
대규모 모델의 검색 기능을 향상시키기 위해 Python 코드 구현

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-11-21 11:21:111831검색
이 글의 주요 초점은 RAG의 개념과 이론입니다. 다음으로 LangChain, OpenAI 언어 모델 및 Weaviate 벡터 데이터베이스를 사용하여 간단한 RAG 오케스트레이션 시스템을 구현하는 방법을 보여드리겠습니다.
검색 향상 생성이란 무엇인가요?
검색 증강 생성(RAG)의 개념은 외부 지식 소스를 통해 LLM에 추가 정보를 제공하는 것을 의미합니다. 이를 통해 LLM은 환각을 줄이면서 보다 정확하고 상황에 맞는 답변을 생성할 수 있습니다.
콘텐츠를 다시 작성할 때 원래 문장 없이 원본 텍스트를 중국어로 다시 작성해야 합니다.
현재 최고의 LLM은 많은 양의 데이터를 사용하여 학습되므로 신경망 가중치가 A에 저장됩니다. 많은 일반 지식(파라미터 메모리). 그러나 프롬프트에서 LLM이 훈련 데이터 이외의 지식(예: 새로운 정보, 독점 데이터 또는 도메인별 정보)이 필요한 결과를 생성하도록 요구하는 경우 콘텐츠를 다시 작성할 때 사실적 부정확성이 발생할 수 있습니다. 아래 스크린샷과 같이 원래 문장(환상) 없이 중국어로 다시 작성되었습니다.
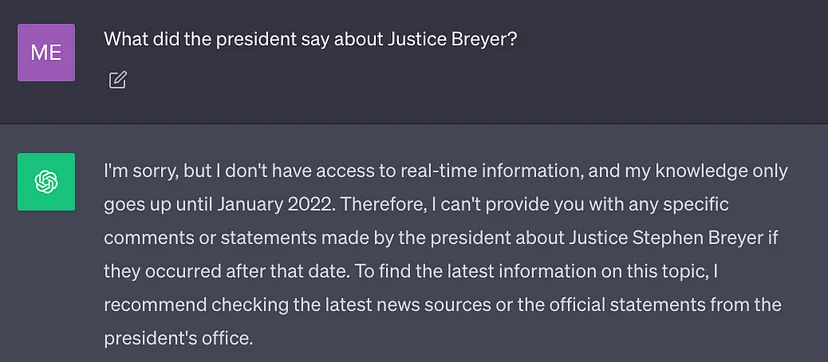
따라서 보다 정확하고 더 많은 상황별 결과 및 환각 감소
솔루션
전통적으로 모델을 미세 조정하여 신경망을 특정 도메인이나 독점 정보에 맞게 조정할 수 있습니다. 이 기술은 효과적이지만, 많은 양의 컴퓨팅 리소스가 필요하고 비용이 많이 들고 기술 전문가의 지원이 필요하므로 변화하는 정보에 빠르게 적응하기가 어렵습니다
2020년에는 Lewis 등의 논문 "Retrieval"이 발표되었습니다. . -지식 집약적 NLP 작업을 위한 증강 생성'에서는 보다 유연한 기술인 검색 강화 생성(RAG)을 제안합니다. 본 논문에서 연구자들은 생성 모델을 보다 쉽게 업데이트할 수 있는 외부 지식 소스를 사용하여 추가 정보를 제공할 수 있는 검색 모듈과 결합합니다.
현지어로 표현하자면: RAG는 LLM에게 오픈북 시험이 인간에게 있는 것과 같습니다. 오픈북 시험의 경우, 학생들은 문제에 답하기 위해 관련 정보를 찾을 수 있는 교과서, 노트 등의 참고 자료를 가져올 수 있습니다. 오픈북 시험의 기본 아이디어는 시험이 학생들의 특정 정보를 암기하는 능력보다는 추론 능력에 초점을 맞춘다는 것입니다.
마찬가지로 사실상의 지식은 LLM 추론 기능과 다르며 쉽게 액세스하고 업데이트할 수 있는 외부 지식 소스에 저장할 수 있습니다.
- 매개변수화된 지식: 훈련 중에 학습한 지식을 암시적으로 포함된 방법은 신경망 가중치.
- 비모수적 지식: 벡터 데이터베이스와 같은 외부 지식 소스에 저장됩니다.
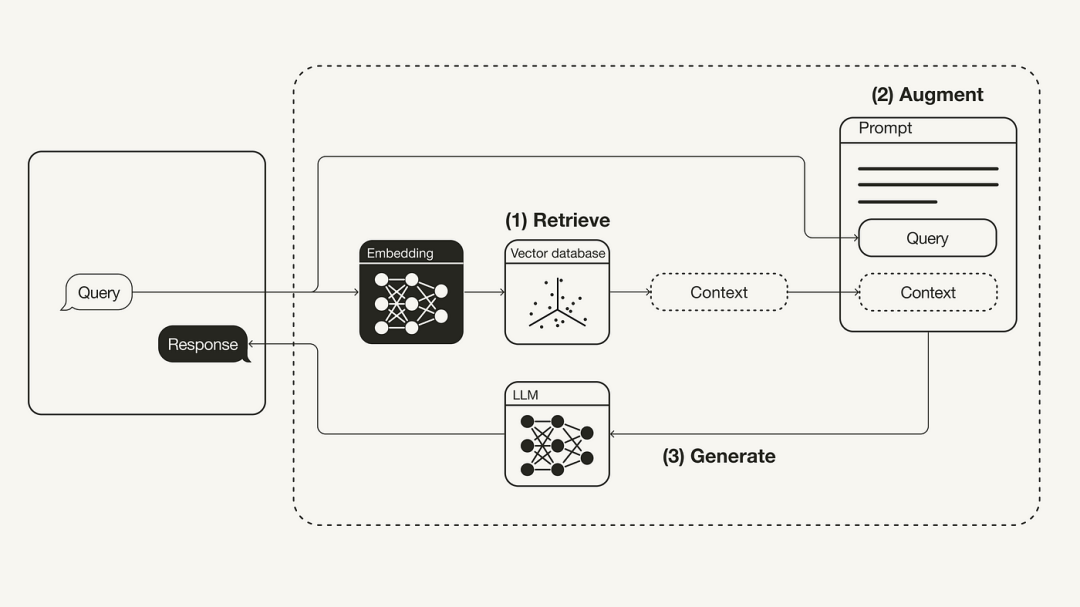
다음 다이어그램은 가장 기본적인 RAG 워크플로를 보여줍니다.
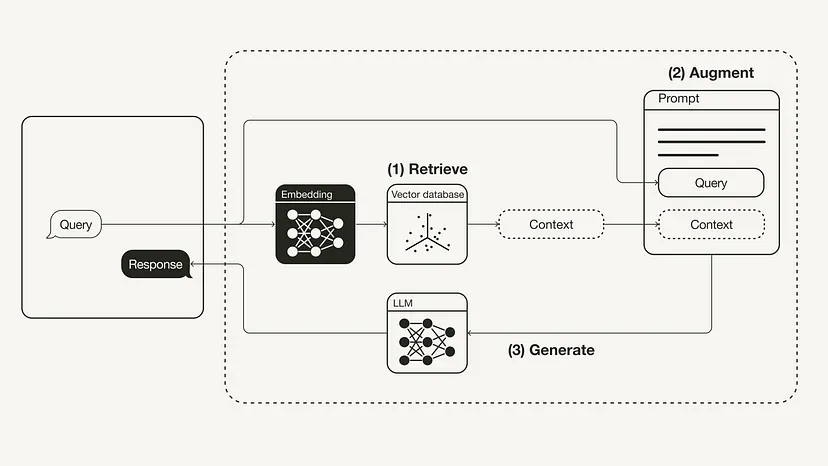
재작성된 콘텐츠: RAG(Retrieval Augmented Generation)의 워크플로 재구축
- 검색: 사용자 쿼리를 적용하여 관련 컨텍스트 검색 외부 지식 소스. 이를 위해 임베딩 모델을 사용하여 사용자 쿼리를 벡터 데이터베이스의 추가 컨텍스트와 동일한 벡터 공간에 임베드합니다. 이를 통해 유사성 검색을 수행하고 사용자 쿼리에 가장 가까운 이 벡터 데이터베이스의 k개 데이터 개체를 반환할 수 있습니다.
- 향상: 사용자 쿼리와 검색된 추가 컨텍스트가 프롬프트 템플릿에 채워집니다.
- 세대: 마지막으로 검색 강화 프롬프트가 LLM에 제공됩니다.
LangChain을 사용하여 검색 향상 생성 구현
다음에서는 OpenAI LLM, Weaviate 벡터 데이터베이스 및 OpenAI 임베딩 모델을 사용하는 Python을 통해 RAG 워크플로를 구현하는 방법을 소개합니다. LangChain의 역할은 오케스트레이션입니다.
다른 말로 바꿔주세요: 필수 전제 조건
필수 Python 패키지가 설치되어 있는지 확인하세요:
- langchain, Orchestration
- openai, 임베디드 모델 및 LLM
- weaviate-client, 벡터 데이터베이스
#!pip install langchain openai weaviate-client
또한 루트 디렉터리의 .env 파일을 사용하여 관련 환경 변수를 정의합니다. OpenAI API 키를 얻으려면 OpenAI 계정이 필요하며, API 키(https://platform.openai.com/account/api-keys)에서 "새 키 생성"을 수행합니다.
OPENAI_API_KEY="<your_openai_api_key>"</your_openai_api_key>
그런 다음 다음 명령을 실행하여 관련 환경 변수를 로드합니다.
import dotenvdotenv.load_dotenv()
준비
준비 단계에서는 모든 추가 정보를 저장하기 위한 외부 지식 소스로 벡터 데이터베이스를 준비해야 합니다. 이 벡터 데이터베이스의 구성에는 다음 단계가 포함됩니다.
- 데이터 수집 및 로드
- 문서 분류
- 텍스트 블록 삽입 및 저장
재작성된 내용: 먼저, 데이터를 수집하고 로드합니다. 예를 들어, 바이든 대통령의 2022년 국정연설을 추가 컨텍스트로 사용하려는 경우 LangChain의 GitHub 저장소는 파일의 원본 텍스트 문서를 제공합니다. 이 데이터를 로드하기 위해 LangChain에 내장된 다양한 문서 로드 도구를 활용할 수 있습니다. 문서는 텍스트와 메타데이터로 구성된 사전입니다. 텍스트를 로드하려면 LangChain의 TextLoader 도구를 사용할 수 있습니다
원본 문서 주소: https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt
import requestsfrom langchain.document_loaders import TextLoaderurl = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"res = requests.get(url)with open("state_of_the_union.txt", "w") as f:f.write(res.text)loader = TextLoader('./state_of_the_union.txt')documents = loader.load()
다음으로 문서를 여러 개의 덩어리로 나눕니다. 문서의 원래 상태가 너무 길어 LLM의 컨텍스트 창에 맞지 않기 때문에 더 작은 텍스트 덩어리로 분할해야 합니다. LangChain에는 또한 많은 내장 분할 도구가 있습니다. 이 간단한 예에서는 Chunk_size를 500으로 설정하고 Chunk_overlap을 50으로 설정하여 텍스트 청크 간의 텍스트 연속성을 유지하는 CharacterTextSplitter를 사용할 수 있습니다.
from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.split_documents(documents)
마지막으로 텍스트 블록을 삽입하고 저장합니다. 텍스트 블록 전체에 걸쳐 의미 검색을 수행하려면 각 텍스트 블록에 대해 벡터 임베딩을 생성하고 해당 임베딩과 함께 저장해야 합니다. 벡터 임베딩을 생성하려면 OpenAI 임베딩 모델을 저장으로 사용하고 Weaviate 벡터 데이터베이스를 사용하세요. .from_documents()를 호출하면 텍스트 블록이 벡터 데이터베이스에 자동으로 채워질 수 있습니다.
from langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Weaviateimport weaviatefrom weaviate.embedded import EmbeddedOptionsclient = weaviate.Client(embedded_options = EmbeddedOptions())vectorstore = Weaviate.from_documents(client = client,documents = chunks,embedding = OpenAIEmbeddings(),by_text = False)
1단계: 검색
벡터 데이터베이스를 채운 후 이를 사용자 쿼리와 내장 블록 간의 의미적 유사성을 기반으로 검색할 수 있는 검색 구성 요소로 정의할 수 있습니다. 추가 컨텍스트
retriever = vectorstore.as_retriever()
2단계: 강화
from langchain.prompts import ChatPromptTemplatetemplate = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.Question: {question} Context: {context} Answer:"""prompt = ChatPromptTemplate.from_template(template)print(prompt)
다음으로 추가 컨텍스트로 프롬프트를 향상하려면 프롬프트 템플릿을 준비해야 합니다. 아래와 같이 프롬프트 템플릿을 사용하여 프롬프트를 쉽게 사용자 정의할 수 있습니다.
3단계: 생성
마지막으로 검색기, 프롬프트 템플릿 및 LLM을 함께 연결하는 이 RAG 프로세스에 대한 사고 체인을 구축할 수 있습니다. RAG 체인이 정의되면
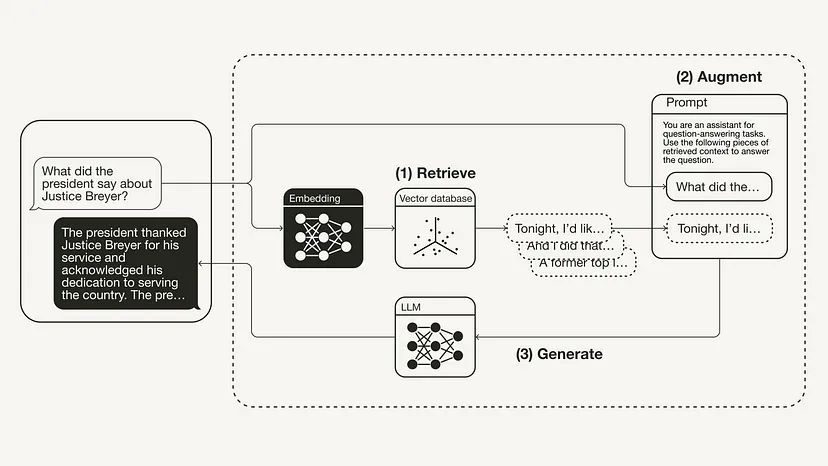
from langchain.chat_models import ChatOpenAIfrom langchain.schema.runnable import RunnablePassthroughfrom langchain.schema.output_parser import StrOutputParserllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)rag_chain = ({"context": retriever,"question": RunnablePassthrough()} | prompt | llm| StrOutputParser() )query = "What did the president say about Justice Breyer"rag_chain.invoke(query)"The president thanked Justice Breyer for his service and acknowledged his dedication to serving the country. The president also mentioned that he nominated Judge Ketanji Brown Jackson as a successor to continue Justice Breyer's legacy of excellence."
라고 할 수 있습니다. 다음 그림은 이 특정 예에 대한 RAG 프로세스를 보여줍니다.
요약
이 기사에서는 RAG의 개념을 소개합니다. 이는 원래 2020년 논문 "지식 집약적 NLP 작업을 위한 검색 증강 생성"에서 나온 것입니다. 동기 부여 및 해결 방법을 포함하여 RAG의 기본 이론을 소개한 후 이 기사에서는 이를 Python에서 구현하는 방법을 보여줍니다. 이 문서에서는 Weaviate 벡터 데이터베이스 및 OpenAI 임베딩 모델과 결합된 OpenAI LLM을 사용하여 RAG 워크플로를 구현하는 방법을 보여줍니다. LangChain의 역할은 오케스트레이션입니다.
위 내용은 대규모 모델의 검색 기능을 향상시키기 위해 Python 코드 구현의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!