
SMPLer-X: 7개의 주요 목록을 뒤집고 최초의 인간 모션 캡처 모델을 선보입니다!

- 王林앞으로
- 2023-10-30 16:01:08779검색
현재 표현적 인간 자세 및 형태 추정(EHPS, Expressive Human Pose and Shape estimation)에 대한 연구가 크게 진전되었지만 가장 발전된 방법은 여전히 훈련 데이터 세트의 한계로 인해 제한됩니다
최근 , 난양 기술 대학의 S-Lab, SenseTime, 도쿄 대학의 상하이 인공 지능 연구소 및 IDEA 연구소의 연구원들은 인체 자세 및 신체 크기 추정 작업을 위한 대규모 모션 캡처 모델 SMPLer-X를 처음으로 제안했습니다. 이 연구는 모델을 훈련하기 위해 다양한 데이터 소스에서 최대 450만 개의 인스턴스를 사용하여 7가지 핵심 목록에서 최고의 성능을 달성했습니다
SMPLer-X는 신체 움직임을 캡처할 수 있을 뿐만 아니라 얼굴과 손 움직임도 출력할 수 있으며 체형

페이퍼 링크: https://arxiv.org/abs/2309.17448
프로젝트 홈페이지: https://caizhongang.github.io/projects/ SMPLer-X/
풍부한 데이터와 거대한 모델을 통해 SMPLer-X는 다양한 테스트와 순위에서 강력한 성능을 입증했으며, 알려지지 않은 환경에서도 뛰어난 활용성을 보여줍니다
at 데이터 확장 측면에서 연구원들은 32개의 3D에 대한 종합적인 평가 및 분석을 수행했습니다. 모델 훈련을 위한 참조를 제공하는 인체 데이터 세트
2. 모델 스케일링 측면에서 시각적 대형 모델을 사용하여 모델 매개변수 수 증가가 성능 향상에 미치는 영향을 연구했습니다. SMPLer-X 일반 대형 모델은 미세 조정 전략을 통해 전용 대형 모델로 변환되어 더욱 향상된 성능을 얻을 수 있습니다.
요약하자면, SMPLer-X는 데이터 스케일링 및 모델 스케일링(그림 1 참조)에 대한 탐색을 수행했으며 450만 인스턴스 교육을 수행하는 동안 32개 학술 데이터 세트에서 순위를 매겨 7개 핵심 목록에서 최고의 성능을 달성했습니다. AGORA, UBody, EgoBody 및 EHF 포함
그림 1 데이터 및 모델 매개변수의 양을 늘리면 핵심 목록(AGORA, UBody, EgoBody, 3DPW 및 EHF)이 줄어들어 모두 평균 주 오류 측면에서 효과적입니다( MPE)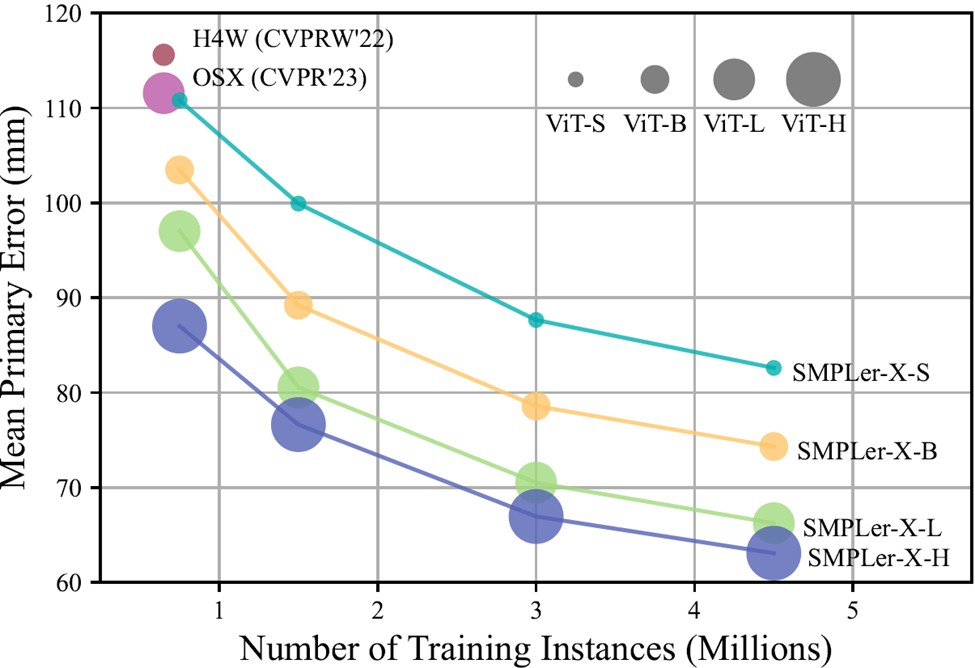
기존 3D 인체 데이터 세트에 대한 일반화 연구 수행
연구원들은 32개 학술 데이터 세트에 대한 일반화 연구를 수행했습니다. 데이터 세트의 순위는 다음과 같습니다. 각 데이터 세트의 성능을 측정하기 위해 해당 데이터 세트를 사용하여 모델을 훈련했습니다. 모델은 AGORA, UBody, EgoBody, 3DPW 및 EHF의 5가지 평가 데이터 세트에서 평가되었습니다.
다양한 데이터 세트 간의 간단한 비교를 용이하게 하기 위해 MPE(Mean Primary Error)도 표에 계산됩니다. 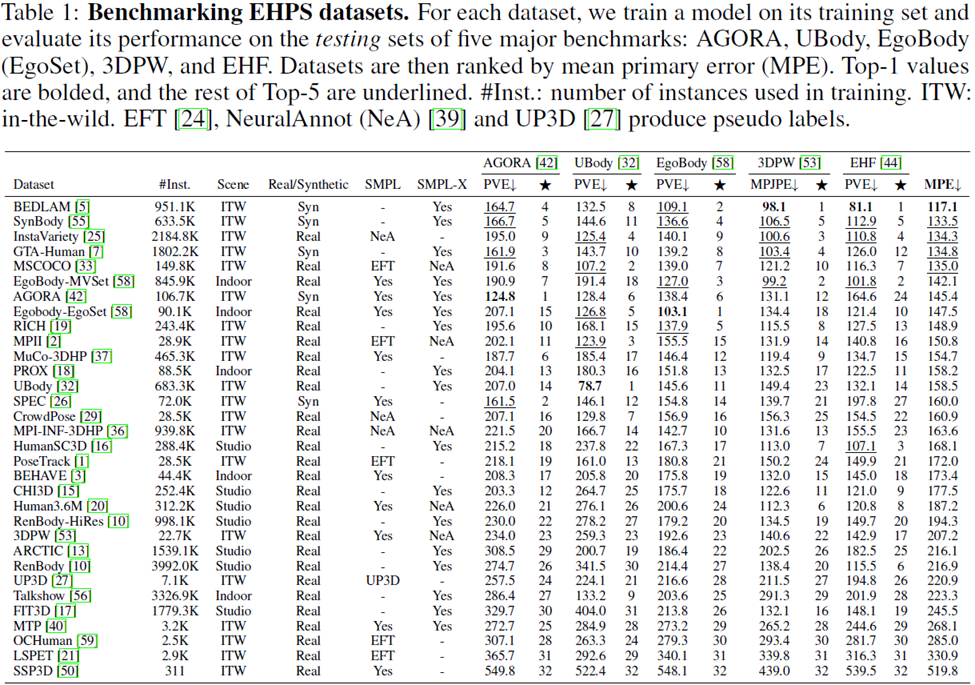
데이터 세트의 일반화 연구에서 얻은 영감
많은 수의 데이터 세트를 분석하여(그림 3 참조) 다음 네 가지 결론을 도출할 수 있습니다. 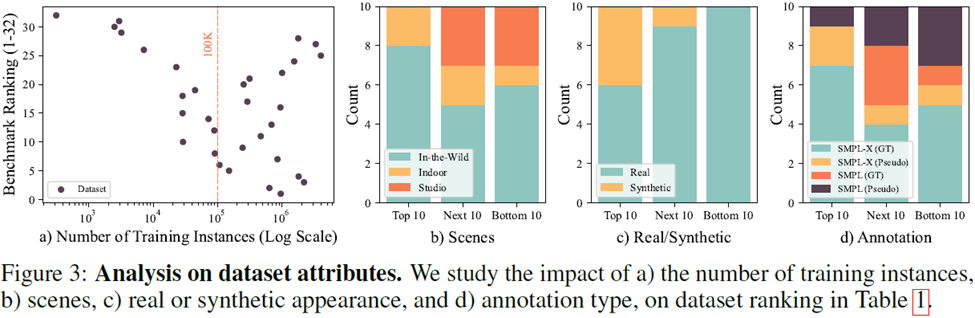
1. 단일 데이터 세트의 데이터 볼륨, 약 100,000개 인스턴스의 데이터 세트를 모델 교육에 사용하여 더 높은 비용 성능을 달성할 수 있습니다.
2. -야생 데이터 세트가 가장 좋습니다. 실내에서만 데이터를 수집할 수 있는 경우 훈련 효과를 높이려면 단일 장면의 데이터 사용을 피해야 합니다
데이터 세트 수집과 관련하여 상위 3개 데이터 세트 중 2개가 생성된 데이터 세트입니다. 최근 몇 년 동안 생성된 데이터 세트는 강력한 성능을 보여주었습니다
데이터 세트의 주석과 관련하여 의사 레이블도 훈련에서 매우 중요한 역할을 합니다
대형 모션 캡처 모델의 훈련 및 미세 조정
요즘에는 대부분의 최첨단 방법은 일반적으로 훈련에 몇 가지 데이터 세트(예: MSCOCO, MPII 및 Human3.6M)만 사용하는 반면, 이 논문에서는 더 많은 데이터 세트를 사용하여 연구합니다
순위가 높은 데이터 세트를 선호한다는 점을 고려하여 우리는 5, 10, 20, 32개의 데이터 세트를 훈련 세트로 사용했으며 총 크기는 750,000, 150만, 300만, 450만 인스턴스입니다.
또한 연구원들은 일반 대형 모델을 특정 시나리오에 적용할 수 있는 저비용 미세 조정 전략도 시연했습니다.
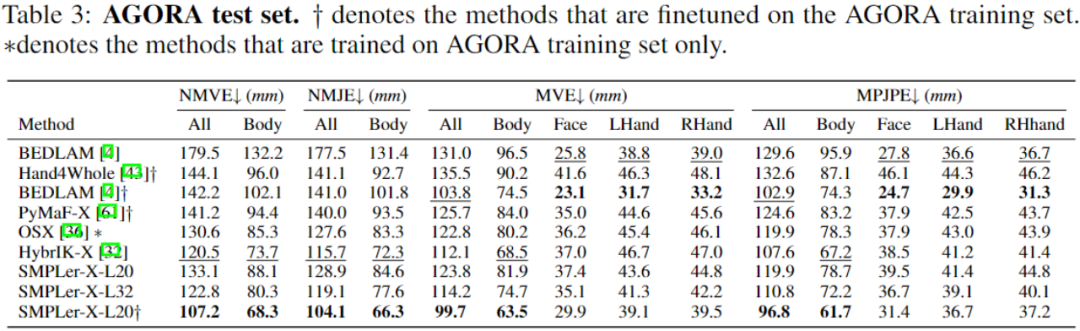
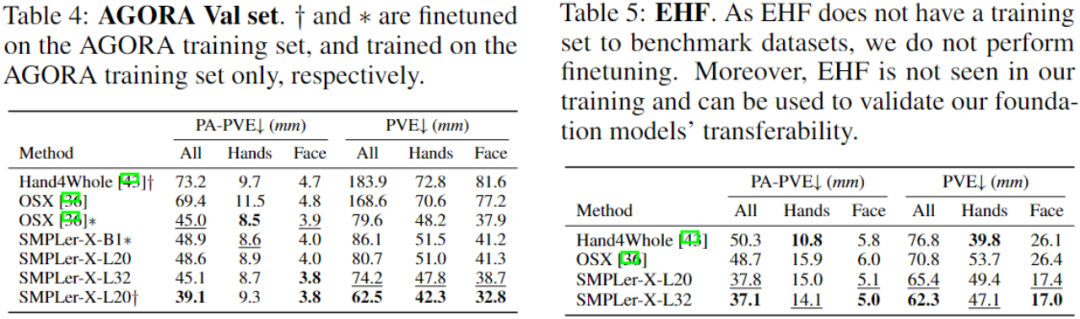
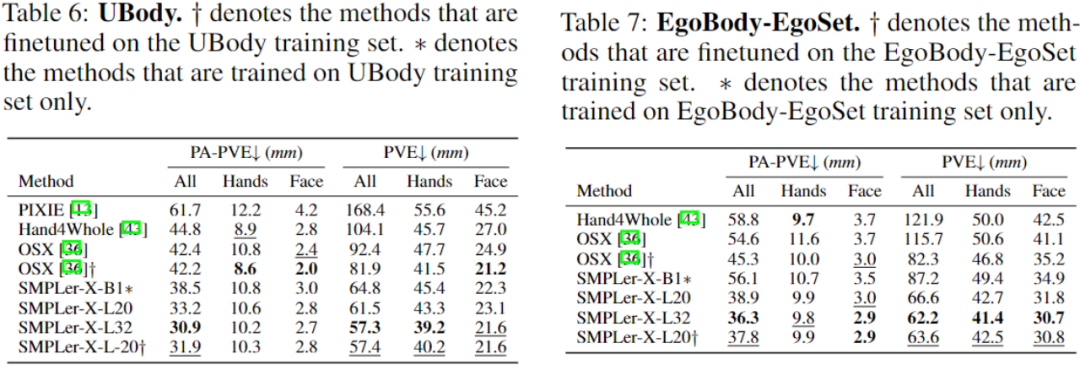
위 표는 AGORA 테스트 세트(표 3), AGORA 검증 세트(표 4), EHF(표 5), UBody(표 5) 등 주요 테스트 중 일부를 보여줍니다. 6) , EgoBody-EgoSet(표 7).
또한 연구원들은 ARCTIC과 DNA-Rendering이라는 두 가지 테스트 세트에서 대형 모션 캡처 모델의 일반화를 평가했습니다.
연구원들은 SMPLer-X가 알고리즘 설계 이상의 이점을 가져올 수 있기를 바랍니다. 강력한 전신 인간 모션 캡처 모델을 갖춘 학술 커뮤니티입니다.
코드와 사전 훈련된 모델은 프로젝트 홈페이지에 오픈소스로 공개되어 있습니다. 자세한 내용은 https://caizhongang.github.io/projects/SMPLer-X/를 방문해 주세요.
결과 표시



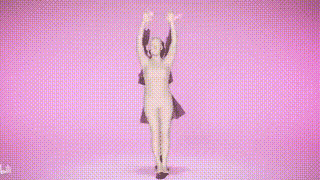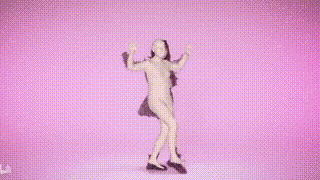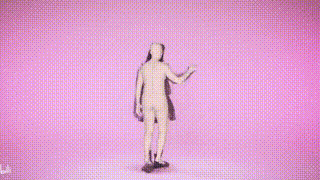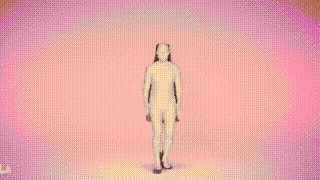




위 내용은 SMPLer-X: 7개의 주요 목록을 뒤집고 최초의 인간 모션 캡처 모델을 선보입니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!