
대규모 모델의 물결에 따른 시계열 예측에 관한 기사

- 王林앞으로
- 2023-11-06 08:13:381287검색
오늘은 시계열 예측에 대형 모델을 적용하는 방법에 대해 말씀드리겠습니다. NLP 분야에서 대형 모델이 개발되면서 시계열 예측 분야에 대형 모델을 적용하려는 연구가 점점 더 많아지고 있습니다. 본 논문에서는 대형모형을 시계열 예측에 적용하는 주요 방법을 소개하고, 대형모형 시대의 시계열 예측 연구방법에 대한 이해를 돕기 위해 최근 관련 연구를 요약한다.
1. 대형 모델 시계열 예측 방법
지난 3개월 동안 대형 모델 시계열 예측 작업이 많이 등장했는데, 이는 기본적으로 두 가지 유형으로 나눌 수 있습니다.
재작성된 콘텐츠: 한 가지 접근 방식은 시계열 예측을 위해 NLP의 대규모 모델을 직접 사용하는 것입니다. 이 방법에서는 시계열 예측을 위해 GPT, Llama와 같은 대형 NLP 모델이 사용됩니다. 두 번째는 시계열 분야에서 대형 모델을 학습시키는 것입니다. 이러한 유형의 방법에서는 시계열 필드에서 GPT 또는 Llama와 같은 대규모 모델을 공동으로 훈련하고 다운스트림 시계열 작업에 사용되는 데 다수의 시계열 데이터 세트가 사용됩니다.
위의 두 가지 방법에 대해 관련된 고전 대형 모델 시계열 표현 작업은 다음과 같습니다.
2. NLP 대형 모델을 시계열에 적용
이 방법은 최초의 대규모 모델 시계열 예측 작업 중 하나입니다.
뉴욕 대학교와 카네기 멜론 대학교가 공동으로 발표한 논문 "Large Language Models as Zero Samples" "Time Series Predictor"에서는 시계열의 디지털 표현을 토큰화하여 GPT 및 LLaMa와 같은 대형 모델에서 인식할 수 있는 입력으로 변환하도록 설계되었습니다. 다양한 대규모 모델은 숫자를 다르게 토큰화하므로 다양한 모델을 사용할 때는 개인화가 필요합니다. 예를 들어 GPT는 일련의 숫자를 여러 하위 시퀀스로 분할하여 모델 학습에 영향을 미칩니다. 따라서 이 문서에서는 GPT의 입력 형식을 수용하기 위해 숫자 사이에 공백을 강제로 적용합니다. LLaMa 등 최근 출시된 대형 모델의 경우 일반적으로 개별번호가 구분되어 있으므로 공백을 추가할 필요가 없습니다. 동시에 너무 큰 시계열 값으로 인해 입력 시퀀스가 너무 길어지는 것을 방지하기 위해 기사에서는 일부 스케일링 작업을 수행하여 원래 시계열 값을 보다 합리적인 범위로 제한합니다
Pictures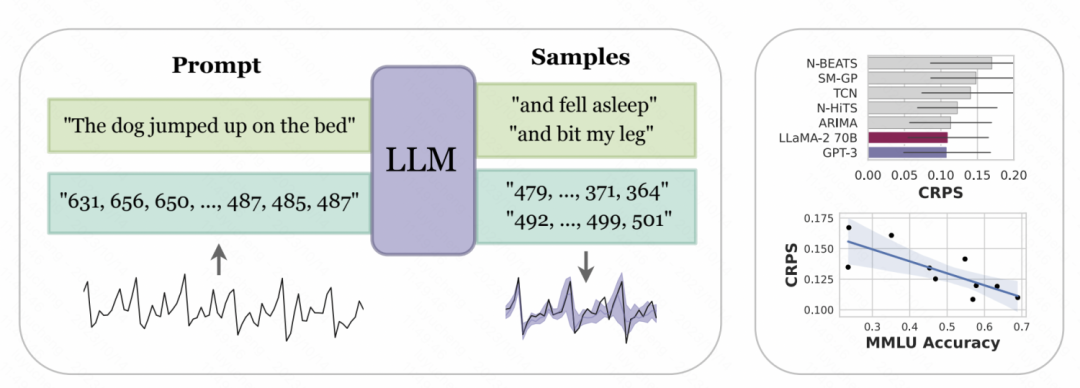 위 처리 후 숫자 문자 대형 모델에 문자열이 입력되고, 대형 모델은 자동 회귀적으로 다음 숫자를 예측하고 최종적으로 예측된 숫자를 해당 시계열 값으로 변환합니다. 아래 그림은 언어 모델의 조건부 확률을 사용하여 이전 숫자를 기반으로 다음 숫자가 각 숫자가 될 확률을 예측하는 것입니다. 이는 표현과 결합됩니다. 대형 모델의 능력은 다양한 분포 유형에 적응할 수 있기 때문에 이러한 방식으로 대형 모델을 시계열 예측에 사용할 수 있습니다. 동시에, 모델에 의해 예측된 다음 숫자의 확률은 시계열의 불확실성 추정을 달성하기 위해 불확실성 예측으로 변환될 수도 있습니다.
위 처리 후 숫자 문자 대형 모델에 문자열이 입력되고, 대형 모델은 자동 회귀적으로 다음 숫자를 예측하고 최종적으로 예측된 숫자를 해당 시계열 값으로 변환합니다. 아래 그림은 언어 모델의 조건부 확률을 사용하여 이전 숫자를 기반으로 다음 숫자가 각 숫자가 될 확률을 예측하는 것입니다. 이는 표현과 결합됩니다. 대형 모델의 능력은 다양한 분포 유형에 적응할 수 있기 때문에 이러한 방식으로 대형 모델을 시계열 예측에 사용할 수 있습니다. 동시에, 모델에 의해 예측된 다음 숫자의 확률은 시계열의 불확실성 추정을 달성하기 위해 불확실성 예측으로 변환될 수도 있습니다.
Pictures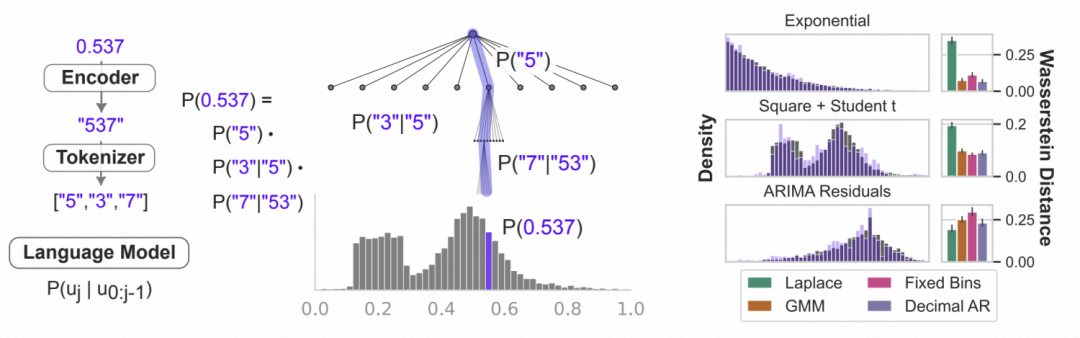 "TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS"라는 제목의 또 다른 기사에서 저자는 시계열을 텍스트로 변환하는 재프로그래밍 방법을 제안했습니다. and text
"TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS"라는 제목의 또 다른 기사에서 저자는 시계열을 텍스트로 변환하는 재프로그래밍 방법을 제안했습니다. and text
구체적인 구현 방법은 먼저 시계열을 여러 개의 패치로 나누고 각 패치는 MLP를 통해 임베딩을 얻는 것입니다. 그런 다음 패치 임베딩은 언어 모델의 단어 벡터에 매핑되어 시계열 세그먼트와 텍스트의 매핑 및 교차 모달 정렬을 달성합니다. 이 기사에서는 일정 기간 동안 일련의 패치 의미를 표현하기 위해 여러 단어를 프로토타입에 매핑하는 텍스트 프로토타입 아이디어를 제안합니다. 예를 들어, 아래 예에서 Shot 및 Up이라는 단어는 시계열의 단기 상승 하위 시퀀스 패치에 해당하는 빨간색 삼각형에 매핑됩니다.
Pictures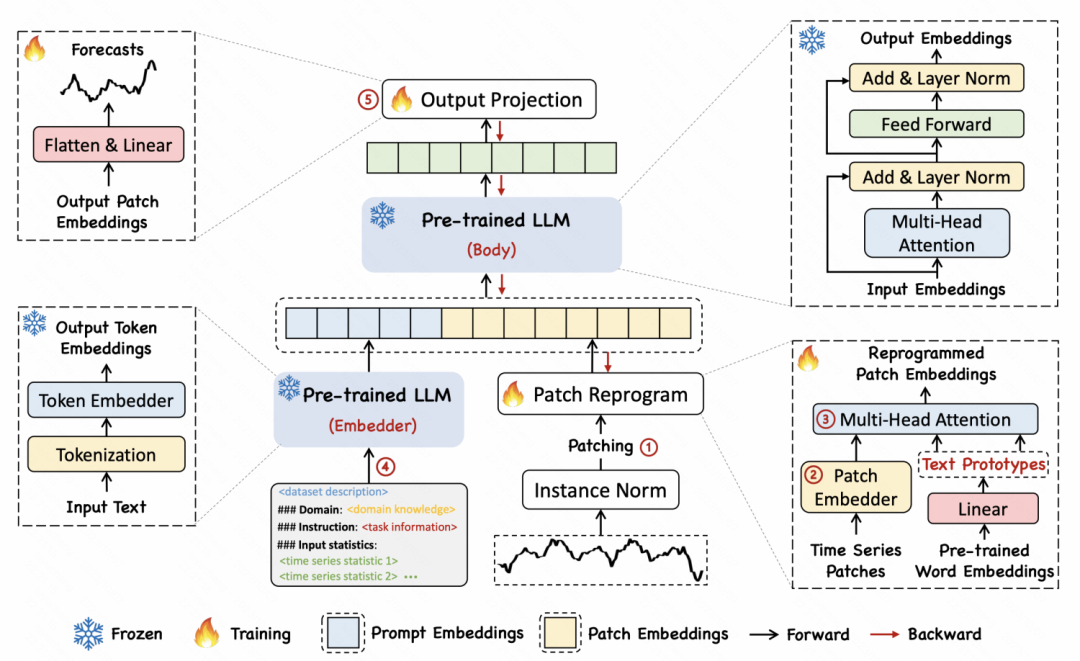 3. 시계열 대형 모델
3. 시계열 대형 모델
또 다른 연구 방향은 자연어 처리 분야의 대형 모델 구축 방법을 참조하여 시계열 예측을 위한 대형 모델을 직접 구축하는 것입니다
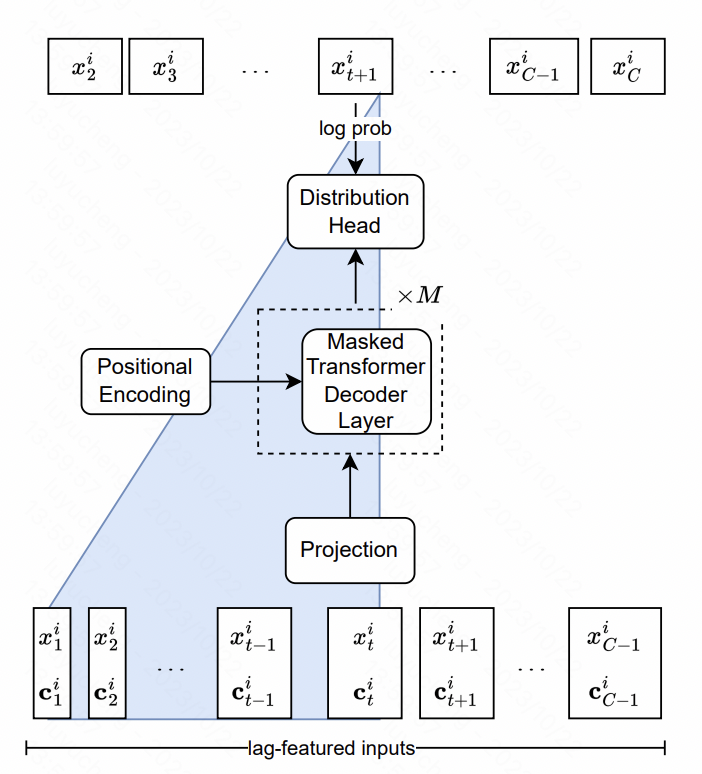
Lag-Llama : 시계열 예측을 위한 기초 모델을 향하여 이 기사에서는 시계열로 Llama 모델을 구축합니다. 핵심에는 기능 수준 및 모델 구조 수준의 설계가 포함됩니다.
특징 측면에서 기사에서는 주로 원본 시계열의 서로 다른 시간대에 있는 과거 시퀀스 통계 값인 다중 규모 및 다중 유형 지연 특성을 추출합니다. 이러한 시퀀스는 추가 기능으로 모델에 입력됩니다. 모델 구조 측면에서 NLP의 LlaMA 구조의 핵심은 정규화 방법과 위치 인코딩 부분이 최적화된 Transformer이다. 최종 출력 레이어는 확률 분포의 매개변수를 맞추기 위해 여러 헤드를 사용합니다. 예를 들어, 이 기사에서는 가우스 분포가 평균 분산을 맞추고 자유도, 평균 및 척도의 세 가지 해당 매개변수를 사용합니다. 출력되고, 최종적으로 각 시점의 예측 확률 분포 결과가 얻어집니다.
 Pictures
Pictures
또 다른 유사한 작업은 시계열 분야에서 GPT 모델을 구축하는 TimeGPT-1입니다. 데이터 교육 측면에서 TimeGPT는 다양한 유형의 도메인 데이터와 관련된 총 100억 개의 데이터 샘플 포인트에 도달하는 대량의 시계열 데이터를 사용합니다. 훈련 중에는 훈련 견고성을 향상시키기 위해 더 큰 배치 크기와 더 작은 학습 속도가 사용됩니다. 모델의 주요 구조는 고전적인 GPT 모델입니다
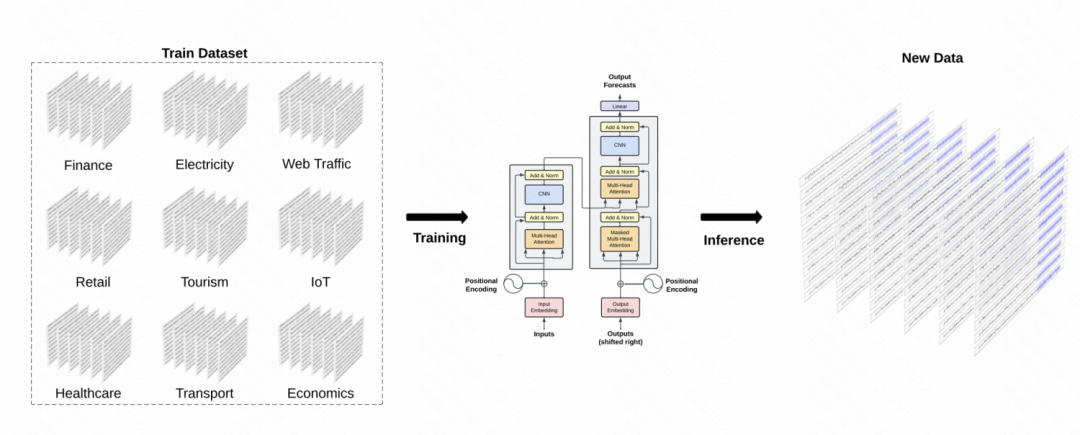 picture
picture
아래 실험 결과에서도 일부 제로 샘플 학습 작업에서 이 시계열 사전 훈련된 대형 모델이 더 나은 결과를 얻었음을 알 수 있습니다. 기본 모델보다 성능이 대폭 향상되었습니다.
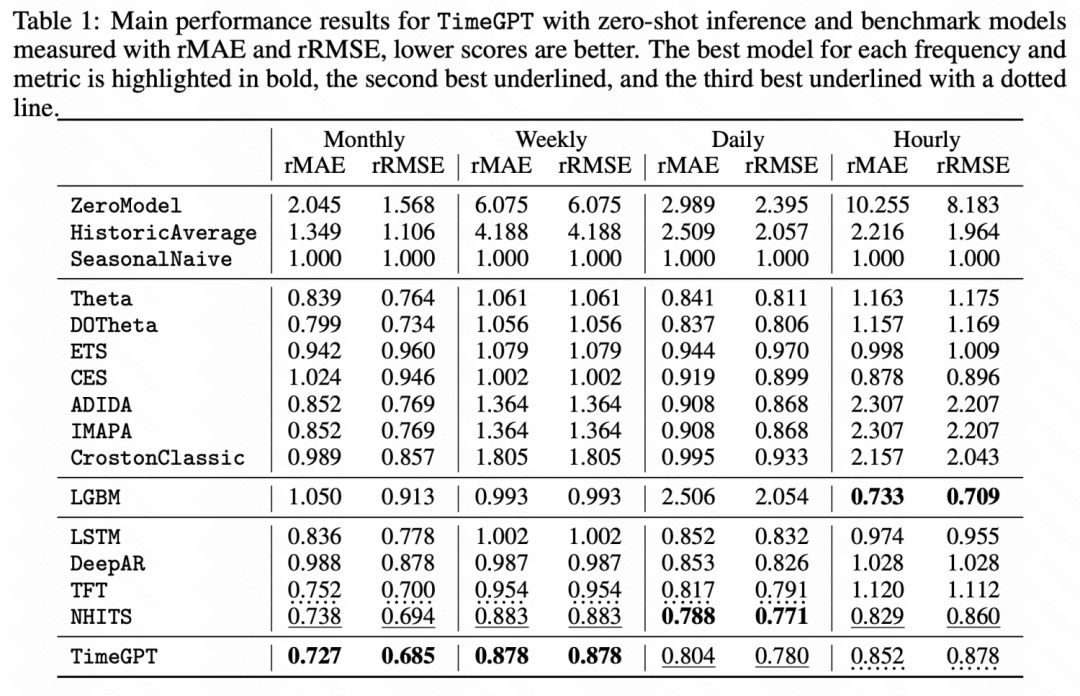 그림
그림
4. 요약
이 기사에서는 대형 모델의 물결 속에서 시계열 예측의 연구 아이디어를 소개합니다. 전체 프로세스에는 시계열 예측을 위해 NLP 대형 모델을 직접 사용하고 해당 시간에 대형 모델을 훈련하는 것이 포함됩니다. 시리즈 필드. 어떤 방법을 사용하든 대형모델+시계열의 가능성을 보여주며, 심도있게 연구해볼 만한 방향이다.
위 내용은 대규모 모델의 물결에 따른 시계열 예측에 관한 기사의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!