
GPT-3.5 또는 Jordan Llama 2 및 기타 오픈 소스 모델을 선택하시겠습니까? 종합적으로 비교해보면 답은 이렇습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-10-16 18:45:05622검색
다양한 작업에서 GPT-3.5와 Llama 2의 매개변수를 비교함으로써 어떤 상황에서 GPT-3.5를 선택하고 어떤 상황에서 Llama 2 또는 다른 모델을 선택하는지 알 수 있습니다.
분명히 GPT-3.5 토크는 매우 비쌉니다. 본 논문에서는 수동 토크 모델이 GPT-3.5 비용의 일부만으로 GPT-3.5 성능에 접근할 수 있는지 여부를 실험적으로 검증합니다. 흥미롭게도 그 신문은 그랬습니다.
SQL 작업과 함수 표현 작업의 결과를 비교한 결과, 논문에서는 다음과 같은 사실을 발견했습니다.
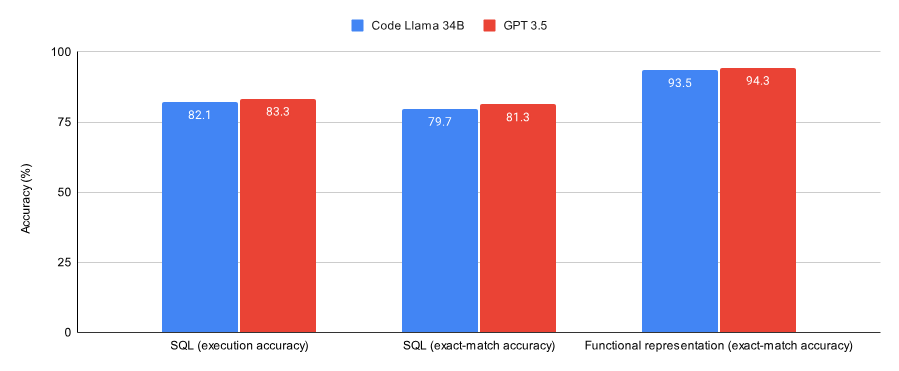
GPT-3.5가 두 데이터 세트(Spider 데이터 세트의 하위 세트 및 Viggo 함수 표현 데이터 세트의 하위 세트)에서 Lora 이후의 코드보다 우수합니다. ) Llama 34B의 성능이 약간 더 좋았습니다.
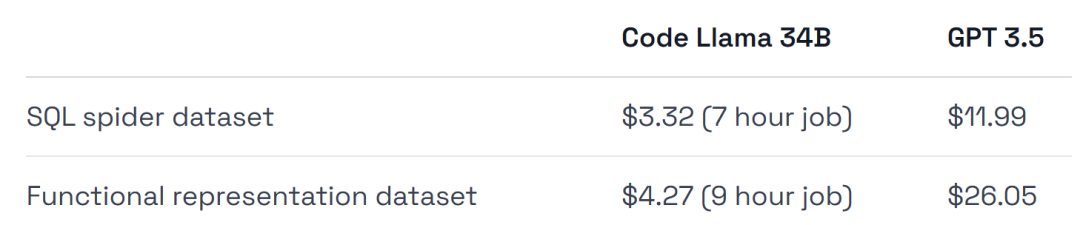
GPT-3.5의 교육 비용은 4~6배 더 높으며 배포 비용도 더 높습니다.
이 실험의 결론 중 하나는 초기 검증 작업에는 GPT-3.5가 적합하지만 이후에는 Llama 2와 같은 모델이 최선의 선택이 될 수 있다는 것입니다. 간단히 요약하자면:
검증을 원하는 경우 특정 작업/데이터 세트에 대한 올바른 접근 방식을 해결하거나 완전 관리형 환경을 원하는 경우 GPT-3.5를 조정하세요.
비용을 절약하고, 데이터 세트에서 최대 성능을 얻고, 인프라 교육 및 배포에 더 많은 유연성을 갖고, 일부 데이터를 원하거나 유지하고 싶다면 Llama 2 오픈 소스 모델과 같은 것을 사용하세요.
다음으로 논문이 어떻게 구현되는지 살펴보겠습니다.
아래 그림은 SQL 작업과 함수 표현 작업을 융합하도록 훈련된 Code Llama 34B와 GPT-3.5의 성능을 보여줍니다. 결과는 GPT-3.5가 두 작업 모두에서 더 나은 정확도를 달성한다는 것을 보여줍니다.
하드웨어 사용량은 약 0.475달러인 A40 GPU를 사용했습니다.
또한 실험에서는 무서운 데이터 세트에 매우 적합한 두 개의 데이터 세트, 즉 Spider 데이터 세트의 하위 세트와 Viggo 함수 표현 데이터 세트를 열거합니다.
GPT-3.5 모델과의 공정한 비교를 위해 최소한의 하이퍼 매개변수를 사용하여 Llama에 대한 실험을 수행했습니다.
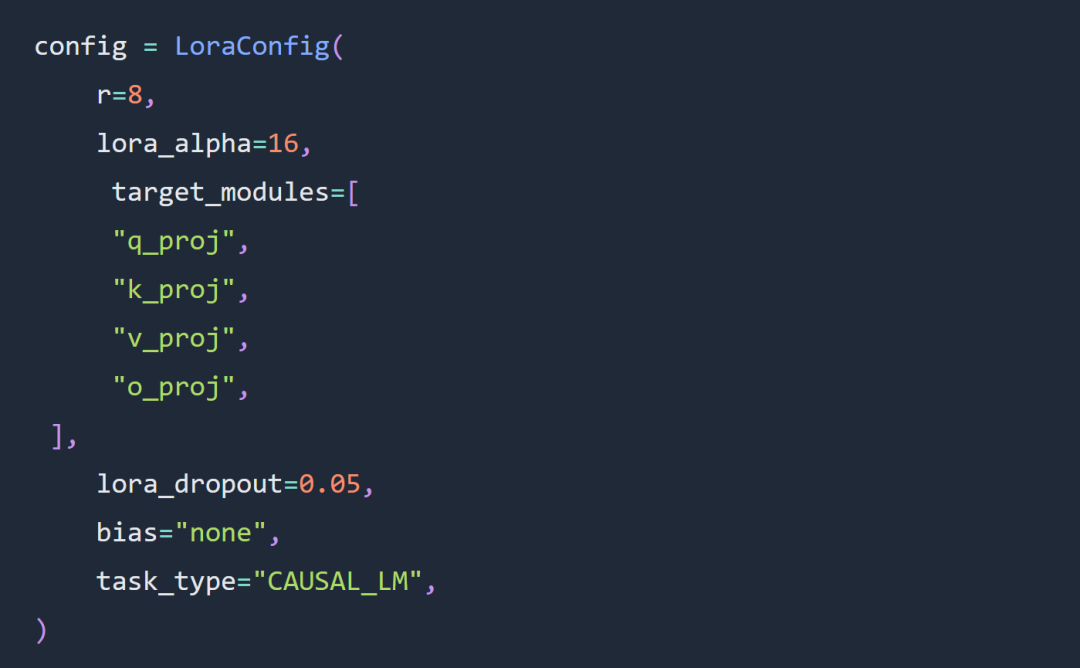
이 기사의 실험에서 두 가지 주요 선택은 전체 매개변수 매개변수 대신 Code Llama 34B 및 Lora 매개변수를 사용하는 것입니다. ˚ 실험은 LoRa 슈퍼 매개변수 구성의 규칙을 크게 따릅니다. LoRA 로드는 다음과 같습니다.
 SQL 프롬프트는 다음과 같습니다.
SQL 프롬프트는 다음과 같습니다.
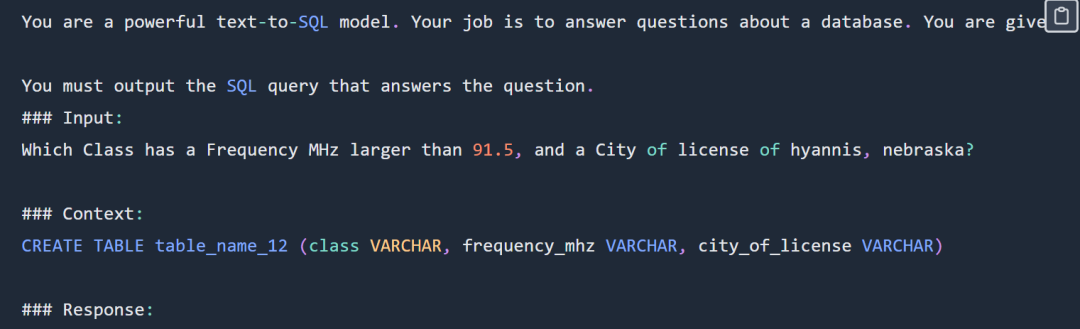
디스플레이의 SQL 프롬프트 부분을 확인하세요. 전체 프롬프트를 보려면 원본 블로그를 확인하세요. 실험에서는 전체 Spider 데이터 세트를 사용하지 않았습니다. 구체적인 형식은 다음과 같습니다
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
함수 표현 프롬프트의 예 아래와 같이: 提 함수는 디스플레이의 프롬프트 부분을 나타냅니다.
이 함수는 작업 코드와 데이터 주소를 나타냅니다: https://github.com/ samlhuillier/viggo-finetune
원본 링크:
https://ragntune.com/blog/gpt3.5-vs-llama2-finetuning?continueFlag=11fc7786e20d498fc4daa79c5923e198위 내용은 GPT-3.5 또는 Jordan Llama 2 및 기타 오픈 소스 모델을 선택하시겠습니까? 종합적으로 비교해보면 답은 이렇습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!