
대규모 부정 행위 모델을 구별하는 비결 중 하나, 의사 동생의 오픈 소스 AI 수학 '악마 거울'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-11-17 12:38:44777검색
요즘에는 빅모델들이 수학을 잘한다고 주장하는 경우가 많은데, 누가 진짜 재능을 갖고 있나요? 연속 시험 문제에서 누가 "속임수"를 쳤습니까?
올해 헝가리 수학 기말고사
많은 모델들이 갑자기 "원래의 모습을 드러냈습니다".
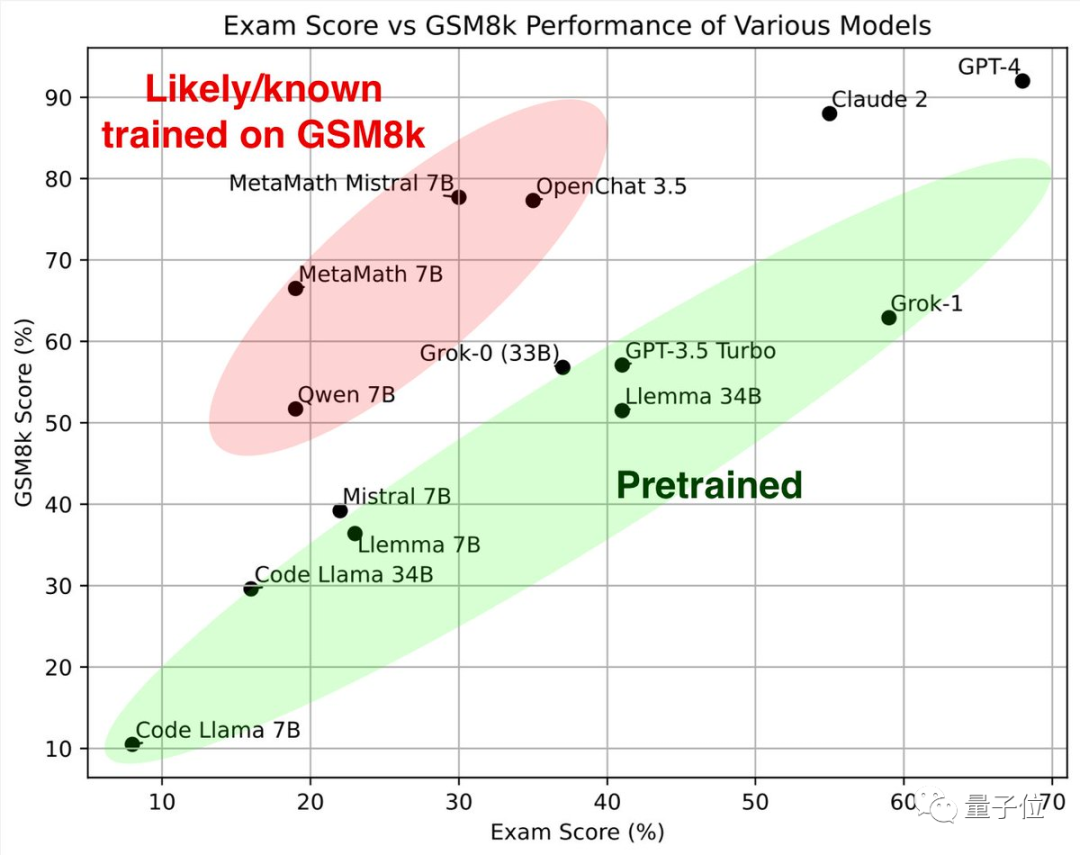
먼저 녹색 부분을 살펴보세요. 이러한 대형 모델은 고전 수학 테스트 세트 GSM8k와 새 논문에서 유사한 결과를 얻었으며 함께 참조 표준을 형성합니다.
빨간색 부분을 보면 GSM8K의 점수는 동일한 매개변수 척도의 대형 모델에 비해 상당히 높습니다. 새 용지에서는 점수가 크게 낮아져 거의 동일합니다. 같은 규모의 대형 모델입니다.
연구원들은 이들을 "GSM8k에 대한 교육을 받은 것으로 의심되거나 알려진"으로 분류했습니다.
이 테스트를 보고 어떤 사람들은 이전에 본 적이 없는 질문에 대한 평가를 시작해야 한다고 말했습니다.

어떤 사람들은 이러한 테스트와 모든 사람들의 실제 대형 모델 사용 경험이 현재 유일한 것이라고 생각합니다. 신뢰할 수 있는 평가 method
Musk Grok은 GPT-4에 이어 두 번째이며, 오픈 소스 Llemma는 우수한 결과를 가지고 있습니다.
테스터Keiran Paster는 토론토 대학의 박사 과정 학생이자 Google 학생 연구원이며, 저자 중 한 명은 테스트에서 대규모 Lemma 모델을 사용했습니다.
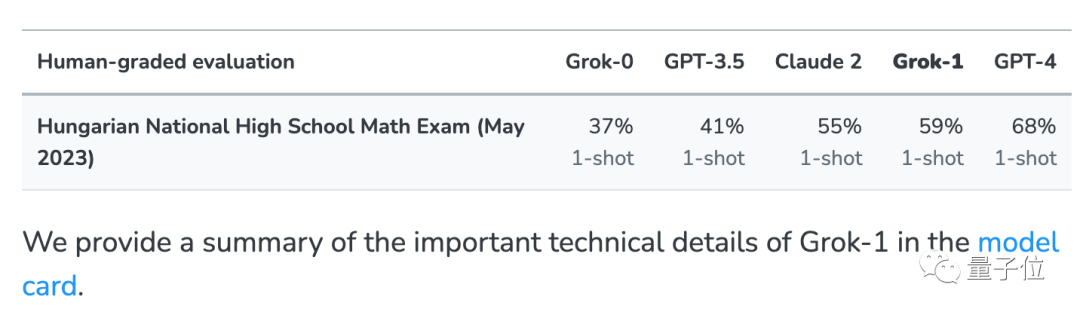
큰 모델이 헝가리 국립 고등학교 수학 최종 시험에 응시하게 하세요. 이 트릭은 Musk의 xAI에서 나온 것입니다.
xAI의 Grok 대형 모델이 실수로 네트워크 데이터에서 테스트 문제를 보는 문제를 해결하기 위해 몇 가지 일반적인 테스트 세트 외에도 이 테스트도 진행되었습니다.
이 시험은 현재 5월 말에야 완료되었습니다. , 대부분의 모델은 기본적으로 이러한 테스트 질문 세트를 본 적이 없습니다.
xAI는 비교를 위해 출시 당시 GPT-3.5, GPT-4, Claude 2의 결과도 발표했습니다.
이 데이터 세트를 기반으로 Paster는 추가 테스트를 수행했습니다. 테스트 대상은 강력한 수학적 생성 기능을 갖춘 여러 오픈 소스 모델
이며 각 모델의 테스트 질문, 테스트 스크립트 및 답변 결과는 모두 모든 사람이 다른 모델을 확인하고 추가 테스트할 수 있도록 Huggingface에 오픈 소스가 있습니다.
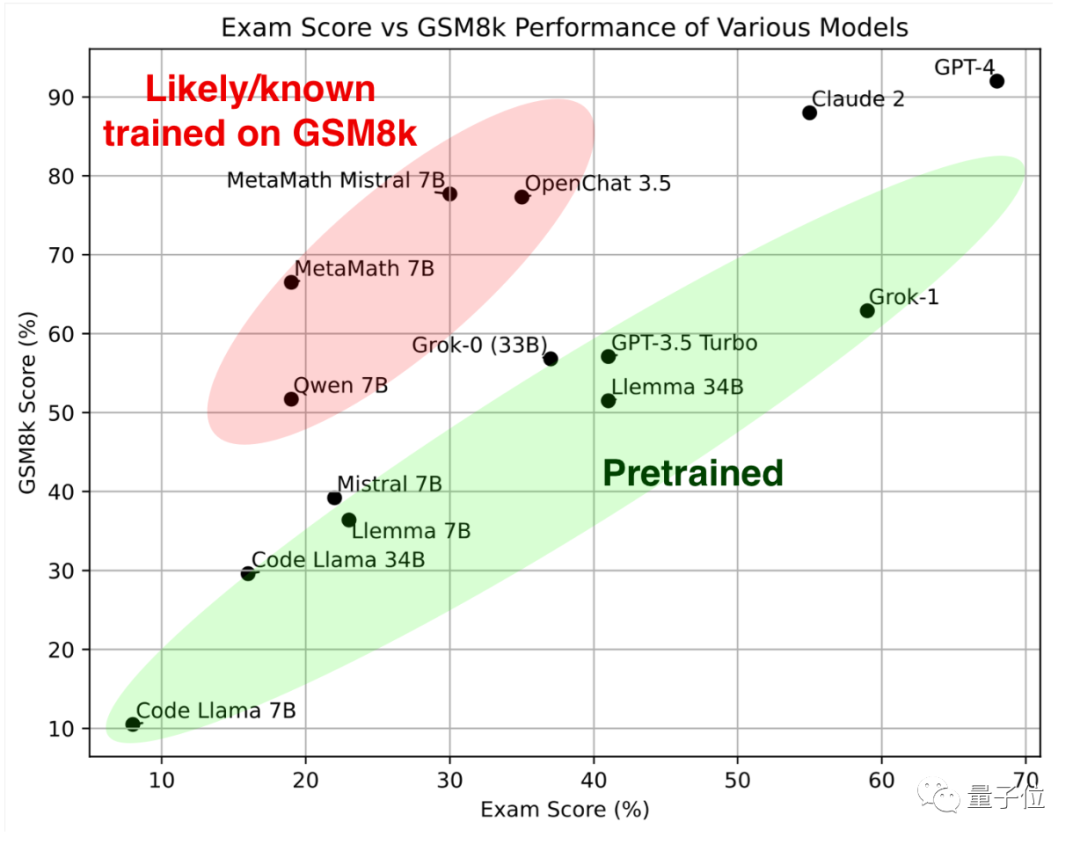
결과에 따르면 GPT-4와 Claude-2가 첫 번째 계층을 형성했으며 GSM8k와 새 논문에서 매우 높은 결과를 얻었습니다.
GPT-4와 Claude 2의 훈련 데이터에 GSM8k 유출 문제가 없다는 뜻은 아니지만, 적어도 그들은 일반화 능력이 좋고 새로운 문제를 올바르게 해결할 수 있으므로 상관하지 않습니다.
다음으로 Musk xAI의 Grok-0(33B) 및 Grok-1(미발표 매개변수 척도) 모두 좋은 성능을 보였습니다.
Grok-1은 "부정 행위를 하지 않는 그룹"에서 가장 높은 점수를 얻었으며, 새 논문 점수는 Claude 2보다 훨씬 높습니다.
GSM8k에서 Grok-0의 성능은 GPT3.5-Turbo에 가깝고 새 종이에서는 약간 더 나쁩니다.
위에서 언급한 폐쇄형 모델을 제외하고 테스트에 참여한 다른 모델은 모두 오픈 소스입니다.
Code Llama 시리즈는 Llama 2를 기반으로 한 Meta 자체 미세 조정으로, 자연어 기반 코드 생성에 중점을 두고 있으며, 지금 보세요 같은 규모의 모델보다 수학적 능력이 약간 떨어집니다.

Code Llama를 기반으로 많은 대학과 연구 기관이 공동으로 Llemma 시리즈를 출시했으며 EleutherAI에서 오픈 소스로 제공했습니다.
팀은 과학 논문, 수학이 포함된 네트워크 데이터 및 수학 코드에서 Proof-Pile-2 데이터 세트를 수집한 후 Llemma는 도구를 사용하고 추가 미세 조정 없이 공식적인 정리 증명을 수행할 수 있습니다.
새 논문에서 Llemma 34B의 성능은 GPT-3.5 Turbo 수준에 가깝습니다

Mistral 시리즈는 프랑스 AI 유니콘인 Mistral AI에 의해 훈련되었습니다. Apache2.0 오픈 소스 계약은 Llama보다 느슨하며 알파카 계열 다음으로 오픈 소스 커뮤니티에서 가장 인기 있는 기본 모델이 되었습니다.
"과적합 그룹" OpenChat 3.5 및 MetaMath Mistral은 모두 Mistral 생태계를 기반으로 미세 조정되었습니다.
MetaMath 및 MAmmoTH Code는 Code Llama 생태계를 기반으로 합니다.
실제 비즈니스에서 대규모 오픈소스 모델을 채택하는 사람들은 이 그룹을 피하는 데 주의해야 합니다. 왜냐하면 단지 순위를 얻기 위해 좋은 성과를 낼 가능성이 높지만 실제 역량은 동급의 다른 모델만큼 강력하지 않을 수 있기 때문입니다. scale

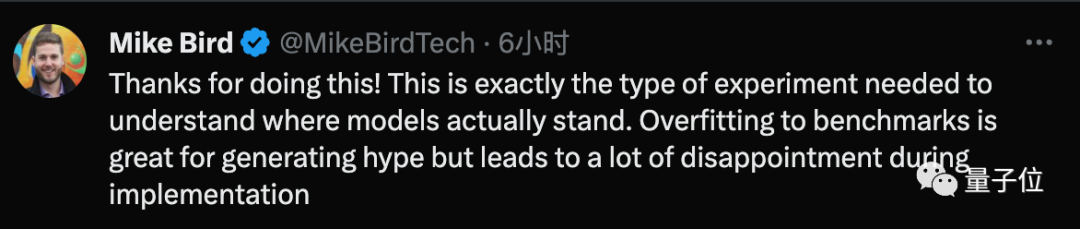
No 많은 네티즌들은 이 실험에 대해 Paster에게 감사를 표시했으며 이것이 바로 모델의 실제 상황을 이해하는 데 필요한 것이라고 믿었습니다.
일부 사람들은 다음과 같이 우려를 표시했습니다.
오늘부터 대형 모델을 교육하는 모든 사람은 이전 연도의 헝가리어 수학 시험 문제를 포함하게 됩니다.
동시에, 그는 독점 테스트를 갖춘 전문 대형 모델 평가 회사를 갖는 것이 해결책이 될 수 있다고 믿습니다.
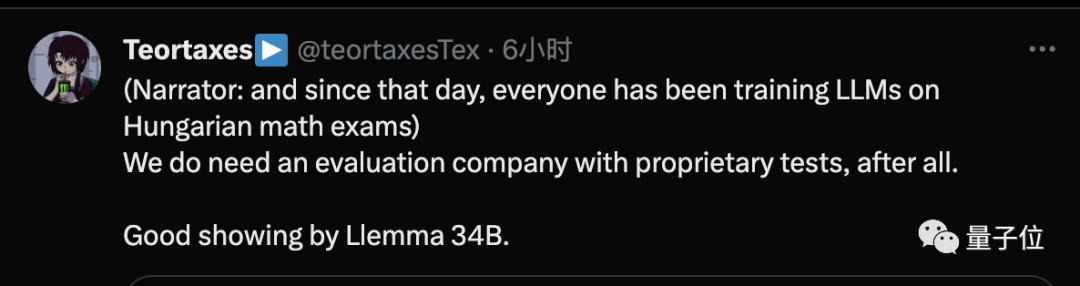
또 다른 제안은 과적합 문제를 완화하기 위해 매년 업데이트되는 테스트 벤치마크를 설정하는 것입니다.

위 내용은 대규모 부정 행위 모델을 구별하는 비결 중 하나, 의사 동생의 오픈 소스 AI 수학 '악마 거울'의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!