
이익 예측은 더 이상 어렵지 않습니다. scikit-learn 선형 회귀 방법을 사용하면 절반의 노력으로 두 배의 결과를 얻을 수 있습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-11-13 20:25:291067검색
1. 소개
생성 인공 지능은 의심할 여지 없이 판도를 바꾸는 기술이지만 대부분의 비즈니스 문제에서는 회귀 및 분류와 같은 전통적인 기계 학습 모델이 여전히 첫 번째 선택입니다.
재작성된 콘텐츠: 사모 펀드나 벤처 캐피탈과 같은 투자자가 기계 학습을 어떻게 활용할 수 있는지 상상해 보세요. 이 질문에 대답하려면 먼저 투자자가 관심을 갖는 데이터가 무엇인지, 그리고 그것이 어떻게 사용되는지 이해해야 합니다. 기업에 대한 투자 결정은 비용, 성장률, 현금 소모율 등의 정량적 데이터뿐만 아니라 창업자의 기록, 고객 피드백, 제품 경험 등의 정성적 데이터도 기반으로 합니다
이 기사에서는 선형 회귀의 기본을 소개합니다. 여기에서 전체 코드를 찾으세요.
다시 작성해야 하는 내용은 다음과 같습니다. [코드]: https://github.com/RoyiHD/linear-regression
2. 프로젝트 설정
이 문서에서는 이 프로젝트에 Jupyter Notebook을 사용합니다. 먼저 일부 라이브러리를 가져옵니다.
라이브러리 가져오기
# 绘制图表import matplotlib.pyplot as plt# 数据管理和处理from pandas import DataFrame# 绘制热力图import seaborn as sns# 分析from sklearn.metrics import r2_score# 用于训练和测试的数据管理from sklearn.model_selection import train_test_split# 导入线性模型from sklearn.linear_model import LinearRegression# 代码注释from typing import List
3.Data
문제를 단순화하기 위해 이 문서에서는 지역 데이터를 사용합니다. 데이터는 회사의 비용 범주와 이익을 나타냅니다. 다양한 데이터 포인트의 몇 가지 예를 볼 수 있습니다. 이 기사에서는 지출 데이터를 사용하여 선형 회귀 모델을 학습하고 수익을 예측하고자 합니다.
이 기사에 설명된 데이터는 회사의 지출에 관한 것임을 이해하는 것이 중요합니다. 지출 데이터와 매출 성장, 지방세, 상각비 및 시장 상황에 대한 데이터가 결합되어야 의미 있는 예측력이 가능합니다.
마케팅
|
|
|
|
|
|
|
|
153441.51 |
101145.55 |
다시 작성해야 할 항목은 407934.54 |
다시 작성해야 할 항목입니다. 현재: 1 91050.39 |
加载数据
companies: DataFrame = pd.read_csv("companies.csv", header = 0)
4、数据可视化
了解数据对于确定要使用的特征、需要进行归一化和转换的特征、从数据中删除异常值以及对特定数据点进行的处理是很重要的。
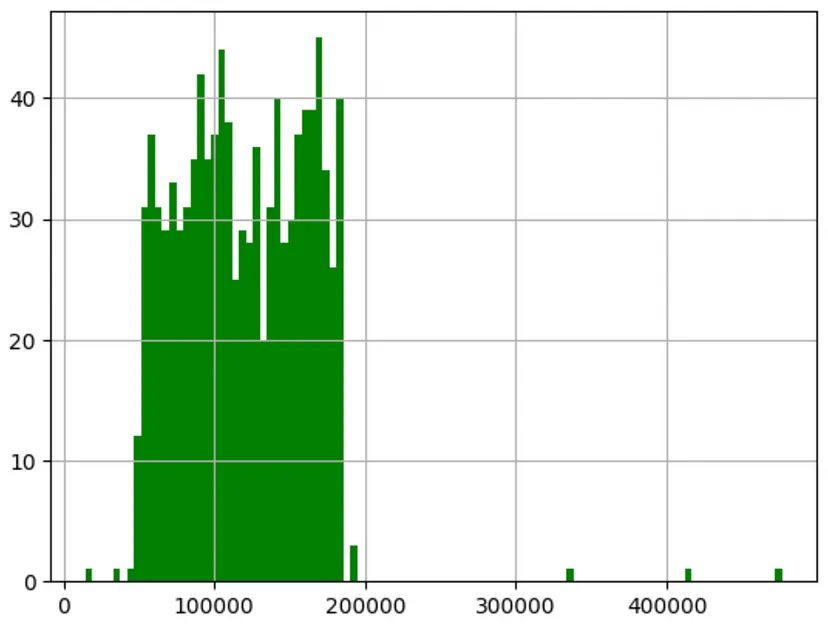
目标(利润)直方图
可以直接使用DataFrame绘制直方图(Pandas使用Matplotlib来绘制数据帧),可以直接访问利润并绘制它。
companies['Profit'].hist( color='g', bins=100);
 图片
图片
从数据中可以清楚地看出,利润超过20万美元的异常值非常罕见。这表明本文所涉及的数据代表的是规模较大的公司。鉴于异常值数量较少,可以将其保留
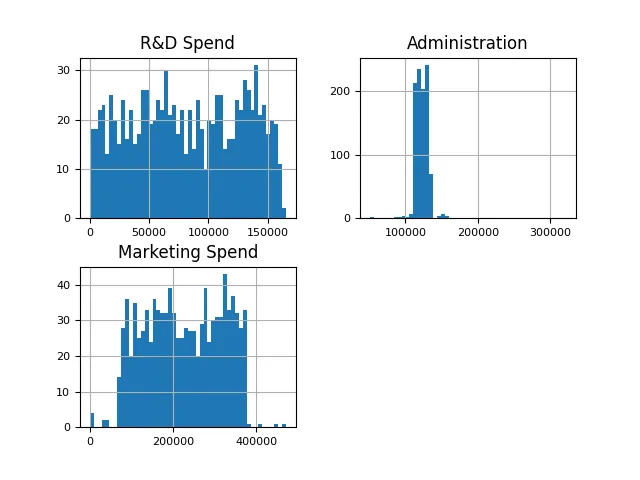
特征(支出)直方图
在这里,本文旨在使用特征的直方图,并观察其分布情况。Y轴表示数字频率,X轴表示支出
companies[["R&D Spend", "行政管理", "Marketing Spend"]].hist(figsize=(16, 20), bins=50, xlabelsize=8, ylabelsize=8)
 图片
图片
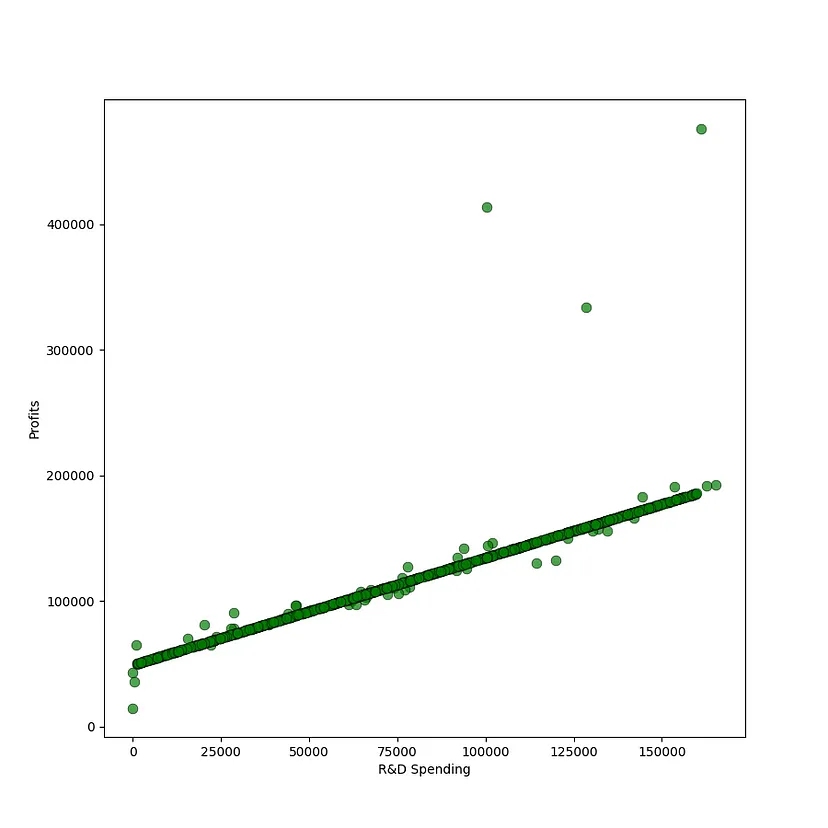
可以观察到一个健康的分布,只有很少的异常值。根据直觉,可以预期投入更多资金在研发和市场营销上的公司会获得更高的利润。从下面的散点图中可以看出,研发支出和利润之间存在明显的相关性
profits: DataFrame = companies[["Profit"]]research_and_development_spending: DataFrame = companies[["R&D Spend"]]figure, ax = plt.subplots(figsize = (9, 9))plt.xlabel("R&D Spending")plt.ylabel("Profits")ax.scatter(research_and_development_spending, profits, s=60, alpha=0.7, edgecolors="k",color='g',linewidths=0.5)
 图片
图片
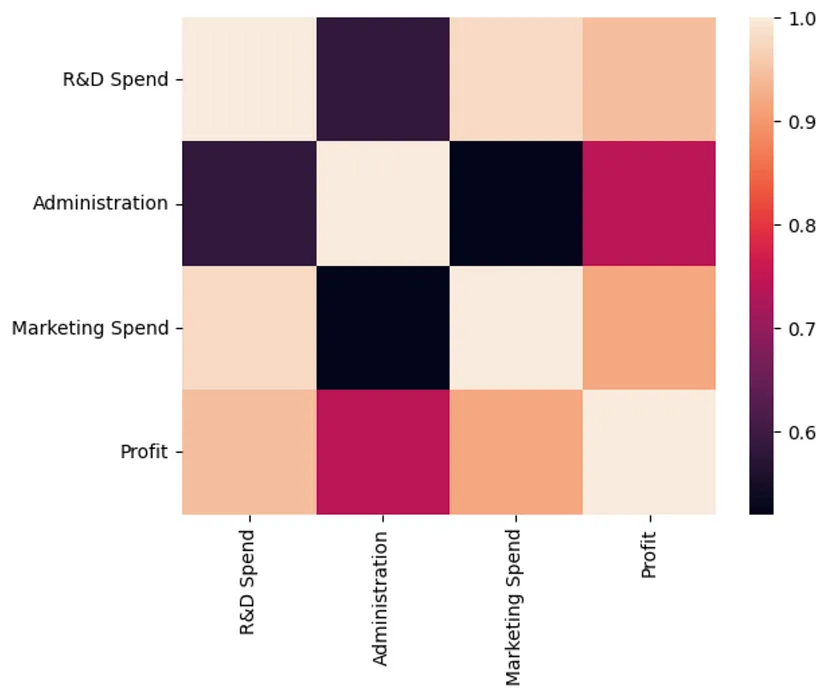
可以使用相关的热图来进一步探索支出和利润之间的关系。从图中可以观察到研发和市场营销支出与利润之间的相关性比行政支出更高
sns.heatmap(companies.corr())
 图片
图片
5、模型训练
首先需要将数据集分割为训练集和测试集两部分。Sklearn提供了一个辅助方法来完成这个任务。鉴于本文的数据集很简单且足够小,可以按照以下方式将特征和目标分离开来。
数据集
features: DataFrame = companies[["R&D Spend", "行政管理", "Marketing Spend",]]targets: DataFrame = companies[["Profit"]]train_features, test_features, train_targets, test_targets = train_test_split(features, targets,test_size=0.2)
大多数数据科学家会使用不同的命名约定,如X_train、y_train或其他类似的变体。
模型训练
现在可以创建并训练模型了。Sklearn使事情变得非常简单。
model: LinearRegression = LinearRegression()model.fit(train_features, train_targets)
6、模型评估
本文希望对模型的性能及其可用性进行评估。首先查看一下计算得到的系数。在机器学习中,系数是用来与每个特征相乘的学习到的权重或数值。期望看到每个特征都有一个学习系数。
coefficients = model.coef_"""We should see the following in our consoleCoefficients[[0.55664299 1.08398919 0.07529883]]"""
正如上述所看到的,有3个系数,每个特征对应一个系数(“研发支出”、“行政支出”、“市场营销支出”)。还可以将其绘制成图表,以便更直观地了解每个系数。
plt.figure()plt.barh(train_features.columns, coefficients[0])plt.show()
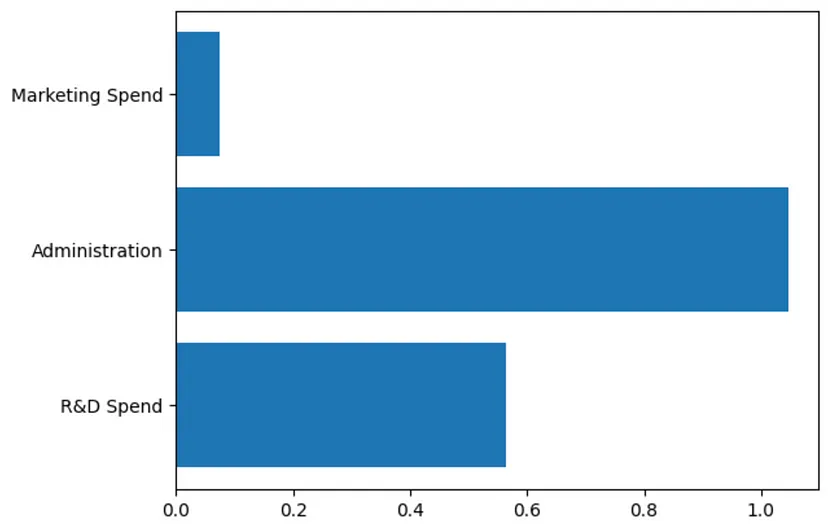 图片
图片
计算误差
希望了解模型的误差率,我们将使用Sklearn的R2得分
test_predictions: List[float] = model.predict(test_features)root_squared_error: float = r2_score(test_targets, test_predictions)"""floatWe should see an ouput similar to this0.9781424529214315"""
离1越近,模型就越准确。实际上可以用一种非常简单的方式对这一点进行测试。
使用下面的支出模型来预测利润,并希望得到一个接近192261美元的数字,可以提取数据集的第一行
"R&D Spend" |"行政管理" |"Marketing Spend" | "Profit"需要进行重写的内容是:165349.2 136897.8需要重写的内容是:471784.1需要改写的内容是:192261.83
接下来创建一个推理请求。
inference_request: DataFrame = pd.DataFrame([{"R&D Spend":需要进行重写的内容是:165349.2, "行政管理":136897.8, "Marketing Spend":需要重写的内容是:471784.1 }])
运行模型。
inference: float = model.predict(inference_request)"""We should get a number that is around199739.88721901"""
现在可以看到的误差率是abs(199739-192261)/192261=0.0388。这是非常准确的。
7、结论
处理数据、搭建模型和分析数据有很多方法。没有一种解决方案适用于所有情况,当用机器学习解决业务问题时,其中一个关键过程是搭建多个旨在解决同一个问题的模型,并选择最有前途的模型
위 내용은 이익 예측은 더 이상 어렵지 않습니다. scikit-learn 선형 회귀 방법을 사용하면 절반의 노력으로 두 배의 결과를 얻을 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!