
자율주행을 위한 엔드투엔드 계획 방법 검토

- 王林앞으로
- 2023-10-30 14:45:05985검색
본 글은 Heart of Autonomous Driving 공개 계정의 승인을 받아 재인쇄되었습니다. 재인쇄를 원하시면 원본 출처로 문의해 주세요
1. Woven Planet(도요타 자회사)의 계획: Urban Driver 2021
이렇지만 21년차 기사인데, 많은 새로운 기사들이 비교를 위한 기준으로 사용하고 있기 때문에 그 방법에 대한 이해도 필요합니다
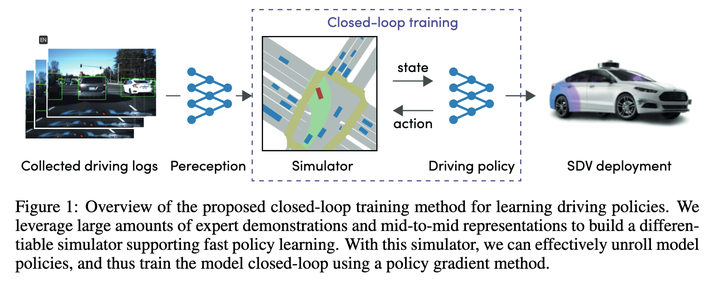
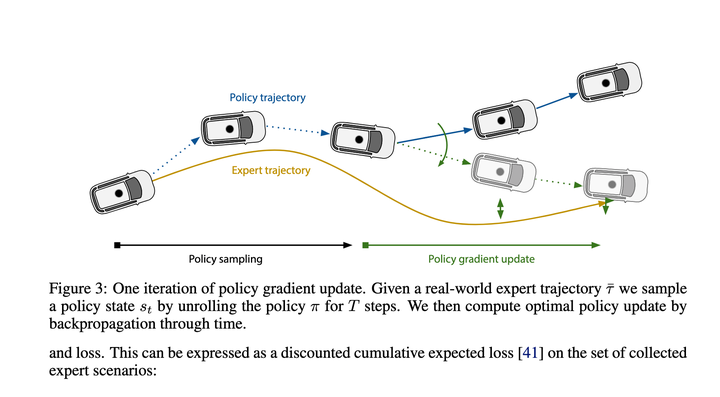
대략 살펴보면 주로 Policy Gradients를 사용하여 매핑 기능을 학습합니다. of State->Recent Action 이 매핑을 사용하면 전체 실행 궤적을 단계별로 추론할 수 있습니다. 최종 손실은 이 추론을 통해 제공되는 궤적을 전문가 궤적에 최대한 가깝게 만드는 것입니다.
당시 효과가 꽤 좋아야 새로운 알고리즘의 기준이 될 수 있습니다.
2. 난양공과대학 계획 1 역강화학습을 이용한 조건부 예측 행동 계획 2023.04
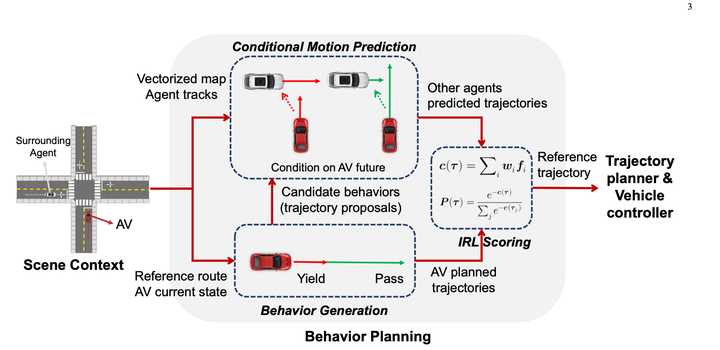
먼저 규칙을 사용하여 다양한 행동을 열거하고 10~30개의 궤적을 생성합니다. (예측 결과는 사용하지 않음)
조건부 예측을 사용하여 각 자차의 후보 궤적에 대한 예측 결과를 계산한 후 IRL을 사용하여 후보 궤적에 점수를 매깁니다.
조건부 결합 예측 모델은 다음과 같습니다.
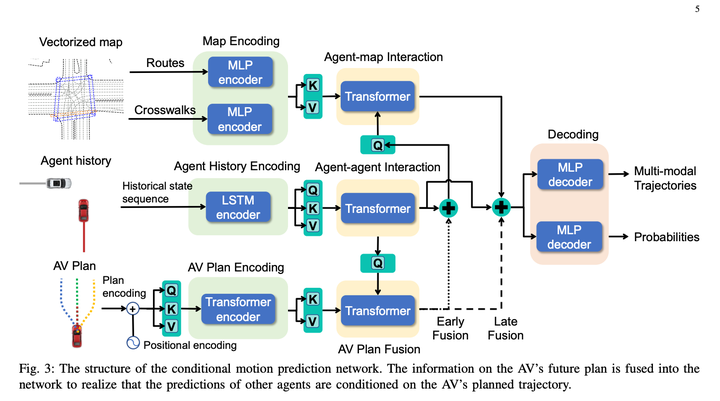
이 방법의 기본적으로 좋은 점은 조건부 결합 예측을 사용하여 대화형 예측을 완료하고 알고리즘에 특정 게임 기능을 제공한다는 것입니다.
하지만 개인적으로 알고리즘의 단점은 이전에는 10~30개의 궤적만 생성되었고, 궤적 생성 시 예측은 고려되지 않았으며, 결국 IRL 이후에는 이 궤적 중 하나가 최종 결과로 직접 선택된다는 점이라고 생각합니다. 예측을 고려한 후 이상적이지 않은 10~30개의 상황에 대해 더 쉽게 채점할 수 있습니다. 그것은 불구자 중에서 장군을 선택하는 것과 같으며, 뽑힌 사람은 여전히 불구자입니다. 이 솔루션을 기반으로 앞선 샘플 생성 품질 문제를 해결하는 좋은 방법이 될 것입니다.
3. NVIDIA 솔루션: 2023.02 학습된 행동 모델을 사용한 트리 구조 정책 계획
정기적인 트리 샘플링을 사용하여, 레이어별로 나중에 생각해 보면 각 레이어의 각 하위 노드에 대한 조건부 예측을 생성한 다음 규칙을 사용하여 예측 결과와 주요 차량 궤적을 점수화하고 몇 가지 규칙을 사용하여 불법적인 규칙을 제거한 다음 DP를 사용하여 미래에 최적의 궤적을 생성하는 DP 아이디어는 Apollo의 dp_path_optimizer와 다소 유사하지만 시간 차원을 추가합니다.
그러나 차원이 하나 더 있기 때문에 너무 여러 번 확장한 후에도 솔루션 공간이 여전히 크고 계산량이 너무 커질 것입니다. 현재 논문에 작성된 방법은 노드가 있을 때 일부 노드를 무작위로 폐기하는 것입니다. 노드가 너무 많으면 계산량을 제어할 수 있는지 확인하세요(노드가 너무 많으면 n 레벨 이후일 수 있고 영향이 상대적으로 작을 수 있다는 의미인 것처럼 느껴짐)
이 기사의 주요 기여 이 트리 샘플링 규칙 프로세스를 통해 연속 솔루션 공간을 마르코프 결정으로 변환한 다음 dp를 사용하여 이를 해결하는 것입니다.
4. 2023년 10월 난양공과대학교와 NVIDIA의 최신 공동 계획: DTPP: 자율 주행의 트리 정책 계획을 위한 미분 가능한 공동 조건부 예측 및 비용 평가
제목이 매우 흥미로워요:
1. 특정 게임 효과
2. 미분 가능하며 전체 기울기를 다시 전달할 수 있으므로 IRL과 함께 예측을 훈련할 수 있습니다. 이는 엔드 투 엔드 자율주행을 구축하기 위한 필수 조건이기도 합니다. 셋째, 트리 정책 계획에는 특정 대화형 추론 기능이 있을 수 있습니다. 자세히 읽어보니 이 기사가 매우 유익하고 방법도 매우 유용하다는 것을 알았습니다. 영리한.
NVIDIA의 TPP와 Nanyang Polytechnic의 조건부 예측 행동 계획을 역 강화 학습과 결합하고 개선한 후 이전 Nanyang Polytechnic 논문의 불량한 후보자 궤적 문제가 성공적으로 해결되었습니다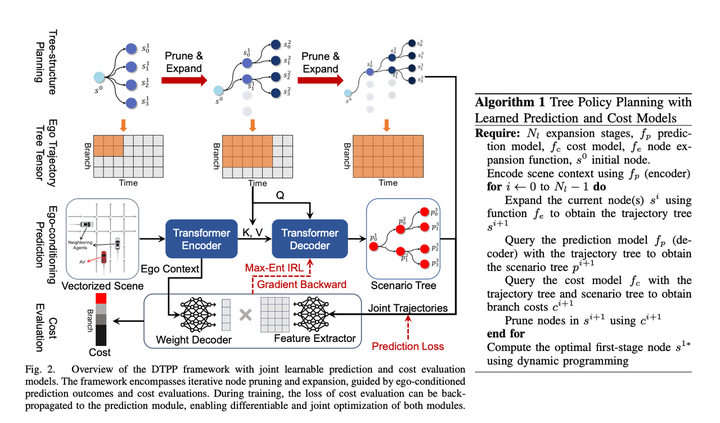
1. 조건부 예측 모듈은 주 차량의 과거 궤적 + 프롬프트 궤적 + 장애물 차량의 과거 궤적을 입력하여 프롬프트 궤적으로 접근하는 주 차량의 예측 궤적과 일관된 장애물 차량의 예측 궤적을 제공합니다. 주요 차량의 행동과 함께.
2. 채점 모듈은 주 차량 + 장애물 차량 궤적을 점수화하여 궤적이 전문가의 행동과 유사한지 확인할 수 있습니다. 학습 방법은 IRL입니다.
3. 여러 후보 궤적을 생성하는 데 사용되는 트리 정책 검색 모듈트리 검색 알고리즘은 주 차량의 실행 가능한 솔루션을 탐색하는 데 사용됩니다. 탐색 프로세스의 각 단계에서는 탐색된 궤적을 입력으로 사용하고 조건부 예측 알고리즘을 사용하여 주 차량과 장애물 차량의 예측 궤적을 생성합니다. 궤적의 우수성을 평가하기 위해 채점 모듈을 호출하므로 다음 확장 노드 검색 방향에 영향을 미칩니다. 이 방법을 통해 다른 솔루션과 다른 일부 주요 차량 궤적을 생성할 수 있으며, 궤적 생성 시 장애물 차량과의 상호 작용을 고려할 수 있습니다.
기존 IRL은 전면 및 후면 기능과 같은 많은 기능을 수동으로 생성합니다. 궤적 시간 차원(상대 s, l 및 ttc 등)의 장애물 특징 이 기사에서는 모델을 차별화 가능하게 만들기 위해 예측의 자아 컨텍스트 MLP를 직접 사용하여 가중치 배열(크기 = 1 * C), 자차 주변의 환경 정보를 암묵적으로 표현한 다음 MLP를 사용하여 자차 궤적 + 해당 다중 모드 예측 결과를 Feature 배열(크기 = C * N, N은 후보 궤적의 수를 나타냄)로 직접 변환합니다. ), 그리고 두 행렬을 곱하여 최종 궤적 점수를 얻습니다. 그런 다음 IRL은 전문가가 가장 높은 점수를 얻도록 합니다. 개인적으로 나는 이것이 계산 효율성을 위한 것이라고 생각하여 디코더를 최대한 단순하게 만들지만 여전히 주요 차량 정보의 손실이 있습니다. 계산 효율성에 주의를 기울이지 않으면 좀 더 복잡한 네트워크를 사용하여 얻을 수 있습니다. Ego Context와 Predicted Trajectories를 연결하면 효과 수준이 좋아질 것입니다. 또는 차별화 가능성을 포기하더라도 수동으로 설정한 기능을 추가하는 것을 고려할 수 있으며 이를 통해 모델 효과도 향상됩니다.
시간 측면에서 이 솔루션은 한 번의 재인코딩 + 다중 경량 디코딩 방법을 사용하여 계산 지연을 성공적으로 줄입니다. 기사에서는 지연을 98밀리초로 압축할 수 있다고 지적합니다
학습 기반 기획자 중 SOTA 등급에 속하며, 폐쇄 루프 효과는 이전 기사에서 언급한 누플랜의 1위 Rule Based 방식 PDM에 가깝습니다.
요약
보고 나면 이 패러다임이 좋은 아이디어라고 생각합니다. 중간에 특정 프로세스를 조정하는 방법을 찾을 수 있습니다.
- 예측 모델을 사용하여 일부 후보 자아를 생성하는 몇 가지 규칙을 안내합니다. trajectories
- 각 궤적에 대해 조건부 공동 예측을 사용하여 대화형 예측을 만들고 에이전트 예측을 생성합니다. 게임 성능을 향상시킬 수 있습니다.
- IRL 및 기타 방법은 조건부 결합 예측 결과를 사용하여 이전 주요 차량 궤적을 점수화하고 최적의 궤적을 선택합니다

다시 작성해야 하는 내용은 다음과 같습니다. 원본 링크: https://mp.weixin. qq.com/s/ZJtMU3zGciot1g5BoCe9Ow
위 내용은 자율주행을 위한 엔드투엔드 계획 방법 검토의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!