


업데이트: Xinpu 시멘트 바닥을 주행하는 자율 주행 배달 차량이라는 새로운 예가 추가되었습니다.
많은 관심 속에서 GPT4는 마침내 오늘 비전 관련 기능을 출시했습니다. 오늘 오후에 친구들과 함께 GPT의 이미지 인식 기능을 빠르게 테스트했습니다. 기대는 했지만 여전히 큰 충격을 받았습니다. TL;DR은 자율주행에서 의미론적 문제가 대형 모델을 통해 잘 해결되었어야 한다고 생각하지만, 대형 모델의 신뢰성과 공간 인식 능력은 아직 만족스럽지 않습니다. 효율성과 관련된 소위 코너 케이스를 해결하는 것만으로도 충분하지만, 독립적인 주행을 완성하고 안전을 보장하기 위해 대형 모델에 전적으로 의존하는 것은 아직 멀었습니다.
1 예1: 도로에 알 수 없는 장애물이 나타났습니다


GPT4 설명
정확한 부분: 트럭 3대가 감지되었으며 앞트럭의 번호판 번호는 기본적으로 정확했습니다(무시됨) 한자)(바)가 있는 경우 날씨 및 환경이 정확함, 프롬프트 없이 전방의 알 수 없는 장애물을 정확하게 식별함
부정확한 부분: 세 번째 트럭의 위치가 왼쪽에서 오른쪽으로 구별되지 않고, 두 번째 트럭의 머리 위에 텍스트가 있음 는 추측입니다. (해상도가 부족해서?)
이것으로는 충분하지 않습니다. 이 개체가 무엇인지, 눌러도 되는지에 대한 약간의 힌트를 계속 제공합니다.

인상적이네요! 비슷한 시나리오를 여러 번 테스트했는데, 알 수 없는 장애물에 대한 성능이 매우 놀랍다고 할 수 있습니다.
2 예2: 도로 물 축적에 대한 이해

표지판을 자동으로 인식하는 프롬프트가 없습니다. 이것은 기본이어야 하며 계속해서 힌트를 제공합니다

또 충격을 받았습니다. . . 그는 자동으로 트럭 뒤의 안개를 알 수 있었고 웅덩이에 대해서도 언급했지만 다시 한 번 방향이 왼쪽이라고 말했습니다. . . GPT가 위치와 방향을 더 잘 출력할 수 있도록 하려면 여기에 몇 가지 즉각적인 엔지니어링이 필요할 수 있다고 생각합니다.
3 그래서 또 다른 프레임이 있습니다.
자동으로 말할 수 있습니다. 이 두 사람은 가드레일을 뚫고 도로 가장자리에 맴돌았습니다. . . 하지만 오히려 쉬워 보이던 도로 표지판이 틀렸습니다. . . 내가 말할 수 있는 것은 이것이 항상 당신에게 충격을 줄 것이며 언제 울게 될지 결코 알 수 없는 거대한 모델이라는 것입니다. . . 또 다른 프레임:


이에 비해 "누군가가 당신에게 손을 흔들었습니다"와 같은 경우는 이전에는 매우 어려워 보였으며 어린이 놀이와 같으며 의미론적 코너 케이스로 해결할 수 있습니다. 5
예제5 유명한 장면을 하나 보겠습니다. . . 새로 건설된 도로에 배달트럭이 실수로 진입했습니다

저는 처음에는 비교적 보수적이어서 직접적으로 추측하지는 않았습니다. 이는 정렬의 목표와 일치합니다. CoT를 사용해본 결과, 해당 차량이 자율주행차로 인식되지 않는 것이 문제인 것으로 확인되었으므로 이러한 정보를 프롬프트를 통해 제공하는 것이 보다 정확한 정보를 제공할 수 있습니다. 마지막으로, 여러 가지 프롬프트를 통해 새로 깔린 아스팔트가 운전에 적합하지 않다는 결론을 내릴 수 있습니다. 최종 결과는 여전히 괜찮지만 프로세스가 더 힘들고 더 신속한 엔지니어링과 신중한 설계가 필요합니다. 그 이유는 1인칭 시점의 사진이 아니고, 3인칭 시점에서만 추측이 가능하기 때문일 수도 있다. 따라서 이 예는 그다지 정확하지 않습니다.
6 요약
몇 가지 빠른 시도로 GPT4V의 성능과 일반화 성능이 완전히 입증되었습니다. 적절한 프롬프트는 GPT4V의 강점을 최대한 활용할 수 있어야 합니다. 의미론적 코너 사례를 해결하는 것은 매우 유망하지만 보안 관련 시나리오에서 환상 문제는 여전히 일부 애플리케이션을 괴롭힐 것입니다. 개인적으로 이런 대형 모델을 합리적으로 활용하면 L4, 심지어 L5 자율주행의 발전도 크게 가속화할 수 있다고 생각합니다. 그런데 LLM이 직접 운전을 해야 하나요? 특히 엔드투엔드 운전은 아직 논란의 여지가 있는 문제로 남아 있습니다. 요즘 고민이 많아서 시간을 내서 여러분과 이야기 나눌 수 있는 글을 쓰겠습니다~

원본 링크: https://mp.weixin.qq.com/s/RtEek6HadErxXLSdtsMWHQ
위 내용은 신나는! 자율주행에서의 GPT-4V 예비 연구의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

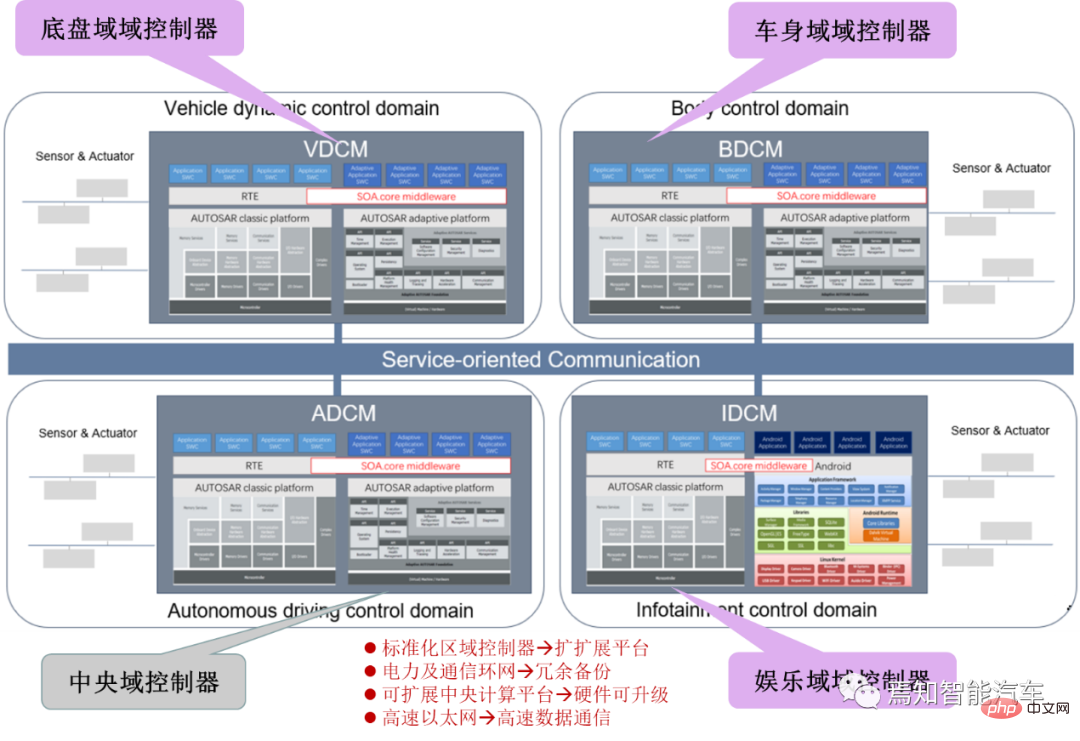 SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM
SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM对于下一代集中式电子电器架构而言,采用central+zonal 中央计算单元与区域控制器布局已经成为各主机厂或者tier1玩家的必争选项,关于中央计算单元的架构方式,有三种方式:分离SOC、硬件隔离、软件虚拟化。集中式中央计算单元将整合自动驾驶,智能座舱和车辆控制三大域的核心业务功能,标准化的区域控制器主要有三个职责:电力分配、数据服务、区域网关。因此,中央计算单元将会集成一个高吞吐量的以太网交换机。随着整车集成化的程度越来越高,越来越多ECU的功能将会慢慢的被吸收到区域控制器当中。而平台化
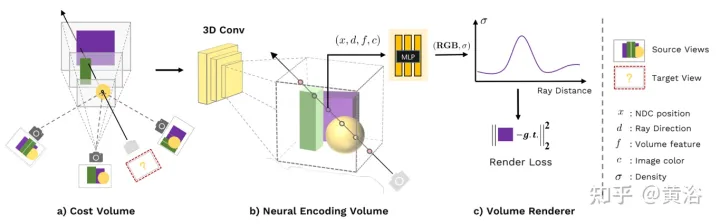 新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM
新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM新视角图像生成(NVS)是计算机视觉的一个应用领域,在1998年SuperBowl的比赛,CMU的RI曾展示过给定多摄像头立体视觉(MVS)的NVS,当时这个技术曾转让给美国一家体育电视台,但最终没有商业化;英国BBC广播公司为此做过研发投入,但是没有真正产品化。在基于图像渲染(IBR)领域,NVS应用有一个分支,即基于深度图像的渲染(DBIR)。另外,在2010年曾很火的3D TV,也是需要从单目视频中得到双目立体,但是由于技术的不成熟,最终没有流行起来。当时基于机器学习的方法已经开始研究,比
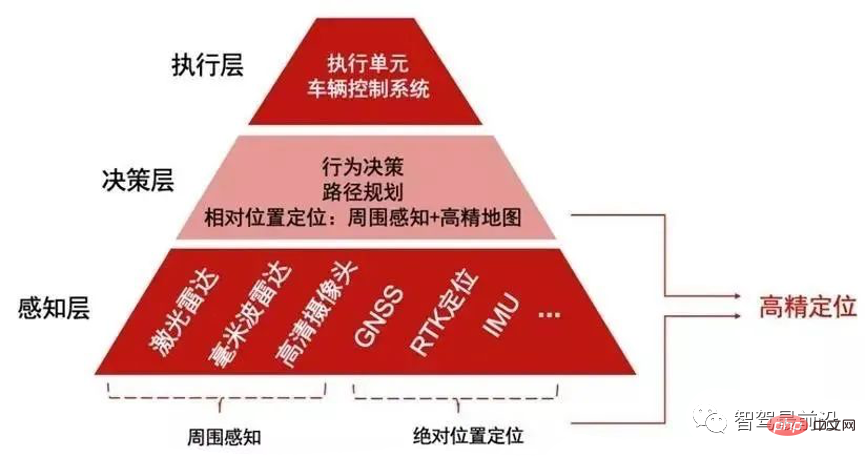 如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM
如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM与人类行走一样,自动驾驶汽车想要完成出行过程也需要有独立思考,可以对交通环境进行判断、决策的能力。随着高级辅助驾驶系统技术的提升,驾驶员驾驶汽车的安全性不断提高,驾驶员参与驾驶决策的程度也逐渐降低,自动驾驶离我们越来越近。自动驾驶汽车又称为无人驾驶车,其本质就是高智能机器人,可以仅需要驾驶员辅助或完全不需要驾驶员操作即可完成出行行为的高智能机器人。自动驾驶主要通过感知层、决策层及执行层来实现,作为自动化载具,自动驾驶汽车可以通过加装的雷达(毫米波雷达、激光雷达)、车载摄像头、全球导航卫星系统(G
 多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM
多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM我们经常可以看到蜜蜂、蚂蚁等各种动物忙碌地筑巢。经过自然选择,它们的工作效率高到叹为观止这些动物的分工合作能力已经「传给」了无人机,来自英国帝国理工学院的一项研究向我们展示了未来的方向,就像这样:无人机 3D 打灰:本周三,这一研究成果登上了《自然》封面。论文地址:https://www.nature.com/articles/s41586-022-04988-4为了展示无人机的能力,研究人员使用泡沫和一种特殊的轻质水泥材料,建造了高度从 0.18 米到 2.05 米不等的结构。与预想的原始蓝图
 超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM
超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM实时全局光照(Real-time GI)一直是计算机图形学的圣杯。多年来,业界也提出多种方法来解决这个问题。常用的方法包通过利用某些假设来约束问题域,比如静态几何,粗糙的场景表示或者追踪粗糙探针,以及在两者之间插值照明。在虚幻引擎中,全局光照和反射系统Lumen这一技术便是由Krzysztof Narkowicz和Daniel Wright一起创立的。目标是构建一个与前人不同的方案,能够实现统一照明,以及类似烘烤一样的照明质量。近期,在SIGGRAPH 2022上,Krzysztof Narko
 internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PM
internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PMinternet的基本结构与技术起源于ARPANET。ARPANET是计算机网络技术发展中的一个里程碑,它的研究成果对促进网络技术的发展起到了重要的作用,并未internet的形成奠定了基础。arpanet(阿帕网)为美国国防部高级研究计划署开发的世界上第一个运营的封包交换网络,它是全球互联网的始祖。
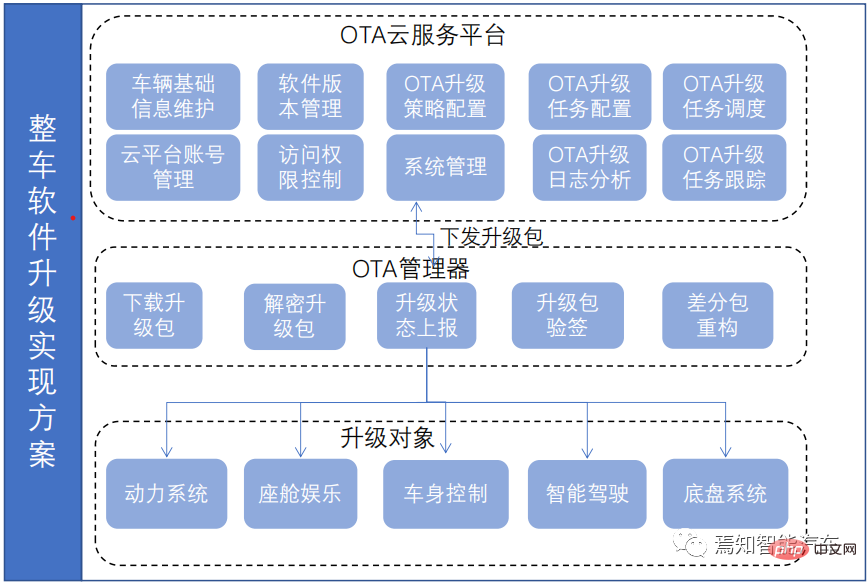 一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM
一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM由于智能汽车集中化趋势,导致在网络连接上已经由传统的低带宽Can网络升级转换到高带宽以太网网络为主的升级过程。为了提升车辆升级能力,基于为车主提供持续且优质的体验和服务,需要在现有系统基础(由原始只对车机上传统的 ECU 进行升级,转换到实现以太网增量升级的过程)之上开发一套可兼容现有 OTA 系统的全新 OTA 服务系统,实现对整车软件、固件、服务的 OTA 升级能力,从而最终提升用户的使用体验和服务体验。软件升级触及的两大领域-FOTA/SOTA整车软件升级是通过OTA技术,是对车载娱乐、导
 综述:自动驾驶的协同感知技术Apr 08, 2023 pm 03:01 PM
综述:自动驾驶的协同感知技术Apr 08, 2023 pm 03:01 PMarXiv综述论文“Collaborative Perception for Autonomous Driving: Current Status and Future Trend“,2022年8月23日,上海交大。感知是自主驾驶系统的关键模块之一,然而单车的有限能力造成感知性能提高的瓶颈。为了突破单个感知的限制,提出协同感知,使车辆能够共享信息,感知视线之外和视野以外的环境。本文回顾了很有前途的协同感知技术相关工作,包括基本概念、协同模式以及关键要素和应用。最后,讨论该研究领域的开放挑战和问题


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

드림위버 CS6
시각적 웹 개발 도구

Dreamweaver Mac版
시각적 웹 개발 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

