
안정적인 비디오 확산이 가능하며 코드 웨이트가 온라인 상태입니다.

- PHPz앞으로
- 2023-11-22 14:30:481483검색
AI 드로잉 회사로 유명한 Stability AI가 드디어 AI 영상 산업에 진출했습니다.
이번 화요일, 안정 확산 기반의 영상 생성 모델인 Stable Video Diffusion이 출시되었고, AI 커뮤니티에서는 즉각 논의가 시작되었습니다
많은 분들이 "드디어 기다렸습니다"라고 말씀해 주셨습니다.
프로젝트 링크: https://github.com/Stability-AI/generative-models
이제 기존 정적 이미지를 사용하여 안정성을 기반으로 몇 초 분량의 비디오
를 생성할 수 있습니다. AI의 독창적인 Stable Diffusion 그래프 모델인 Stable Video Diffusion은 오픈 소스 또는 상업용 순위에서 몇 안 되는 비디오 생성 모델 중 하나가 되었습니다.


아직 모든 분들이 이용할 수는 없지만, Stable Video Diffusion에서 사용자 대기자 등록을 오픈했습니다(https://stability.ai/contact).
소개에 따르면 Stable Video Propagation은 멀티뷰 데이터 세트를 미세 조정하여 단일 이미지의 멀티뷰 합성을 포함하여 다양한 다운스트림 작업에 쉽게 적용할 수 있습니다. Stable AI는 초당 3~30회 속도로 확산될 수 있는 안정적인 영상을 통해 안정적인 확산을 중심으로 구축된 생태계


와 유사하게 이러한 기반을 구축하고 확장하기 위해 다양한 모델이 계획되고 있다고 밝혔습니다. 프레임 속도는 14 및 25 프레임 비디오를 생성합니다
외부 평가에서 Stability AI는 이러한 모델이 사용자 선호도 조사에서 주요 비공개 소스 모델보다 성능이 우수하다는 것을 확인했습니다. Video Diffusion은 현 단계에서 실제 또는 직접적인 상업용 애플리케이션에 적합하지 않으며 보안 및 품질에 대한 사용자 통찰력과 피드백을 기반으로 모델이 개선될 것입니다.

안정적인 영상 전송은 A 안정적인 AI 오픈 소스 모델 제품군의 구성원입니다. 이제 그들의 제품은 이미지, 언어, 오디오, 3D 및 코드와 같은 다양한 양식을 포괄하는 것으로 보이며 이는 인공 지능 개선에 대한 그들의 의지를 완전히 입증합니다

안정적 비디오 확산의 기술적 측면
안정적 잠재력 고해상도 비디오 확산 모델에 비해 비디오 확산 모델은 텍스트-비디오 또는 이미지-비디오의 SOTA 수준에 도달했습니다. 최근에는 2D 이미지 합성을 위해 훈련된 잠재 확산 모델이 시간 레이어를 삽입하고 소규모 고품질 비디오 데이터 세트에 미세 조정하여 생성 비디오 모델로 전환되었습니다. 그러나 훈련 방법은 문헌에 따라 매우 다양하며 현장에서는 아직 비디오 데이터 큐레이션을 위한 통합 전략에 동의하지 않았습니다.
Stable Video Diffusion 논문에서 Stability AI는 비디오 잠재성을 성공적으로 훈련하기 위한 세 가지 단계를 식별하고 평가합니다. 확산 모델 : 텍스트-이미지 사전 훈련, 비디오 사전 훈련 및 고품질 비디오 미세 조정. 또한 고품질 비디오를 생성하기 위해 신중하게 준비된 사전 훈련 데이터 세트의 중요성을 보여주고 자막 및 필터링 전략을 포함하여 강력한 기본 모델을 훈련하기 위한 체계적인 큐레이션 프로세스를 설명합니다.
안정성 AI는 또한 고품질 데이터에 대한 기본 모델 미세 조정의 영향을 논문에서 탐색하고 비공개 소스 비디오 생성에 필적하는 텍스트-비디오 모델을 교육합니다. 이 모델은 이미지-비디오 생성 및 카메라 모션별 LoRA 모듈에 대한 적응성과 같은 다운스트림 작업을 위한 강력한 모션 표현을 제공합니다. 또한 이 모델은 다중 뷰 확산 모델의 기초로 사용할 수 있는 강력한 다중 뷰 3D 사전을 제공할 수도 있습니다. 이 모델은 피드포워드 방식으로 객체의 다중 뷰를 생성합니다. 작은 컴퓨팅 전력 요구 사항 및 성능 또한 이미지 기반 방법보다 뛰어납니다 .

구체적으로 이 모델을 성공적으로 훈련하려면 다음 세 단계가 필요합니다.
1단계: 이미지 사전 훈련. 이 기사에서는 이미지 사전 훈련을 훈련 파이프라인의 첫 번째 단계로 간주하고 Stable Diffusion 2.1에서 초기 모델을 구축하여 비디오 모델에 강력한 시각적 표현을 제공합니다. 이미지 사전 훈련의 효과를 분석하기 위해 이 기사에서는 두 개의 동일한 비디오 모델도 훈련하고 비교합니다. 그림 3a 결과는 사전 훈련된 이미지 모델이 품질과 큐 추적 측면에서 선호된다는 것을 보여줍니다.
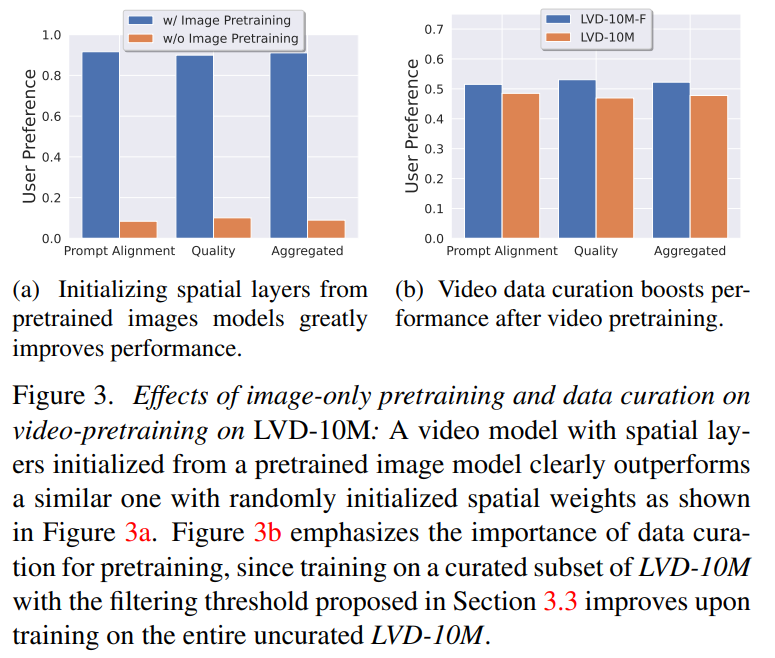
2단계: 비디오 사전 학습 데이터세트. 이 문서에서는 인간의 선호도를 신호로 사용하여 적합한 사전 학습 데이터세트를 만듭니다. 본 글에서 생성된 데이터 세트는 LVD(Large Video Dataset)로, 주석이 달린 5억 8천만 쌍의 비디오 클립으로 구성됩니다.
추가 조사에 따르면 생성된 데이터 세트에 최종 비디오 모델의 성능을 저하시킬 수 있는 몇 가지 예가 포함되어 있는 것으로 나타났습니다. 따라서 본 논문에서는 데이터 세트에 주석을 달기 위해 조밀한 광학 흐름을 사용합니다.
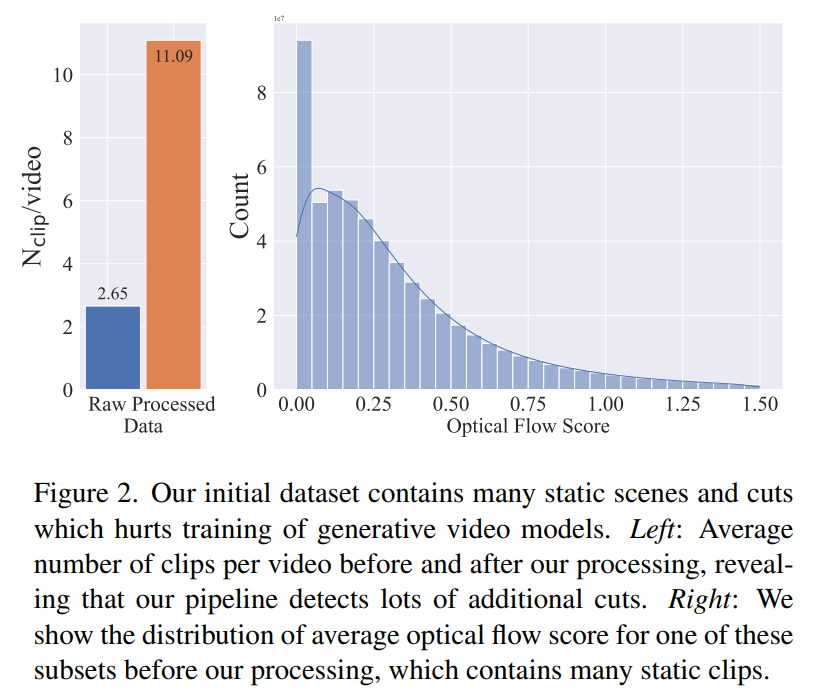
또한 이 논문에서는 광학 문자 인식을 적용하여 많은 양의 텍스트가 포함된 클립을 정리합니다. 마지막으로 CLIP 임베딩을 사용하여 각 클립의 첫 번째, 중간 및 마지막 프레임에 주석을 추가합니다. 다음 표는 LVD 데이터 세트의 일부 통계를 제공합니다.
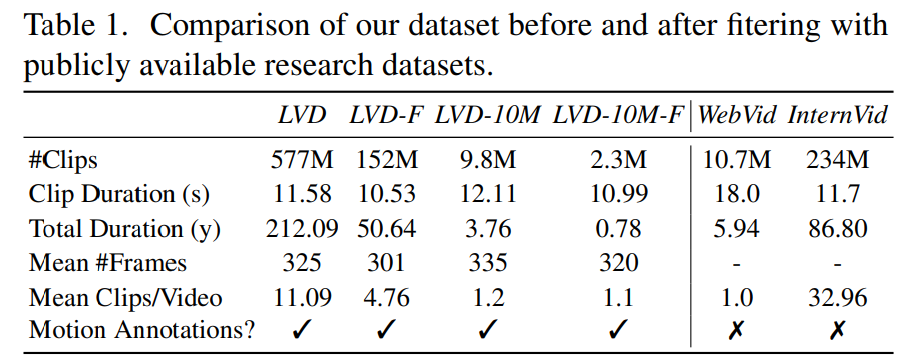
3단계: 고품질 미세 조정. 비디오 사전 훈련이 최종 단계에 미치는 영향을 분석하기 위해 본 논문에서는 초기화만 다른 세 가지 모델을 미세 조정합니다. 그림 4e는 결과를 보여줍니다.

좋은 시작인 것 같습니다. AI를 이용해 직접 영화를 제작할 수 있는 날은 언제쯤 될까?
위 내용은 안정적인 비디오 확산이 가능하며 코드 웨이트가 온라인 상태입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!