



머신러닝 모델의 일반화 능력 문제에는 구체적인 코드 예제가 필요합니다
머신러닝의 개발과 적용이 점점 더 보편화되면서 사람들은 머신러닝 모델의 일반화 능력 문제에 점점 더 많은 관심을 기울이고 있습니다. . 일반화 능력은 레이블이 지정되지 않은 데이터에 대한 기계 학습 모델의 예측 능력을 의미하며, 현실 세계에서 모델의 적응성으로도 이해될 수 있습니다. 좋은 머신러닝 모델은 높은 일반화 능력을 갖추고 새로운 데이터에 대해 정확한 예측을 할 수 있어야 합니다. 그러나 실제 적용에서는 모델이 훈련 세트에서는 잘 수행되지만 테스트 세트나 실제 데이터에서는 성능이 좋지 않아 일반화 능력의 문제가 제기되는 상황에 자주 직면합니다.
일반화 능력 문제의 주된 이유는 훈련 과정에서 모델이 훈련 세트 데이터를 과적합하기 때문입니다. 과대적합은 훈련 시 훈련 세트의 노이즈와 이상값에 너무 집중하여 데이터의 실제 패턴을 무시하는 모델을 의미합니다. 이러한 방식으로 모델은 훈련 세트의 모든 데이터에 대해 좋은 예측을 수행하지만 새 데이터에 대해서는 정확한 예측을 수행하지 않습니다. 이 문제를 해결하려면 과적합을 방지하기 위한 몇 가지 조치를 취해야 합니다.
아래에서는 특정 코드 예제를 사용하여 머신러닝 모델의 일반화 능력 문제를 처리하는 방법을 설명하겠습니다. 이미지가 고양이인지 개인지 결정하기 위해 분류기를 구축한다고 가정해 보겠습니다. 우리는 훈련 세트로 고양이와 개의 레이블이 지정된 이미지 1000개를 수집하고 CNN(컨볼루션 신경망)을 분류자로 사용했습니다.
코드 예시는 다음과 같습니다.
import tensorflow as tf
from tensorflow.keras import layers
# 加载数据集
train_dataset = tf.keras.preprocessing.image_dataset_from_directory(
"train", label_mode="binary", image_size=(64, 64), batch_size=32
)
test_dataset = tf.keras.preprocessing.image_dataset_from_directory(
"test", label_mode="binary", image_size=(64, 64), batch_size=32
)
# 构建卷积神经网络模型
model = tf.keras.Sequential([
layers.experimental.preprocessing.Rescaling(1./255),
layers.Conv2D(32, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(128, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(1)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
model.fit(train_dataset, validation_data=test_dataset, epochs=10)
# 测试模型
test_loss, test_acc = model.evaluate(test_dataset)
print('Test accuracy:', test_acc)이 예시에서는 먼저 tf.keras.preprocessing.image_dataset_from_directory 함수를 사용하여 훈련 세트와 테스트 세트의 이미지 데이터를 로드합니다. 그런 다음 다중 컨볼루션 레이어, 풀링 레이어 및 완전 연결 레이어를 포함하는 컨볼루션 신경망 모델을 구축했습니다. 모델의 마지막 레이어는 이진 분류 레이어로, 사진이 고양이인지 개인지 판단하는 데 사용됩니다. 마지막으로 model.fit 함수를 사용하여 모델을 훈련하고 model.evaluate 함수를 사용하여 테스트 세트에서 모델 성능을 테스트합니다. tf.keras.preprocessing.image_dataset_from_directory函数加载训练集和测试集的图片数据。然后,我们构建了一个卷积神经网络模型,包括多个卷积层、池化层和全连接层。模型的最后一层是一个二元分类层,用来判断图片中是猫还是狗。最后,我们使用model.fit函数来训练模型,并使用model.evaluate函数来测试模型在测试集上的表现。
以上代码示例中的主要思路是通过使用卷积神经网络来提取图片特征,并通过全连接层对特征进行分类。同时,我们通过在模型的训练过程中加入Dropout层来减少过度拟合的可能性。这种方法可以一定程度上提高模型的泛化能力。
总结来说,머신러닝 모델의 일반화 능력 문제是一个重要且需要注意的问题。在实际应用中,我们需要采取一些合适的方法来避免模型的过度拟合,以提高模型的泛化能力。在示例中,我们使用了卷积神经网络和Dropout
Dropout 레이어를 추가하여 과적합 가능성을 줄입니다. 이 방법은 모델의 일반화 능력을 어느 정도 향상시킬 수 있습니다. 🎜🎜요약하자면, 머신러닝 모델의 일반화 능력은 주의가 필요한 중요한 문제입니다. 실제 적용에서는 모델의 일반화 능력을 향상시키기 위해 모델의 과적합을 방지하기 위한 몇 가지 적절한 방법을 취해야 합니다. 예시에서는 일반화 능력 문제를 다루기 위해 컨벌루션 신경망과 Dropout 레이어를 사용했지만 이는 가능한 방법일 뿐이며 구체적인 방법의 선택은 실제 상황에 따라 결정되어야 합니다. 그리고 데이터 특성. 🎜위 내용은 머신러닝 모델의 일반화 능력 문제의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

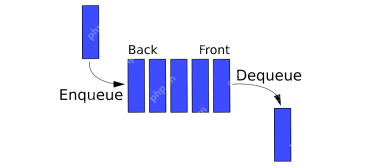 파이썬의 대기열 - 분석 VidhyaApr 16, 2025 am 10:32 AM
파이썬의 대기열 - 분석 VidhyaApr 16, 2025 am 10:32 AM소개 슈퍼마켓 대기열에서 자신을 구상하면서 좋아하는 아티스트를위한 콘서트 티켓을 구매하기 위해 회전을 기다리고 있습니다. 개인이 라인에 합류하여 첫 번째 (FIFO) 방식으로 진행하는이 순서 대비 프로세스는 PREC입니다.
 AV 바이트 : AI 산업 교대 및 기술 혁신 - 분석 VidhyaApr 16, 2025 am 10:29 AM
AV 바이트 : AI 산업 교대 및 기술 혁신 - 분석 VidhyaApr 16, 2025 am 10:29 AM이번 주 AI : 주요 인수, 모델 발전 및 윤리적 고려 사항 이 AV Bytes 에디션은 지난주의 상당한 AI 혁신을 다룹니다. Google의 전략적 문자 획득에서 이는 Bitnet B1.58의 출시에 이르기까지
 Movinets 탐색 : 효율적인 모바일 비디오 인식Apr 16, 2025 am 10:25 AM
Movinets 탐색 : 효율적인 모바일 비디오 인식Apr 16, 2025 am 10:25 AM소개 “Movinets Unleashed”로 매혹적인 모바일 비디오 인식의 세계로 뛰어 들자! 이 블로그는 Movinets가 모바일 장치에 대한 비디오 분석을 어떻게 변형시키는 지 탐색합니다.
 팬더 대 폴라Apr 16, 2025 am 10:24 AM
팬더 대 폴라Apr 16, 2025 am 10:24 AM소개 데이터 프로젝트에서 무릎을 꿇고, 대규모 데이터 세트로 씨름하고 가능한 한 빨리 패턴을 사냥한다고 상상해보십시오. 이동 데이터 조작 도구에 도달하지만 더 나은 옵션이 존재하면 어떻게됩니까? 상대적으로 NE를 입력하십시오
 IT 비즈니스 분석가의 역할Apr 16, 2025 am 10:19 AM
IT 비즈니스 분석가의 역할Apr 16, 2025 am 10:19 AM소개 혁신적인 소프트웨어를 시작하기 직전에 역동적 인 IT 회사를 구상하십시오. 흥분이 높지만 기술 개발자와 비즈니스 이해 관계자 간의 격차를 해소합니다. 이곳은 IT 비즈니스 분석가입니다
 파이썬의 계승 프로그램Apr 16, 2025 am 10:13 AM
파이썬의 계승 프로그램Apr 16, 2025 am 10:13 AM소개 특정 원하는 맛 프로파일로 접시를 준비한다고 상상해보십시오. 올바른 단계의 단계가 중요합니다. 마찬가지로 수학 및 프로그래밍에서 숫자의 계승을 계산하려면 정확한 Multiplicatio의 정확한 시퀀스가 필요합니다.
 데이터 오케스트레이션을위한 공기 흐름 대안 - 분석 VidhyaApr 16, 2025 am 09:55 AM
데이터 오케스트레이션을위한 공기 흐름 대안 - 분석 VidhyaApr 16, 2025 am 09:55 AM소개 Apache Airflow는 데이터 오케스트레이션의 중요한 구성 요소이며 복잡한 워크 플로우를 처리하고 데이터 파이프 라인을 자동화 할 수있는 기능으로 유명합니다. 많은 조직이 유연성과 S로 인해이를 선택했습니다.
 Nvidia AI Summit 2024에 어떻게 등록 할 수 있습니까?Apr 16, 2025 am 09:49 AM
Nvidia AI Summit 2024에 어떻게 등록 할 수 있습니까?Apr 16, 2025 am 09:49 AMNvidia AI Summit 2024 : 인도의 AI 혁명에 대한 깊은 다이빙 Datahack Summit 2024에 이어 인도는 뭄바이의 Jio World Convention Center에서 10 월 23 일부터 25 일까지 예정된 Nvidia AI Summit 2024에 기어 올랐습니다. 이 중추적 인 이벤트 무도회


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

Dreamweaver Mac版
시각적 웹 개발 도구

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

