



강화 학습(RL)은 에이전트가 시행착오를 통해 환경에서 행동하는 방법을 학습할 수 있는 기계 학습 방법입니다. 에이전트는 원하는 결과로 이어지는 조치를 취한 것에 대해 보상을 받거나 처벌을 받습니다. 시간이 지남에 따라 에이전트는 예상 보상을 최대화하는 조치를 취하는 방법을 배웁니다
RL 에이전트는 일반적으로 순차적 결정 문제 수학적 프레임워크를 모델링하는 MDP(Markov Decision Process)를 사용하여 교육됩니다. MDP는 네 부분으로 구성됩니다:
- 상태: 가능한 환경 상태의 집합입니다.
- Action: 에이전트가 취할 수 있는 일련의 작업입니다.
- 전환 함수: 현재 상태와 동작을 고려하여 새로운 상태로 전환할 확률을 예측하는 함수입니다.
- 보상 기능: 각 전환에 대해 에이전트에게 보상을 할당하는 기능입니다.
에이전트의 목표는 상태를 작업에 매핑하는 정책 기능을 배우는 것입니다. 정책 기능을 통해 시간이 지남에 따라 에이전트의 예상 수익을 극대화합니다.
Deep Q-learning은 심층 신경망을 사용하여 정책 기능을 학습하는 강화 학습 알고리즘입니다. 심층 신경망은 현재 상태를 입력으로 사용하고 값 벡터를 출력합니다. 여기서 각 값은 가능한 작업을 나타냅니다. 그런 다음 에이전트는 가장 높은 값을 기반으로 작업을 수행합니다.
Deep Q-learning은 값 기반 강화 학습 알고리즘으로, 각 상태-작업 쌍의 값을 학습한다는 의미입니다. 상태-작업 쌍의 값은 에이전트가 해당 상태에서 해당 작업을 수행할 때 예상되는 보상입니다.
Actor-Critic은 가치 기반과 정책 기반을 결합한 RL 알고리즘입니다. 두 가지 구성 요소가 있습니다.
Actor: 액터는 작업 선택을 담당합니다.
비평가: 배우의 행동을 평가하는 역할을 담당합니다.
배우와 평론가는 동시에 훈련을 받습니다. 행위자는 예상 보상을 최대화하도록 훈련되고 비평가는 각 상태-행동 쌍에 대한 예상 보상을 정확하게 예측하도록 훈련됩니다.
행위자-비평가 알고리즘은 다른 강화 학습 알고리즘에 비해 몇 가지 장점이 있습니다. 첫째, 더 안정적입니다. 즉, 훈련 중에 편향이 발생할 가능성이 적습니다. 둘째, 더 효율적이므로 더 빨리 배울 수 있습니다. 셋째, 확장성이 뛰어나고 상태 공간과 행동 공간이 큰 문제에 적용할 수 있습니다.
아래 표에는 Deep Q-learning과 Actor-Critic의 주요 차이점이 요약되어 있습니다.

Actor의 장점- 비평가(A2C)
Actor-Critic은 정책 기반 접근 방식과 가치 기반 접근 방식을 결합한 인기 있는 강화 학습 아키텍처입니다. 다양한 강화 학습 작업을 해결하는 데 강력한 선택이 되는 많은 장점이 있습니다.
1. 낮은 분산
기존 정책 경사 방법과 비교할 때 A2C는 일반적으로 분산 훈련 중 성능이 낮습니다. 이는 A2C가 정책 그래디언트와 가치 함수를 모두 사용하고, 그래디언트 계산의 분산을 줄이기 위해 가치 함수를 사용하기 때문입니다. 낮은 분산은 학습 과정이 더 안정적이고 더 나은 전략으로 더 빠르게 수렴할 수 있음을 의미합니다
2. 더 빠른 학습 속도
A2C는 낮은 분산의 특성으로 인해 일반적으로 더 빠른 속도로 정책을 학습할 수 있습니다. 전략. 학습 속도가 빨라지면 귀중한 시간과 컴퓨팅 리소스가 절약되므로 이는 광범위한 시뮬레이션이 필요한 작업에 특히 중요합니다.
3. 정책과 가치 기능의 결합
A2C의 가장 큰 특징은 정책과 가치 기능을 동시에 학습한다는 점입니다. 이 조합을 통해 에이전트는 환경과 작업 간의 상관 관계를 더 잘 이해할 수 있으므로 정책 개선을 더 잘 이끌 수 있습니다. 가치 함수의 존재는 정책 최적화의 오류를 줄이고 훈련 효율성을 향상시키는 데에도 도움이 됩니다.
4. 연속 및 이산 동작 공간 지원
A2C는 연속 및 이산 동작을 포함한 다양한 유형의 동작 공간에 적응할 수 있으며 매우 다재다능합니다. 이로 인해 A2C는 로봇 제어부터 게임 플레이 최적화까지 다양한 작업에 적용할 수 있는 널리 적용 가능한 강화 학습 알고리즘이 됩니다.
5. 병렬 훈련
A2C는 멀티 코어를 최대한 활용하기 위해 쉽게 병렬화할 수 있습니다. 처리 서버 및 분산 컴퓨팅 리소스. 이는 더 짧은 시간에 더 많은 경험적 데이터를 수집할 수 있어 훈련 효율성이 향상된다는 것을 의미합니다.
배우 비평가 방법에는 몇 가지 장점이 있지만 초매개변수 조정 및 훈련의 잠재적인 불안정성과 같은 몇 가지 과제도 직면합니다. 그러나 경험 재생 및 대상 네트워크와 같은 적절한 조정 및 기술을 사용하면 이러한 문제를 크게 완화할 수 있으므로 배우 평론가가 강화 학습에서 귀중한 방법이 됩니다
panda-gym
panda-gym은 PyBullet 엔진을 기반으로 개발되었으며 주로 팬더 로봇 팔 주위로 도달, 밀기, 슬라이드, 선택 및 배치, 쌓기, 뒤집기와 같은 6가지 작업을 캡슐화합니다. OpenAI Fetch로.
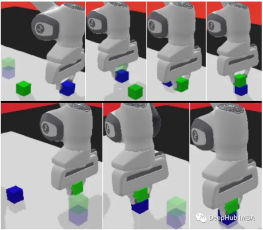
아래 코드를 보여주기 위해 panda-gym을 예로 사용하겠습니다.
1. 라이브러리를 설치합니다.
먼저 강화 학습 환경을 위한 코드를 초기화해야 합니다.
!apt-get install -y \libgl1-mesa-dev \libgl1-mesa-glx \libglew-dev \xvfb \libosmesa6-dev \software-properties-common \patchelf !pip install \free-mujoco-py \pytorch-lightning \optuna \pyvirtualdisplay \PyOpenGL \PyOpenGL-accelerate\stable-baselines3[extra] \gymnasium \huggingface_sb3 \huggingface_hub \ panda_gym
2. 라이브러리 가져오기
import os import gymnasium as gym import panda_gym from huggingface_sb3 import load_from_hub, package_to_hub from stable_baselines3 import A2C from stable_baselines3.common.evaluation import evaluate_policy from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize from stable_baselines3.common.env_util import make_vec_env
3. 실행 환경 만들기
env_id = "PandaReachDense-v3" # Create the env env = gym.make(env_id) # Get the state space and action space s_size = env.observation_space.shape a_size = env.action_space print("\n _____ACTION SPACE_____ \n") print("The Action Space is: ", a_size) print("Action Space Sample", env.action_space.sample()) # Take a random action
4. 관찰 및 보상의 정규화
강화 학습을 최적화하는 좋은 방법은 입력 특성을 정규화하는 것입니다. 래퍼를 통해 입력 특성의 실행 평균과 표준 편차를 계산합니다. 또한norm_reward = True
env = make_vec_env(env_id, n_envs=4) env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
5를 추가하여 보상을 정규화합니다. A2C 모델 생성
Stable-Baselines3 팀
model = A2C(policy = "MultiInputPolicy",env = env,verbose=1)
6에서 훈련한 공식 에이전트를 사용합니다. A2C
model.learn(1_000_000) # Save the model and VecNormalize statistics when saving the agent model.save("a2c-PandaReachDense-v3") env.save("vec_normalize.pkl")
7을 훈련합니다. Agent
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize # Load the saved statistics eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")]) eval_env = VecNormalize.load("vec_normalize.pkl", eval_env) # We need to override the render_mode eval_env.render_mode = "rgb_array" # do not update them at test time eval_env.training = False # reward normalization is not needed at test time eval_env.norm_reward = False # Load the agent model = A2C.load("a2c-PandaReachDense-v3") mean_reward, std_reward = evaluate_policy(model, eval_env) print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
요약
"panda-gym"에서는 Panda 로봇팔과 GYM 환경의 효과적인 결합을 통해 로컬에서 로봇팔에 대한 강화학습을 쉽게 수행할 수 있습니다.
Actor-Critic The Architecture 희소 보상 함수(결과가 바이너리인 경우)와 달리 에이전트가 각 시간 단계에서 점진적인 개선을 수행하는 방법을 학습하는 경우 Actor-Critic 방법이 이러한 유형의 작업에 특히 적합합니다.
정책 학습과 가치 추정을 완벽하게 결합함으로써 로봇 에이전트는 로봇 팔 엔드 이펙터를 능숙하게 조작하고 지정된 목표 위치에 정확하게 도달할 수 있습니다. 이는 로봇 제어와 같은 작업에 대한 실용적인 솔루션을 제공할 뿐만 아니라 민첩하고 정보에 입각한 의사 결정이 필요한 다양한 분야를 변화시킬 수 있는 잠재력을 가지고 있습니다
위 내용은 Panda-Gym의 로봇팔 시뮬레이션을 이용한 Deep Q-learning 강화학습의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 신속한 엔지니어링에서 생각의 그래프는 무엇입니까?Apr 13, 2025 am 11:53 AM
신속한 엔지니어링에서 생각의 그래프는 무엇입니까?Apr 13, 2025 am 11:53 AM소개 신속한 엔지니어링에서 "Thought of Thought"는 그래프 이론을 사용하여 AI의 추론 과정을 구성하고 안내하는 새로운 접근법을 나타냅니다. 종종 선형 S와 관련된 전통적인 방법과 달리
 Genai 에이전트와 함께 조직의 이메일 마케팅을 최적화하십시오Apr 13, 2025 am 11:44 AM
Genai 에이전트와 함께 조직의 이메일 마케팅을 최적화하십시오Apr 13, 2025 am 11:44 AM소개 축하해요! 당신은 성공적인 사업을 운영합니다. 웹 페이지, 소셜 미디어 캠페인, 웹 세미나, 컨퍼런스, 무료 리소스 및 기타 소스를 통해 매일 5000 개의 이메일 ID를 수집합니다. 다음 명백한 단계는입니다
 Apache Pinot을 사용한 실시간 앱 성능 모니터링Apr 13, 2025 am 11:40 AM
Apache Pinot을 사용한 실시간 앱 성능 모니터링Apr 13, 2025 am 11:40 AM소개 오늘날의 빠르게 진행되는 소프트웨어 개발 환경에서 최적의 애플리케이션 성능이 중요합니다. 응답 시간, 오류율 및 자원 활용과 같은 실시간 메트릭 모니터링 메인이 도움이 될 수 있습니다.
 Chatgpt가 10 억 명의 사용자를 쳤습니까? Openai CEO는'몇 주 만에 두 배가되었습니다Apr 13, 2025 am 11:23 AM
Chatgpt가 10 억 명의 사용자를 쳤습니까? Openai CEO는'몇 주 만에 두 배가되었습니다Apr 13, 2025 am 11:23 AM"얼마나 많은 사용자가 있습니까?" 그는 자극했다. Altman은“마지막으로 우리가 마지막으로 말한 것은 매주 5 억 명의 행위자이며 매우 빠르게 성장하고 있다고 생각합니다. 앤더슨은 계속해서“당신은 나에게 몇 주 만에 두 배가되었다고 말했습니다. “저는 그 개인이라고 말했습니다
 Pixtral -12B : Mistral AI의 첫 번째 멀티 모드 모델 -Anuctics VidhyaApr 13, 2025 am 11:20 AM
Pixtral -12B : Mistral AI의 첫 번째 멀티 모드 모델 -Anuctics VidhyaApr 13, 2025 am 11:20 AM소개 Mistral은 최초의 멀티 모드 모델, 즉 Pixtral-12B-2409를 발표했습니다. 이 모델은 Mistral의 120 억 개의 매개 변수 인 NEMO 12B를 기반으로합니다. 이 모델을 차별화하는 것은 무엇입니까? 이제 이미지와 Tex를 모두 가져갈 수 있습니다
 생성 AI 응용 프로그램을위한 에이전트 프레임 워크 - 분석 VidhyaApr 13, 2025 am 11:13 AM
생성 AI 응용 프로그램을위한 에이전트 프레임 워크 - 분석 VidhyaApr 13, 2025 am 11:13 AM쿼리에 응답 할뿐만 아니라 자율적으로 정보를 모으고, 작업을 실행하며, 여러 유형의 데이터 (텍스트, 이미지 및 코드를 처리하는 AI 구동 조수가 있다고 상상해보십시오. 미래처럼 들리나요? 이것에서
 금융 부문에서 생성 AI의 응용Apr 13, 2025 am 11:12 AM
금융 부문에서 생성 AI의 응용Apr 13, 2025 am 11:12 AM소개 금융 산업은 효율적인 거래 및 신용 가용성을 촉진함으로써 경제 성장을 주도하기 때문에 모든 국가 개발의 초석입니다. 거래가 발생하는 용이성 및 신용
 온라인 학습 및 수동 공격 알고리즘 안내Apr 13, 2025 am 11:09 AM
온라인 학습 및 수동 공격 알고리즘 안내Apr 13, 2025 am 11:09 AM소개 소셜 미디어, 금융 거래 및 전자 상거래 플랫폼과 같은 소스에서 전례없는 속도로 데이터가 생성되고 있습니다. 이 지속적인 정보 스트림을 처리하는 것은 어려운 일이지만


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

드림위버 CS6
시각적 웹 개발 도구

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

