
언어, 로봇 파괴, MIT 등은 GPT-4를 사용하여 시뮬레이션 작업을 생성하고 이를 현실 세계로 마이그레이션합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-10-16 20:21:03984검색
콘텐츠를 다음과 같이 다시 작성했습니다: Machine Heart Report
편집자: Du Wei, Xiaozhou
GPT-4와 로봇이 새로운 불꽃을 일으켰습니다.

로봇 분야에서 보편적인 로봇 전략을 구현하려면 많은 양의 데이터가 필요하며, 현실 세계에서 이 데이터를 수집하는 것은 시간이 많이 걸리고 힘든 일입니다. 시뮬레이션은 장면 및 인스턴스 수준에서 다양한 양의 데이터를 생성하기 위한 경제적인 솔루션을 제공하지만, 시뮬레이션 환경에서 작업 다양성을 늘리는 것은 필요한 인력이 많이 필요하기 때문에(특히 복잡한 작업의 경우) 여전히 어려움에 직면해 있습니다. 이로 인해 일반적으로 수십에서 수백 개의 작업만 포함하는 일반적인 인공 시뮬레이션 벤치마크가 생성됩니다.
어떻게 해결하나요? 최근 몇 년 동안 대규모 언어 모델은 다양한 작업을 위한 자연어 처리 및 코드 생성 분야에서 계속해서 상당한 진전을 이루었습니다. 마찬가지로 LLM은 사용자 인터페이스, 작업 및 동작 계획, 로봇 로그 요약, 비용 및 보상 설계를 포함하여 로봇공학의 여러 측면에 적용되어 물리 기반 및 코드 생성 작업 모두에서 강력한 기능을 보여줍니다.
최근 연구에서 MIT CSAIL, Shanghai Jiao Tong University 및 기타 기관의 연구원들은 LLM을 사용하여 다양한 시뮬레이션 작업을 생성하고 그 기능을 더 탐구할 수 있는지 추가로 조사했습니다.
구체적으로 연구원들은 작업 자산 배열 및 작업 진행을 설계하고 확인하기 위한 자동화된 메커니즘을 제공하는 LLM인 GenSim을 기반으로 하는 프레임워크를 제안했습니다. 더 중요한 것은 생성된 작업이 매우 다양하여 로봇 전략의 작업 수준 일반화를 촉진한다는 것입니다. 또한 개념적으로 GenSim을 사용하면 LLM의 추론 및 인코딩 기능이 시뮬레이션 데이터의 중간 합성을 통해 언어-시각-행동 전략으로 정제됩니다.

다시 작성해야 할 내용은 다음과 같습니다. 논문 링크:
https://arxiv.org/pdf/2310.01361.pdf
GenSim 프레임워크는 다음 세 부분으로 구성됩니다.
- 첫 번째는 자연어 명령과 해당 코드에 의해 구현된 프롬프트 메커니즘을 통해 새로운 작업을 제안하는 것입니다.
- 두 번째는 검증 및 언어 모델 미세 조정을 위해 이전에 생성된 고품질 명령 코드를 캐시하고 이를 포괄적인 작업 데이터 세트로 반환하는 작업 라이브러리입니다. 마지막으로, 언어적응 다중업무 정책 훈련 프로세스는 생성된 데이터를 활용하여 업무 수준의 일반화 능력을 향상시킵니다.
아래 그림 1에서 연구원은 수동으로 선별된 10개의 작업이 포함된 작업 라이브러리를 초기화하고 GenSim을 사용하여 이를 확장하고 100개 이상의 작업을 생성했습니다.

그뿐만 아니라 연구원들은 다중 작업 로봇 전략도 훈련했는데, 이는 모든 생성 작업에 대해 잘 일반화되었으며 인간 계획 작업에만 훈련된 모델에 비해 제로 샷 일반화 성능이 향상되었습니다. GPT-4 세대 작업과의 공동 훈련은 일반화 성능을 50% 향상시키고 제로샷 작업의 약 40%를 시뮬레이션의 새로운 작업으로 전환합니다.
마지막으로 연구원들은 시뮬레이션에서 실제로의 전환도 고려하여 다양한 시뮬레이션 작업에 대한 사전 훈련이 실제 일반화 능력을 25% 향상시킬 수 있음을 보여주었습니다.
요약하자면, 다양한 LLM 생성 작업에 대해 교육된 정책은 새로운 작업에 대한 작업 수준 일반화를 향상시켜 LLM을 통해 시뮬레이션된 작업을 확장하여 기본 정책을 교육할 수 있는 가능성을 강조합니다.
Tenstorrent AI의 제품 관리 이사인 Shubham Saboo는 이 연구를 로봇과 결합한 GPT-4에 대한 획기적인 연구라고 말했습니다. 자동 조종 장치에서 일련의 시뮬레이션된 로봇 작업이 GPT-4와 같은 LLM을 통해 생성됩니다. 4. 제로샷 학습과 로봇의 실제 적응을 현실화합니다.

방법 소개
아래 그림 2와 같이 GenSim 프레임워크는 프로그램 합성을 통해 시뮬레이션 환경, 작업 및 데모를 생성합니다. GenSim 파이프라인은 작업 생성자에서 시작되며 프롬프트 체인은 대상 작업에 따라 목표 지향 모드와 탐색 모드의 두 가지 모드로 실행됩니다. GenSim의 작업 라이브러리는 이전에 생성된 고품질 작업을 저장하는 데 사용되는 인메모리 구성 요소입니다. 작업 라이브러리에 저장된 작업은 다중 작업 정책 교육 또는 LLM 미세 조정에 사용될 수 있습니다.
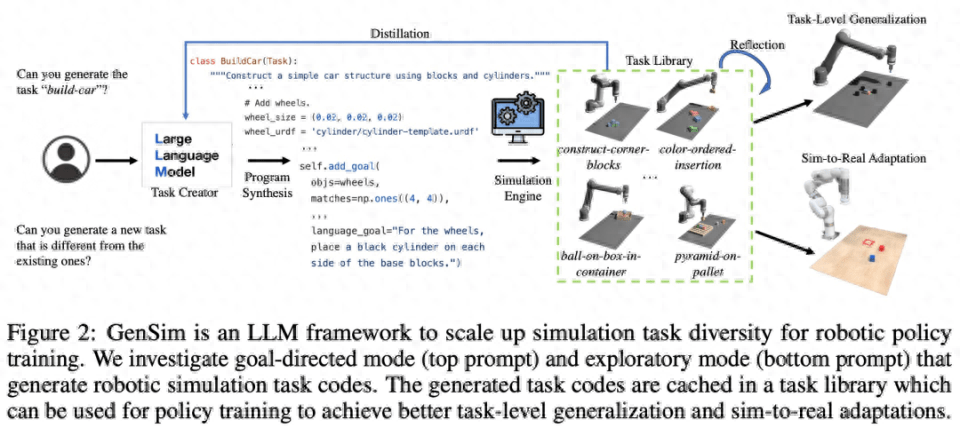
작업 생성기
아래 그림 3과 같이 언어 체인은 먼저 작업 설명을 생성한 다음 관련 구현을 생성합니다. 작업 설명에는 작업 이름, 리소스 및 작업 요약이 포함됩니다. 이 연구에서는 파이프라인에서 몇 가지 샘플 프롬프트를 사용하여 코드를 생성합니다.
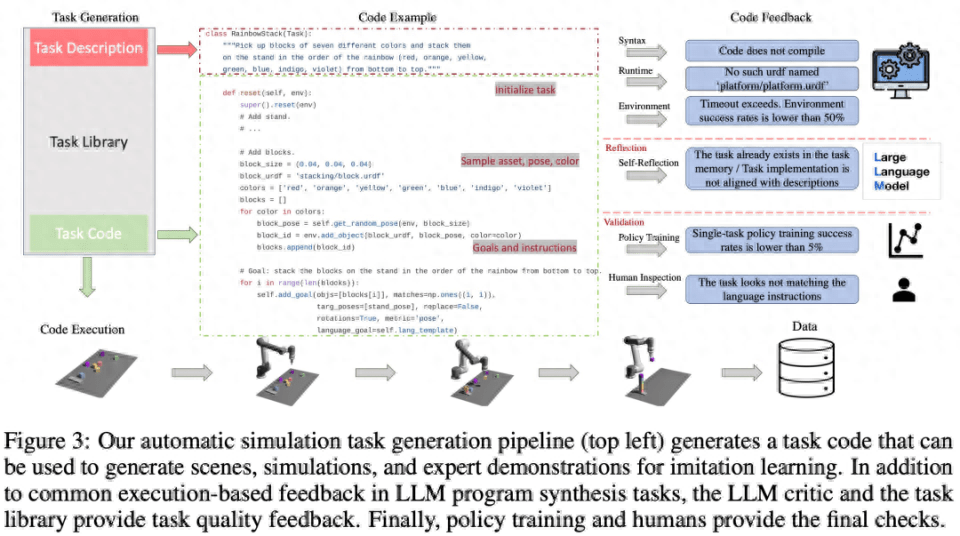
작업 라이브러리
GenSim 프레임워크의 작업 라이브러리는 더 나은 새 작업을 생성하고 다중 작업 전략을 훈련하기 위해 작업 생성자가 생성한 작업을 저장합니다. 작업 라이브러리는 수동으로 생성된 벤치마크의 작업을 기반으로 초기화됩니다.
작업 라이브러리는 설명 생성 단계의 조건으로 작업 생성자에게 이전 작업 설명을 제공하고, 코드 생성 단계를 위한 이전 코드를 제공하며, 작업 생성자에게 작업 라이브러리에서 참조 작업을 샘플로 선택하도록 요청합니다. 새로운 작업을 작성합니다. 작업 구현이 완료되고 모든 테스트가 통과된 후 LLM은 새 작업 및 작업 라이브러리를 "반영"하고 새로 생성된 작업을 라이브러리에 추가해야 하는지 여부에 대한 포괄적인 결정을 내리라는 메시지를 받습니다.
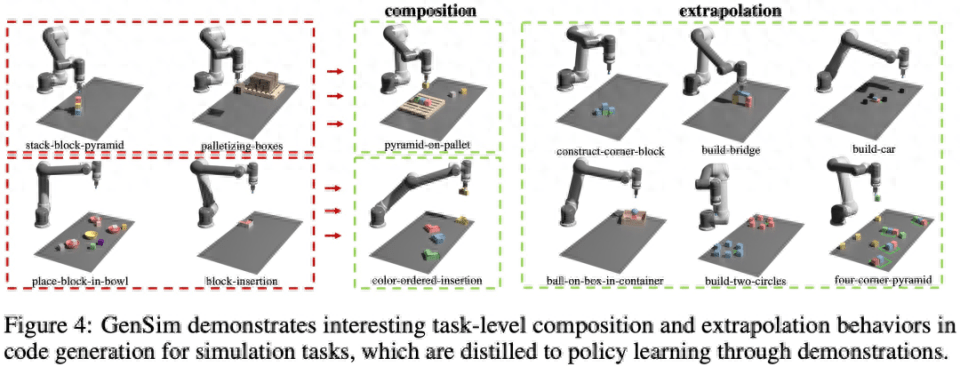
아래 그림 4에서 볼 수 있듯이 연구에서는 GenSim이 흥미로운 작업 수준 조합 및 추정 동작을 보이는 것으로 관찰되었습니다.
LLM 감독형 다중 작업 전략
작업을 생성한 후 이 연구에서는 Shridhar et al.(2022)과 유사한 이중 스트림 전송 네트워크 아키텍처를 사용하여 이러한 작업 구현을 사용하여 데모 데이터를 생성하고 운영 정책을 교육합니다.
아래 그림 5에서 볼 수 있듯이 본 연구에서는 프로그램을 작업 및 관련 데모 데이터의 효과적인 표현으로 간주합니다(그림 5). 작업 간의 임베딩 공간 정의가 가능하며 거리 지수는 작업과 관련된 다양한 요소에 민감합니다. 인식(예: 물체의 자세 및 모양)이 더욱 강력해졌습니다.

내용을 다시 작성하려면 원문의 언어를 중국어로 다시 작성해야 하며, 원문이 나올 필요는 없습니다
이 연구는 실험을 통해 GenSim 프레임워크를 검증하고 다음과 같은 구체적인 질문을 다룹니다. (1) 시뮬레이션 작업을 설계하고 구현하는 데 LLM이 얼마나 효과적인가요? GenSim이 작업 생성에서 LLM의 성능을 향상시킬 수 있습니까? (2) LLM에서 생성된 업무에 대한 교육이 정책 일반화 능력을 향상시킬 수 있습니까? 더 많은 생성 작업이 주어지면 정책 교육에 더 많은 이점이 있습니까? (3) LLM 생성 시뮬레이션 작업에 대한 사전 교육이 실제 로봇 정책 배포에 도움이 됩니까?
LLM 로봇 시뮬레이션 작업의 일반화 능력을 평가합니다
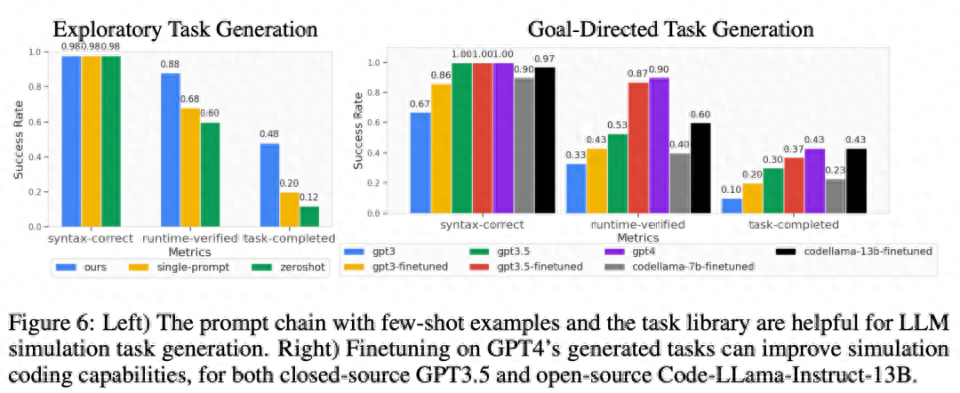
아래 그림 6과 같이 탐색 모드와 목표 지향 모드 작업 생성의 경우 소수의 샘플과 작업 라이브러리로 구성된 2단계 프롬프트 체인이 코드 생성 성공률을 효과적으로 향상시킬 수 있습니다.
작업 수준 일반화
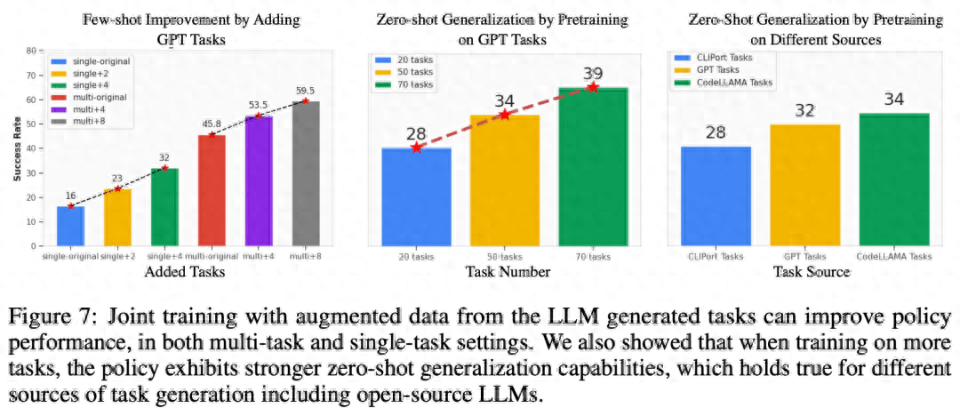
관련 업무에 대한 퓨샷 전략 최적화. 아래 그림 7의 왼쪽에서 볼 수 있듯이 LLM에서 생성된 작업을 공동으로 교육하면 특히 데이터가 적은 상황(예: 데모 5개)에서 원래 CLIPort 작업에 대한 정책 성능을 50% 이상 향상할 수 있습니다.
보이지 않는 작업에 대한 제로샷 정책 일반화. 그림 7에서 볼 수 있듯이 LLM에서 생성된 더 많은 작업에 대한 사전 학습을 통해 모델은 원래 Ravens 벤치마크의 작업에 더 잘 일반화할 수 있습니다. 그림 7의 오른쪽 중간에서 연구원들은 수동으로 작성된 작업, 폐쇄 소스 LLM 및 오픈 소스 미세 조정 LLM을 포함하여 다양한 작업 소스에 대한 5가지 작업에 대해 사전 교육을 받았고 유사한 제로샷 작업 수준을 관찰했습니다. 일반화.
사전 훈련된 모델을 현실 세계에 적용
연구원들은 시뮬레이션 환경에서 훈련된 전략을 실제 환경으로 옮겼습니다. 결과는 아래 표 1에 나와 있습니다. GPT-4 생성 작업 70개에 대해 사전 훈련된 모델은 9개 작업에 대해 10번의 실험을 수행했으며 평균 68.8%의 성공률을 달성했습니다. 이는 CLIPort 작업만 사전 훈련한 것보다 좋습니다. 기본 모델과 비교하면 25% 이상 향상되었으며, 50개 작업만 사전 학습한 모델과 비교하면 15% 향상되었습니다.
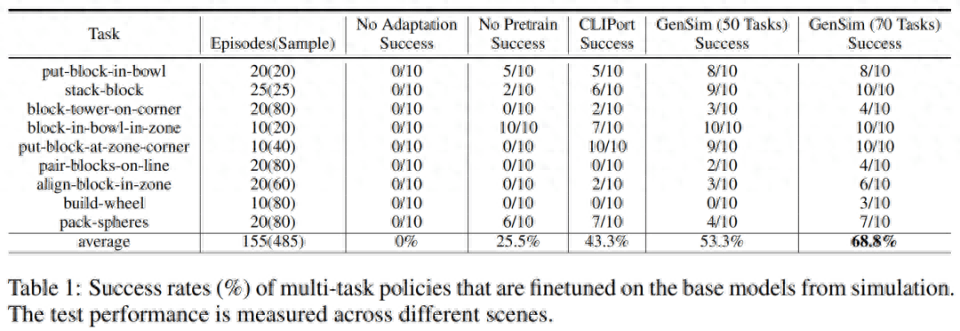
연구원들은 또한 다양한 시뮬레이션 작업에 대한 사전 교육이 장기적으로 복잡한 작업의 견고성을 향상시키는 것을 관찰했습니다. 예를 들어, GPT-4 사전 훈련된 모델은 실제 빌드휠 작업에서 더욱 강력한 성능을 보여줍니다.

절제 실험
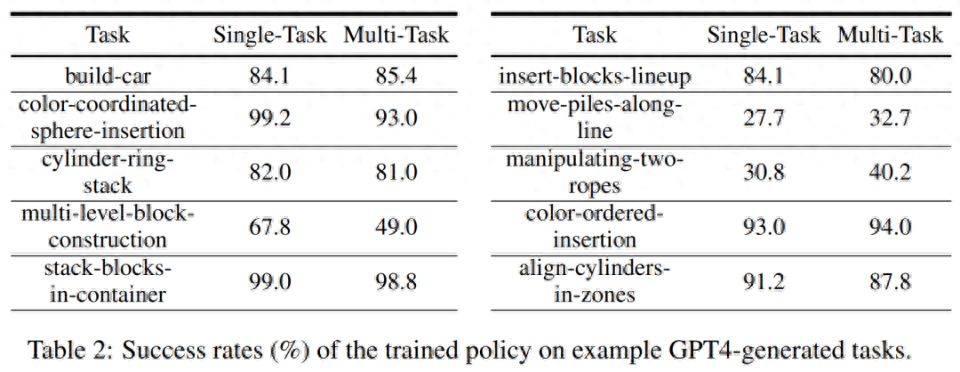
시뮬레이션 훈련 성공률. 아래 표 2에서 연구원들은 200개의 데모를 통해 생성된 작업의 하위 집합에 대한 단일 작업 및 다중 작업 정책 교육의 성공률을 보여줍니다. GPT-4 세대 과제에 대한 정책훈련의 평균 과제 성공률은 단일 과제 75.8%, 다중 과제 74.1%이다.
작업 통계를 생성합니다. 아래 그림 9 (a)에서 연구원은 LLM에서 생성된 120개 작업의 다양한 기능에 대한 작업 통계를 보여줍니다. LLM 모델에서 생성된 색상, 자산, 작업 및 인스턴스 수 사이에는 흥미로운 균형이 있습니다. 예를 들어, 생성된 코드에는 7개 이상의 개체 인스턴스가 포함된 장면이 많이 포함되어 있을 뿐만 아니라 선택 및 배치 기본 동작과 블록과 같은 자산도 많이 포함되어 있습니다.
코드 생성 비교에서 연구진은 아래 그림 9(b)에서 GPT-4와 Code Llama의 하향식 실험에서 실패 사례를 정성적으로 평가했습니다

자세한 기술적인 내용은 원본 논문을 참고해주세요.
위 내용은 언어, 로봇 파괴, MIT 등은 GPT-4를 사용하여 시뮬레이션 작업을 생성하고 이를 현실 세계로 마이그레이션합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!