
Google, Mirasol 출시: 30억 개의 매개변수로 다중 모드 이해를 긴 동영상으로 확장

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-11-17 23:39:011178검색

11월 16일 뉴스에서 Google은 최근 동영상에 대한 질문에 답변하고 새로운 기록을 세울 수 있는 소형 인공 지능 모델인 Mirasol을 소개하는 보도 자료를 발표했습니다.
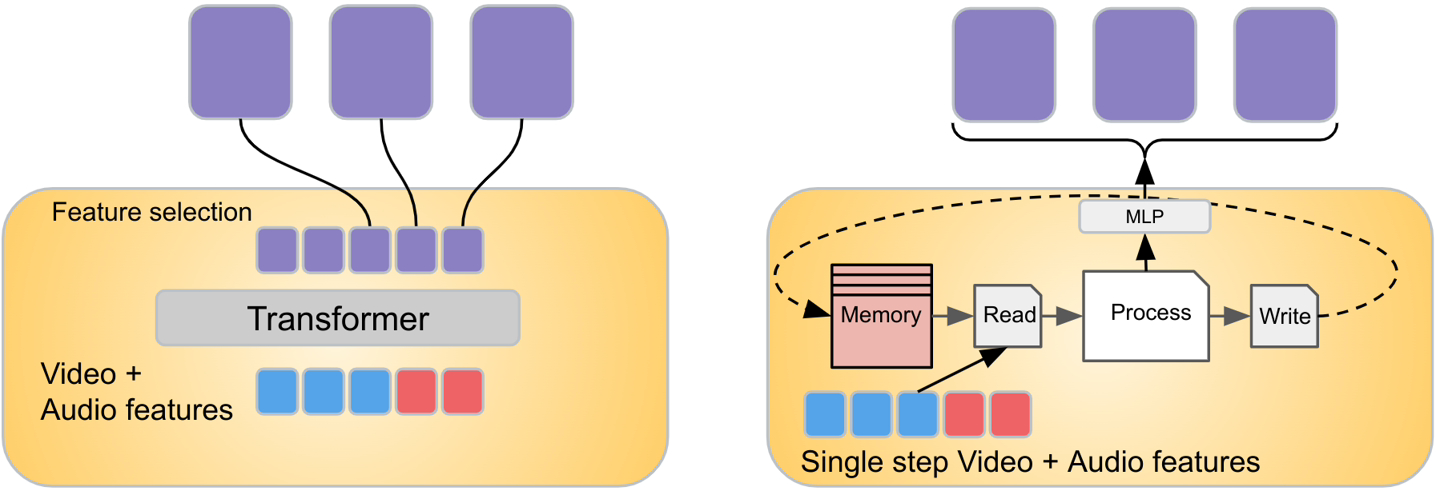
- 비디오와 오디오를 높은 샘플링 주파수로 동기화해야 하지만 제목과 비디오 설명을 비동기적으로 처리해야 합니다.
- 비디오 및 오디오는 많은 양의 데이터를 생성하므로 모델 용량에 부담을 줄 수 있습니다.
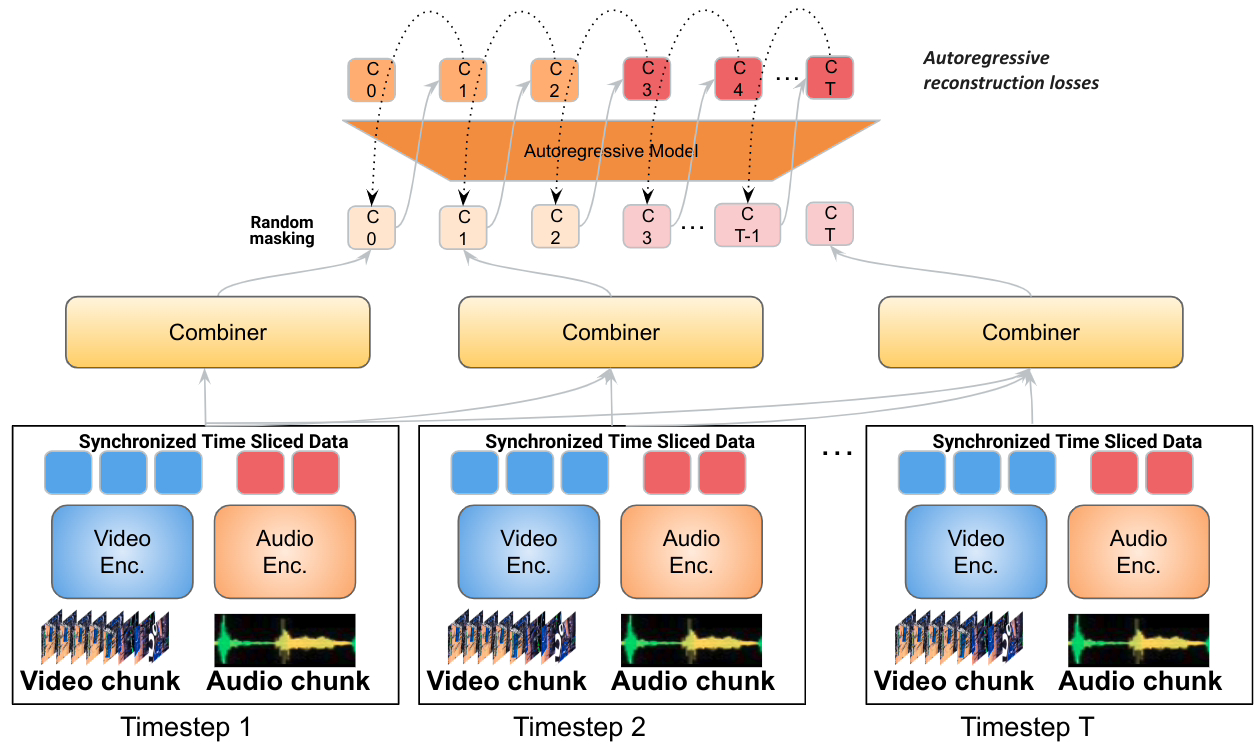
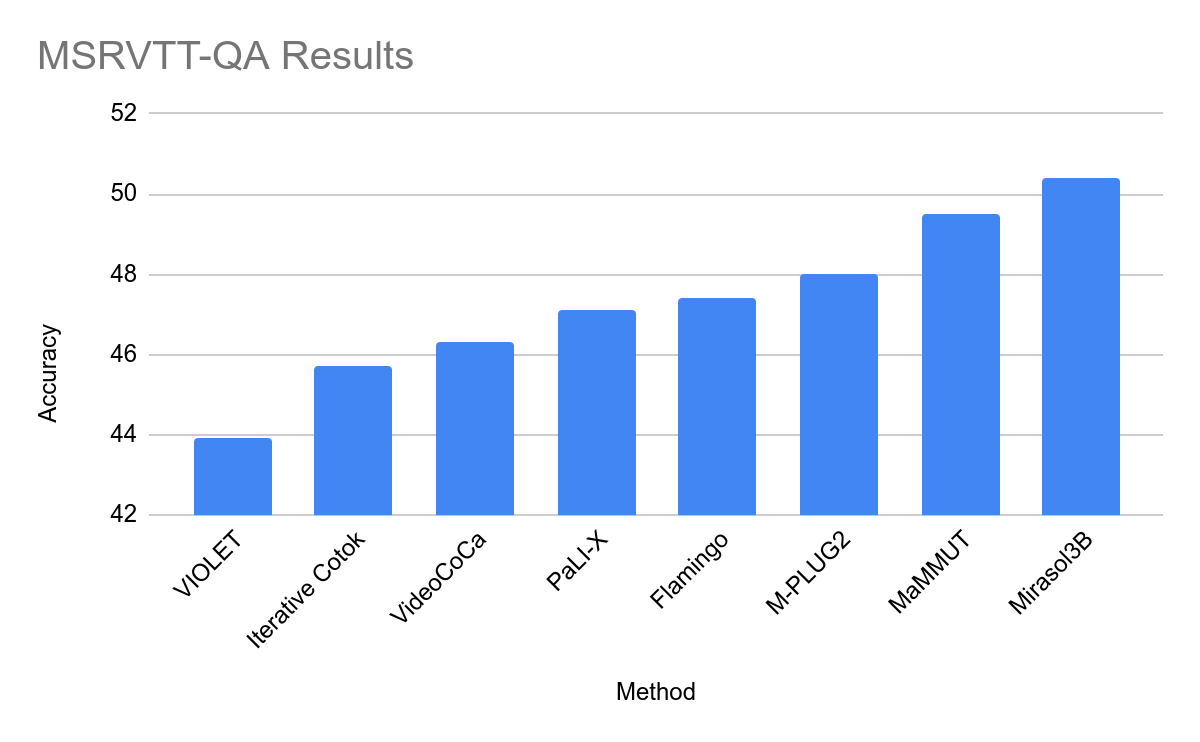
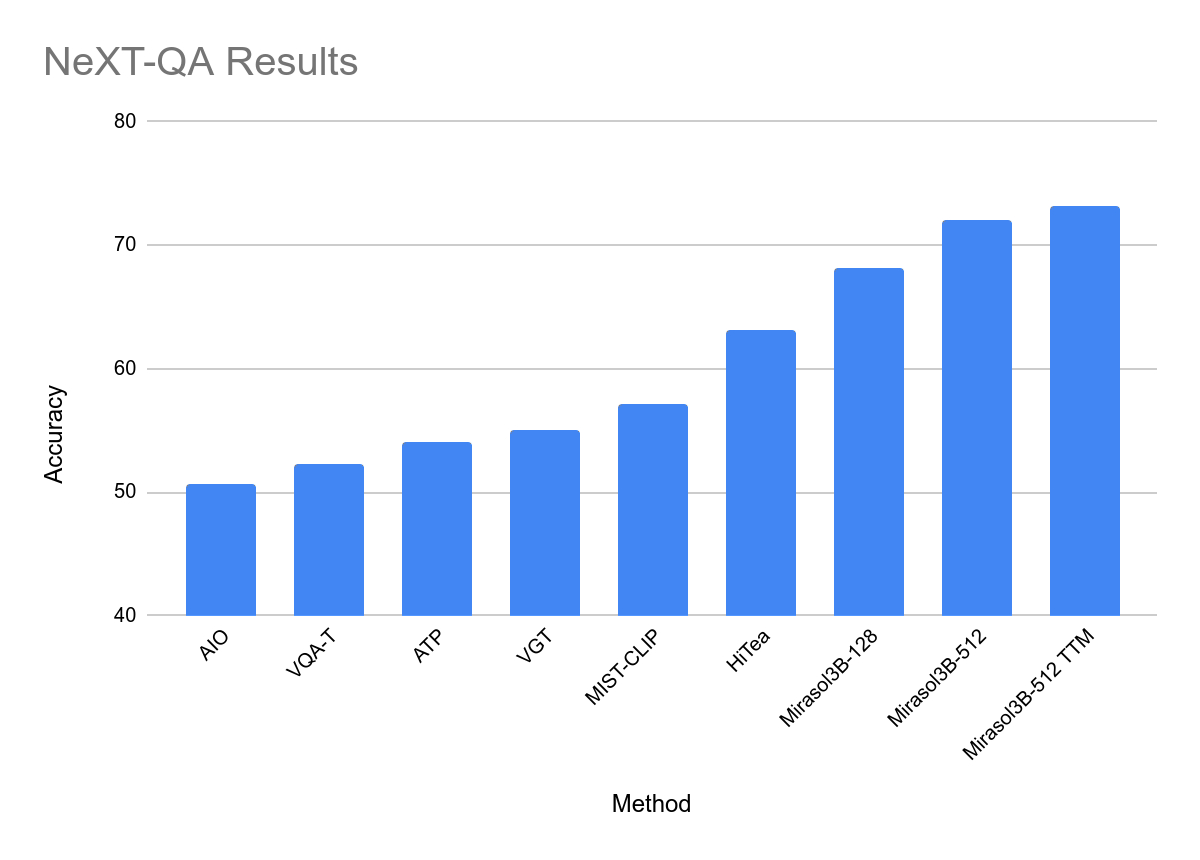
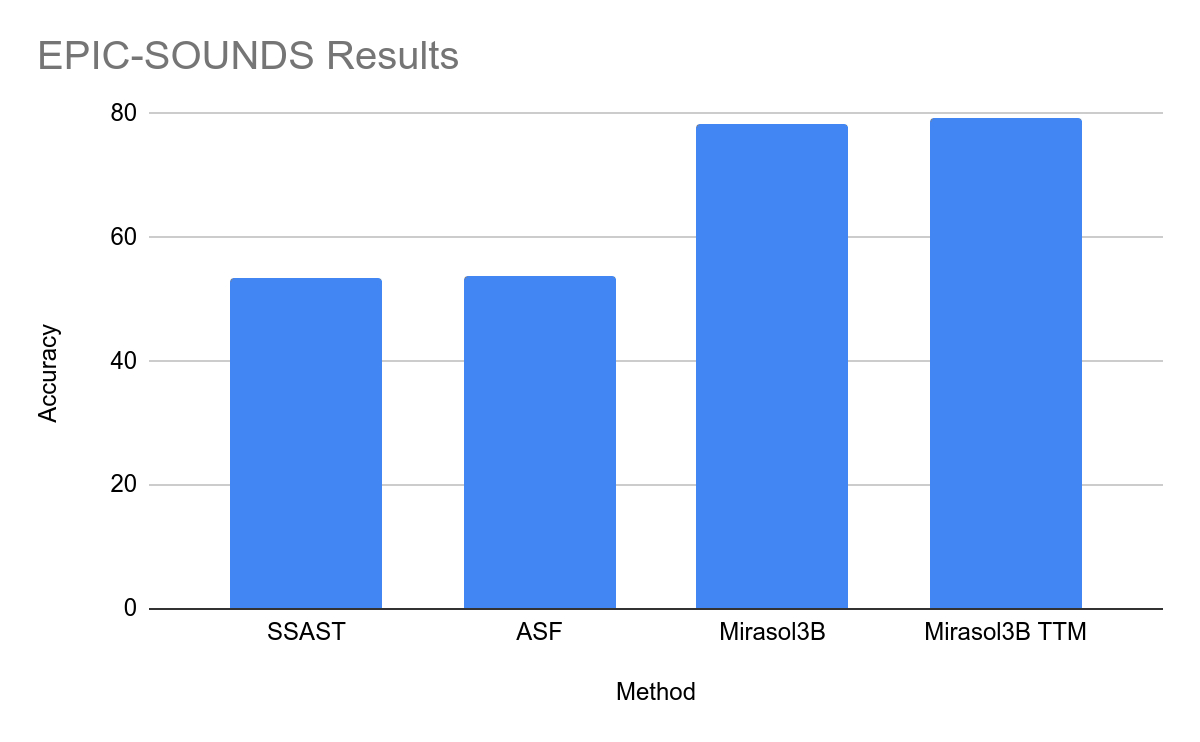
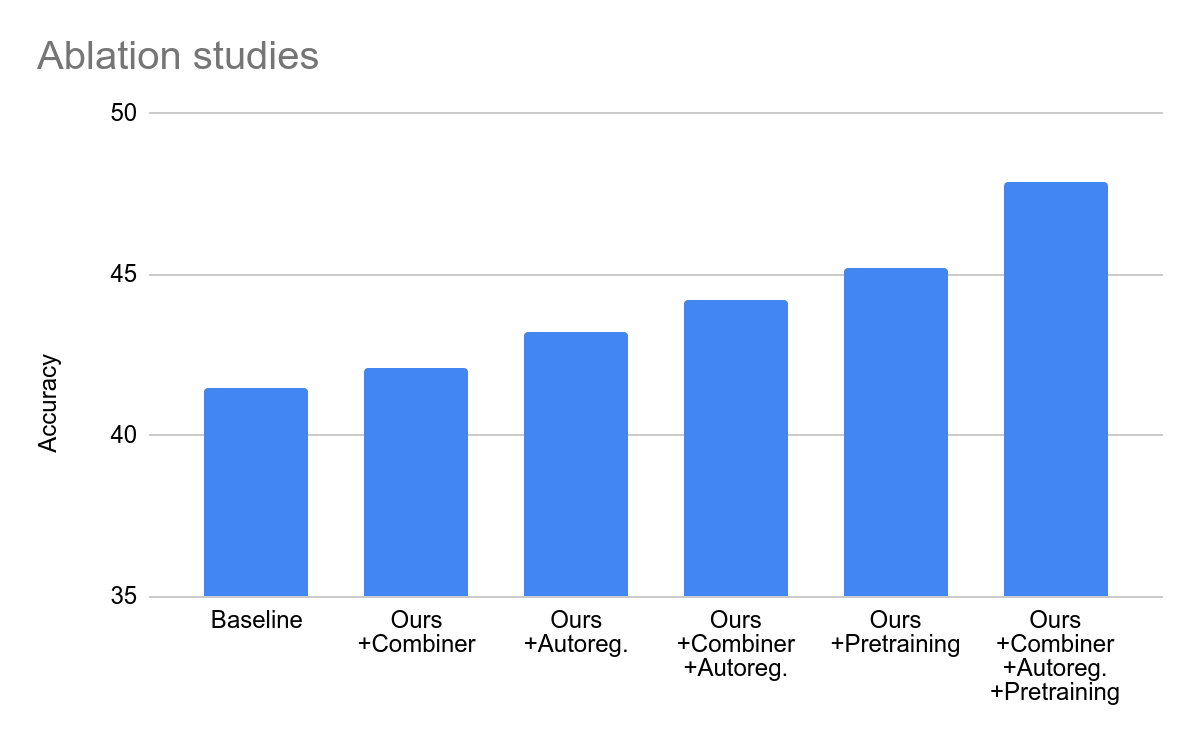
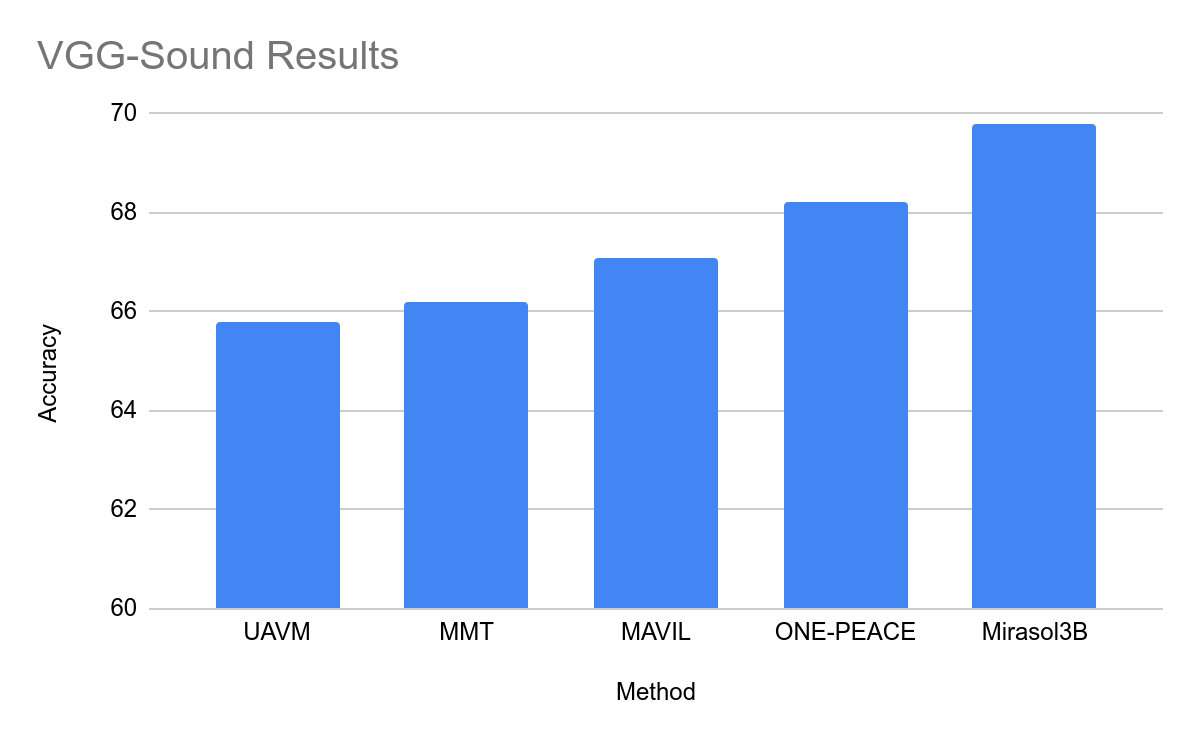
공식 Mirasol Press 버전을 첨부합니다. release , 관심 있는 사용자는 자세히 읽을 수 있습니다.
위 내용은 Google, Mirasol 출시: 30억 개의 매개변수로 다중 모드 이해를 긴 동영상으로 확장의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
이 기사는 51cto.com에서 복제됩니다. 침해가 있는 경우 admin@php.cn으로 문의하시기 바랍니다. 삭제