



빅데이터 시대가 도래하면서 데이터 처리와 분석이 더욱 중요해지고 있습니다. 데이터 처리 및 분석 분야에서 널리 사용되는 NoSQL 데이터베이스인 MongoDB는 실시간 데이터 처리 및 분석에 널리 사용됩니다. 이 글은 실제 경험에서 시작하여 MongoDB를 기반으로 한 실시간 데이터 처리 및 분석에 대한 몇 가지 경험을 요약합니다.
1. 데이터 모델 설계
실시간 데이터 처리 및 분석을 위해 MongoDB를 사용할 때는 합리적인 데이터 모델 설계가 중요합니다. 먼저, 비즈니스 요구 사항을 분석하고 처리 및 분석해야 하는 데이터 유형과 구조를 이해해야 합니다. 그런 다음 데이터의 특성과 쿼리 요구 사항을 기반으로 적절한 데이터 모델을 설계합니다. 데이터 모델을 설계할 때는 데이터의 관계와 계층을 고려하고 적절한 데이터 중첩 및 데이터 인덱싱 방법을 선택해야 합니다.
2. 데이터 가져오기 및 동기화
실시간 데이터 처리 및 분석에는 실시간 데이터 수집 및 가져오기가 필요합니다. 데이터 가져오기 및 동기화를 위해 MongoDB를 사용할 때 다음 방법을 고려할 수 있습니다.
- MongoDB 자체 가져오기 도구 사용: MongoDB는 데이터를 쉽게 가져오고 백업할 수 있도록 mongodump 및 mongorestore 명령을 제공합니다.
- ETL 도구 사용: ETL(Extract-Transform-Load) 도구를 사용하면 다른 데이터 소스에서 데이터를 추출하고 데이터를 MongoDB 형식으로 변환한 다음 MongoDB로 가져올 수 있습니다.
- 실시간 데이터 동기화 도구 사용: 실시간 데이터 동기화 도구는 데이터를 MongoDB에 실시간으로 동기화하여 데이터의 정확성과 적시성을 보장할 수 있습니다.
3. 인덱스 설정
실시간 데이터 처리 및 분석을 위해 MongoDB를 사용할 때는 적절한 인덱스를 설정하는 것이 매우 중요합니다. 인덱스는 쿼리 효율성을 향상시키고 데이터 읽기 및 분석 속도를 높일 수 있습니다. 인덱스를 구축할 때 쿼리 요구 사항과 데이터 모델을 기반으로 적절한 인덱스 유형과 인덱스 필드를 선택하여 과도한 인덱싱과 불필요한 인덱싱을 방지하여 시스템 성능을 향상시키는 것이 필요합니다.
4. 복제 및 샤딩 활용
데이터 양이 증가하면 단일 머신 MongoDB는 실시간 데이터 처리 및 분석 요구 사항을 충족하지 못할 수 있습니다. 이때 MongoDB의 복제 및 샤딩 메커니즘을 사용하여 데이터베이스의 성능과 용량을 확장하는 것을 고려할 수 있습니다.
- 복제: MongoDB의 복제 메커니즘은 중복 백업과 데이터의 고가용성을 달성할 수 있습니다. 여러 개의 복제본 세트를 구성하면 데이터를 여러 노드에 자동으로 복사할 수 있고, 데이터 읽기와 쓰기를 분리하여 시스템 가용성과 성능을 향상시킬 수 있습니다.
- 샤딩: MongoDB의 샤딩 메커니즘은 데이터의 수평 확장을 달성할 수 있습니다. 여러 샤드에 데이터를 분산함으로써 시스템의 동시 처리 기능과 스토리지 용량을 향상시킬 수 있습니다. 샤딩 시 데이터 왜곡 및 오버 샤딩을 방지하기 위해 샤딩 키와 데이터 간격을 합리적으로 나누는 것이 필요합니다.
5. 쿼리 및 집계 최적화
실시간 데이터 처리 및 분석을 위해 MongoDB를 사용할 경우 시스템의 응답 속도와 성능을 향상시키기 위해 쿼리 및 집계 작업을 최적화해야 합니다.
- 적절한 쿼리 방법 사용: 데이터 모델 및 쿼리 요구 사항에 따라 적절한 쿼리 방법을 선택합니다. 기본 CRUD 작업이나 중첩된 계층적 데이터 쿼리 또는 지리적 위치 쿼리 사용과 같은 더 복잡한 쿼리 작업을 사용할 수 있습니다.
- 집계 프레임워크 사용: MongoDB는 복잡한 데이터 집계 및 분석 작업을 수행할 수 있는 강력한 집계 프레임워크를 제공합니다. 집계 프레임워크를 올바르게 사용하면 데이터 전송 및 계산 양을 줄이고 쿼리 효율성과 성능을 향상시킬 수 있습니다.
6. 모니터링 및 최적화
실시간 데이터 처리 및 분석 시스템은 시스템 안정성과 성능을 유지하기 위해 정기적인 모니터링과 최적화가 필요합니다.
- 시스템 성능 모니터링: 시스템의 CPU, 메모리, 네트워크 및 기타 지표를 모니터링하여 시스템의 로드 및 성능 병목 현상을 이해하고 적시에 시스템 구성 및 매개변수를 조정하여 시스템의 안정성과 성능을 향상할 수 있습니다. .
- 쿼리 계획 최적화: 쿼리 및 집계 작업의 실행 계획을 정기적으로 분석하고, 성능 병목 현상 및 최적화 공간을 찾아내고, 인덱스 조정, 쿼리 문 다시 작성 등을 수행하여 쿼리 효율성 및 응답 속도를 향상시킵니다.
- 데이터 압축 및 보관: 기록 데이터 및 콜드 데이터의 경우 데이터 압축 및 보관을 수행하여 저장 공간을 절약하고 시스템 성능을 향상시킬 수 있습니다.
요약:
MongoDB 기반의 실시간 데이터 처리 및 분석에는 합리적인 데이터 모델 설계, 데이터 가져오기 및 동기화, 인덱스 설정, 복제 및 샤딩, 쿼리 및 집계 최적화, 정기적인 모니터링 및 최적화가 필요합니다. 이러한 경험을 종합하면 MongoDB를 실시간 데이터 처리 및 분석에 더 잘 적용할 수 있으며, 데이터 처리 및 분석의 효율성과 정확성을 높일 수 있습니다.
위 내용은 MongoDB 기반의 실시간 데이터 처리 및 분석 경험 요약의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

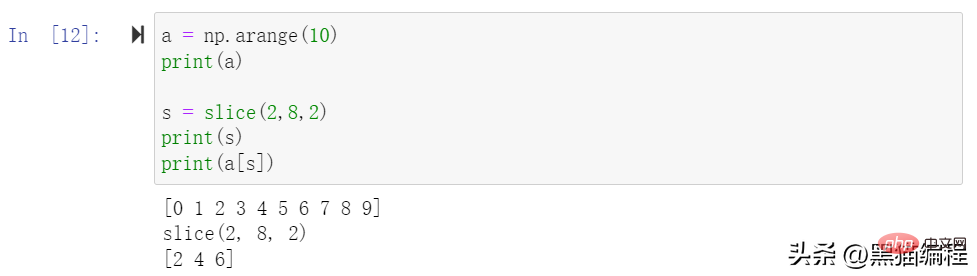 一文详解Python数据分析模块Numpy切片、索引和广播Apr 10, 2023 pm 02:56 PM
一文详解Python数据分析模块Numpy切片、索引和广播Apr 10, 2023 pm 02:56 PMNumpy切片和索引ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。ndarray 数组可以基于 0 ~ n-1 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。高级索引整数数组索引以下实例获取数组中 (0,0),(1,1
 Python中的机器学习是什么?Jun 04, 2023 am 08:52 AM
Python中的机器学习是什么?Jun 04, 2023 am 08:52 AM近年来,机器学习(MachineLearning)成为了IT行业中最热门的话题之一,Python作为一种高效的编程语言,已经成为了许多机器学习实践者的首选。本文将会介绍Python中机器学习的概念、应用和实现。一、机器学习概念机器学习是一种让机器通过对数据的分析、学习和优化,自动改进性能的技术。其主要目的是让机器能够在数据中发现存在的规律,从而获得对未来
 如何利用 Go 语言进行数据分析和机器学习?Jun 10, 2023 am 09:21 AM
如何利用 Go 语言进行数据分析和机器学习?Jun 10, 2023 am 09:21 AM随着互联网技术的发展和大数据的普及,越来越多的公司和机构开始关注数据分析和机器学习。现在,有许多编程语言可以用于数据科学,其中Go语言也逐渐成为了一种不错的选择。虽然Go语言在数据科学上的应用不如Python和R那么广泛,但是它具有高效、并发和易于部署等特点,因此在某些场景中表现得非常出色。本文将介绍如何利用Go语言进行数据分析和机器学习
 数据挖掘和数据分析的区别是什么?Dec 07, 2020 pm 03:16 PM
数据挖掘和数据分析的区别是什么?Dec 07, 2020 pm 03:16 PM区别:1、“数据分析”得出的结论是人的智力活动结果,而“数据挖掘”得出的结论是机器从学习集【或训练集、样本集】发现的知识规则;2、“数据分析”不能建立数学模型,需要人工建模,而“数据挖掘”直接完成了数学建模。
 Python量化交易实战:获取股票数据并做分析处理Apr 15, 2023 pm 09:13 PM
Python量化交易实战:获取股票数据并做分析处理Apr 15, 2023 pm 09:13 PM量化交易(也称自动化交易)是一种应用数学模型帮助投资者进行判断,并且根据计算机程序发送的指令进行交易的投资方式,它极大地减少了投资者情绪波动的影响。量化交易的主要优势如下:快速检测客观、理性自动化量化交易的核心是筛选策略,策略也是依靠数学或物理模型来创造,把数学语言变成计算机语言。量化交易的流程是从数据的获取到数据的分析、处理。数据获取数据分析工作的第一步就是获取数据,也就是数据采集。获取数据的方式有很多,一般来讲,数据来源主要分为两大类:外部来源(外部购买、网络爬取、免费开源数据等)和内部来源
 MySQL中的大数据分析技巧Jun 14, 2023 pm 09:53 PM
MySQL中的大数据分析技巧Jun 14, 2023 pm 09:53 PM随着大数据时代的到来,越来越多的企业和组织开始利用大数据分析来帮助自己更好地了解其所面对的市场和客户,以便更好地制定商业策略和决策。而在大数据分析中,MySQL数据库也是经常被使用的一种工具。本文将介绍MySQL中的大数据分析技巧,为大家提供参考。一、使用索引进行查询优化索引是MySQL中进行查询优化的重要手段之一。当我们对某个列创建了索引后,MySQL就可
 为何军事人工智能初创公司近年来备受追捧Apr 13, 2023 pm 01:34 PM
为何军事人工智能初创公司近年来备受追捧Apr 13, 2023 pm 01:34 PM俄乌冲突爆发 2 周后,数据分析公司 Palantir 的首席执行官亚历山大·卡普 (Alexander Karp) 向欧洲领导人提出了一项建议。在公开信中,他表示欧洲人应该在硅谷的帮助下实现武器现代化。Karp 写道,为了让欧洲“保持足够强大以战胜外国占领的威胁”,各国需要拥抱“技术与国家之间的关系,以及寻求摆脱根深蒂固的承包商控制的破坏性公司与联邦政府部门之间的资金关系”。而军队已经开始响应这项号召。北约于 6 月 30 日宣布,它正在创建一个 10 亿美元的创新基金,将投资于早期创业公司和
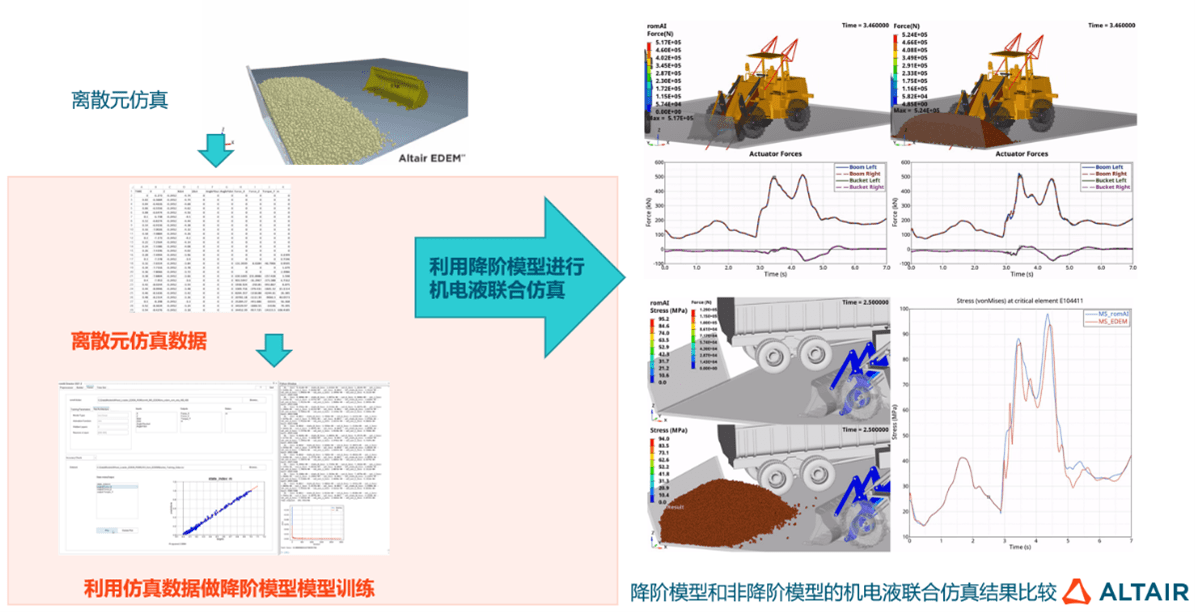 AI牵引工业软件新升级,数据分析与人工智能在探索中进化Jun 05, 2023 pm 04:04 PM
AI牵引工业软件新升级,数据分析与人工智能在探索中进化Jun 05, 2023 pm 04:04 PMCAE和AI技术双融合已成为企业研发设计环节数字化转型的重要应用趋势,但企业数字化转型绝不仅是单个环节的优化,而是全流程、全生命周期的转型升级,数据驱动只有作用于各业务环节,才能真正助力企业持续发展。数字化浪潮席卷全球,作为数字经济核心驱动,数字技术逐步成为企业发展新动能,助推企业核心竞争力进化,在此背景下,数字化转型已成为所有企业的必选项和持续发展的前提,拥抱数字经济成为企业的共同选择。但从实际情况来看,面向C端的产业如零售电商、金融等领域在数字化方面走在前列,而以制造业、能源重工等为代表的传


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

안전한 시험 브라우저
안전한 시험 브라우저는 온라인 시험을 안전하게 치르기 위한 보안 브라우저 환경입니다. 이 소프트웨어는 모든 컴퓨터를 안전한 워크스테이션으로 바꿔줍니다. 이는 모든 유틸리티에 대한 액세스를 제어하고 학생들이 승인되지 않은 리소스를 사용하는 것을 방지합니다.

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

WebStorm Mac 버전
유용한 JavaScript 개발 도구

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기
뜨거운 주제
 1371
1371 523919
523919