
로그 스펙트로그램을 기반으로 한 딥러닝 심음 분류

- PHPz앞으로
- 2023-09-29 17:21:081604검색
이 논문은 심음 신호의 로그 스펙트로그램을 기반으로 두 가지 심박음 분류 모델을 제안하는 매우 흥미롭습니다. 우리 모두는 스펙트로그램이 음성 인식에 널리 사용된다는 것을 알고 있습니다. 본 논문에서는 심음 신호를 음성 신호로 처리하여 좋은 결과를 얻었습니다
심음 신호를 일정한 길이의 프레임으로 분할하고 이에 대한 로그 스펙트로그램 특징을 추출한 논문입니다. 두 가지 딥 러닝 모델인 CNN(컨벌루션 신경망)은 추출된 특징을 기반으로 심장 박동 소리를 분류합니다.
심장음 데이터 세트
영상 진단에는 심장 자기공명영상(MRI), CT 스캔, 심근관류 영상이 포함됩니다. 이러한 기술의 단점도 분명합니다. 현대 기계 및 전문가에 대한 높은 요구 사항과 긴 진단 시간입니다.
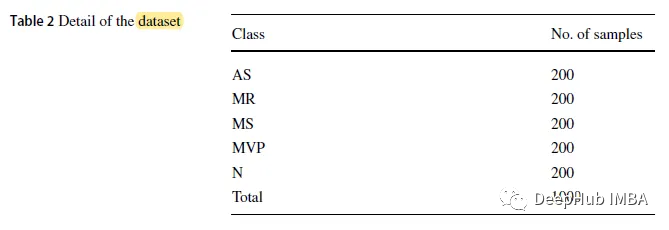
논문에 사용된 데이터 세트는 공개 데이터 세트로, 샘플링 주파수가 8kHz인 .wav 형식의 1000개 신호 샘플이 포함되어 있습니다. 데이터 세트는 1개의 정상 범주(N)와 4개의 비정상 범주(대동맥 협착증(AS), 승모판 역류(MR), 승모판 협착증(MS) 및 승모판 역류(MR))를 포함하는 5개 범주로 나뉩니다. )
대동맥 협착증(AS)은 대동맥 판막이 너무 작거나 좁거나 뻣뻣한 경우입니다. 대동맥 협착증의 전형적인 심잡음은 고음의 "다이아몬드 모양" 심잡음입니다.
승모판 역류(MR)는 심장의 승모판이 제대로 닫히지 않아 혈액이 펌핑되지 않고 심장으로 다시 흘러 들어가는 경우입니다. 태아 심장을 청진할 때 S1에서 나오는 소리는 S2만큼 심잡음의 크기가 커질 때까지 낮을 수 있습니다(때로는 클 수도 있습니다). S3 이후 승모판의 빠른 흐름으로 인해 짧고 우렁찬 확장기 중간 잡음이 들릴 수 있습니다
승모판 협착증(MS)은 승모판이 손상되어 완전히 열릴 수 없음을 의미합니다. 심음 청진상 S1은 초기 승모판 협착증에서 악화되고, 심한 승모판 협착증에서는 부드러워지는 것으로 나타났습니다. 폐고혈압이 진행되면 S2 소리가 강조됩니다. 순수 MS 환자는 좌심실 S3가 거의 없습니다.
승모판 탈출증(MVP)은 심장 수축 중에 승모판 전단지가 좌심방으로 탈출하는 것을 말합니다. MVP는 일반적으로 양성이지만 승모판 역류, 심내막염 및 척수 파열과 같은 합병증을 유발할 수 있습니다. 징후에는 수축기 중 클릭 및 수축기 말 잡음(역류가 있는 경우)이 포함됩니다.
전처리 및 특징 추출
소리 신호의 길이가 다르므로 녹음된 각 파일 속도에 대해 샘플을 고정해야 합니다. 소리 신호에 최소한 하나의 완전한 심장 주기가 포함되도록 하기 위해 길이를 자릅니다. 성인의 분당 심장 박동 수는 65~75회이고 심장 박동 주기는 약 0.8초라는 사실에 따라 신호 샘플을 2.0초, 1.5초, 1.0초의 세그먼트로 자릅니다
이산 푸리에 변환(DFT)을 기반으로 ), 심장음은 신호의 원래 파형이 로그 스펙트로그램으로 변환됩니다. 소리 신호의 DFT y(k)는 식(1)이고, 로그 스펙트럼 s는 식(2)와 같이 정의된다.
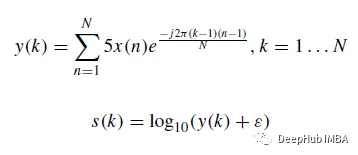
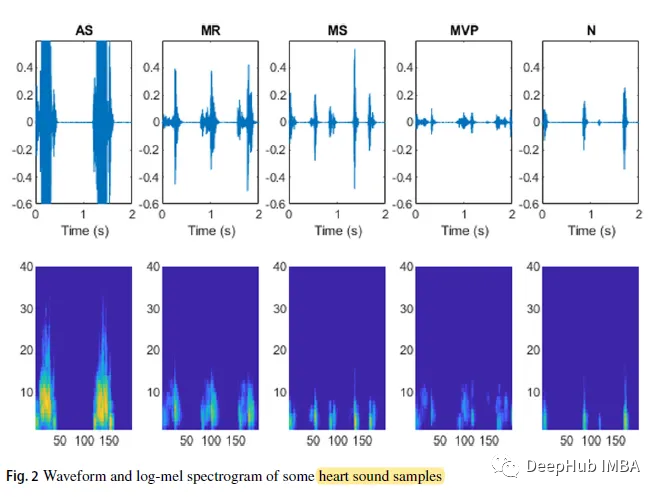
공식에서 N은 벡터 x의 길이이고 ε = 10^(- 6)은 작은 오프셋입니다. 일부 심장 소리 샘플의 파형 및 로그 스펙트로그램은 다음과 같습니다.
딥 러닝 모델
1, LSTM
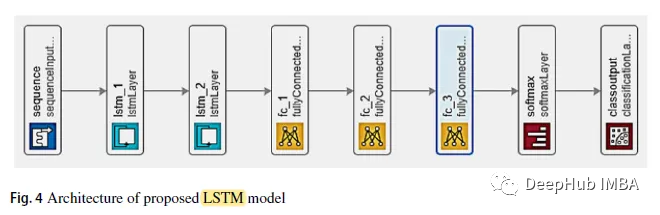
LSTM 모델은 2개의 직접 연결 레이어로 설계되었습니다. 그런 다음 완전한 연결의 3개 레이어가 있습니다. 세 번째 완전 연결 계층은 소프트맥스 분류기를 입력합니다.
2. CNN 모델
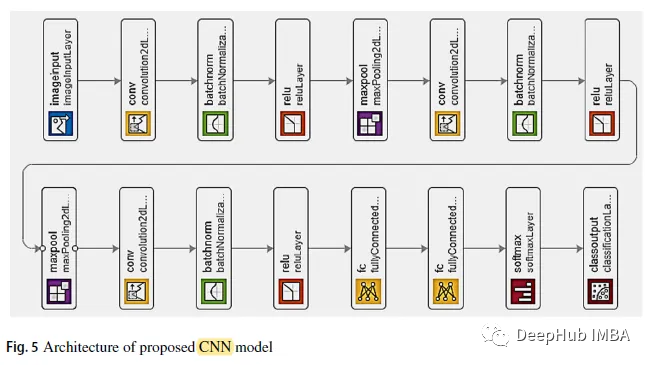
위 그림에서 볼 수 있듯이 처음 두 컨볼루션 레이어 뒤에는 겹치는 최대 풀링 레이어가 있습니다. 세 번째 컨벌루션 레이어는 첫 번째 완전 연결 레이어에 직접 연결됩니다. 두 번째 완전 연결 레이어는 5개의 클래스 라벨이 있는 소프트맥스 분류기에 입력됩니다. 각 컨볼루션 레이어 뒤에 BN 및 ReLU 사용
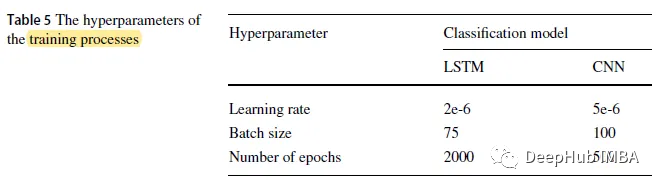
3. 학습 세부 정보
Results
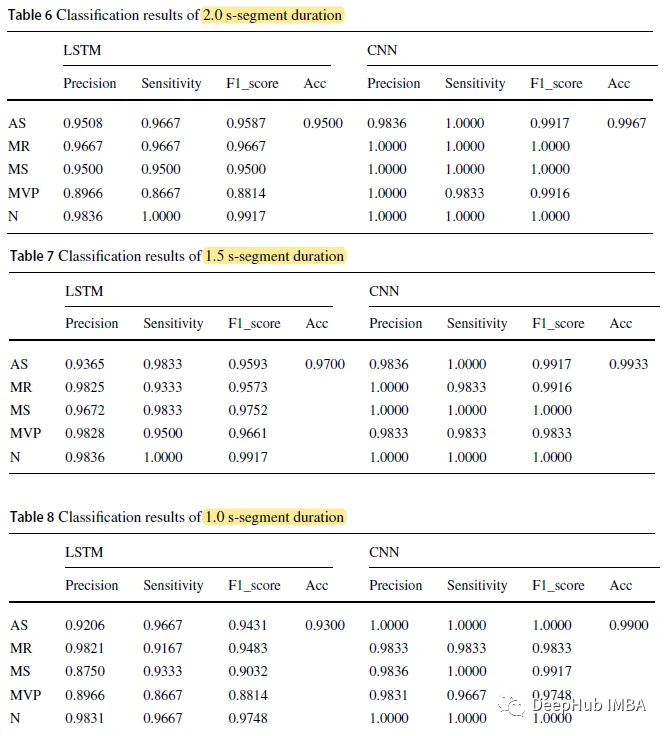
학습 세트는 전체 데이터 세트의 70%를 차지하고 테스트 세트에는 나머지가 포함됩니다. 부분
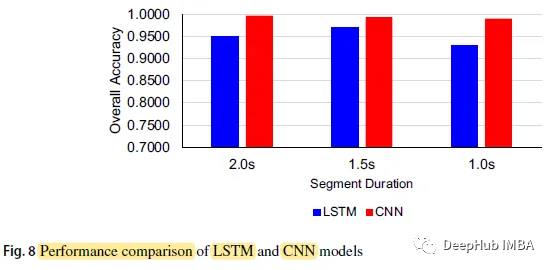
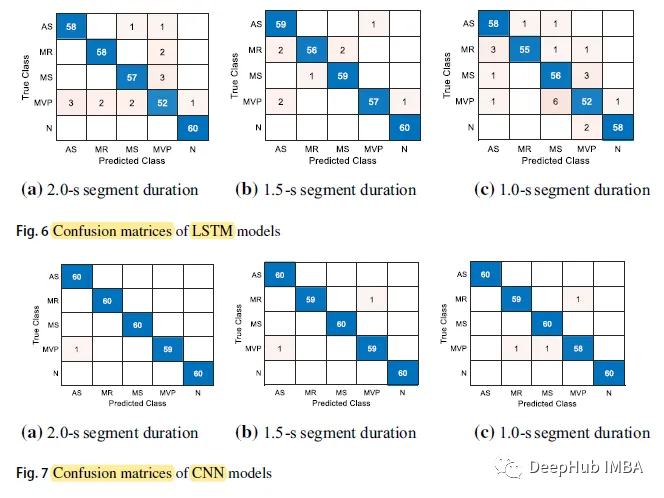
CNN 모델 세그먼트 기간이 2.0초일 때 가장 높은 정확도는 0.9967이고, 분할 시간이 1.0초인 LSTM 정확도는 0.9300입니다.
CNN 모델의 전체 정확도는 각각 0.9967, 0.9933, 0.9900이고 세그먼트 지속 시간은 각각 2.0초, 1.5초, 1.0초인 반면 LSTM 모델의 세 수치는 각각 0.9500, 0.9700, 0.9300입니다
CNN 각 기간별 모델의 예측 정확도는 LSTM 모델의 예측 정확도보다 높습니다.
다음은 혼동 행렬입니다.
N 클래스(Normal)의 예측 정확도가 가장 높으며, 5개 사례에서 60에 도달하는 반면 MVP 클래스는 모든 사례 중에서 예측 정확도가 가장 낮습니다.
LSTM 모델의 입력 시간 길이는 2.0초이고, 가장 긴 예측 시간은 9.8631ms입니다. 분류 시간이 1.0초인 CNN 모델은 예측 시간이 4.2686ms로 가장 짧습니다.
다른 SOTA에 비해 일부 연구의 정확도는 매우 높지만 이러한 연구는 두 가지 범주(정상 및 비정상)만 포함하는 반면, 우리 연구는 5개 범주로 나누어집니다
를 사용하여 다른 연구와 비교 동일한 데이터 세트(0.9700)에서 논문 연구는 0.9967의 최고 정확도로 크게 개선되었습니다.

위 내용은 로그 스펙트로그램을 기반으로 한 딥러닝 심음 분류의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!