
기계 학습 | PyTorch 간결한 튜토리얼 2부

- WBOY앞으로
- 2023-11-02 17:29:15887검색
이전 글"PyTorch Concise Tutorial Part 1"에 이어 다층 퍼셉트론, 컨볼루셔널 신경망, LSTMNet을 계속해서 배워보세요.
1. 다층 퍼셉트론
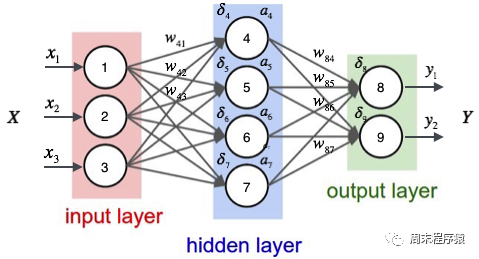
다층 퍼셉트론은 간단한 신경망이자 딥러닝의 중요한 기반입니다. 네트워크에 하나 이상의 숨겨진 레이어를 추가하여 선형 모델의 한계를 극복합니다. 구체적인 다이어그램은 다음과 같습니다.
import numpy as npimport torchfrom torch.autograd import Variablefrom torch import optimfrom data_util import load_mnistdef build_model(input_dim, output_dim):return torch.nn.Sequential(torch.nn.Linear(input_dim, 512, bias=False),torch.nn.ReLU(),torch.nn.Dropout(0.2),torch.nn.Linear(512, 512, bias=False),torch.nn.ReLU(),torch.nn.Dropout(0.2),torch.nn.Linear(512, output_dim, bias=False),)def train(model, loss, optimizer, x_val, y_val):model.train()optimizer.zero_grad()fx = model.forward(x_val)output = loss.forward(fx, y_val)output.backward()optimizer.step()return output.item()def predict(model, x_val):model.eval()output = model.forward(x_val)return output.data.numpy().argmax(axis=1)def main():torch.manual_seed(42)trX, teX, trY, teY = load_mnist(notallow=False)trX = torch.from_numpy(trX).float()teX = torch.from_numpy(teX).float()trY = torch.tensor(trY)n_examples, n_features = trX.size()n_classes = 10model = build_model(n_features, n_classes)loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')optimizer = optim.Adam(model.parameters())batch_size = 100for i in range(100):cost = 0.num_batches = n_examples // batch_sizefor k in range(num_batches):start, end = k * batch_size, (k + 1) * batch_sizecost += train(model, loss, optimizer,trX[start:end], trY[start:end])predY = predict(model, teX)print("Epoch %d, cost = %f, acc = %.2f%%"% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))if __name__ == "__main__":main()
(1) 위 코드는 단일 레이어 신경망의 코드와 유사합니다. 차이점은 build_model이 3개의 선형 레이어와 2개의 ReLU 활성화를 포함하는 신경망 모델을 구축한다는 것입니다. 함수:
- 모델에 첫 번째 선형 레이어를 추가합니다. 이 레이어의 입력 기능 수는 input_dim이고 출력 기능 수는 512입니다. 그런 다음 ReLU 활성화 함수와 드롭아웃 레이어를 추가하여 비선형 기능을 향상합니다.
- 두 번째 선형 레이어를 모델에 추가합니다. 이 레이어의 입력 기능 수는 512개이고, 출력 기능 수는 512개입니다. 그런 다음 ReLU 활성화 함수와 드롭아웃 레이어;
- 모델에 세 번째 선형 레이어 추가 선형 레이어, 이 레이어의 입력 기능 수는 512개, 출력 기능 수는 모델의 출력 범주 수인 output_dim입니다. (2) ReLU 활성화 함수란? ReLU(Rectified Linear Unit) 활성화 함수는 딥러닝 및 신경망에서 일반적으로 사용되는 활성화 함수입니다. ReLU 함수의 수학적 표현은 f(x) = max(0, x)입니다. 여기서 x는 입력 값입니다. ReLU 함수의 특징은 입력 값이 0보다 작거나 같으면 출력이 0이고, 입력 값이 0보다 크면 출력이 입력 값과 같다는 것입니다. 간단히 말해서 ReLU 함수는 음수 부분을 0으로 억제하고 양수 부분은 변경하지 않고 그대로 둡니다. 신경망에서 ReLU 활성화 함수의 역할은 신경망이 복잡한 비선형 관계를 맞출 수 있도록 비선형 요소를 도입하는 것입니다. 동시에 ReLU 함수는 다른 활성화 함수(예: Sigmoid 또는 Tanh) 및 기타 장점
- (3) 드롭아웃 레이어란 무엇입니까? 드롭아웃 레이어는 신경망에서 과적합을 방지하기 위해 사용되는 기술입니다. 훈련 과정에서 드롭아웃 레이어는 일부 뉴런의 출력을 무작위로 0으로 설정합니다. 즉, 이러한 뉴런을 "폐기"하는 목적은 뉴런 간의 상호 의존성을 줄여 네트워크의 일반화 능력을 향상시키는 것입니다.
- (4)print("Epoch %d, 비용 = %f, acc = %.2f%%" % (i + 1, 비용 / num_batches, 100. * np.mean(predY == teY))) 마지막으로 , 현재 훈련 라운드, 손실 값 및 acc가 인쇄됩니다. 위 코드 출력은 다음과 같습니다.
...Epoch 91, cost = 0.011129, acc = 98.45%Epoch 92, cost = 0.007644, acc = 98.58%Epoch 93, cost = 0.011872, acc = 98.61%Epoch 94, cost = 0.010658, acc = 98.58%Epoch 95, cost = 0.007274, acc = 98.54%Epoch 96, cost = 0.008183, acc = 98.43%Epoch 97, cost = 0.009999, acc = 98.33%Epoch 98, cost = 0.011613, acc = 98.36%Epoch 99, cost = 0.007391, acc = 98.51%Epoch 100, cost = 0.011122, acc = 98.59%
최종 동일한 데이터 분류가 단일 계층 신경망보다 더 높은 정확도(98.59% > 97.68)를 갖는 것을 볼 수 있습니다. %).
2. Convolutional Neural Network
CNN(Convolutional Neural Network)은 딥러닝 알고리즘입니다. 행렬이 입력되면 CNN은 중요한 부분과 중요하지 않은 부분을 구분(가중치 할당)할 수 있습니다. 다른 분류 작업에 비해 CNN은 완전히 훈련된 한 높은 데이터 전처리가 필요하지 않으며 행렬의 특성을 학습할 수 있습니다. 다음 그림은 프로세스를 보여줍니다.
import numpy as npimport torchfrom torch.autograd import Variablefrom torch import optimfrom data_util import load_mnistclass ConvNet(torch.nn.Module):def __init__(self, output_dim):super(ConvNet, self).__init__()self.conv = torch.nn.Sequential()self.conv.add_module("conv_1", torch.nn.Conv2d(1, 10, kernel_size=5))self.conv.add_module("maxpool_1", torch.nn.MaxPool2d(kernel_size=2))self.conv.add_module("relu_1", torch.nn.ReLU())self.conv.add_module("conv_2", torch.nn.Conv2d(10, 20, kernel_size=5))self.conv.add_module("dropout_2", torch.nn.Dropout())self.conv.add_module("maxpool_2", torch.nn.MaxPool2d(kernel_size=2))self.conv.add_module("relu_2", torch.nn.ReLU())self.fc = torch.nn.Sequential()self.fc.add_module("fc1", torch.nn.Linear(320, 50))self.fc.add_module("relu_3", torch.nn.ReLU())self.fc.add_module("dropout_3", torch.nn.Dropout())self.fc.add_module("fc2", torch.nn.Linear(50, output_dim))def forward(self, x):x = self.conv.forward(x)x = x.view(-1, 320)return self.fc.forward(x)def train(model, loss, optimizer, x_val, y_val):model.train()optimizer.zero_grad()fx = model.forward(x_val)output = loss.forward(fx, y_val)output.backward()optimizer.step()return output.item()def predict(model, x_val):model.eval()output = model.forward(x_val)return output.data.numpy().argmax(axis=1)def main():torch.manual_seed(42)trX, teX, trY, teY = load_mnist(notallow=False)trX = trX.reshape(-1, 1, 28, 28)teX = teX.reshape(-1, 1, 28, 28)trX = torch.from_numpy(trX).float()teX = torch.from_numpy(teX).float()trY = torch.tensor(trY)n_examples = len(trX)n_classes = 10model = ConvNet(output_dim=n_classes)loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)batch_size = 100for i in range(100):cost = 0.num_batches = n_examples // batch_sizefor k in range(num_batches):start, end = k * batch_size, (k + 1) * batch_sizecost += train(model, loss, optimizer,trX[start:end], trY[start:end])predY = predict(model, teX)print("Epoch %d, cost = %f, acc = %.2f%%"% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))if __name__ == "__main__":main()
(1) 위 코드는 torch.nn.Module 클래스에서 상속되고 __init__ 메서드에서 컨벌루션 신경망을 나타내는 ConvNet이라는 클래스를 정의합니다. 두 개의 하위 모듈은 fc는 각각 컨벌루션 레이어와 완전 연결 레이어를 나타내는 것으로 정의됩니다. conv 하위 모듈에서는 두 개의 컨벌루션 계층(torch.nn.Conv2d), 두 개의 최대 풀링 계층(torch.nn.MaxPool2d), 두 개의 ReLU 활성화 함수(torch.nn.ReLU) 및 드롭아웃 계층(torch.nn)을 정의합니다. 탈락). fc 하위 모듈에는 두 개의 선형 레이어(torch.nn.Linear), ReLU 활성화 함수 및 드롭아웃 레이어가 정의됩니다.
풀링 레이어는 CNN에서 중요한 역할을 하며 주요 목적은 다음과 같습니다. : 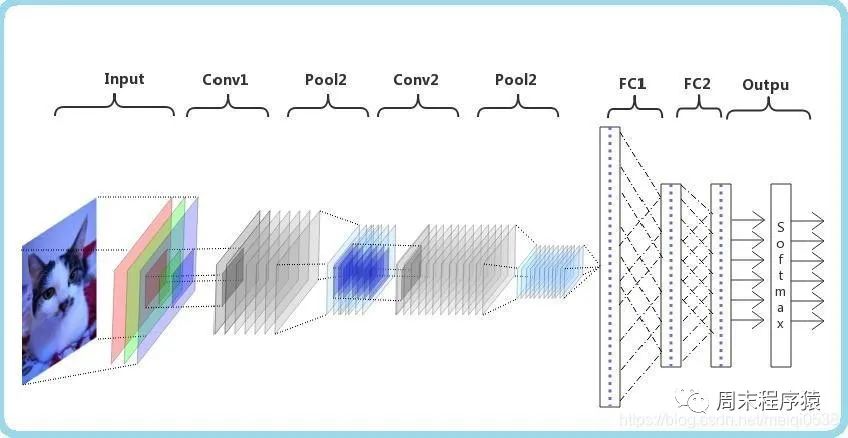
- 降低维度:池化层通过对输入特征图(Feature maps)进行局部区域的下采样操作,降低了特征图的尺寸。这样可以减少后续层中的参数数量,降低计算复杂度,加速训练过程;
- 平移不变性:池化层可以提高网络对输入图像的平移不变性。当图像中的某个特征发生小幅度平移时,池化层的输出仍然具有相似的特征表示。这有助于提高模型的泛化能力,使其能够在不同位置和尺度下识别相同的特征;
- 防止过拟合:通过减少特征图的尺寸,池化层可以降低模型的参数数量,从而降低过拟合的风险;
- 增强特征表达:池化操作可以聚合局部区域内的特征,从而强化和突出更重要的特征信息。常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling),分别表示在局部区域内取最大值或平均值作为输出;
(3)print("Epoch %d, cost = %f, acc = %.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))最后打印当前训练的轮次,损失值和acc,上述的代码输出如下:
...Epoch 91, cost = 0.047302, acc = 99.22%Epoch 92, cost = 0.049026, acc = 99.22%Epoch 93, cost = 0.048953, acc = 99.13%Epoch 94, cost = 0.045235, acc = 99.12%Epoch 95, cost = 0.045136, acc = 99.14%Epoch 96, cost = 0.048240, acc = 99.02%Epoch 97, cost = 0.049063, acc = 99.21%Epoch 98, cost = 0.045373, acc = 99.23%Epoch 99, cost = 0.046127, acc = 99.12%Epoch 100, cost = 0.046864, acc = 99.10%
可以看出最后相同的数据分类,准确率比多层感知机要高(99.10% > 98.59%)。
3、LSTMNet
LSTMNet是使用长短时记忆网络(Long Short-Term Memory, LSTM)构建的神经网络,核心思想是引入了一个名为"记忆单元"的结构,该结构可以在一定程度上保留长期依赖信息,LSTM中的每个单元包括一个输入门(input gate)、一个遗忘门(forget gate)和一个输出门(output gate),这些门的作用是控制信息在记忆单元中的流动,以便网络可以学习何时存储、更新或输出有用的信息。
import numpy as npimport torchfrom torch import optim, nnfrom data_util import load_mnistclass LSTMNet(torch.nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(LSTMNet, self).__init__()self.hidden_dim = hidden_dimself.lstm = nn.LSTM(input_dim, hidden_dim)self.linear = nn.Linear(hidden_dim, output_dim, bias=False)def forward(self, x):batch_size = x.size()[1]h0 = torch.zeros([1, batch_size, self.hidden_dim])c0 = torch.zeros([1, batch_size, self.hidden_dim])fx, _ = self.lstm.forward(x, (h0, c0))return self.linear.forward(fx[-1])def train(model, loss, optimizer, x_val, y_val):model.train()optimizer.zero_grad()fx = model.forward(x_val)output = loss.forward(fx, y_val)output.backward()optimizer.step()return output.item()def predict(model, x_val):model.eval()output = model.forward(x_val)return output.data.numpy().argmax(axis=1)def main():torch.manual_seed(42)trX, teX, trY, teY = load_mnist(notallow=False)train_size = len(trY)n_classes = 10seq_length = 28input_dim = 28hidden_dim = 128batch_size = 100epochs = 100trX = trX.reshape(-1, seq_length, input_dim)teX = teX.reshape(-1, seq_length, input_dim)trX = np.swapaxes(trX, 0, 1)teX = np.swapaxes(teX, 0, 1)trX = torch.from_numpy(trX).float()teX = torch.from_numpy(teX).float()trY = torch.tensor(trY)model = LSTMNet(input_dim, hidden_dim, n_classes)loss = torch.nn.CrossEntropyLoss(reductinotallow='mean')optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)for i in range(epochs):cost = 0.num_batches = train_size // batch_sizefor k in range(num_batches):start, end = k * batch_size, (k + 1) * batch_sizecost += train(model, loss, optimizer,trX[:, start:end, :], trY[start:end])predY = predict(model, teX)print("Epoch %d, cost = %f, acc = %.2f%%" %(i + 1, cost / num_batches, 100. * np.mean(predY == teY)))if __name__ == "__main__":main()
(1)以上这段代码通用的部分就不解释了,具体说LSTMNet类:
- self.lstm = nn.LSTM(input_dim, hidden_dim)创建一个LSTM层,输入维度为input_dim,隐藏层维度为hidden_dim;
- self.linear = nn.Linear(hidden_dim, output_dim, bias=False)创建一个线性层(全连接层),输入维度为hidden_dim,输出维度为output_dim,并设置不使用偏置项(bias);
- h0 = torch.zeros([1, batch_size, self.hidden_dim])初始化LSTM层的隐藏状态h0,全零张量,形状为[1, batch_size, hidden_dim];
- c0 = torch.zeros([1, batch_size, self.hidden_dim])初始化LSTM层的细胞状态c0,全零张量,形状为[1, batch_size, hidden_dim];
- fx, _ = self.lstm.forward(x, (h0, c0))将输入数据x以及初始隐藏状态h0和细胞状态c0传入LSTM层,得到LSTM层的输出fx;
- return self.linear.forward(fx[-1])将LSTM层的输出传入线性层进行计算,得到最终输出。这里fx[-1]表示取LSTM层输出的最后一个时间步的数据;
(2)print("第%d轮,损失值=%f,准确率=%.2f%%" % (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))。打印出当前训练轮次的信息,其中包括损失值和准确率,以上代码的输出结果如下:
Epoch 91, cost = 0.000468, acc = 98.57%Epoch 92, cost = 0.000452, acc = 98.57%Epoch 93, cost = 0.000437, acc = 98.58%Epoch 94, cost = 0.000422, acc = 98.57%Epoch 95, cost = 0.000409, acc = 98.58%Epoch 96, cost = 0.000396, acc = 98.58%Epoch 97, cost = 0.000384, acc = 98.57%Epoch 98, cost = 0.000372, acc = 98.56%Epoch 99, cost = 0.000360, acc = 98.55%Epoch 100, cost = 0.000349, acc = 98.55%
4、辅助代码
两篇文章的from data_util import load_mnist的data_util.py代码如下:
import gzip
import os
import urllib.request as request
from os import path
import numpy as np
DATASET_DIR = 'datasets/'
MNIST_FILES = ["train-images-idx3-ubyte.gz", "train-labels-idx1-ubyte.gz", "t10k-images-idx3-ubyte.gz", "t10k-labels-idx1-ubyte.gz"]
def download_file(url, local_path):
dir_path = path.dirname(local_path)
if not path.exists(dir_path):
print("创建目录'%s' ..." % dir_path)
os.makedirs(dir_path)
print("从'%s'下载中 ..." % url)
request.urlretrieve(url, local_path)
def download_mnist(local_path):
url_root = "http://yann.lecun.com/exdb/mnist/"
for f_name in MNIST_FILES:
f_path = os.path.join(local_path, f_name)
if not path.exists(f_path):
download_file(url_root + f_name, f_path)
def one_hot(x, n):
if type(x) == list:
x = np.array(x)
x = x.flatten()
o_h = np.zeros((len(x), n))
o_h[np.arange(len(x)), x] = 1
return o_h
def load_mnist(ntrain=60000, ntest=10000, notallow=True):
data_dir = os.path.join(DATASET_DIR, 'mnist/')
if not path.exists(data_dir):
download_mnist(data_dir)
else:
# 检查所有文件
checks = [path.exists(os.path.join(data_dir, f)) for f in MNIST_FILES]
if not np.all(checks):
download_mnist(data_dir)
with gzip.open(os.path.join(data_dir, 'train-images-idx3-ubyte.gz')) as fd:
buf = fd.read()
loaded = np.frombuffer(buf, dtype=np.uint8)
trX = loaded[16:].reshape((60000, 28 * 28)).astype(float)
with gzip.open(os.path.join(data_dir, 'train-labels-idx1-ubyte.gz')) as fd:
buf = fd.read()
loaded = np.frombuffer(buf, dtype=np.uint8)
trY = loaded[8:].reshape((60000))
with gzip.open(os.path.join(data_dir, 't10k-images-idx3-ubyte.gz')) as fd:
buf = fd.read()
loaded = np.frombuffer(buf, dtype=np.uint8)
teX = loaded[16:].reshape((10000, 28 * 28)).astype(float)
with gzip.open(os.path.join(data_dir, 't10k-labels-idx1-ubyte.gz')) as fd:
buf = fd.read()
loaded = np.frombuffer(buf, dtype=np.uint8)
teY = loaded[8:].reshape((10000))
trX /= 255.
teX /= 255.
trX = trX[:ntrain]
trY = trY[:ntrain]
teX = teX[:ntest]
teY = teY[:ntest]
if onehot:
trY = one_hot(trY, 10)
teY = one_hot(teY, 10)
else:
trY = np.asarray(trY)
teY = np.asarray(teY)
return trX, teX, trY, teY
위 내용은 기계 학습 | PyTorch 간결한 튜토리얼 2부의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!