
타이핑보다 더 효과적으로 대형 모델의 사진을 살펴보자! NeurIPS 2023의 새로운 연구에서는 다중 모드 쿼리 방법을 제안하여 정확도를 7.8% 높였습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-10-23 11:45:09814검색
대형모델의 '이미지 인식' 능력은 이렇게 강한데, 왜 아직도 엉뚱한 것을 찾고 있는 걸까요?
예를 들어, 박쥐와 닮지 않은 박쥐를 혼동하거나 일부 데이터 세트에서 희귀한 물고기를 인식하지 못하는 경우...
대형 모델에 "물건 찾기"를 요청할 때 종종 입력하는 것은 텍스트.
"박쥐" (박쥐 또는 박쥐?) 또는 "악마" (Cyprinodon diabolis) 과 같이 설명이 모호하거나 너무 편향된 경우 AI는 크게 혼란스러워질 것입니다.
이로 인해 대형 모델을 사용하여 표적 탐지, 특히 오픈 월드 (알 수 없는 장면)표적 탐지 작업을 수행할 때 결과가 예상만큼 좋지 않은 경우가 많습니다.
이제 NeurIPS 2023에 포함된 논문이 마침내 이 문제를 해결했습니다.

논문에서는 다중 모달 쿼리MQ-Det를 기반으로 한 대상 탐지 방법을 제안합니다. 입력에 이미지 예제를 추가하기만 하면 대규모 모델에서 항목을 찾는 정확도가 크게 향상될 수 있습니다.
벤치마크 감지 데이터 세트 LVIS에서 다운스트림 작업 모델 미세 조정이 필요 없이 MQ-Det은 평균적으로 주류 감지 대형 모델 GLIP의 정확도를 13 벤치마크에서 약 7.8% 향상시킵니다. 작은 샘플 다운스트림 작업의 경우 평균 개선은 6.3%정확도입니다.
이 작업은 어떻게 이루어지나요? 와서 보자.
다음 내용은 논문 작성자이자 Zhihu 블로거 @沁园夏가 재현한 내용입니다.
목차
- MQ-Det: 다중 모드 쿼리를 위한 대규모 개방형 대상 탐지 모델
- 1.1 텍스트 쿼리에서 멀티모달 Stateful 쿼리로
- 1.2 MQ-Det 플러그 앤 플레이 멀티모달 쿼리 모델 아키텍처
- 1.3 MQ-Det 효율적인 학습 전략
- 1.4 실험 결과: 미세 조정이 필요 없는 평가
- 1.5 실험 결과: Few-shot 평가
- 1.6 다중 모드 쿼리 객체 감지의 전망
MQ-Det: 다중 모드 쿼리를 위한 대규모 개방형 객체 감지 모델
논문명: 다중 모드 쿼리 객체 감지 in the Wild
문서 링크: https://www.php.cn/link/9c6947bd95ae487c81d4e19d3ed8cd6f
코드 주소: https://www.php.cn/link/2307ac1cfee5db3a54 02aac9db25cc5d

1.1 텍스트 쿼리에서 다중 양식 쿼리로
사진은 천 단어의 가치가 있습니다: 이미지와 텍스트 사전 훈련의 증가로 텍스트의 개방형 의미론을 통해 대상 탐지가 점차 개방형 단계에 들어갔습니다. 세계 인식. 이를 위해 많은 대규모 탐지 모델은 범주형 텍스트 설명을 사용하여 대상 이미지의 잠재적인 대상을 쿼리하는 텍스트 쿼리 패턴을 따릅니다. 그러나 이러한 접근 방식은 “광범위하지만 정확하지 않다”는 문제에 직면하는 경우가 많습니다.
예를 들어, (1) 세립 개체 (어종) 감지 그림 1에서는 제한된 텍스트로 다양한 세립 어종을 설명하기 어려운 경우가 많으며, (2) 카테고리 모호성 ("박쥐" 둘 다) 배트와 라켓을 모두 지칭할 수 있습니다).
그러나 위의 문제는 이미지 예시를 통해 해결될 수 있습니다. 텍스트에 비해 이미지는 대상 개체에 대한 더 풍부한 기능 단서를 제공할 수 있지만 동시에 텍스트는 강력한 일반화를 제공합니다.
이렇게 두 쿼리 방식을 유기적으로 결합하는 방법은 자연스러운 아이디어가 되었습니다.
다중 모드 쿼리 기능을 얻는 데 어려움: 다중 모드 쿼리로 이러한 모델을 얻는 방법에는 세 가지 과제가 있습니다. (1) 제한된 이미지 예제를 사용한 직접 미세 조정은 쉽게 치명적인 망각으로 이어질 수 있습니다. ) ) 대규모 감지 모델을 처음부터 훈련하면 일반화가 더 잘되지만 많은 비용이 소모됩니다. 예를 들어 단일 카드로 GLIP을 훈련하려면 480일 동안 3천만 개의 데이터 볼륨을 훈련해야 합니다.
다중 모드 쿼리 대상 탐지: 위 고려 사항을 바탕으로 저자는 간단하고 효과적인 모델 설계 및 훈련 전략인 MQ-Det를 제안합니다.
MQ-Det은 기존의 대형 고정 텍스트 쿼리 감지 모델을 기반으로 소수의 게이트 인식 모듈(GCP)을 삽입하여 시각적 예제로부터 입력을 받는 동시에 시각적 조건 마스크 언어 예측을 설계합니다. 성능 다중 모드 쿼리를 위한 높은 A 검출기를 효율적으로 얻기 위한 훈련 전략입니다.
1.2 MQ-Det 플러그 앤 플레이 멀티 모달 쿼리 모델 아키텍처
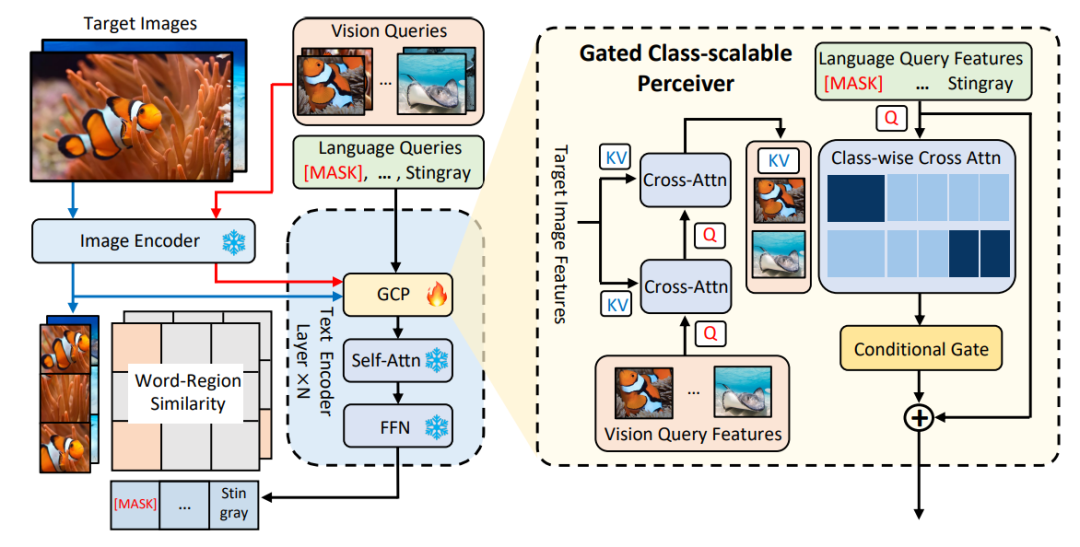
Δ그림 1 MQ-Det 방법 아키텍처 다이어그램
Gated Sensing Module
그림 1에서 볼 수 있듯이 저자는 텍스트를 가지고 있습니다. 고정된 텍스트 쿼리 감지 대형 모델의 인코더 끝은 게이트 인식 모듈 (GCP) 에 레이어별로 삽입됩니다. GCP의 작업 모드는 다음 공식으로 간결하게 표현될 수 있습니다.
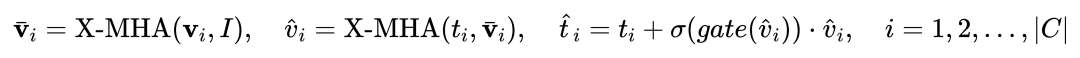
i번째의 경우 카테고리, 입력 시각적 예시 Vi는 먼저 표현 능력을 향상시키기 위해 획득 대상 이미지 I와 교차 주의 (X-MHA) 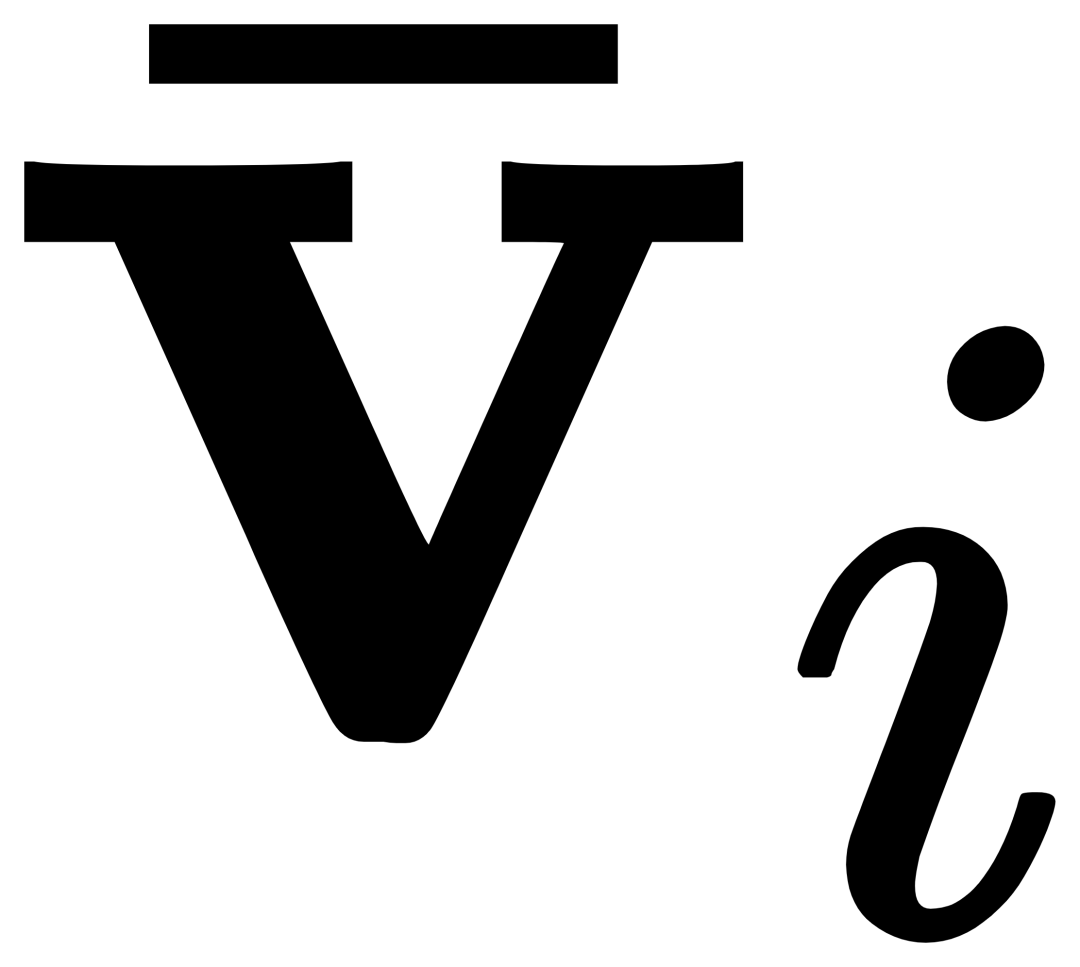 를 수행한 다음, 각 카테고리 텍스트 ti는 해당하는 시각적 예시
를 수행한 다음, 각 카테고리 텍스트 ti는 해당하는 시각적 예시 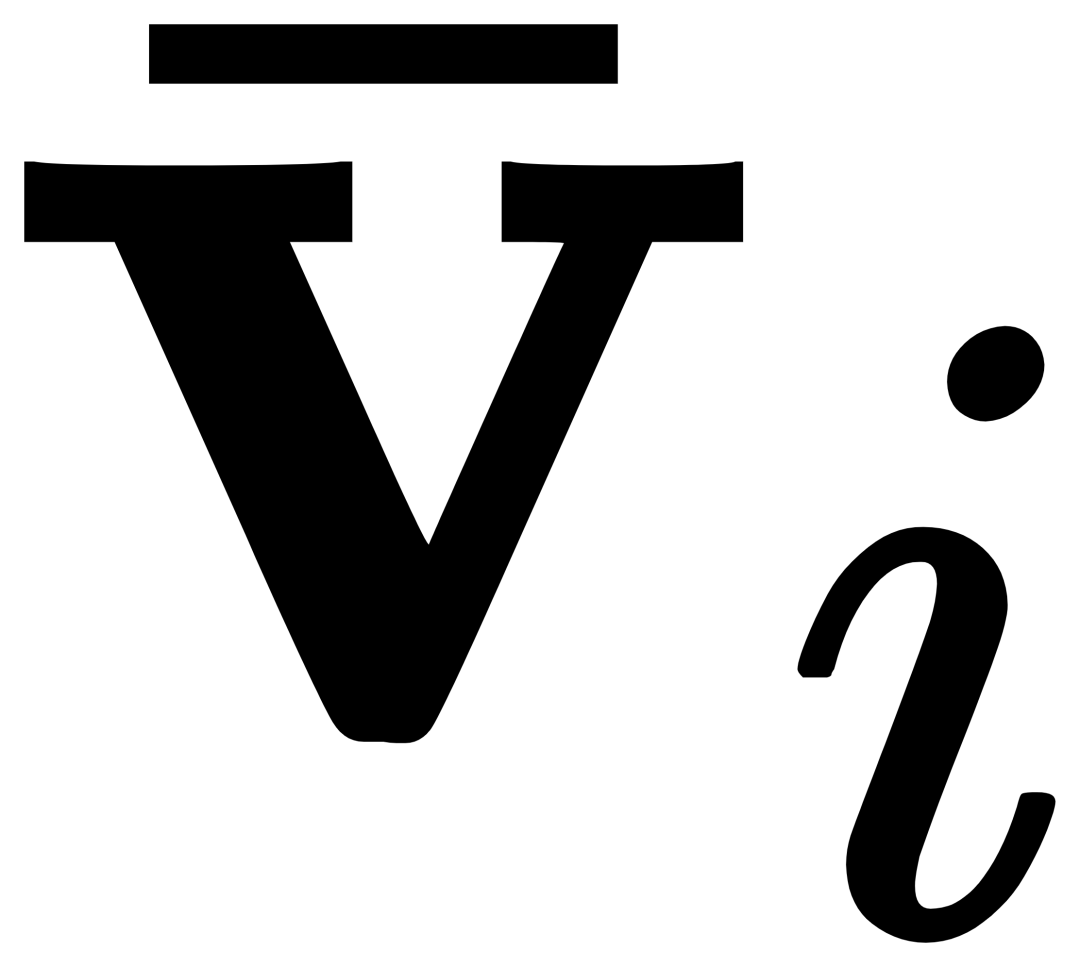 와 교차 주의를 수행합니다. 범주를 획득하여
와 교차 주의를 수행합니다. 범주를 획득하여 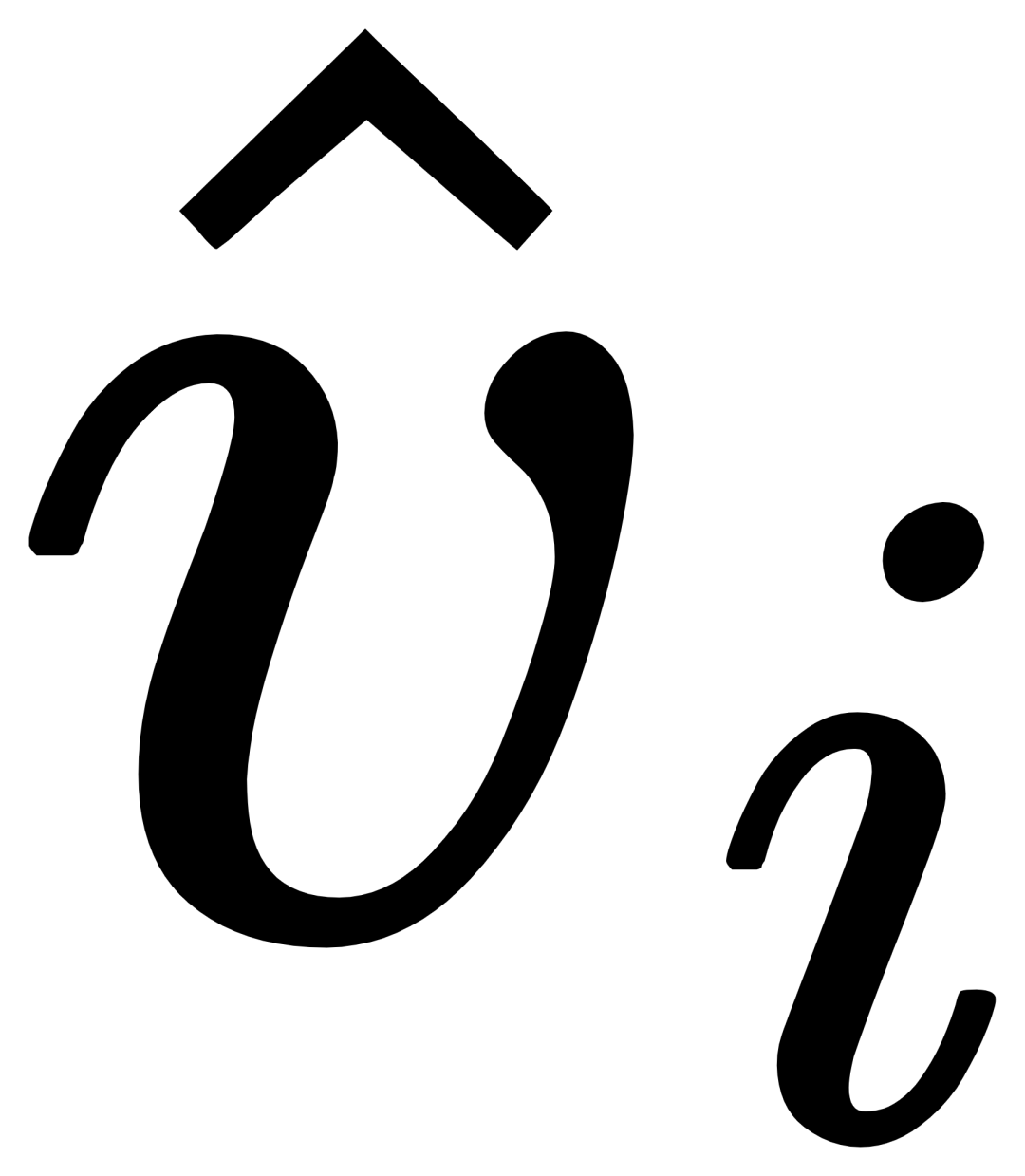 을 얻은 다음 게이팅 모듈 게이트를 통해 원본 텍스트 ti와 시각적으로 증강된 텍스트
을 얻은 다음 게이팅 모듈 게이트를 통해 원본 텍스트 ti와 시각적으로 증강된 텍스트 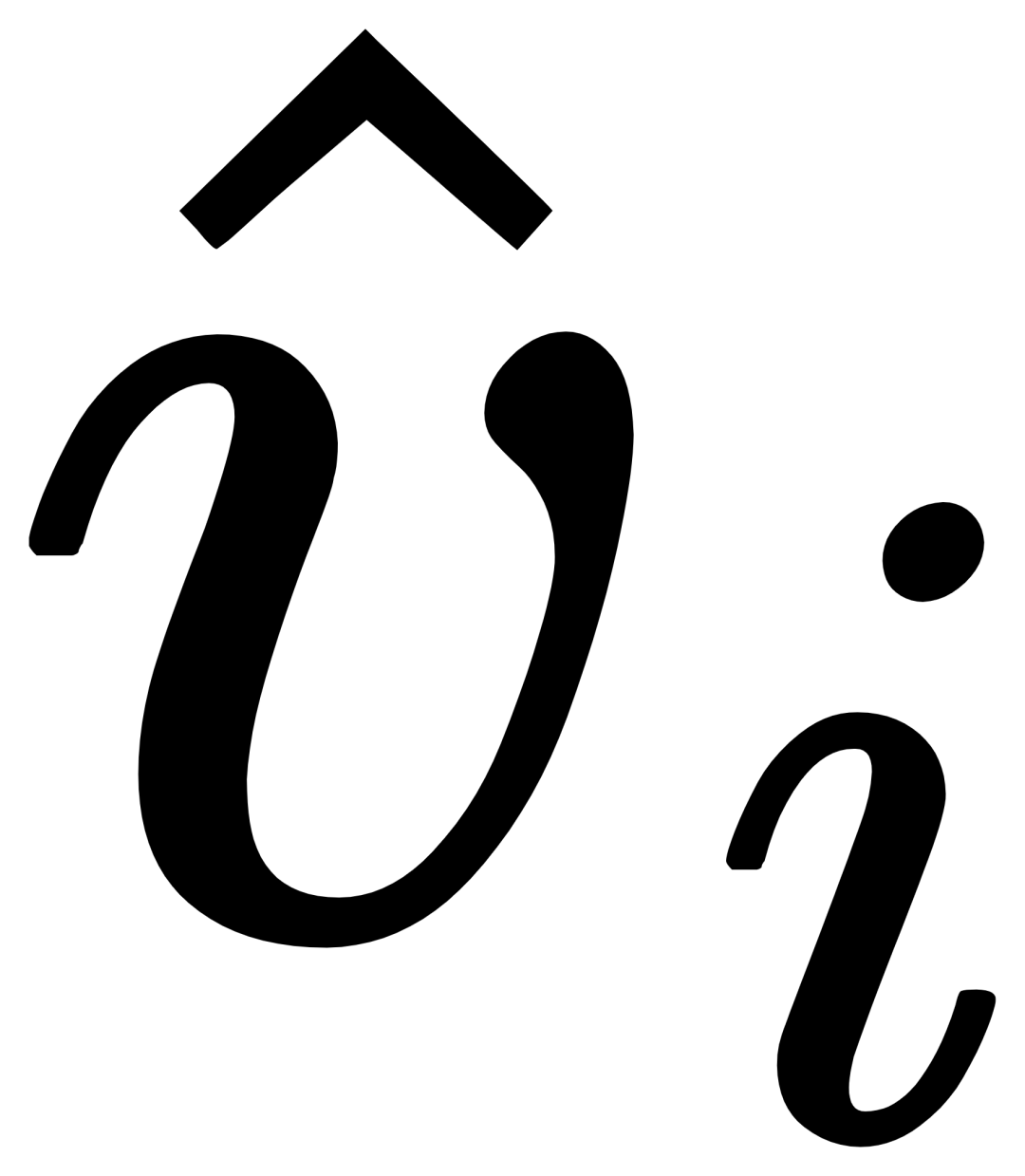 를 융합하여 현재 레이어의 출력
를 융합하여 현재 레이어의 출력 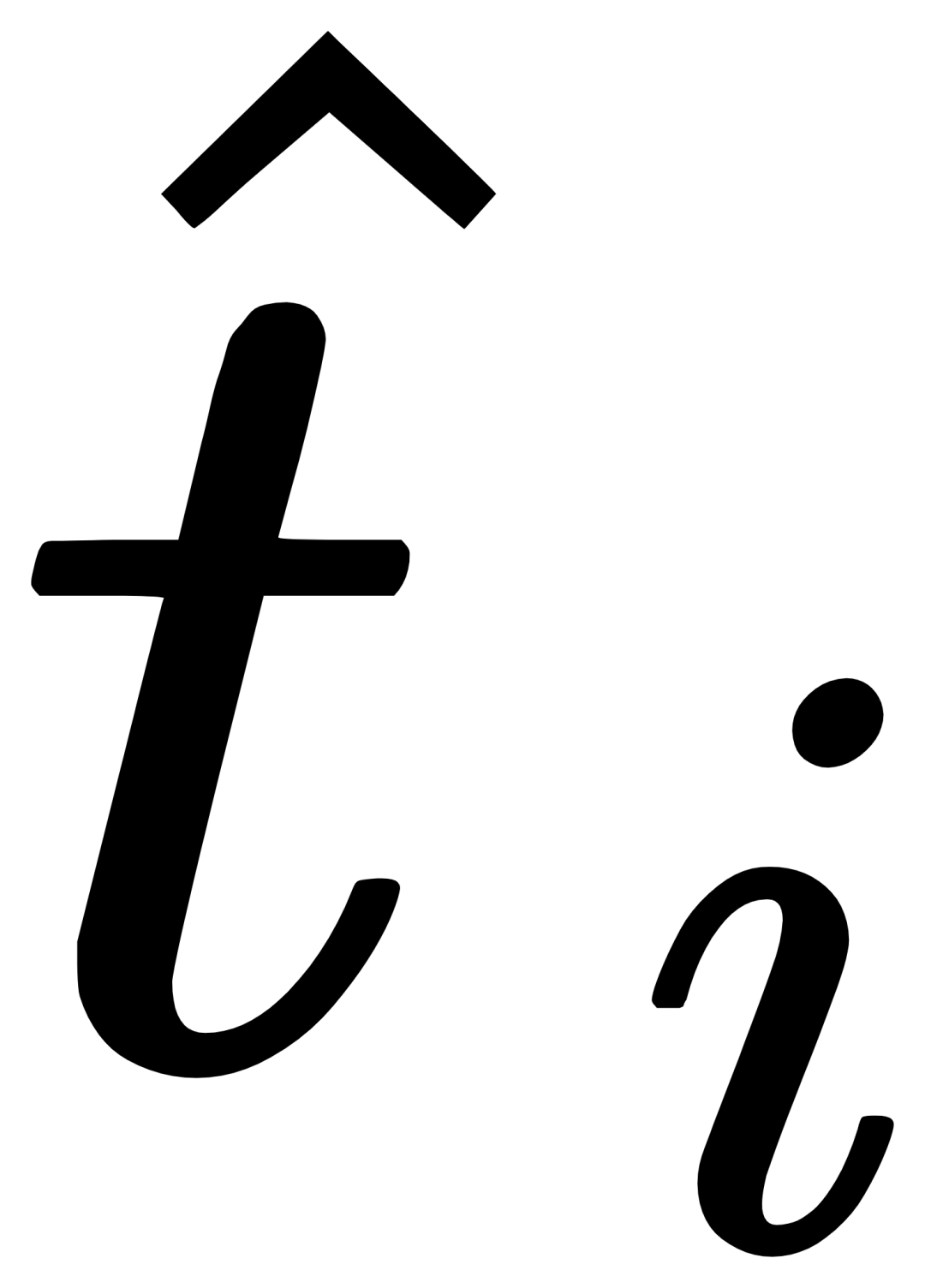 을 얻습니다. 이러한 단순한 디자인은 세 가지 원칙을 따릅니다: (1) 범주 확장성, (2) 의미 완성, (3) 망각 방지.
을 얻습니다. 이러한 단순한 디자인은 세 가지 원칙을 따릅니다: (1) 범주 확장성, (2) 의미 완성, (3) 망각 방지.
1.3 MQ-Det 효율적인 훈련 전략
고정 언어 쿼리 탐지기 기반 변조 훈련
현재의 대규모 사전 훈련된 텍스트 쿼리 탐지 모델 자체는 일반화가 좋기 때문에 논문 저자는 Just make만이 가능하다고 믿습니다. 원본 텍스트 기능을 기반으로 시각적 세부 사항을 약간 조정했습니다.
원래 사전 훈련된 모델 매개변수를 연 후 미세 조정하면 쉽게 치명적인 망각 문제로 이어질 수 있으며 대신 열린 세계를 감지하는 능력을 상실한다는 사실을 발견한 기사에는 구체적인 실험 시연도 있습니다.
따라서 MQ-Det은 미리 훈련된 고정 텍스트 쿼리 탐지기를 기반으로 훈련된 GCP 모듈만 변조함으로써 기존 텍스트 쿼리 탐지기에 시각적 정보를 효율적으로 삽입할 수 있습니다.
논문에서 저자는 MQ-Det의 구조 설계 및 훈련 기술을 현재 SOTA 모델인 GLIP 및 GroundingDINO에 각각 적용하여 방법의 다양성을 검증했습니다.
비전 조건 마스크 언어 예측 훈련 전략
저자는 사전 훈련된 모델 동결로 인한 학습 관성 문제를 해결하기 위해 비전 조건 마스크 언어 예측 훈련 전략도 제안했습니다.
소위 학습 관성이란 탐지기가 훈련 과정 중에 원본 텍스트 쿼리의 기능을 유지하는 경향이 있어 새로 추가된 시각적 쿼리 기능을 무시한다는 의미입니다.
이를 위해 MQ-Det은 훈련 중에 텍스트 토큰을 [MASK] 토큰으로 무작위로 대체하여 모델이 시각적 쿼리 기능 측면에서 학습하도록 합니다. 즉,
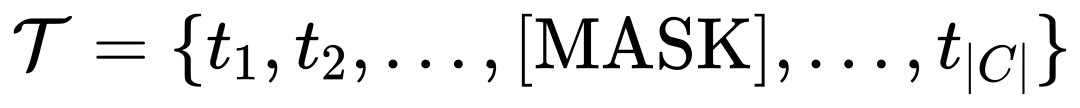
이 전략은 간단하지만 매우 효과적입니다. 실험 결과에 따르면 이 전략은 상당한 성능 향상을 가져오는 것으로 나타났습니다.
1.4 실험 결과: Finetuning-free 평가
Finetuning-free: 테스트를 위해 카테고리 텍스트만 사용하는 기존의 제로샷 (zero-shot) 평가와 비교하여 MQ-Det은 보다 현실적인 평가 전략을 제안합니다. 미세 조정이 필요하지 않습니다. 이는 다음과 같이 정의됩니다. 다운스트림 미세 조정 없이 사용자는 카테고리 텍스트, 이미지 예제 또는 둘의 조합을 사용하여 객체 감지를 수행할 수 있습니다.
미세 조정이 없는 설정에서 MQ-Det은 각 범주에 대해 5개의 시각적 예를 선택하고 대상 탐지를 위해 범주 텍스트를 결합합니다. 그러나 다른 기존 모델은 시각적 쿼리를 지원하지 않으며 일반 텍스트 설명만 사용할 수 있습니다. 아래 표는 LVIS MiniVal 및 LVIS v1.0에 대한 탐지 결과를 보여줍니다. 다중 모드 쿼리의 도입으로 오픈 월드 대상 탐지 기능이 크게 향상되었음을 알 수 있습니다.
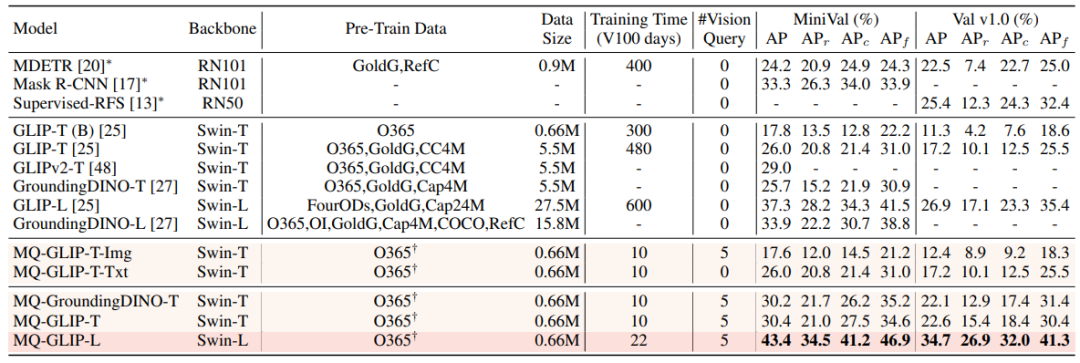
Δ표 1 LVIS 벤치마크 데이터 세트에서 각 탐지 모델의 미세 조정 없는 성능
표 1에서 볼 수 있듯이 MQ-GLIP-L은 GLIP-L을 기준으로 AP를 7% 이상 증가시켰습니다. , 효과가 매우 좋습니다!
1.5 실험 결과: Few-shot 평가
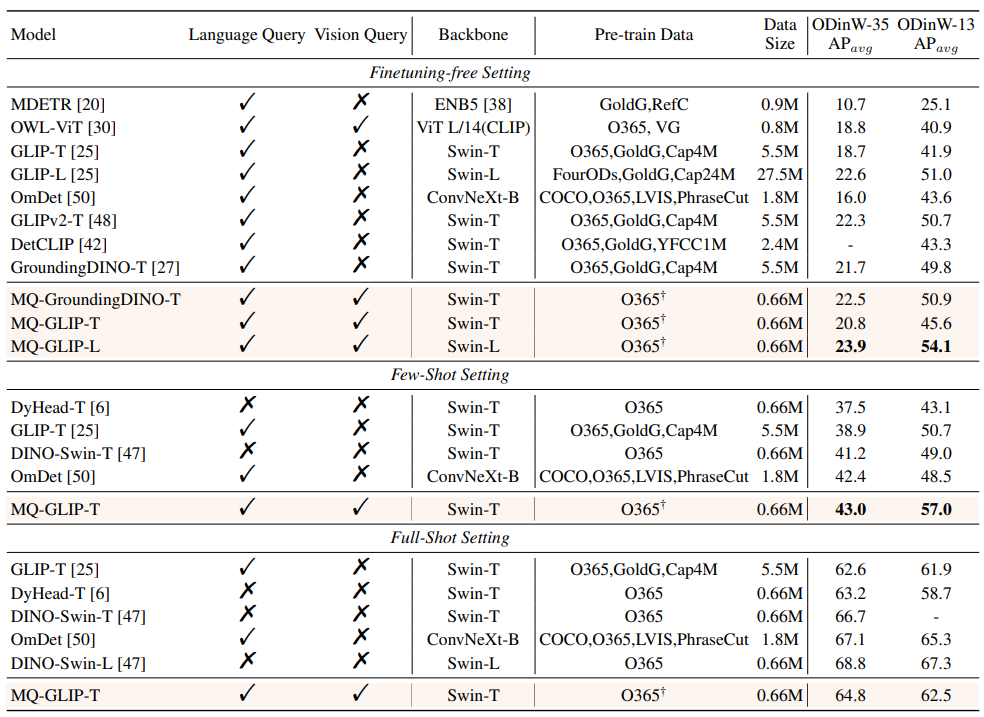
Δ표 2 35개 탐지 작업에서 각 모델의 성능 ODinW-35 및 13개 하위 집합 ODinW-13
저자는 또한 35개의 다운스트림 탐지 작업을 추가로 수행했습니다. 포괄적인 실험은 다음과 같습니다. ODinW-35에서 수행되었습니다. 표 2에서 볼 수 있듯이 MQ-Det은 미세 조정이 필요 없는 강력한 성능 외에도 우수한 소규모 샘플 감지 기능을 갖추고 있어 다중 모드 쿼리의 잠재력을 더욱 확인시켜 줍니다. 그림 2는 또한 GLIP에서 MQ-Det의 상당한 개선을 보여줍니다.
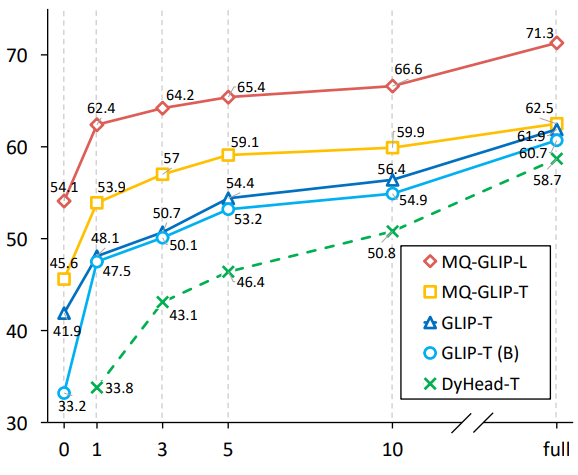
Δ그림 2 데이터 활용 효율성 비교 가로축: 훈련 샘플 수, 세로축: OdinW-13의 평균 AP
1.6 다중 모드 쿼리 대상 탐지의 전망
실용적인 대상 탐지 응용 기초 연구 분야로 알고리즘 구현을 매우 중요하게 생각합니다.
이전의 일반 텍스트 쿼리 대상 탐지 모델은 좋은 일반화를 보여주었지만 실제 오픈 월드 탐지에서는 텍스트가 세밀한 정보를 커버하기 어렵고 이미지의 풍부한 정보 입도가 이를 완벽하게 보완합니다.
지금까지 우리는 텍스트는 일반적이지만 정확하지 않고, 이미지는 정확하지만 일반적이지 않다는 것을 알 수 있습니다. 이 둘, 즉 다중 모드 쿼리를 효과적으로 결합할 수 있다면 오픈 월드 타겟 탐지가 더욱 발전할 것입니다.
MQ-Det은 다중 모드 쿼리의 첫 번째 단계를 밟았으며, 상당한 성능 개선은 다중 모드 쿼리 대상 탐지의 엄청난 잠재력을 보여줍니다.
동시에 텍스트 설명과 시각적 예시를 도입하여 사용자에게 더 많은 선택권을 제공하여 대상 탐지를 더욱 유연하고 사용자 친화적으로 만듭니다.
위 내용은 타이핑보다 더 효과적으로 대형 모델의 사진을 살펴보자! NeurIPS 2023의 새로운 연구에서는 다중 모드 쿼리 방법을 제안하여 정확도를 7.8% 높였습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!