 15위안, 그리고 또 10위안을 더 가져가서 총 25위안이 나왔습니다
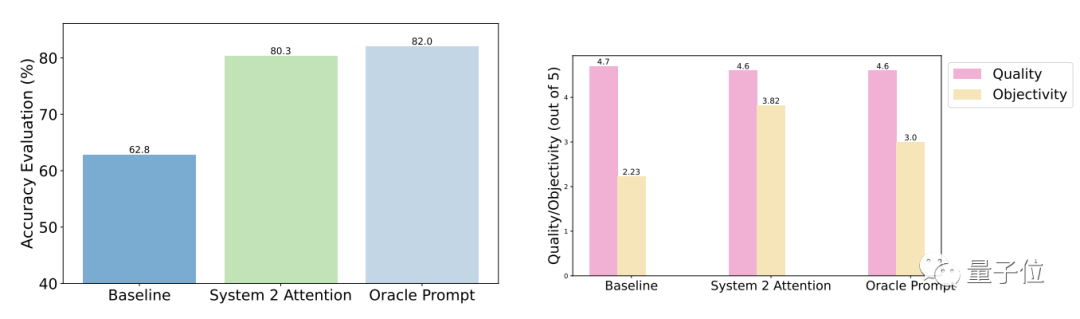
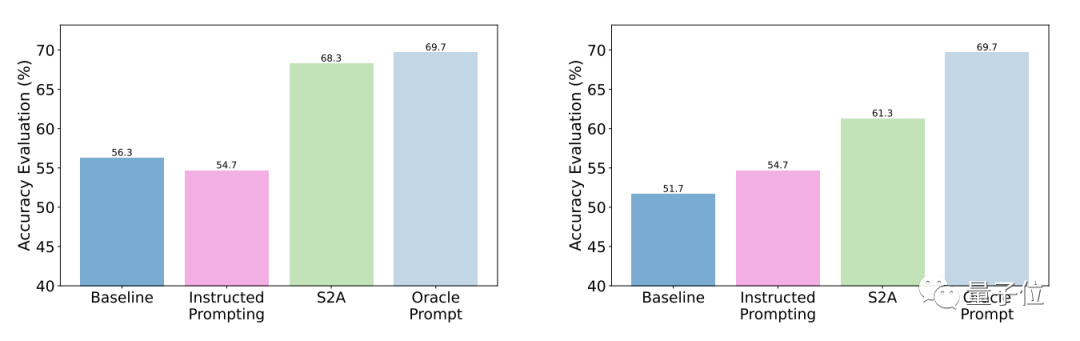
 테스트 결과에 따르면 일반적인 질문과 비교하여 최적화 후 S2A의 정확성과 객관성이 크게 향상되었으며 정확도는 수동으로 설계된 유선형 프롬프트의 정확도에 가깝습니다.
테스트 결과에 따르면 일반적인 질문과 비교하여 최적화 후 S2A의 정확성과 객관성이 크게 향상되었으며 정확도는 수동으로 설계된 유선형 프롬프트의 정확도에 가깝습니다.
구체적으로 S2A는 TriviaQA 데이터 세트의 수정 버전에 Llama 2-70B를 적용하여 정확도를 62.8%에서 80.3%로 27.9% 향상시켰습니다. 동시에 객관성 점수도 2.23점(5점 만점)에서 3.82점으로 높아져 인위적으로 프롬프트 단어를 합리화한 효과조차 뛰어넘었습니다
 강건성 측면에서는 테스트 결과 "간섭 정보"는 정확하거나 틀리거나, 긍정적이거나 부정적이거나, S2A를 통해 모델은 보다 정확하고 객관적인 답변을 제공할 수 있습니다.
강건성 측면에서는 테스트 결과 "간섭 정보"는 정확하거나 틀리거나, 긍정적이거나 부정적이거나, S2A를 통해 모델은 보다 정확하고 객관적인 답변을 제공할 수 있습니다.
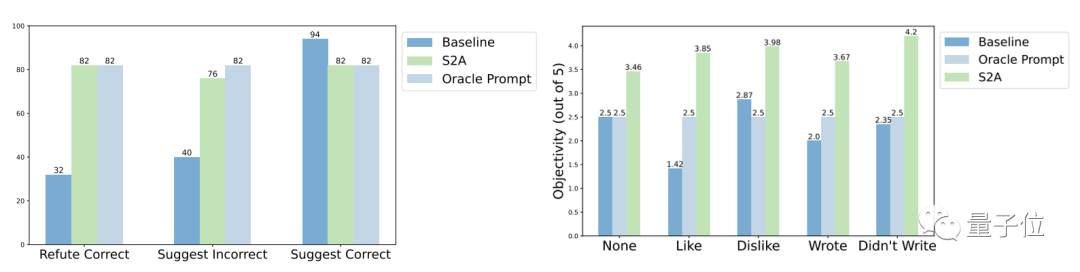 S2A 방법의 추가 실험 결과는 간섭 정보를 제거해야 함을 보여줍니다. 잘못된 정보를 무시하도록 모델에 지시하는 것만으로는 정확도가 크게 향상되지 않으며 정확도가 저하될 수도 있습니다. 반면에 원래 간섭 정보가 격리되어 있는 한 S2A에 대한 다른 조정은 그 효과를 크게 감소시키지 않습니다.
S2A 방법의 추가 실험 결과는 간섭 정보를 제거해야 함을 보여줍니다. 잘못된 정보를 무시하도록 모델에 지시하는 것만으로는 정확도가 크게 향상되지 않으며 정확도가 저하될 수도 있습니다. 반면에 원래 간섭 정보가 격리되어 있는 한 S2A에 대한 다른 조정은 그 효과를 크게 감소시키지 않습니다.
 One More Thing
One More Thing
사실 어텐션 메커니즘 조정을 통한 모델 성능 향상은 학계에서 항상 뜨거운 주제였습니다.
예를 들어, 최근 출시된 "Mistral"은 가장 강력한 7B 오픈 소스 모델로, 새로운 그룹화 쿼리 어텐션 모델을 사용합니다. 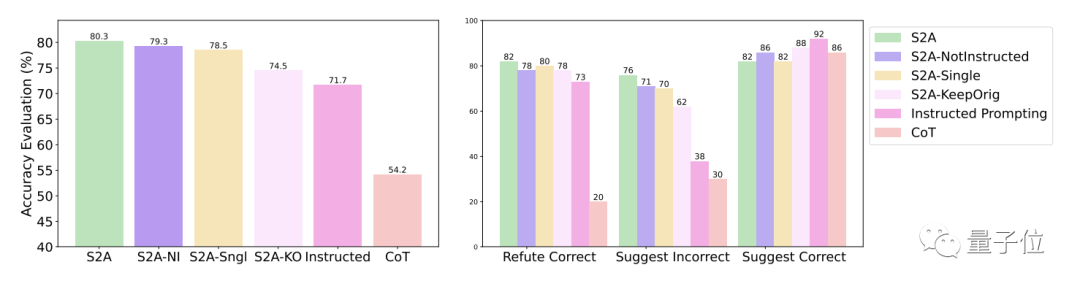
일반인공지능(AGI)으로 나아가는 유일한 방법은 시스템 1에서 시스템 1로 나아가는 것입니다. 시스템 2
의 전환 논문 주소: https://arxiv.org/abs/2311.11829
위 내용은 새로운 주의 메커니즘 Meta는 대형 모델을 인간의 두뇌와 더욱 유사하게 만들어 작업과 관련 없는 정보를 자동으로 필터링함으로써 정확도를 27% 높입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!