Meta의 "모든 것 분할" 모델을 어떻게 최적화해야 합니까? PyTorch 팀이 작성한 이 블로그는 간단한 것부터 깊은 것까지 이에 대한 답변을 제공합니다.
연초부터 현재까지 제너레이티브 AI는 빠르게 발전해왔습니다. 그러나 우리는 특히 PyTorch를 사용할 때 생성 AI의 훈련, 추론 등의 속도를 어떻게 높일 것인가라는 어려운 문제에 직면할 때가 많습니다. 이 기사에서는 PyTorch 팀의 연구원들이 솔루션을 제공합니다. 이 기사에서는 순수 네이티브 PyTorch를 사용하여 생성 AI 모델을 가속화하는 방법에 중점을 두고 있으며, 새로운 PyTorch 기능과 이를 결합하는 방법에 대한 실제 사례도 소개합니다. 결과는 어땠나요? PyTorch 팀은 Meta의 "모든 것을 분할"(SAM) 모델을 다시 작성하여 정확성을 잃지 않고 원래 구현보다 8배 빠른 코드를 생성했으며 모두 기본 PyTorch를 사용하여 최적화되었다고 말했습니다. 
블로그 주소: https://pytorch.org/blog/accelerating-generative-ai/이 기사를 읽고 나면 다음 내용을 배울 수 있습니다.
- Torch.compile: PyTorch 모델 컴파일러인 PyTorch 2.0에는 한 줄의 코드로 기존 모델을 가속화할 수 있는 torch.compile()이라는 새로운 기능이 추가되었습니다.
- GPU 양자화: 계산 정확도를 줄여 모델을 가속화합니다. Dot Product Attention): 메모리 효율적인 attention 구현
- 반구조적(2:4) 희소성: GPU에 최적화된 희소 메모리 형식
- Nested Tensor: 중첩된 Tensor는 다양한 크기의 이미지와 같이 균일하지 않은 크기의 데이터를 단일 텐서로 일괄 처리합니다.
- Triton 사용자 정의 작업: Triton Python DSL을 사용하여 GPU 작업을 작성하고 사용자 정의합니다. 연산자 등록을 통해 PyTorch의 다양한 구성 요소에 쉽게 통합할 수 있습니다. . ㅋㅋㅋ PyTorch의 기본 기능으로 인해 처리량이 증가하고 메모리 오버헤드가 감소했습니다.
SAM은 Meta에서 제안했습니다. 이 연구에 대한 자세한 내용은 "CV는 더 이상 존재하지 않습니까? Meta는 "모든 것을 분할"하는 AI 모델을 출시하고 CV는 GPT-3 순간을 가져올 수 있습니다
"를 참조하세요. .
다음으로 이 기사에서는 성능 분석, 병목 현상 식별, 이러한 새로운 기능을 PyTorch에 통합하여 SAM이 직면한 문제를 해결하는 방법을 포함한 SAM 최적화 프로세스를 소개합니다. 또한 이 기사에서는 torch.compile, SDPA, Triton 커널, Nested Tensor 및 반구조적 희소성과 같은 PyTorch의 몇 가지 새로운 기능도 소개합니다. 이 기사의 내용은 기사 마지막 부분에서 SAM의 빠른 버전을 소개합니다. 또한, 이 기사에서는 이를 시각화할 수도 있습니다. Perfetto UI를 통해 PyTorch의 각 특성에 대한 응용 가치를 설명합니다.
GitHub 주소: https://github.com/pytorch-labs/segment-anything-fast
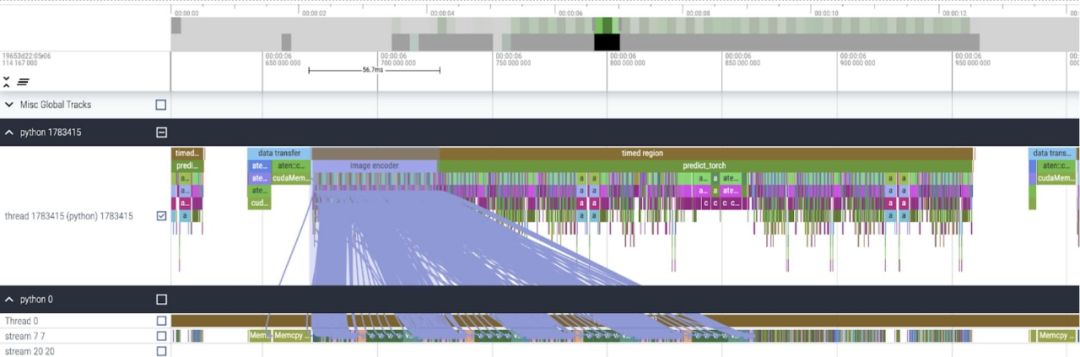
재작성 연구에 따르면 이 기사는 다음과 같습니다. 사용된 SAM 기본 데이터 유형은 float32 dtype이고 배치 크기는 1입니다. PyTorch Profiler를 사용하여 커널 추적을 본 결과는 다음과 같습니다.
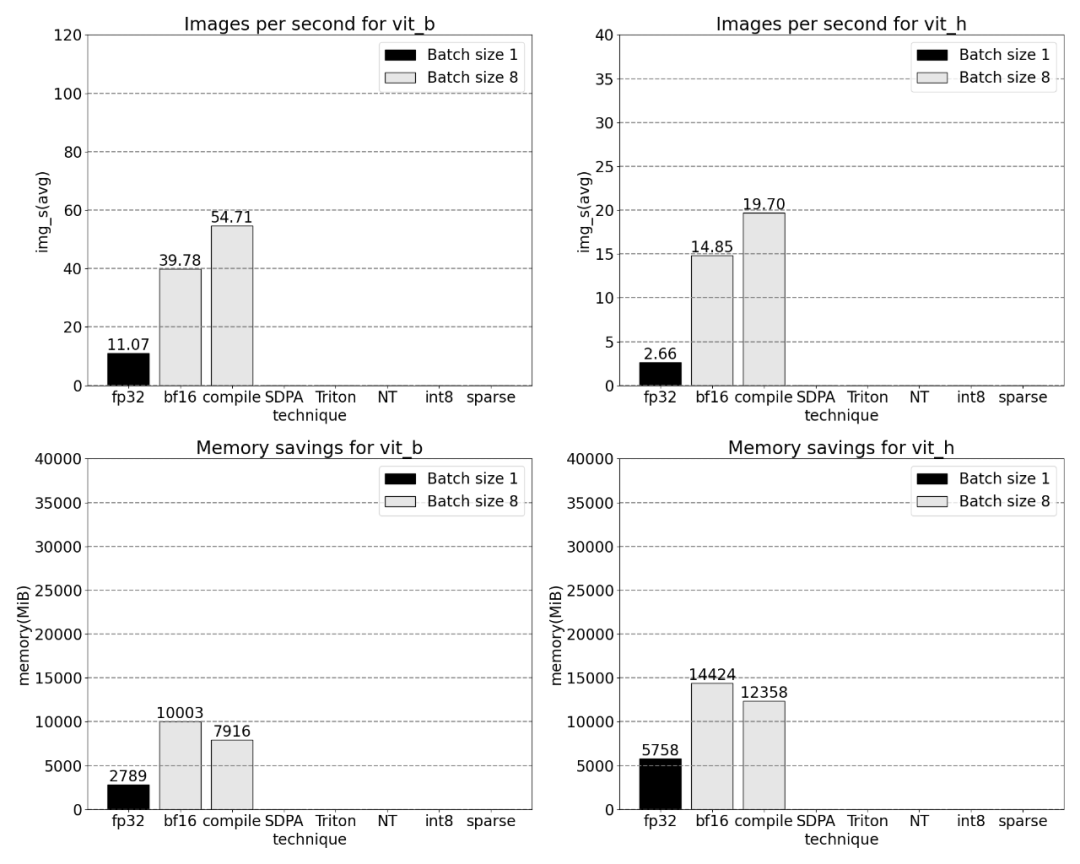
이 기사에서는 SAM을 최적화할 수 있는 두 곳이 있음을 발견했습니다. 첫 번째는 aten::index에 대한 긴 호출로, 이는 텐서 인덱스 작업(예: [])에 의해 생성된 기본 호출로 인해 발생합니다. . 그러나 GPU가 aten::index에 소비하는 실제 시간은 상대적으로 낮습니다. 그 이유는 두 코어를 시작하는 과정에서 aten::index가 두 코어 사이의 cudaStreamSynchronize를 차단하기 때문입니다. 즉, CPU는 두 번째 코어가 시작될 때까지 GPU가 처리를 완료할 때까지 기다립니다. 따라서 본 논문에서는 SAM을 최적화하기 위해서는 유휴 시간을 유발하는 GPU 동기화 차단을 제거하기 위해 노력해야 한다고 믿습니다. 두 번째는 SAM이 Transformers에서 흔히 볼 수 있는 행렬 곱셈(위 이미지의 진한 녹색)에 GPU 시간을 많이 소비한다는 것입니다. SAM 모델이 행렬 곱셈에 소비하는 GPU 시간을 줄일 수 있다면 SAM 속도를 크게 높일 수 있습니다. 다음으로 이 문서에서는 SAM의 처리량(img/s)과 메모리 오버헤드(GiB)를 사용하여 기준선을 설정합니다. 그 후에는 최적화 프로세스가 진행됩니다.
Bfloat16 반 정밀도(GPU 동기화 및 일괄 처리 포함) 위의 문제를 해결하기 위해, 즉 행렬 곱셈의 시간을 단축하기 위해 이 기사에서는 bfloat16을 사용합니다. Bfloat16은 일반적으로 사용되는 반정밀도 유형으로 각 매개변수 및 활성화의 정밀도를 줄여 컴퓨팅 시간과 메모리를 많이 절약할 수 있습니다. 1 BFLOAT16을 사용하여 Padding 유형을 대체합니다. 또한 GPU 동기화를 제거하기 위해 최적화할 수 있는 위치가 두 가지가 있다는 것을 이 기사에서는 찾아냈습니다.
구체적으로(위 그림을 참고하면 이해하기 쉬우며, 나타나는 변수 이름은 모두 코드에 있음) 연구 결과 SAM 이미지 인코더에는 좌표 스케일러가 있는 것으로 나타났습니다. 및 k_coords, 이러한 변수는 CPU에 할당되고 처리됩니다. 그러나 이러한 변수가 rel_pos_resize에서 인덱싱하는 데 사용되면 이러한 인덱싱 작업은 자동으로 이러한 변수를 GPU로 이동하고 이 복사본으로 인해 GPU 동기화가 발생합니다. 위의 문제를 해결하기 위해 이 부분은 위와 같이 torch.where를 이용하여 다시 작성하면 해결할 수 있다고 연구에서는 지적했습니다.
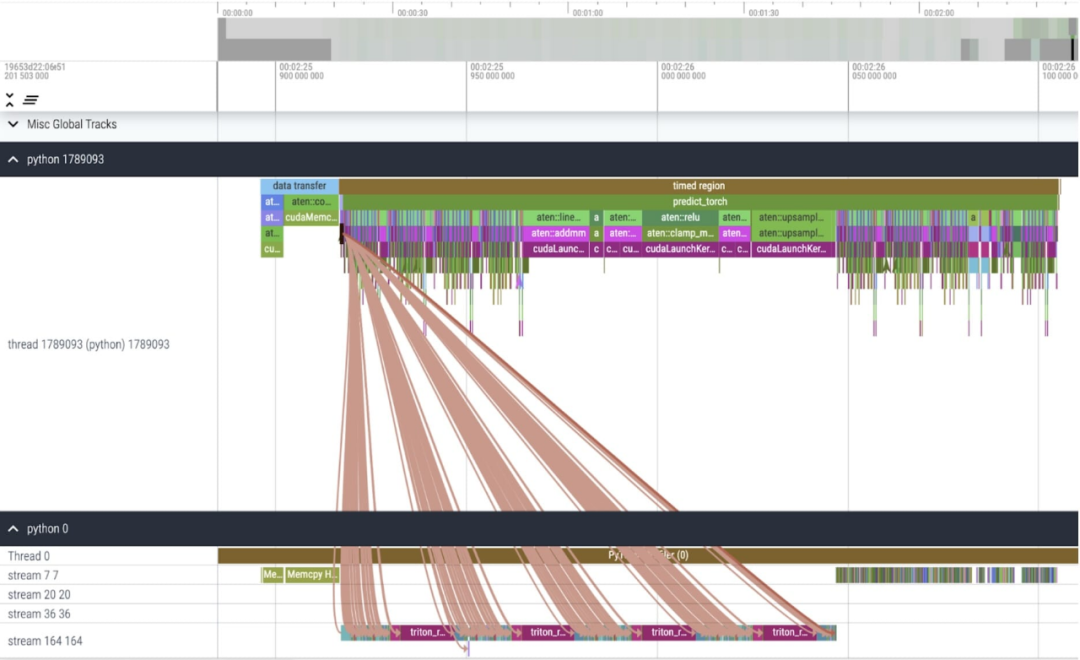
이러한 변경 사항을 적용한 후 이 문서에서는 특히 소규모 배치(여기 1)에서 개별 커널 호출 간에 상당한 시간 차이가 있음을 확인했습니다. 이 현상에 대한 더 깊은 이해를 얻기 위해 이 기사는 배치 크기 8을 사용한 SAM 추론의 성능 분석으로 시작합니다.
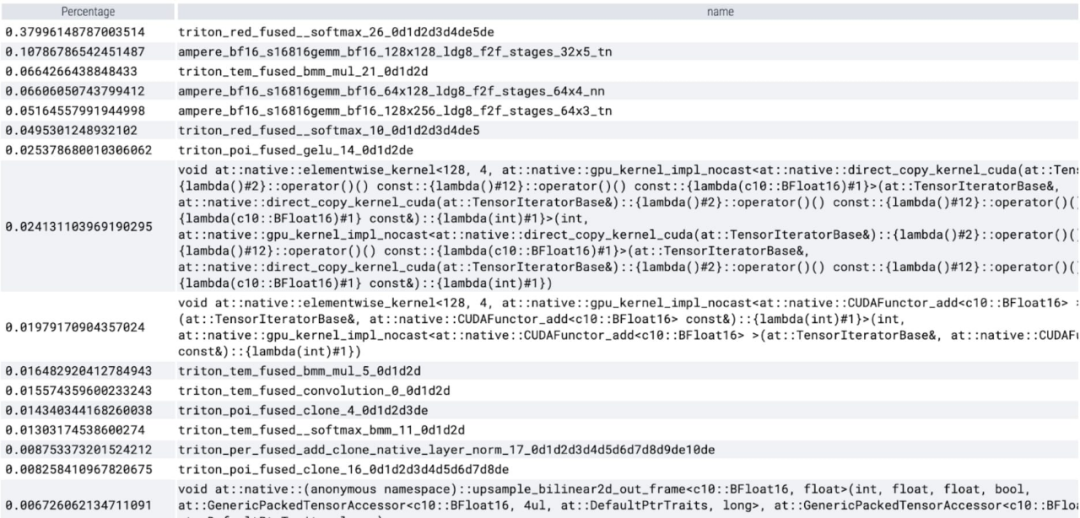
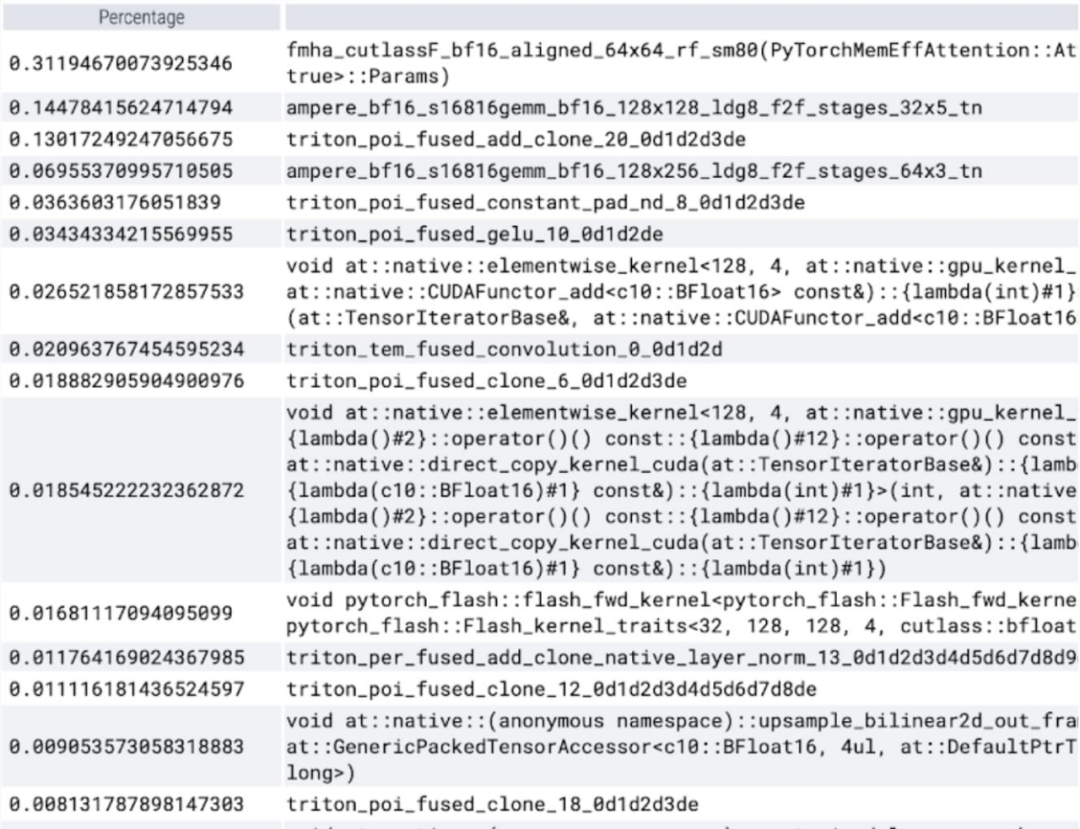
코어당 소비된 시간을 살펴보면 이 기사에서는 SAM이 대부분의 GPU를 소비한다는 것을 관찰합니다. 시간 요소별 커널 및 소프트맥스 작업에 적용됩니다. 이제 행렬 곱셈의 상대적 비용이 훨씬 작다는 것을 알 수 있습니다. GPU 동기화와 bfloat16 최적화를 결합하여 SAM 성능이 3배 향상되었습니다.
Torch.compile (+그래프 나누기 및 CUDA 그래프)이 기사에서는 SAM을 심층적으로 연구하는 과정에서 많은 작은 작업이 있음을 발견했습니다. 그들은 작업을 융합하기 위해 컴파일러를 사용하는 것이 좋다고 생각합니다. PyTorch torch.compile에 다음과 같은 최적화가 이루어졌습니다.
- nn.LayerNorm 또는 nn.GELU와 같은 작업 시퀀스를 단일 GPU 커널로 융합
- 즉시 이어지는 작업 융합; GPU 커널 호출 수를 줄이기 위한 행렬 곱셈 커널.
이러한 최적화를 통해 연구에서는 GPU 전역 메모리 왕복 횟수를 줄여 추론 속도를 높였습니다. 이제 SAM의 이미지 인코더에서 torch.compile을 사용해 볼 수 있습니다. 성능을 최대화하기 위해 이 기사에서는 몇 가지 고급 컴파일 기술을 사용합니다.
결과에 따르면 torch.compile이 매우 잘 작동하는 것으로 나타났습니다.
softmax가 많은 시간을 차지하고 그 뒤를 이어 다양한 GEMM 변형이 나타나는 것을 볼 수 있습니다. 다음 측정값은 배치 크기 8 이상에 대한 것입니다.
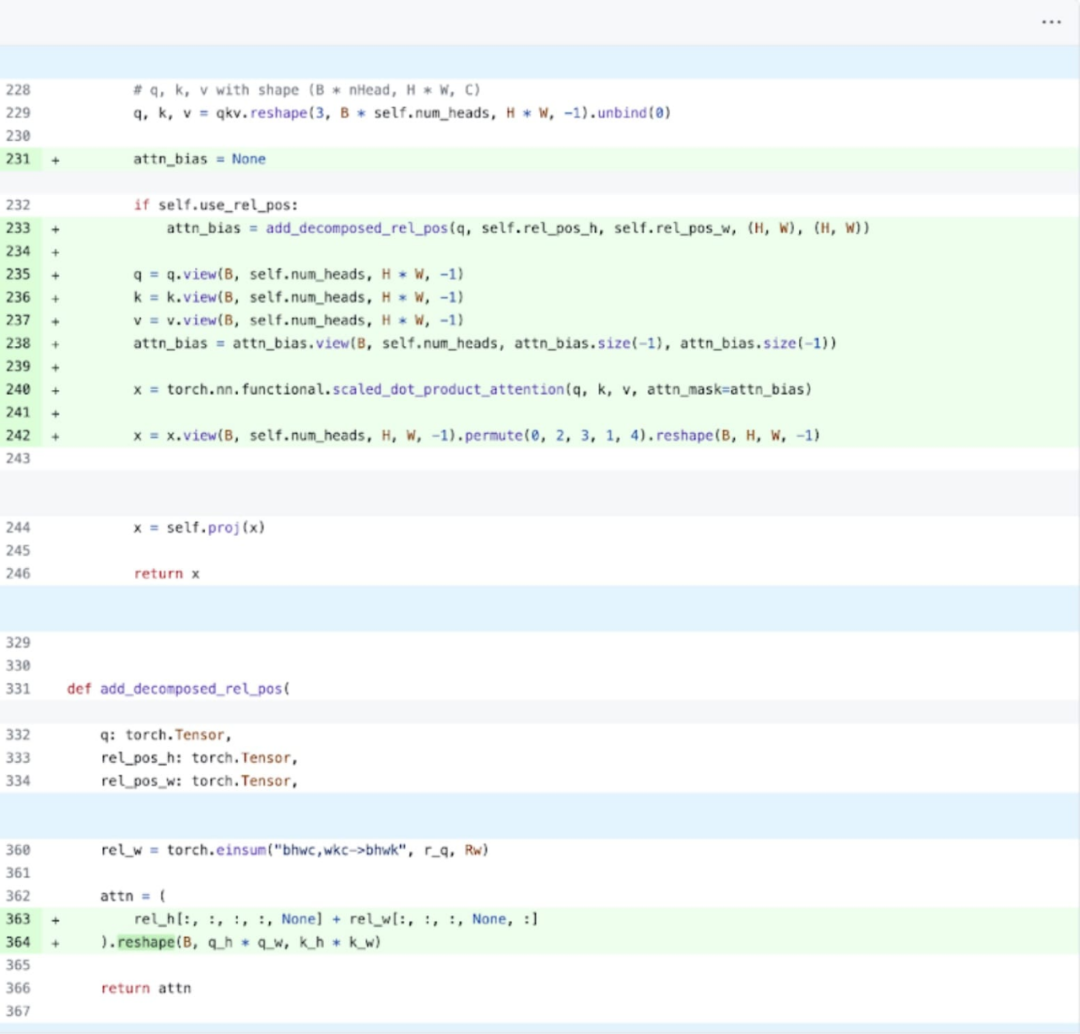
SDPA: scaled_dot_product_attention다음으로 이 기사에서는 주의 메커니즘에 초점을 맞춰 SDPA(scaled_dot_product_attention)에 대한 실험을 수행했습니다. 일반적으로 기본 주의 메커니즘은 시간과 메모리의 시퀀스 길이에 따라 2차적으로 확장됩니다. PyTorch의 SDPA 작업은 Flash Attention, FlashAttentionV2 및 xFormer의 메모리 효율적인 주의 원칙을 기반으로 구축되어 GPU 주의 속도를 크게 높일 수 있습니다. torch.compile과 결합된 이 작업을 통해 MultiheadAttention의 변형에서 공통 패턴을 표현하고 융합할 수 있습니다. 약간의 변경 후에 모델은 이제 scaled_dot_product_attention을 사용할 수 있습니다.
이제 메모리 효율적인 Attention 커널이 GPU에서 많은 계산 시간을 차지하는 것을 볼 수 있습니다.
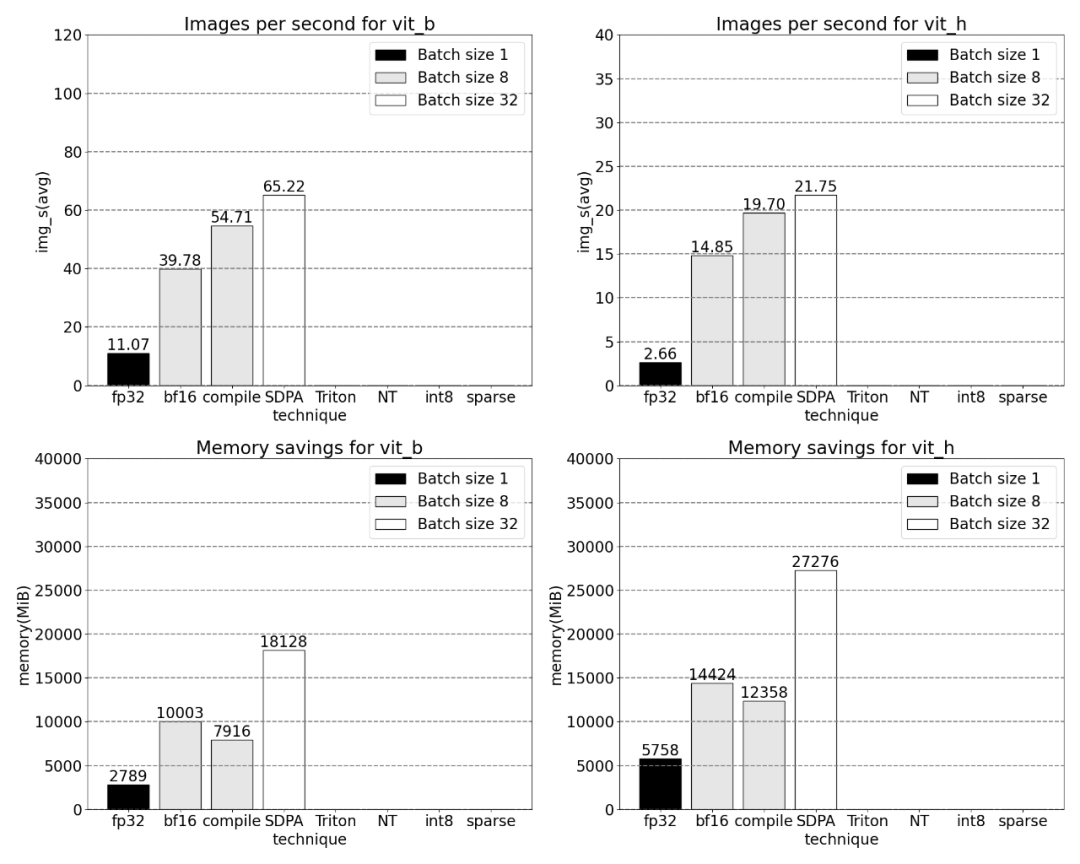
PyTorch의 기본 scaled_dot_product_attention을 사용하면 는 배치 크기. 아래 그래프는 배치 크기가 32 이상인 경우의 변경 사항을 보여줍니다.
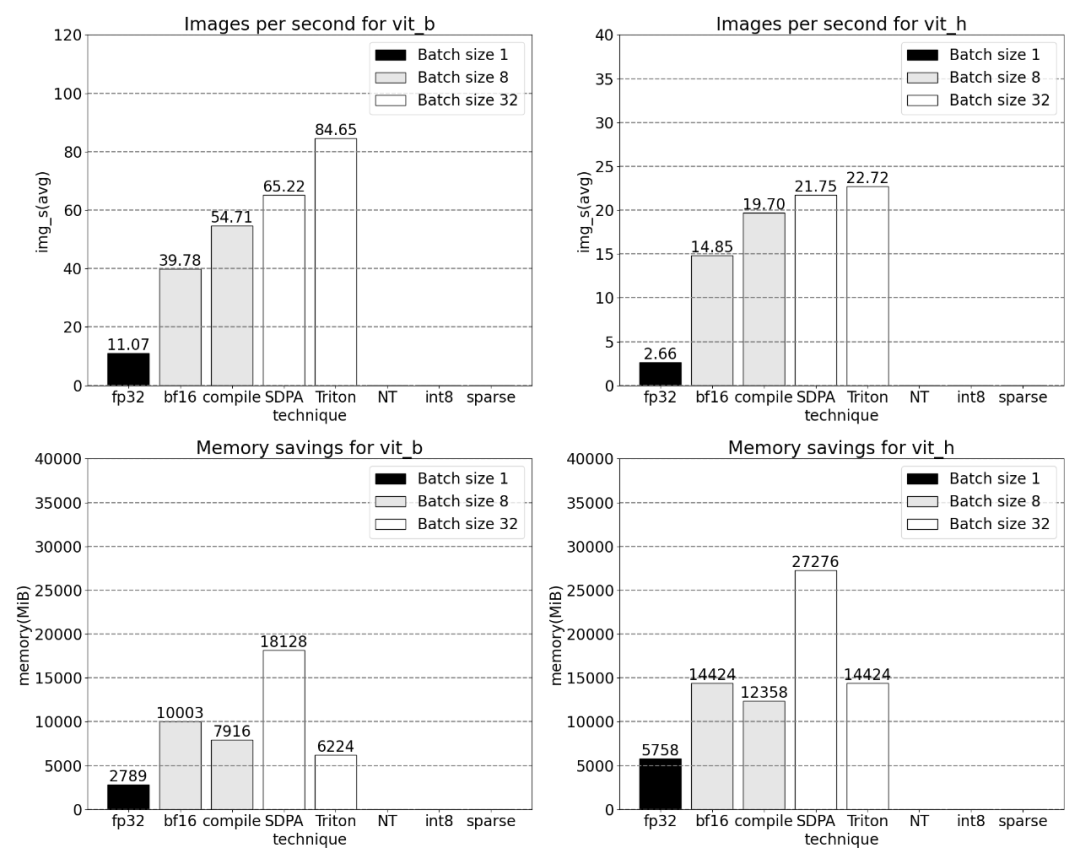
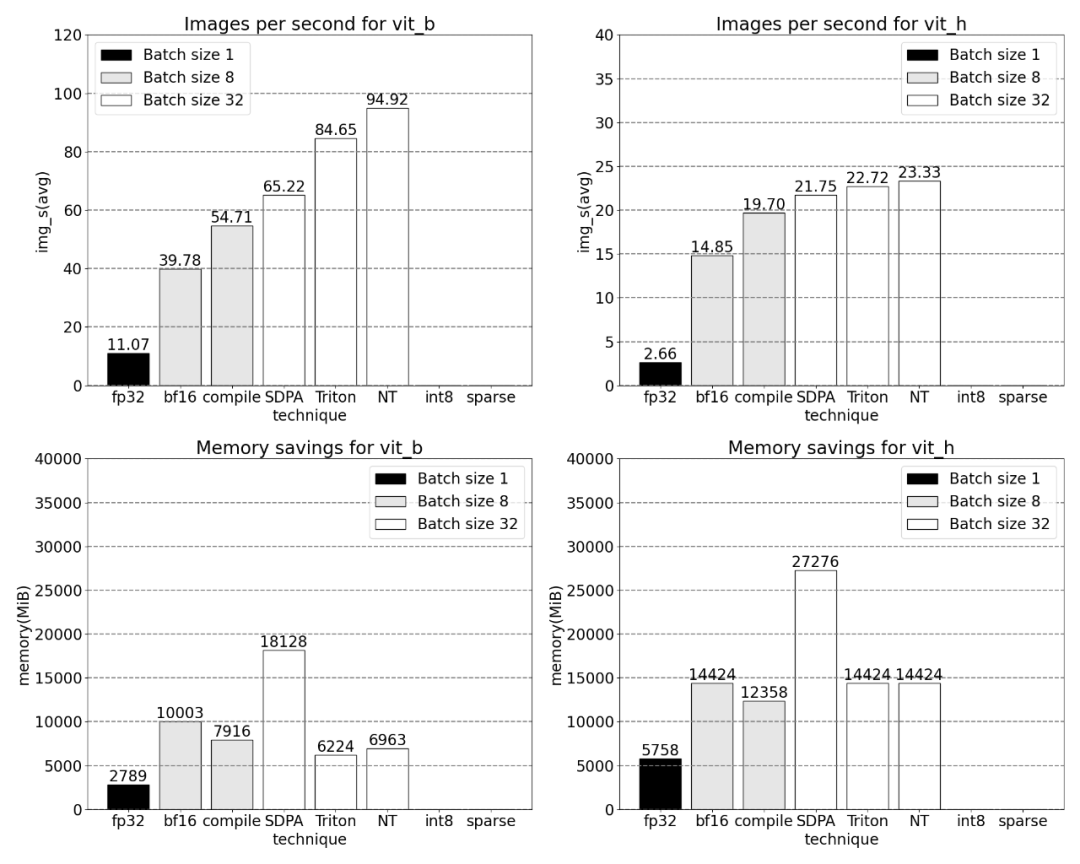
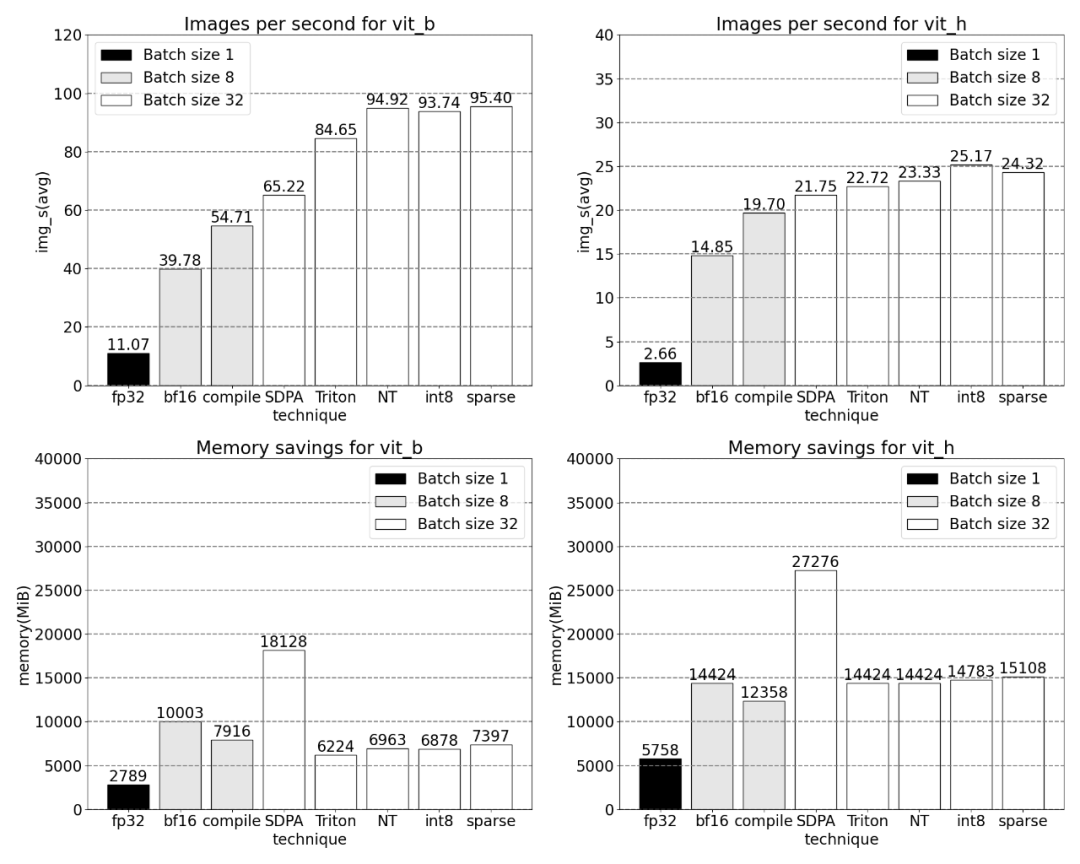
이후 연구에서는 Triton, NestedTensor, 일괄 처리 Predict_torch, int8 양자화, 반구조적(2:4) 희소성 및 기타 작업도 실험했습니다. 예를 들어 이 기사에서는 사용자 정의 위치 Triton 커널을 사용하고 배치 크기 32로 측정 결과를 관찰합니다.
Nested Tensor를 사용하면 배치 크기가 32 이상부터 다양합니다.
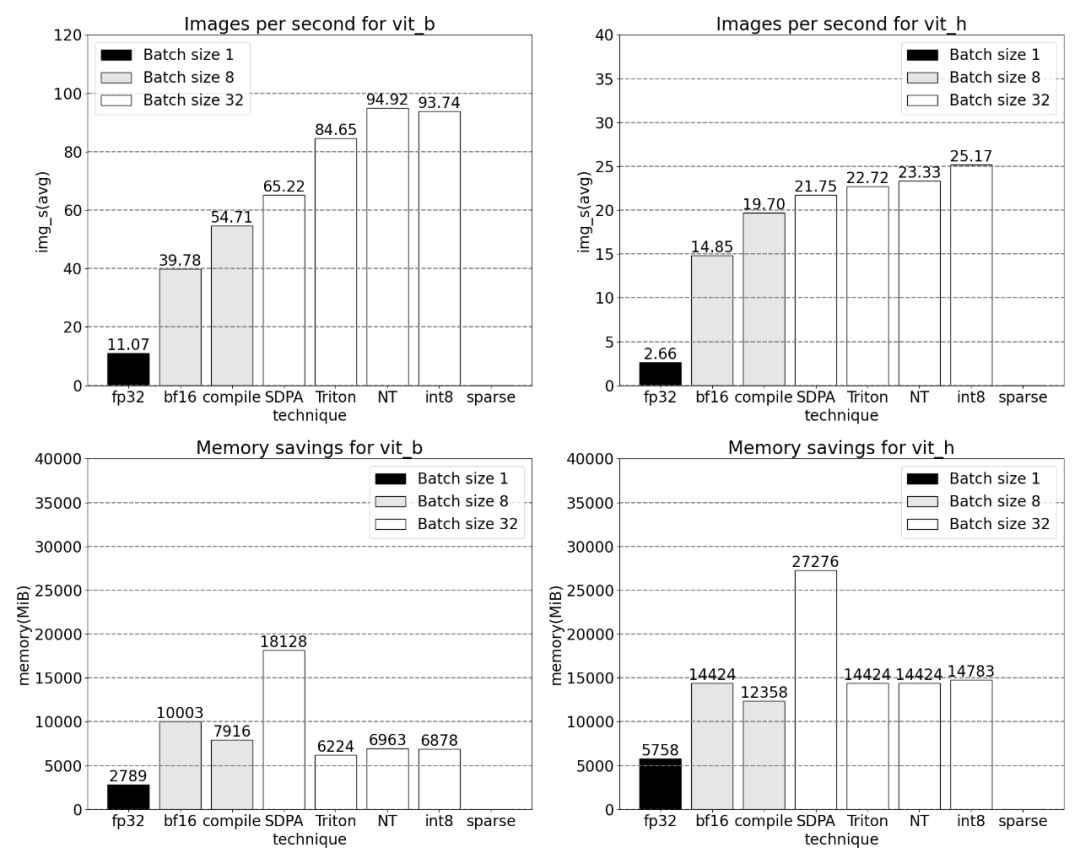
양자화 추가 후 배치 크기 32 이상에 대한 측정입니다.
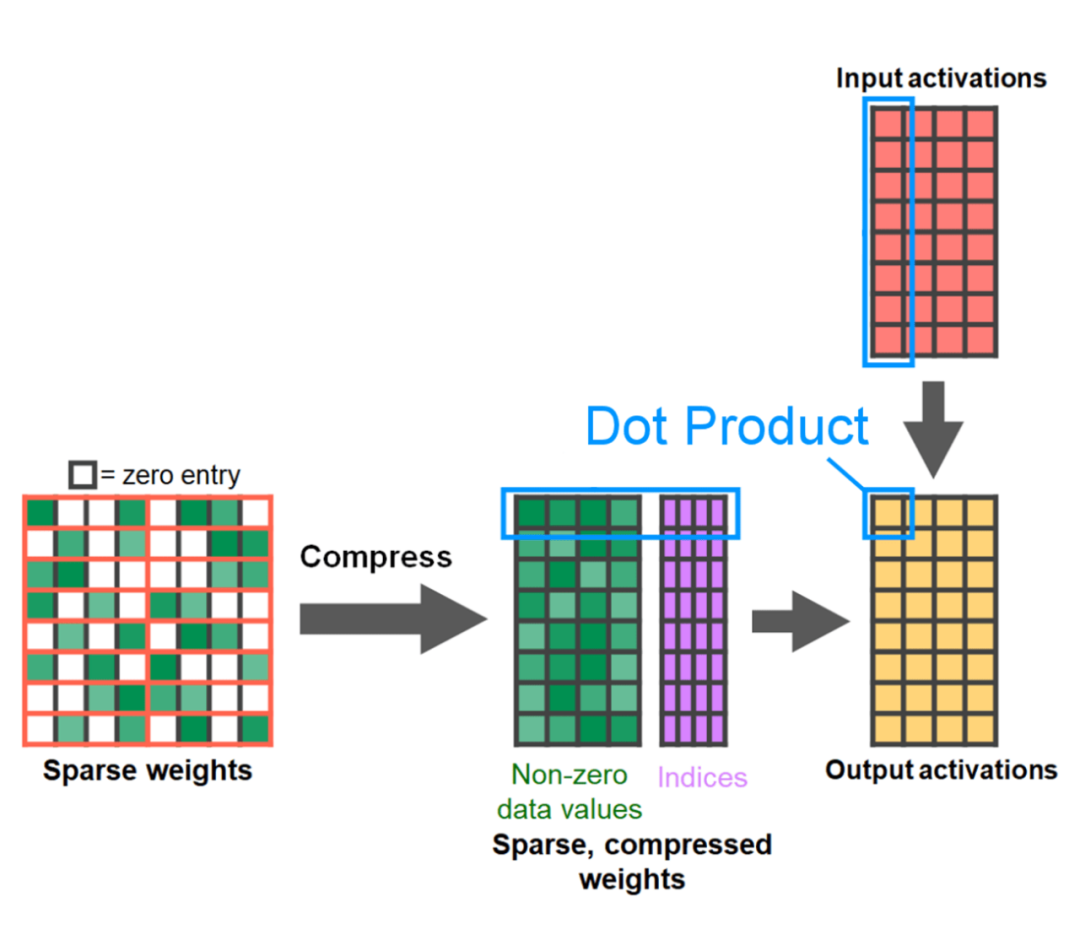
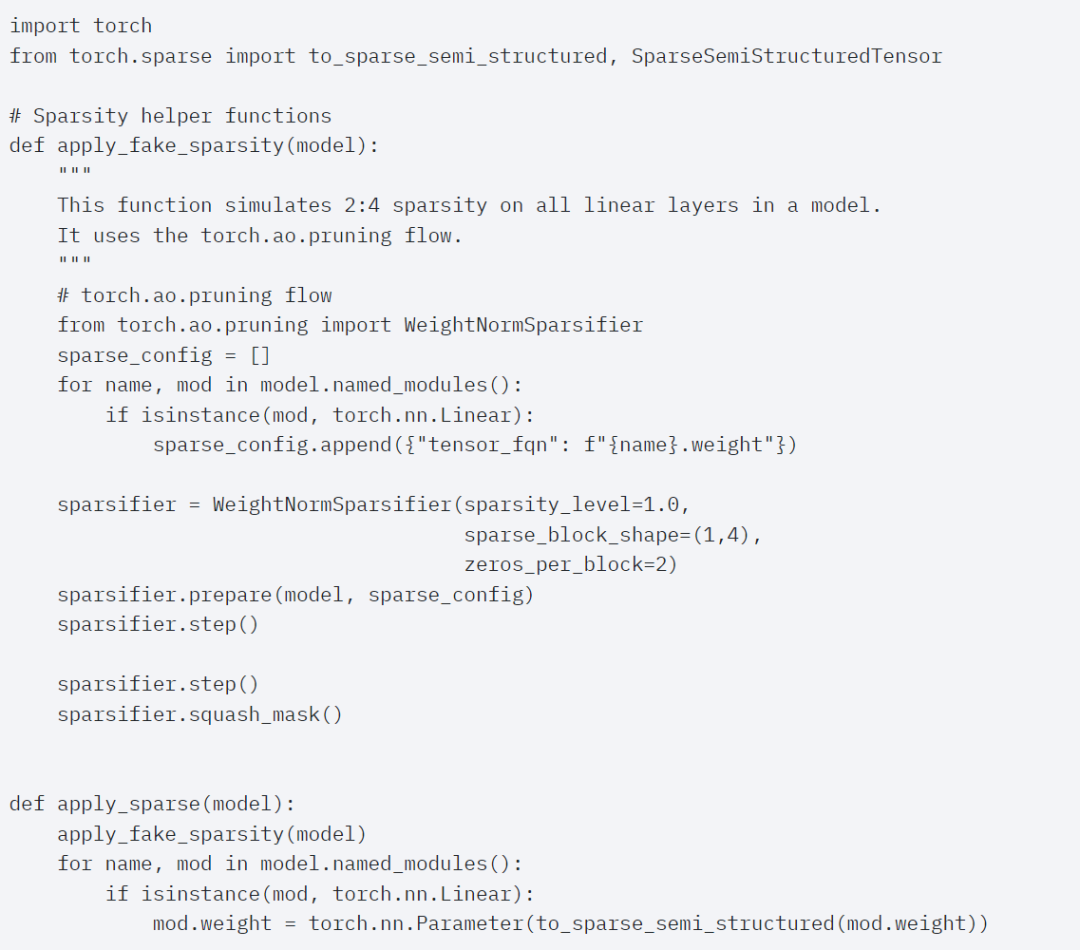
글의 끝은 반구조화된 희소성입니다. 이 연구는 행렬 곱셈이 여전히 직면해야 할 병목 현상임을 보여줍니다. 해결책은 희소화를 사용하여 행렬 곱셈을 근사화하는 것입니다. 희소 행렬(즉, 값을 0으로 설정)을 사용하면 가중치와 활성화 텐서를 저장하는 데 더 적은 비트를 사용할 수 있습니다. 텐서의 어떤 가중치를 0으로 설정하는 프로세스를 가지치기(pruning)라고 합니다. 더 작은 가중치를 잘라내면 정확도가 크게 떨어지지 않고 모델 크기가 잠재적으로 줄어들 수 있습니다. 완전히 구조화되지 않은 것부터 고도로 구조화된 것까지 가지치기 방법에는 여러 가지가 있습니다. 구조화되지 않은 가지치기는 이론적으로 정확도에 최소한의 영향을 미치며, GPU는 대규모의 조밀한 행렬 곱셈을 수행하는 데 매우 효율적이지만 희박한 경우에는 심각한 성능 저하를 겪을 수 있습니다. 최근 PyTorch에서 지원하는 가지치기 방법은 반구조적(또는 2:4) 희소성이라는 균형을 맞추는 것을 목표로 합니다. 이 희박한 저장 공간은 밀도가 높은 텐서 출력을 생성하는 동시에 원래 텐서를 50% 줄입니다. 아래 그림을 참조하세요.
이 희소 저장 형식과 관련 빠른 커널을 사용하기 위해 다음으로 해야 할 일은 가중치를 잘라내는 것입니다. 이 기사에서는 2:4의 희소성에서 가지치기를 위해 가장 작은 두 개의 가중치를 선택합니다. 기본 PyTorch("스트라이드") 레이아웃에서 이 새로운 반구조적 스파스 레이아웃으로 가중치를 변경하는 것은 쉽습니다. Apply_sparse(모델)를 구현하려면 32줄의 Python 코드만 필요합니다.
2:4의 희소성에서 이 문서는 vit_b 및 배치 크기가 32일 때 SAM 최대 성능을 관찰합니다.
마지막으로 , 이 기사를 한 문장으로 요약하면 다음과 같습니다. 이 기사는 지금까지 PyTorch에서 가장 빠른 Segment Anything 구현을 소개합니다. 이 기사는 공식적으로 출시된 일련의 새로운 기능을 통해 정확성을 잃지 않고 순수 PyTorch에서 원본 SAM을 다시 작성합니다. 관심 있는 독자는 원본 블로그에서 자세한 내용을 확인할 수 있습니다. 참조 링크: https://pytorch.org/blog/accelerating-generative-ai/위 내용은 PyTorch 팀은 원래 구현보다 8배 빠른 '모든 것을 분할' 모델을 다시 작성했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



 CV는 더 이상 존재하지 않습니까? Meta는 "모든 것을 분할"하는 AI 모델을 출시하고 CV는 GPT-3 순간을 가져올 수 있습니다
CV는 더 이상 존재하지 않습니까? Meta는 "모든 것을 분할"하는 AI 모델을 출시하고 CV는 GPT-3 순간을 가져올 수 있습니다


 이러한 변경 사항을 적용한 후 이 문서에서는 특히 소규모 배치(여기 1)에서 개별 커널 호출 간에 상당한 시간 차이가 있음을 확인했습니다. 이 현상에 대한 더 깊은 이해를 얻기 위해 이 기사는 배치 크기 8을 사용한 SAM 추론의 성능 분석으로 시작합니다.
이러한 변경 사항을 적용한 후 이 문서에서는 특히 소규모 배치(여기 1)에서 개별 커널 호출 간에 상당한 시간 차이가 있음을 확인했습니다. 이 현상에 대한 더 깊은 이해를 얻기 위해 이 기사는 배치 크기 8을 사용한 SAM 추론의 성능 분석으로 시작합니다.