
FMCW 레이더 위치 인식을 우아하게 구현하는 방법(IROS2023)

- 王林앞으로
- 2023-10-26 11:13:011510검색
안녕하세요 여러분, 제 이름은 Yuan Jianhao입니다. IROS2023에서 레이더 위치 인식에 대한 우리의 작업을 공유하기 위해 Heart of Autonomous Driving 플랫폼에 오게 되어 매우 기쁩니다.
FMCW(주파수 변조 연속파) 레이더를 사용한 위치 지정은 까다로운 환경에 대한 고유한 저항성으로 인해 점점 더 주목을 받고 있습니다. 그러나 레이더 측정 프로세스의 복잡한 아티팩트는 이 유망한 센서 방식을 안전하고 안정적으로 적용하기 위해 적절한 불확실성 추정이 필요합니다. 본 연구에서는 추가 현지화를 위해 임베딩 공간에서 학습된 분산 속성을 기반으로 "최적" 맵을 구축하는 다중 세션 맵 관리 시스템을 제안합니다. 동일한 분산 속성을 사용하여 정확하지 않을 수 있는 위치 쿼리를 내부적으로 거부하는 새로운 방법도 제안합니다. 이를 위해 주행 경로를 따라 레이더 데이터의 단기 변화를 활용하고(데이터 확대를 위해) 미터법 공간 기반 위치 식별의 다운스트림 불확실성을 예측하는 강력한 소음 인식 미터법 학습을 적용합니다. 우리는 Oxford Radar RobotCar 및 MulRan 데이터 세트에 대한 광범위한 교차 검증 테스트를 통해 우리 접근 방식의 효율성을 입증합니다. 여기서는 단일 최근접 이웃 쿼리만 사용하여 레이더 위치 식별 및 기타 불확실성 인식 방법의 현재 최첨단 기술을 능가합니다. 또한 불확실성을 기반으로 쿼리를 거부할 때 어려운 테스트 환경에서 성능이 향상되는 것을 보여줍니다. 이는 경쟁 불확실성 인식 위치 인식 시스템에서는 관찰되지 않은 것입니다.
레이더의 출발점에서
위치 인식 및 위치 파악은 시스템이 환경을 이해하고 탐색할 수 있도록 하기 때문에 로봇 공학 및 자율 시스템 분야에서 중요한 작업입니다. 기존의 비전 기반 위치 인식 방법은 조명, 날씨, 폐색 등 환경 조건의 변화에 취약하여 성능 저하를 초래하는 경우가 많습니다. 이 문제를 해결하기 위해 이러한 적대적 환경에서 강력한 센서 대안으로 FMCW 레이더를 사용하는 것에 대한 관심이 높아지고 있습니다.
기존 작업에서는 FMCW 레이더 위치 인식을 위한 수작업 및 학습 기반 특징 추출 방법의 효율성이 입증되었습니다. 기존 작업의 성공에도 불구하고 자율 주행과 같이 안전이 중요한 응용 분야에 이러한 방법을 배포하는 것은 여전히 교정 불확실성 추정으로 인해 제한됩니다. 이 영역에서는 다음 사항을 고려해야 합니다.
- 보안에서는 내성적 거부를 가능하게 하기 위해 오탐률로 잘 보정된 불확실성 추정이 필요합니다.
- 실시간 배포에는 빠른 단일 스캔 불확실성 기반 추론 기능이 필요합니다. 장기 자율성에서 반복적인 경로 탐색을 위해서는 온라인상의 지속적인 지도 유지 관리가 필요합니다.
시스템 프로세스 개요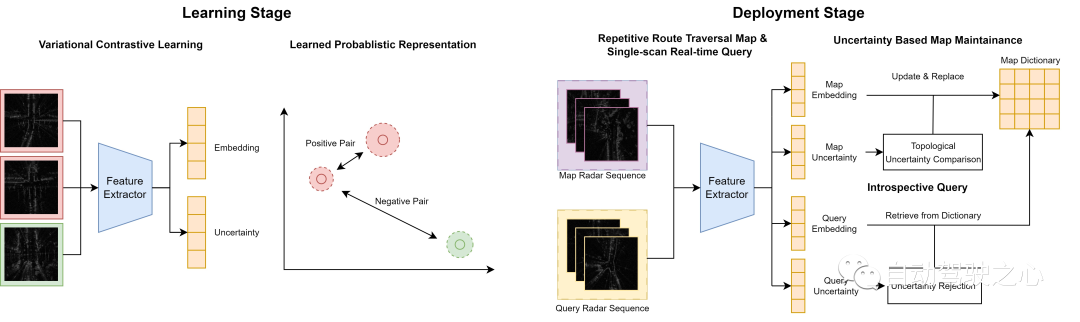
Off the Radar 방법 소개
이 글에서는 위치 식별의 불확실성을 설명하기 위해 레이더 위치 식별을 위한 변형 대조 학습 프레임워크를 소개합니다. 주요 기여는 다음과 같습니다:- 불확실성 인식 대조 학습 프레임워크.
- 교정 불확실성 추정을 기반으로 한 내성적 쿼리 메커니즘.
- 변화하는 환경에 맞춰 온라인 재귀 지도를 유지 관리합니다.
변형 대조 학습
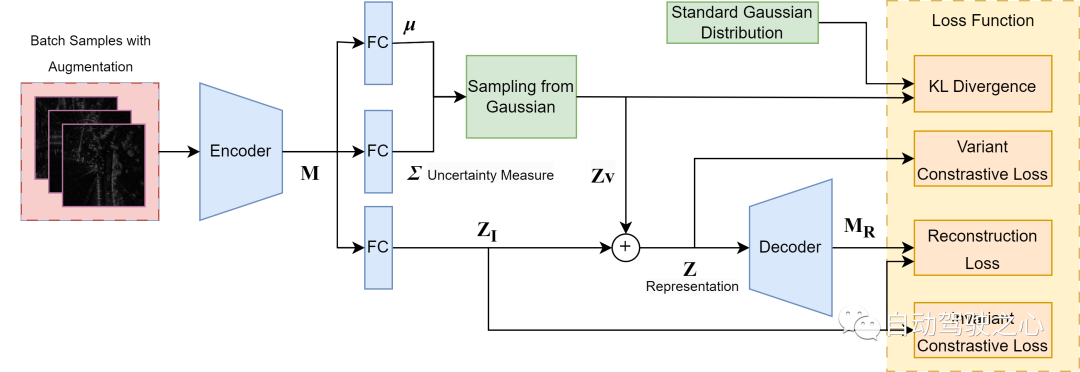
이 섹션의 작업은 우리의 핵심 기여를 가능하게 하는 핵심 요소이자 레이더 위치 인식과 심층 변형 측정 학습의 새로운 통합일 뿐만 아니라 위치 인식의 불확실성을 특성화하는 새로운 방법입니다. 그림에서 볼 수 있듯이 레이더 스캔 임베딩을 예측과 관련 없는 불확실성 소스의 분산을 포착하는 잡음 유발 가변 부분과 장면 표현을 위한 의미 불변 부분으로 분해하는 구조를 채택합니다. 변수 부분은 나중에 이전의 다변량 동일 제곱 가우스 분포에서 샘플링되고 불변 부분에 추가되어 전체 표현을 형성합니다. 가변 출력은 불확실성 측정으로 직접 사용됩니다. 우리는 데이터의 고유한 모호함과 무작위성으로 인해 발생하는 모델 예측의 우발적 불확실성만을 불확실성의 주요 원인으로 간주한다고 가정합니다. 특히 레이더 스캔의 경우 이는 얼룩 노이즈, 채도 및 일시적인 폐색으로 인해 발생할 수 있습니다. 선택한 손실 함수에 관계없이 표준 메트릭 학습 방법은 긍정적인 예 쌍 사이에 잠재적인 차이를 무시하면서 두 쌍의 긍정적인 예 사이에 동일한 임베딩을 강제하는 경향이 있습니다. 그러나 이로 인해 모델이 작은 특성에 둔감해지고 훈련 분포에 과적합될 수 있습니다. 따라서 잡음 분산을 모델링하기 위해 구조의 추가 확률적 분산 출력을 사용하여 가능성 있는 불확실성을 추정합니다. 이러한 잡음 인식 레이더 인식 표현을 구축하기 위해 우리는 4가지 손실 함수를 사용하여 전체 훈련을 안내합니다.
1) 불변 임베딩에 충분한 인과 정보가 포함되도록 레이더 의미에서 작업과 관련 없는 노이즈를 분리하기 위한 결정적 표현(Z_I)의 불변 대비 손실 및
2) 가변 대비 손실 전체 표현(Z ), 의미 있는 메트릭 공간을 설정합니다. 두 대비 손실은 모두 다음과 같은 형태를 취합니다.
배치 중 하나는 m개의 샘플과 회전 불변성을 위한 회전 증대인 "회전" 전략을 사용하는 합성 회전의 시간적으로 근사된 프레임 증대로 구성됩니다. 우리의 목표는 증가된 표본이 원본 인스턴스로 인식될 확률을 최대화하는 동시에 반전 사례의 확률을 최소화하는 것입니다.
임베딩(Z)은 방정식 1)과 2)에 설명된 대로 (Z_I) 또는 (Z)입니다.
3) Kullback–Leibler(KL) 발산 학습된 가우스 분포와 표준 등방성 다변량 가우스 분포 사이에서 이는 데이터 노이즈에 대한 선험적 가정입니다. 이는 모든 샘플에 걸쳐 동일한 노이즈 분포를 보장하고 변수 출력의 절대값에 대한 정적 참조를 제공합니다.
4) 재구성 손실 은 추출된 특징 맵(M)과 디코더 출력(M_R) 사이에 있으며, 이는 전체 표현(Z)이 재구성될 원본 레이더 스캔의 충분한 정보를 포함하도록 강제합니다. 그러나 우리는 디코딩 과정에서 계산 비용을 줄이기 위해 픽셀 수준의 레이더 스캔 재구성 대신 저차원 특징 맵만 재구성합니다.
KL 발산 및 재구성 손실로만 구동되는 일반적인 VAE 구조도 잠재 분산을 제공하지만 잘 알려진 후방 붕괴 및 소멸 분산 문제로 인해 불확실성 추정에 신뢰할 수 없는 것으로 간주됩니다. 이러한 비효율성은 주로 훈련 중 두 손실의 불균형으로 인해 발생합니다. KL 발산이 지배적일 때 잠재 공간 후방은 사전과 동일하게 강제되는 반면, 재구성 손실이 지배적일 때 잠재 분산은 0으로 푸시됩니다. 그러나 우리의 접근 방식에서는 가변 대비 손실을 추가 정규화 도구로 도입하여 보다 안정적인 훈련을 달성합니다. 여기서 분산은 메트릭 공간에서 클러스터 중심 간의 견고한 경계를 유지하기 위해 구동됩니다. 결과적으로, 우리는 레이더 인식의 기본 우발적 불확실성을 반영하는 보다 신뢰할 수 있는 기본 공간 변화를 얻습니다. 우리는 기능이 증가하는 손실 설정에서 불확실성을 학습하는 특정 접근 방식의 이점을 보여 주기로 결정했습니다. 이 분야에서 레이더 위치 인식을 위한 최첨단 기술은 이미 많은(예: 2개 이상) 네거티브 샘플의 손실을 사용하므로 이를 기반으로 확장합니다.
지속적인 지도 유지관리
지속적인 지도 유지관리는 온라인 시스템의 중요한 기능입니다. 자율주행차 운행 중에 얻은 스캔 데이터를 최대한 활용하고 지도를 반복적으로 개선하는 것을 목표로 하기 때문입니다. 새로운 레이더 스캔을 이전에 탐색된 스캔으로 구성된 상위 맵에 병합하는 과정은 다음과 같습니다. 각 레이더 스캔은 숨겨진 표현과 불확실성 지표로 표시됩니다. 병합 프로세스 동안 우리는 임계값 아래의 토폴로지 거리를 가진 각각의 새로운 스캔에 대해 일치하는 양성 샘플을 검색합니다. 새 스캔의 불확실성이 낮으면 상위 맵에 통합되어 일치하는 스캔을 대체하고, 그렇지 않으면 폐기됩니다.
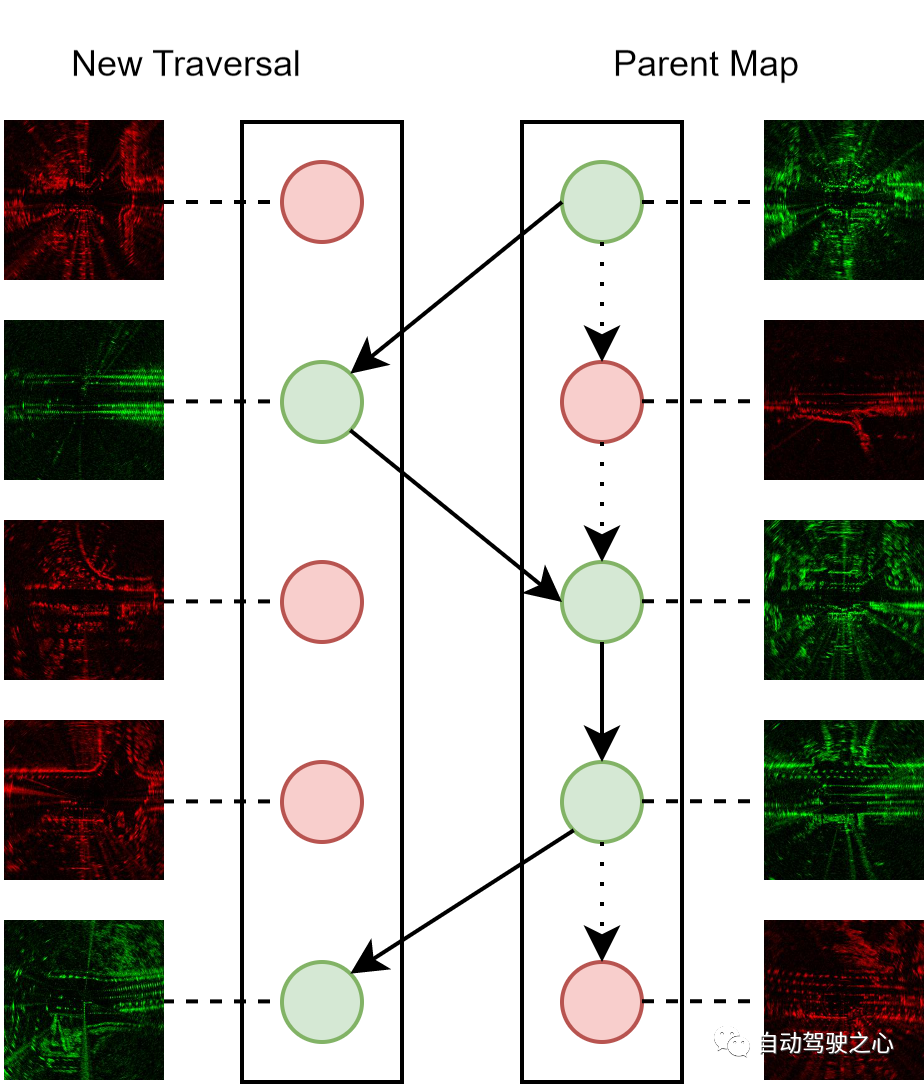
지도 유지 관리의 개략도: 빨간색과 녹색 노드는 각각 불확실성이 더 높고 낮은 레이더 스캔을 나타냅니다. 우리는 항상 불확실성이 가장 낮은 스캔으로만 구성된 각 위치의 위치 지정 참조로 상위 지도를 유지합니다. 파선 가장자리는 상위 맵의 초기 상태를 나타내고 단색 가장자리는 상위 맵의 업데이트된 버전을 나타냅니다.
유지 관리 과정을 반복적으로 수행함으로써 통합 상위 맵의 품질을 점차적으로 향상시킬 수 있습니다. 따라서 유지 관리 알고리즘은 동일한 경로 순회에 대한 여러 경험을 지속적으로 활용하여 인식 성능을 향상시키면서 일정한 상위 맵 크기를 유지하여 예산 계산 및 저장 비용이 발생하기 때문에 효과적인 온라인 배포 전략의 역할을 할 수 있습니다.
내부 쿼리
표준 가우스 분포 측정값의 모델 불확실성으로 인해 모든 차원의 추정 분산은 1에 가깝습니다. 따라서 두 개의 하이퍼파라미터인 Delta와 N을 사용하여 불확실성 거부의 규모와 해결 방법을 완전히 정의할 수 있습니다. 결과 임계값 T는 다음과 같이 정의됩니다.
m차원 잠재 분산이 있는 스캔에서 모든 차원에 대한 평균을 구하여 스칼라 불확실성 측정값을 얻습니다.
예측 거부
추론 시간에 자체 검사를 수행합니다. 쿼리 거부 , 분산이 정의된 임계값을 초과하는 쿼리 스캔은 식별이 거부됩니다. STUN 및 MC Dropout과 같은 기존 방법은 샘플 배치의 불확실성 범위를 임계값 수준으로 동적으로 나눕니다. 그러나 이를 위해서는 추론 중에 여러 샘플이 필요하며 특히 샘플 수가 적은 경우 불안정한 거부 성능으로 이어질 수 있습니다. 대조적으로, 우리의 정적 임계값 전략은 샘플 독립적인 임계값 수준을 제공하고 일관된 단일 스캔 불확실성 추정 및 거부를 제공합니다. 운전 중에 레이더 스캔이 프레임별로 수집되므로 이 기능은 위치 인식 시스템의 실시간 배포에 매우 중요합니다.
실험 세부정보
이 기사에서는 1) Oxford Radar RobotCar와 2) MulRan의 두 가지 데이터 세트를 사용합니다. 두 데이터 세트 모두 CTS350-X Navtech FMCW 스캐닝 레이더를 사용합니다. 레이더 시스템은 76GHz ~ 77GHz 범위에서 작동하며 4.38cm의 해상도로 최대 3768개의 범위 판독값을 생성할 수 있습니다.
benchmark의 인식 성능은 BCRadar라고 불리는 Gaddet al에서 제안한 최첨단 레이더 사이트 식별 방법인 원래 VAE를 포함한 여러 기존 방법과 비교하여 수행됩니다. 및 비학습 기반 메서드 RingKey(회전 세분화가 없는 ScanContext의 일부)입니다. 또한 불확실성 인식 장소 인식의 기준이 되는 MC Dropout 및 STUN과 성능을 비교합니다.
절제 연구 제안된 내부 쿼리(Q) 및 맵 유지 관리(M) 모듈의 효율성을 평가하기 위해 각각 OURS(O/M) /Q로 표시되는 방법의 다양한 변형을 비교하여 절제 연구를 수행했습니다. /QM), 세부 사항은 다음과 같습니다.
- O: 맵 유지 관리 없음, 내부 쿼리 없음
- M: 맵 유지 관리만
- Q: 내부 쿼리만
- QM: 맵 유지 관리와 내부 쿼리 모두 특정합니다. 예를 들어 , O와 M 사이의 식별 성능과 Q와 QM 사이의 불확실성 추정 성능을 비교했습니다.
공통 설정 공정한 비교를 보장하기 위해 모든 대조 학습 기반 방법에 대해 공통 배치 대조 손실을 채택하여 벤치마크 전체에서 일관된 손실 함수를 제공합니다.
구현 세부 정보
스캔 설정
모든 방법에 대해 A = 400 베어링 및 B = 3768 그리드의 극지 레이더 스캔을 각 상자 크기가 4.38cm, W = 측면 길이가 256인 데카르트 스캔으로 변환합니다. 상자 크기는 0.5m입니다.
초매개변수 훈련
배경 특징 추출기로 VGG-19 [^simonyan2014very^]를 사용하고 선형 레이어를 사용하여 추출된 특징을 낮은 임베딩 차원 d=128에 투영합니다. 우리는 학습률 1e{-5} 및 배치 크기 8로 Oxford Radar RobotCar에서 10개 에포크, MulRan에서 15회 반복에 대한 모든 기준을 훈련했습니다.
평가 측정항목
장소 인식 성능을 평가하기 위해 Recall@N (R@N)Recall@N (R@N) 指标,这是通过确定在 N 个候选者中是否至少有一个候选者接近 GPS/INS 所指示的地面真实值来确定的本地化的准确性。这对于自动驾驶应用中的安全保证尤为重要,因为它反映了系统对假阴性率的校准。我们还使用 Average Precision (AP) 来测量所有召回级别的平均精度。最后,我们使用 F-scores 与 beta=2/1/0.5 来分配召回对精确度的重要性级别,作为评估整体识别性能的综合指标。
此外,为了评估不确定性估计性能。我们使用 Recall@RR,在这里我们执行内省查询拒绝,并在不同的不确定性阈值级别上评估 Recall@N=1 -- 拒绝所有查询的扫描的不确定性大于阈值的。我们因此拒绝了 0-100% 的查询。
结果总结
地点识别性能
如 Oxford Radar RobotCar实验中表格1所示,我们的方法仅使用度量学习模块,在所有指标上都取得了最高的性能。具体来说,在 Recall@1 方面,我们的方法 OURS(O) 展示了通过变分对比学习框架学习的方差解耦表示的有效性,实现了超过 90.46% 的识别性能。这进一步得到了 MulRan 实验结果的支持,如表2所示,我们的方法在 Recall@1、总体 F-scores 和 AP 上均优于其他所有方法。尽管在 MulRan 实验中,VAE 在 Recall@5/10 上优于我们的方法,但我们的方法在两种设置中的最佳 F-1/0.5/2 和 AP N개의 후보 중 최소 1개의 후보가 있는지 확인하는 지표 정확도 GPS/INS가 지시하는 Ground Truth에 접근하여 위치 파악이 결정됩니다. 이는 시스템의 위음성율 보정을 반영하므로 자율 주행 애플리케이션의 안전 보장에 특히 중요합니다. 또한
평균 정밀도(AP) 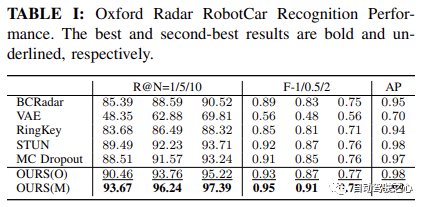 모든 재현율 수준의 평균 정밀도를 측정합니다. 마지막으로
모든 재현율 수준의 평균 정밀도를 측정합니다. 마지막으로
F-점수 및
beta=2/1/0.5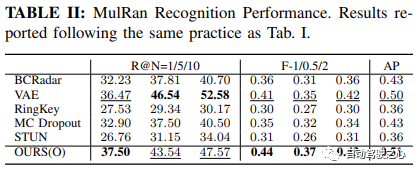
Recall@RR, 내성적인 쿼리 거부를 수행하고 다양한 불확실성 임계값 수준에서 평가합니다 🎜 🎜Recall@N=1🎜-- 거부 모든 쿼리는 더 큰 불확실성으로 검사됩니다. 문턱보다. 결과적으로 쿼리를 0~100% 거부합니다. 🎜🎜결과 요약🎜
🎜🎜장소 인식 성능🎜🎜🎜Oxford Radar RobotCar 실험의 표 1에서 볼 수 있듯이 우리의 방법은 메트릭 학습 모듈만을 사용하여 모든 메트릭에서 가장 높은 성능을 달성했습니다. 구체적으로 🎜 🎜Recall@1🎜 🎜성능 측면에서 우리의 방법 OURS(O)는 변형 대조 학습 프레임워크를 통해 학습된 분산 분리 표현의 효율성을 보여 90.46% 이상의 인식 성능을 달성합니다. 이는 🎜 🎜MulRan🎜 🎜표 2에 표시된 대로 추가로 뒷받침됩니다. -radius: 4px; Overflow-wrap: break-word text-indent: 0px; block;">Recall@1, 전체 🎜 🎜F-점수🎜 🎜 및 🎜 🎜AP🎜는 다른 모든 방법보다 우수합니다. 🎜 🎜MulRan🎜 🎜실험에서는 VAE가 🎜🎜 ; text-indent: 0px; display: inline-block;">Recall@5/10 🎜 🎜보다 우수하지만 우리의 방법은 두 설정 중 가장 좋은 설정 🎜 🎜F- 1/0.5/2🎜 🎜 및 🎜 🎜AP🎜 🎜는 우리의 방법이 더 높은 정밀도와 재현율을 보여 더 정확하고 강력한 인식을 제공합니다. 성능. 🎜🎜🎜🎜🎜옥스포드 레이더 로봇자동차 인식 성능. 최고 결과와 차상위 결과는 각각 🎜굵게🎜 및 __밑줄__입니다. 🎜🎜🎜🎜🎜뮬란 인정 퍼포먼스. 형식은 위와 동일합니다. 🎜 또한 Oxford Radar RobotCar에서 진행 중인 지도 유지 관리를 더욱 활용하여 Recall@1Recall@1 进一步提高到 93.67%,超过了当前最先进的方法 STUN,超出了 4.18%。这进一步证明了学习方差作为一个有效的不确定性度量,以及基于不确定性的地图集成策略在提高地点识别性能方面的有效性。
不确定性估计性能
随着被拒绝的不确定查询的百分比增加,识别性能的变化,特别是 Recall@1,在 Oxford Radar RobotCar 实验中如图1所示,在 MulRan 实验中如图2所示。值得注意的是,我们的方法是唯一一个在两种实验设置中都展示出随着不确定查询拒绝率增加而持续改进的识别性能的方法。在MulRan实验中,OURS(Q) 是唯一一个随着拒绝率增加而持续平稳地提高 Recall@RR 指标的方法。与 VAE 和 STUN 相比,这两种方法也像我们的方法一样估计了模型的不确定性,OURS(Q) 在 Recall@RR=0.1/0.2/0.5 上实现了 +(1.32/3.02/8.46)% 的改进,而 VAE 和 STUN 分别下降了 -(3.79/5.24/8.80)% 和 -(2.97/4.16/6.30)%。
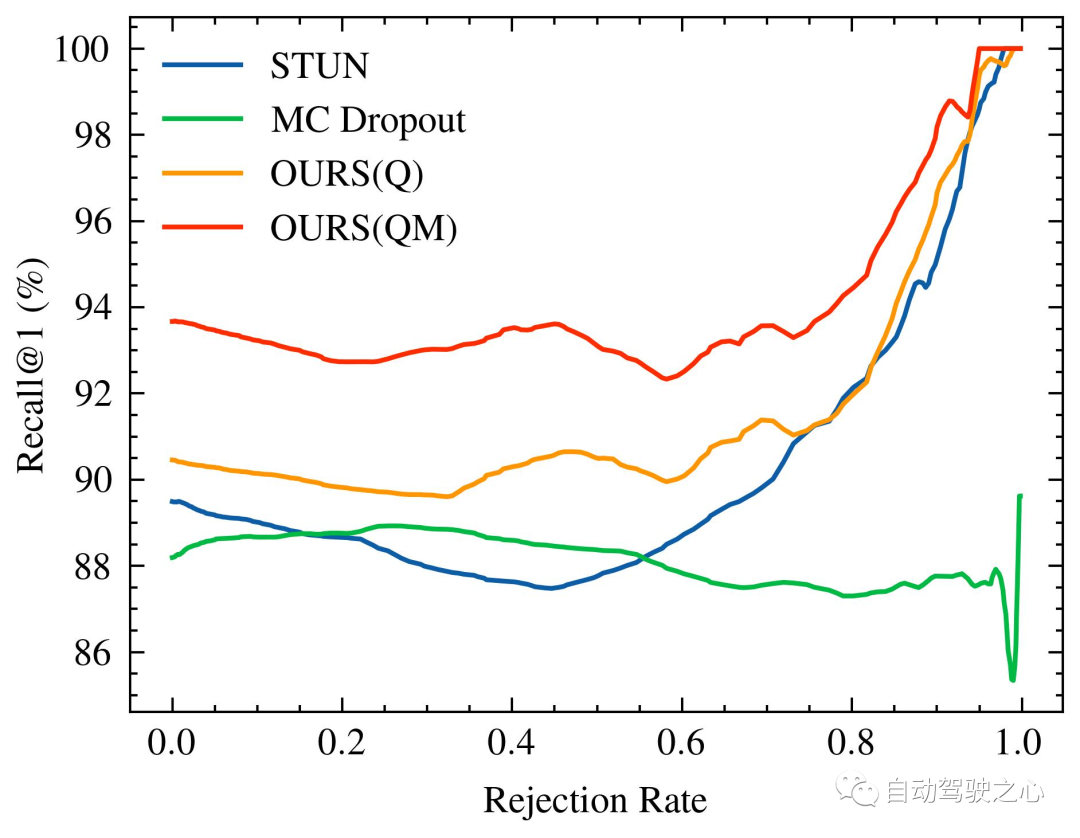
Oxford Radar RobotCar的内省查询拒绝性能。随着被拒绝的不确定查询的百分比增加,Recall@1增加/减少。由于 VAE 的性能与其他方法相比较低(具体为Recall@RR=0.1/0.2/0.5的 (48.42/48.08/18.48)%),因此没有进行可视化。
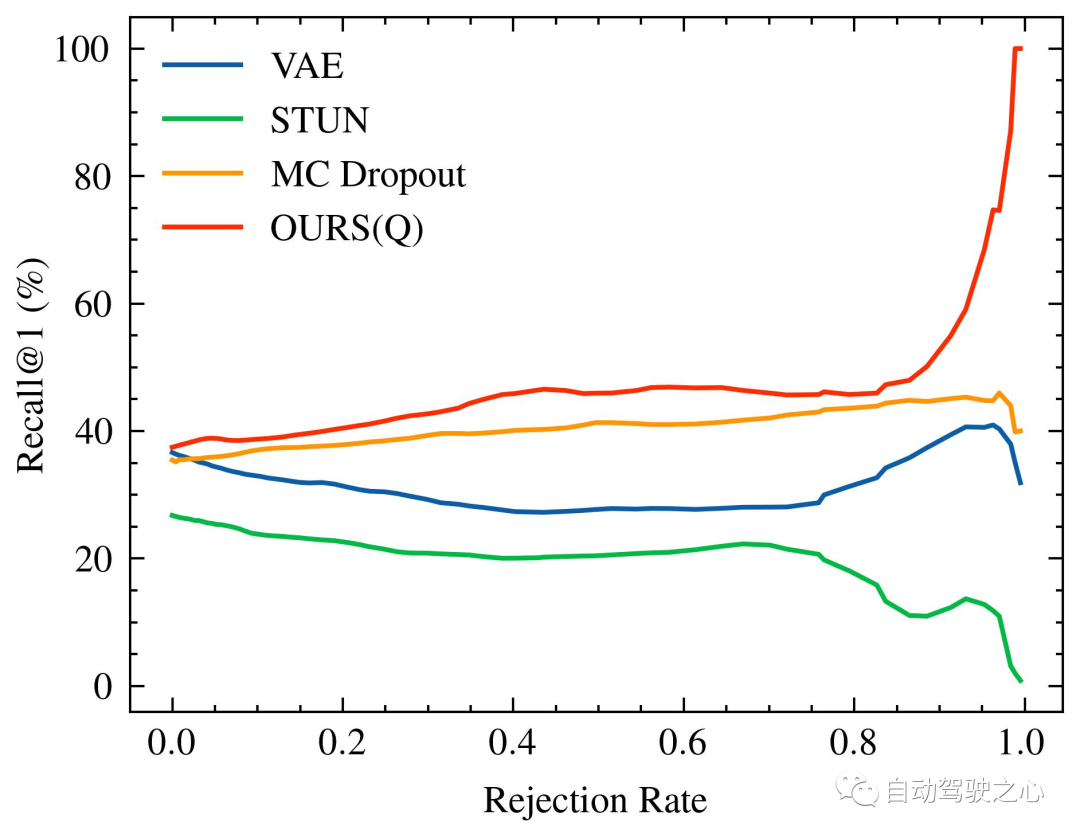
Mulran的内省查询拒绝性能。格式同上。
另一方面,与 MC Dropout 相比,后者估计了由于数据偏见和模型误差导致的认知不确定性,尽管它在Oxford Radar RobotCar实验的早期阶段有更高的 Recall@1 增加,但其性能总体上低于我们的,并且随着拒绝率进一步增加,未能实现更大的改进。最后,比较 OURS(Q) 和 OURS(QM) 在Oxford Radar RobotCar实验中,我们观察到 Recall@RR 현재 최첨단 방법인 STUN을 초과하여 93.67%로 더욱 향상되었습니다. 4.18%. 이는 효과적인 불확실성 측정으로서 학습된 분산의 효과와 장소 인식 성능을 향상시키는 불확실성 기반 지도 통합 전략을 추가로 보여줍니다.
불확실성 추정 성능
거부된 불확실한 쿼리의 비율이 증가함에 따라 인식 성능의 변화, 특히 Recall@1,
Oxford Radar RobotCar실험 그림 2와 같은
 MulRan
MulRan
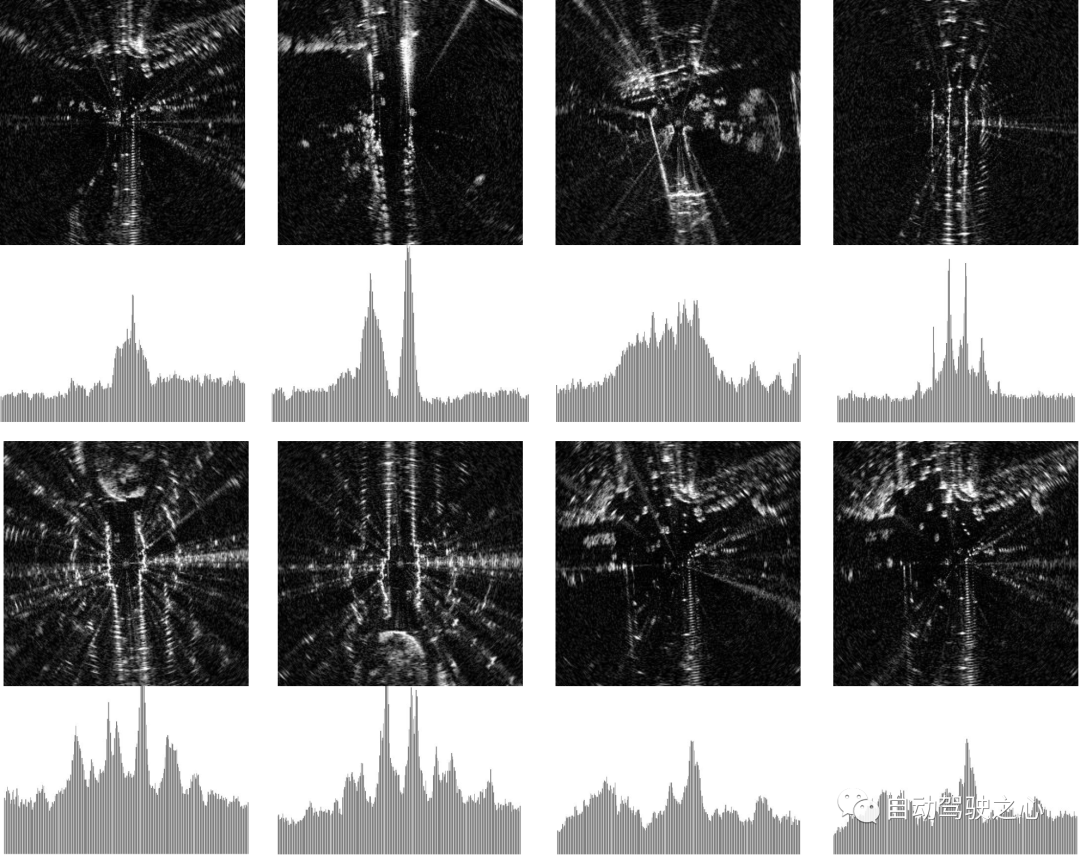
Recall@RR🎜 🎜 표시 방법. 우리의 방법과 같이 모델 불확실성을 추정하는 VAE 및 STUN과 비교하면 🎜 🎜Recall@RR=0.1/0.2/0.5🎜 🎜구현됨 +(1.32/ 3.02/8.46)%, VAE 및 STUN은 각각 -(3.79/5.24/8.80)% 및 -(2.97/4.16/6.30)% 감소했습니다. 🎜🎜🎜🎜 Oxford Radar RobotCar의 Introspection 쿼리 거부 성능. 거부된 불확실한 쿼리의 비율이 증가함에 따라 Recall@1증가/감소. VAE의 성능은 다른 방법에 비해 낮기 때문에(구체적으로 Recall@RR=0.1/0.2/0.5's (48.42/48.08/18.48)%)이므로 시각화되지 않습니다. 🎜🎜🎜🎜 Mulran의 성찰적인 쿼리 거부 성능. 형식은 위와 동일합니다. 🎜🎜한편, 데이터 편향과 모델 오류로 인한 인식적 불확실성을 추정하는 MC Dropout과 비교하면 Oxford Radar RobotCar 실험 초기 단계에서 더 높은 🎜 🎜을 나타냈지만 🎜Recall@1 🎜 증가했지만 전반적으로 성능이 우리보다 낮았고, 거부율이 더 높아질수록 더 큰 개선을 이루지 못했습니다. 마지막으로 OURS(Q)와 OURS(QM)를 비교했습니다. Oxford Radar RobotCar 실험에서 🎜 🎜Recall@RR🎜 🎜는 유사한 변경 패턴을 가지고 있지만 그 사이에는 상당한 차이가 있습니다. 이는 내성적 질의 및 지도 유지 관리 메커니즘이 장소 인식 시스템에 독립적으로 기여하며 각각 불확실성 측정값을 통합적인 방식으로 활용한다는 것을 의미합니다. 🎜🎜🎜 Off the Radar에 대한 토론 🎜🎜🎜🎜 정성적 분석 및 시각화 🎜🎜🎜 레이더 인식의 불확실성 원인을 정성적으로 평가하기 위해 우리는 불확실성 샘플의 시각적 비교 방법을 사용하여 두 데이터세트에서 높은/낮은 추정치를 제공합니다. 표시된 것처럼 불확실성이 높은 레이더 스캔은 일반적으로 모션 블러가 심하고 감지되지 않은 영역이 드물게 표시되는 반면, 불확실성이 낮은 스캔은 일반적으로 히스토그램에서 강도가 더 강한 뚜렷한 특징을 포함합니다. 🎜🎜🎜🎜다양한 수준의 불확실성으로 레이더 스캔을 시각화합니다. 왼쪽의 네 가지 예는 Oxford Radar RobotCar 데이터 세트에서 가져온 것이고 오른쪽의 네 가지 예는 MulRan에서 가져온 것입니다. 불확실성이 가장 높은(위)/가장 낮은(아래) 상위 10개 샘플을 표시합니다. 레이더 스캔은 향상된 대비를 위해 데카르트 좌표로 표시됩니다. 각 이미지 아래의 히스토그램은 모든 방위각에서 추출된 강도의 RingKey 설명자 기능을 보여줍니다.
이는 레이더 인식의 불확실성 원인에 대한 우리의 가설을 더욱 뒷받침하고 우리의 불확실성 측정이 이 데이터 노이즈를 포착한다는 정성적 증거 역할을 합니다.
데이터 세트 차이
벤치마크 실험에서 우리는 두 데이터 세트 간의 인식 성능에 상당한 차이가 있음을 관찰했습니다. 우리는 사용 가능한 훈련 데이터의 크기가 타당한 이유일 수 있다고 생각합니다. Oxford Radar RobotCar의 훈련 세트에는 300Km 이상의 운전 경험이 포함되어 있는 반면, MulRan 데이터 세트에는 약 120Km만 포함되어 있습니다. 그러나 RingKey 설명자 메서드의 성능 저하도 고려하세요. 이는 레이더 장면 인식에 고유한 구별할 수 없는 특징이 있을 수 있음을 시사합니다. 예를 들어, 열린 공간이 희박한 환경에서는 종종 동일한 스캔이 발생하고 인식 성능이 최적이 아닌 것으로 나타났습니다. 우리는 이러한 불확실성이 높은 상황에서 우리 시스템과 다양한 기준에 어떤 일이 발생하는지 이 데이터세트를 통해 보여줍니다.

원본 링크: https://mp.weixin.qq.com/s/wu7whicFEAuo65kYp4quow
위 내용은 FMCW 레이더 위치 인식을 우아하게 구현하는 방법(IROS2023)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!