
엔지니어링 효율성 향상 - RAG(향상된 검색 생성)

- 王林앞으로
- 2023-10-14 20:17:011507검색
GPT-3와 같은 대규모 언어 모델의 출현으로 자연어 처리(NLP) 분야에서 큰 발전이 이루어졌습니다. 이러한 언어 모델은 인간과 유사한 텍스트를 생성하는 능력을 갖추고 있어 챗봇, 번역 등 다양한 시나리오에서 널리 사용되어 왔습니다

그러나 전문화되고 사용자 정의된 응용 시나리오의 경우 범용 대형 언어 모델이 있을 수 있습니다. 전문적인 지식이 부족합니다. 특수한 말뭉치로 이러한 모델을 미세 조정하는 데는 비용과 시간이 많이 소요되는 경우가 많습니다. "RAG(Retrieval Enhanced Generation)"는 전문 애플리케이션을 위한 새로운 기술 솔루션을 제공합니다.
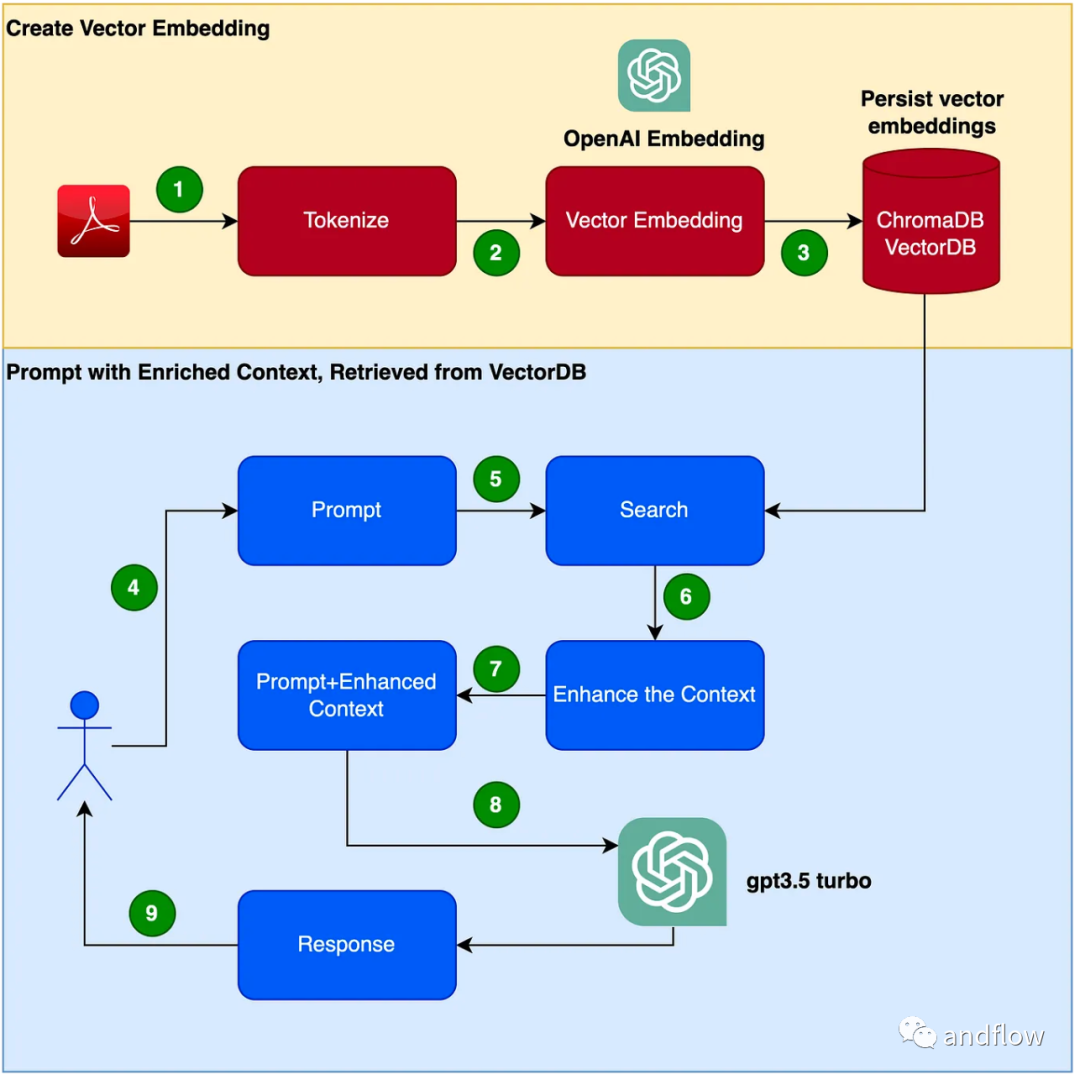
아래에서는 주로 RAG의 작동 방식을 소개하고, 실제 사례를 통해 제품 매뉴얼을 전문적인 코퍼스로 활용하고, GPT-3.5 Turbo를 질의응답 모델로 활용해 효율성을 검증합니다.
사례: 특정 제품과 관련된 질문에 답할 수 있는 챗봇을 개발합니다. 이 비즈니스에는 고유한 사용자 매뉴얼이 있습니다.
RAG 소개
RAG는 도메인별 질문과 답변에 대한 효과적인 솔루션을 제공합니다. 주로 업계 지식을 저장 및 검색을 위한 벡터로 변환하고, 검색 결과를 사용자 질문과 결합하여 프롬프트 정보를 형성하고, 마지막으로 대규모 모델을 사용하여 적절한 답변을 생성합니다. 검색 메커니즘과 언어 모델을 결합하여 모델의 응답성이 크게 향상됩니다.
챗봇 프로그램을 만드는 단계는 다음과 같습니다.
- PDF(사용자 설명서 PDF 파일)를 읽고 1000개 토큰에 대한 Chunk_size를 사용하여 토큰화합니다. .
- 벡터 생성(OpenAI EmbeddingsAPI를 사용하여 벡터 생성 가능)
- 로컬 벡터 라이브러리에 벡터를 저장합니다. ChromaDB를 벡터 데이터베이스로 사용하겠습니다(벡터 데이터베이스는 Pinecone 또는 다른 제품으로 대체할 수도 있음).
- 사용자는 질문/질문으로 팁을 게시합니다.
- 사용자의 질문을 기반으로 벡터 데이터베이스에서 지식 컨텍스트 데이터를 검색합니다. 이 지식 맥락 데이터는 종종 문맥 강화라고 불리는 단서 단어를 강화하기 위해 후속 단계에서 단서 단어와 함께 사용될 것입니다.
- 사용자 질문이 포함된 프롬프트 단어는 이 맥락을 기반으로 향상된 문맥 지식
- LLM 답변과 함께 LLM으로 전달됩니다.
실습 개발
(1) Python 가상 환경 설정 버전 또는 종속성 충돌을 피하기 위해 Python을 샌드박스하는 가상 환경을 설정합니다. 다음 명령을 실행하여 새로운 Python 가상 환경을 생성합니다.
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
다시 작성해야 하는 콘텐츠는 다음과 같습니다. (2) OpenAI 키 생성
GPT를 사용하려면 액세스하려면 OpenAI 키가 필요합니다.
다시 작성해야 하는 콘텐츠는 다음과 같습니다. (3) 종속 라이브러리 설치
설치 프로그램에 필요한 다양한 종속성. 다음 라이브러리가 포함되어 있습니다.
- lanchain: LLM 애플리케이션 개발을 위한 프레임워크입니다.
- chromaDB: 영구 벡터 임베딩을 위한 VectorDB입니다.
- 구조화되지 않음: Word/PDF 문서를 전처리하는 데 사용됩니다.
- tiktoken: Tokenizer 프레임워크
- pypdf: PDF 문서를 읽고 처리하기 위한 프레임워크입니다.
- openai: OpenAI 프레임워크에 액세스하세요.
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
OpenAI 키를 저장할 환경 변수를 만듭니다.
export OPENAI_API_KEY=<openai-key></openai-key>
(4) 사용자 설명서 PDF 파일을 벡터로 변환하고 ChromaDB에 저장합니다.
PDF를 읽고, 문서를 토큰화하고, 문서를 분할하기 위해
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
를 사용하는 데 필요한 모든 종속 라이브러리와 기능을 가져옵니다. .
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
크로마 컬렉션과 크로마 데이터를 저장할 로컬 디렉터리를 생성하세요. 그런 다음 벡터(임베딩)를 생성하고 이를 ChromaDB에 저장합니다.
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()
이 코드를 실행하면 벡터를 저장하기 위해 생성된 폴더가 표시됩니다.
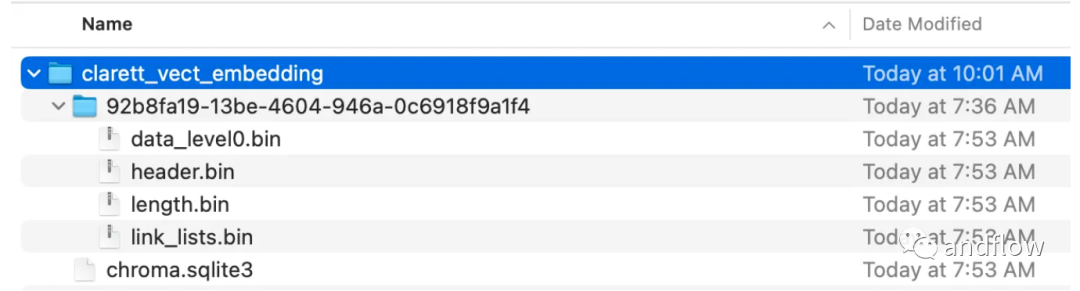
벡터 임베딩이 ChromaDB에 저장된 후 LangChain의 ConversationalRetrievalChain API를 사용하여 채팅 기록 구성 요소를 시작할 수 있습니다.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
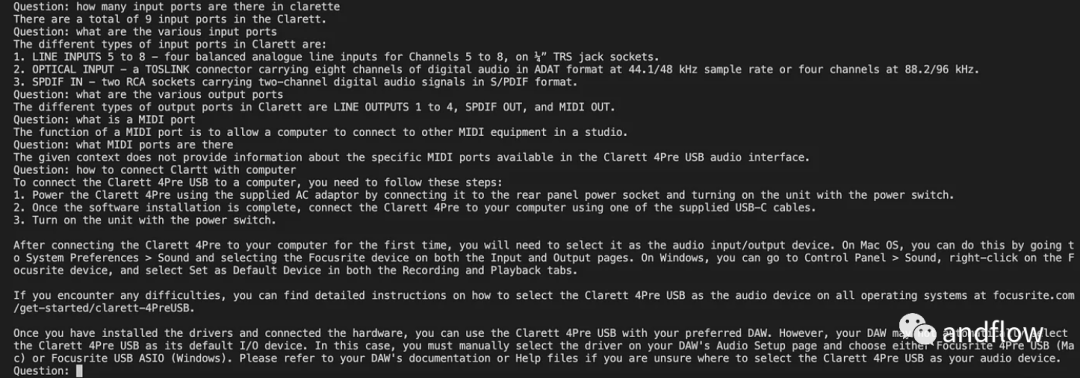
langchan을 초기화한 후 채팅/QA에 사용할 수 있습니다. 아래 코드에서는 사용자가 입력한 질문을 수락하고, 사용자가 'done'을 입력한 후 질문을 LLM으로 전달하여 답변을 받아 인쇄합니다.
chat_history = []qry = ""while qry != 'done':qry = input('Question: ')if qry != exit:response = chatQA({"question": qry, "chat_history": chat_history})print(response["answer"])

간단히 말하면
RAG는 GPT와 같은 언어 모델의 장점과 정보 검색의 장점을 결합합니다. 특정 지식 맥락 정보를 활용하여 프롬프트 단어의 풍부함을 향상함으로써 언어 모델은 보다 정확한 지식 맥락 관련 답변을 생성할 수 있습니다. RAG는 "미세 조정"보다 더 효율적이고 비용 효과적인 솔루션을 제공하여 산업 애플리케이션 또는 기업 애플리케이션을 위한 맞춤형 대화형 솔루션을 제공합니다
위 내용은 엔지니어링 효율성 향상 - RAG(향상된 검색 생성)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!