
ICCV 2023 | 인간 행동 생성을 재구성하고 확산 모델과 검색 전략을 통합하는 새로운 패러다임인 ReMoDiffuse가 등장합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-09-27 21:29:01844검색
인간 액션 생성 작업의 목표는 엔터테인먼트, 가상 현실, 로봇 공학 및 기타 분야의 요구 사항을 충족하기 위해 현실적인 인간 액션 시퀀스를 생성하는 것입니다. 전통적인 생성 방법에는 3D 캐릭터 생성, 키프레임 애니메이션 및 모션 캡처와 같은 단계가 포함되지만 시간이 많이 걸리고 전문적인 기술 지식이 필요하며 고가의 시스템과 소프트웨어가 필요하고 다양한 소프트웨어와 하드웨어 시스템 간의 호환성이 가능한 등 많은 제한이 있습니다. 성적인 문제 등 딥 러닝이 발전하면서 사람들은 텍스트 설명을 입력하고 모델이 텍스트 요구 사항과 일치하는 동작 시퀀스를 생성하도록 요구하는 등 인간 동작 시퀀스의 자동 생성을 달성하기 위해 생성 모델을 사용하기 시작했습니다. 확산 모델이 현장에 도입됨에 따라 생성된 작업과 주어진 텍스트의 일관성이 계속해서 향상됩니다.
그러나 생성된 동작의 자연스러움이 향상되었음에도 불구하고 사용자 요구와 여전히 큰 격차가 있습니다. 본 논문에서는 인간 모션 생성 알고리즘의 성능을 더욱 향상시키기 위해 MotionDiffuse[1]를 기반으로 한 ReMoDiffuse 알고리즘(그림 1)을 제안합니다. 검색 전략을 활용하여 관련성이 높은 참조 샘플을 찾고 세분화된 참조 기능을 제공하여 더 높은 품질의 작업 시퀀스를 생성합니다

논문 링크: https://arxiv.org/pdf/2304.01116 .pdf
GitHub 링크: https://github.com/mingyuan-zhang/ReMoDiffuse
프로젝트 홈페이지: https://mingyuan-zhang.github.io/projects/ReMoDiffuse.html
확산을 교묘하게 통합하여 모델과 혁신적인 검색 전략인 ReMoDiffuse는 텍스트 기반 인간 행동 생성에 새로운 생명을 불어넣습니다. 신중하게 고안된 모델 구조를 통해 ReMoDiffuse는 풍부하고 다양하며 매우 사실적인 액션 시퀀스를 생성할 수 있을 뿐만 아니라 다양한 길이와 다중 입도의 액션 요구 사항을 효과적으로 충족할 수 있습니다. 실험에 따르면 ReMoDiffuse는 작업 생성 분야의 여러 핵심 지표에서 기존 알고리즘을 훨씬 능가하는 성능을 발휘한다는 것이 입증되었습니다.
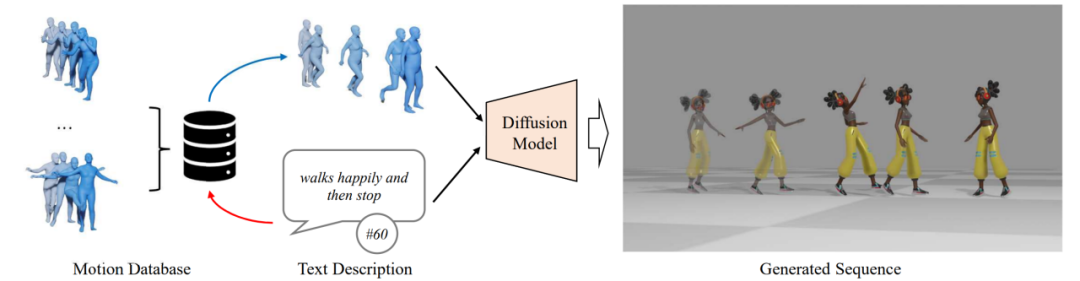 그림 1. ReMoDiffuse 개요
그림 1. ReMoDiffuse 개요
방법 소개
ReMoDiffuse의 주요 프로세스는 검색과 확산의 두 단계로 나뉩니다. 검색 단계에서 ReMoDiffuse는 하이브리드 검색 기술을 사용하여 사용자 입력 텍스트와 예상 작업 시퀀스 길이를 기반으로 외부 다중 모달 데이터베이스에서 풍부한 정보의 샘플을 검색하여 작업 생성을 위한 강력한 지침을 제공합니다. 확산 단계에서 ReMoDiffuse는 검색 단계에서 얻은 정보를 사용하여 효율적인 모델 구조를 통해 사용자 입력과 의미론적으로 일치하는 모션 시퀀스를 생성합니다.
효율적인 검색을 보장하기 위해 ReMoDiffuse는 다음과 같은 데이터 흐름을 신중하게 설계했습니다. 검색 단계(그림 2):
검색 프로세스에는 세 가지 유형의 데이터, 즉 사용자 입력 텍스트, 예상 작업 시퀀스 길이 및 여러 쌍을 포함하는 외부 다중 모드 데이터베이스가 있습니다. 가장 관련성이 높은 샘플을 검색할 때 ReMoDiffuse는 공식 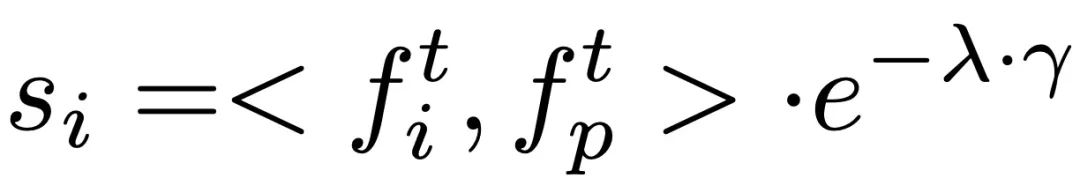 을 사용하여 각 데이터베이스의 샘플과 사용자 입력 간의 유사성을 계산합니다. 여기서 첫 번째 항목은 사전 훈련된 CLIP [2] 모델의 텍스트 인코더를 사용하여 사용자 입력 텍스트와 데이터베이스 엔터티의 텍스트 간의 코사인 유사성을 계산하는 것이고, 두 번째 항목은 예상되는 동작 시퀀스 길이의 차이를 계산하는 것입니다. 그리고 데이터베이스 엔터티의 동작 시퀀스 길이는 운동학적 유사성으로 간주됩니다. 유사성 점수를 계산한 후 ReMoDiffuse는 검색된 샘플과 유사한 유사성을 갖는 상위 k 샘플을 선택하고 텍스트 특징
을 사용하여 각 데이터베이스의 샘플과 사용자 입력 간의 유사성을 계산합니다. 여기서 첫 번째 항목은 사전 훈련된 CLIP [2] 모델의 텍스트 인코더를 사용하여 사용자 입력 텍스트와 데이터베이스 엔터티의 텍스트 간의 코사인 유사성을 계산하는 것이고, 두 번째 항목은 예상되는 동작 시퀀스 길이의 차이를 계산하는 것입니다. 그리고 데이터베이스 엔터티의 동작 시퀀스 길이는 운동학적 유사성으로 간주됩니다. 유사성 점수를 계산한 후 ReMoDiffuse는 검색된 샘플과 유사한 유사성을 갖는 상위 k 샘플을 선택하고 텍스트 특징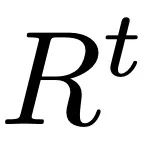 및 액션 특징
및 액션 특징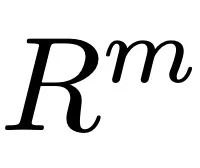 을 추출합니다. 이 두 가지는 사용자가 입력한 텍스트에서 추출된 특징
을 추출합니다. 이 두 가지는 사용자가 입력한 텍스트에서 추출된 특징 과 함께 확산 단계의 입력 신호 역할을 하여 액션 생성을 안내합니다.
과 함께 확산 단계의 입력 신호 역할을 하여 액션 생성을 안내합니다.
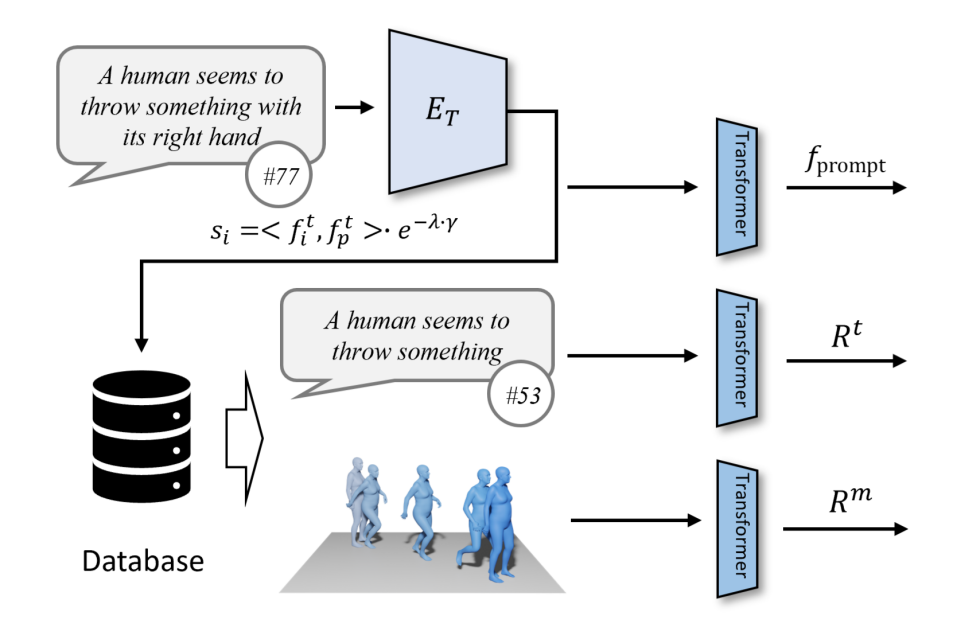 그림 2: ReMoDiffuse
그림 2: ReMoDiffuse
확산 공정(그림 3.c)은 순방향 공정과 역방향 공정의 두 부분으로 구성됩니다. 순방향 프로세스에서 ReMoDiffuse는 원래 모션 데이터에 가우시안 노이즈를 점진적으로 추가하고 최종적으로 이를 랜덤 노이즈로 변환합니다. 역 프로세스는 노이즈를 제거하고 사실적인 모션 샘플을 생성하는 데 중점을 둡니다. ReMoDiffuse는 임의의 가우스 노이즈에서 시작하여 역 프로세스의 각 단계에서 SMT(의미 변조 모듈)(그림 3.a)를 사용하여 실제 분포를 추정하고 조건부 신호를 기반으로 노이즈를 점진적으로 제거합니다. 여기서 SMT의 SMA 모듈은 모든 조건 정보를 생성된 시퀀스 기능에 통합합니다. 이는 이 기사에서 제안된 핵심 모듈입니다
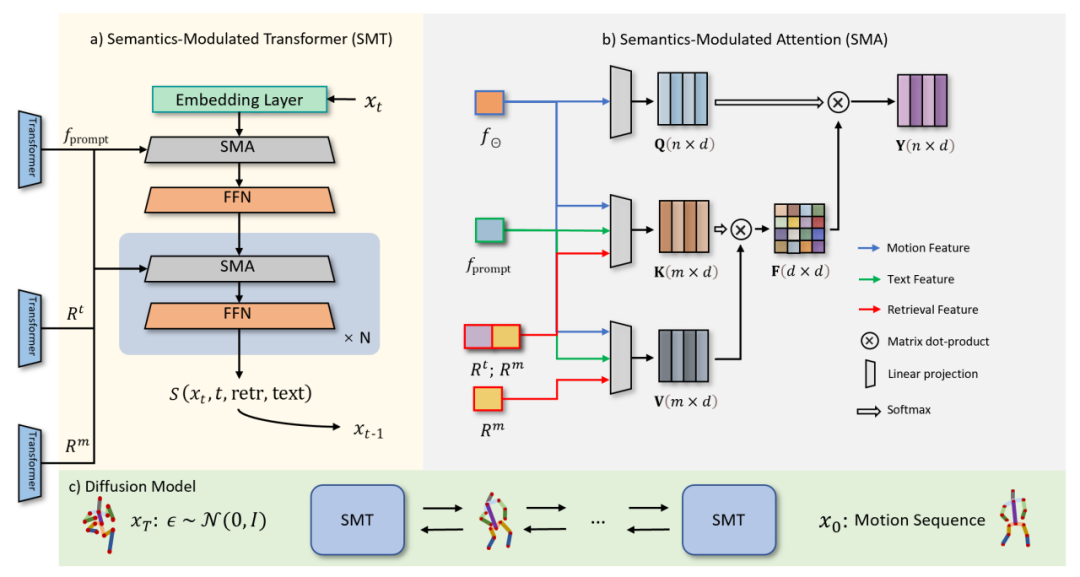 그림 3: ReMoDiffuse의 확산 단계
그림 3: ReMoDiffuse의 확산 단계
SMA 레이어의 경우( 그림 3.b)에서는 효율적인 Attention 메커니즘(Efficient Attention)[3]을 사용하여 Attention 모듈의 계산을 가속화하고 전역 정보를 더욱 강조하는 전역 기능 맵을 만듭니다. 이 기능 맵은 동작 시퀀스에 대한 보다 포괄적인 의미론적 단서를 제공하여 모델 성능을 향상시킵니다. SMA 계층의 핵심 목표는 조건 정보를 집계하여 동작 시퀀스 생성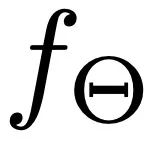 을 최적화하는 것입니다. 이 프레임워크에서:
을 최적화하는 것입니다. 이 프레임워크에서:
1.Q 벡터는 조건부 정보를 기반으로 생성할 것으로 예상되는 예상 동작 시퀀스 를 구체적으로 나타냅니다.
를 구체적으로 나타냅니다.
2.K 벡터는 현재 동작 시퀀스 특징, 사용자가 입력한 의미론적 특징 , 검색 샘플에서 얻은 특징
, 검색 샘플에서 얻은 특징 및
및  을 포함한 여러 요소를 종합적으로 고려하는 인덱싱 메커니즘 역할을 합니다. 그 중 는 검색 샘플에서 얻은 동작 시퀀스 특징을 나타내고, 는 검색 샘플에서 얻은 텍스트 설명 특징을 나타냅니다. 이 포괄적인 구성 방법은 인덱싱 프로세스에서 K 벡터의 효율성을 보장합니다.
을 포함한 여러 요소를 종합적으로 고려하는 인덱싱 메커니즘 역할을 합니다. 그 중 는 검색 샘플에서 얻은 동작 시퀀스 특징을 나타내고, 는 검색 샘플에서 얻은 텍스트 설명 특징을 나타냅니다. 이 포괄적인 구성 방법은 인덱싱 프로세스에서 K 벡터의 효율성을 보장합니다.
3.V 벡터는 액션을 생성하는 데 필요한 실제 기능을 제공합니다. K 벡터와 유사하게 V 벡터는 검색 샘플, 사용자 입력 및 현재 작업 순서를 고려합니다. 검색된 샘플의 텍스트 설명 기능과 생성된 작업 사이에는 직접적인 상관 관계가 없으므로 불필요한 정보 간섭을 피하기 위해 V 벡터를 계산할 때 이 기능을 사용하지 않기로 선택했습니다
Efficient Attention의 글로벌 어텐션 템플릿 메커니즘과 결합된 SMA 레이어는 검색 샘플의 보조 정보, 사용자 텍스트의 의미 정보, 노이즈 제거할 시퀀스의 특징 정보를 사용하여 일련의 포괄적인 글로벌 템플릿을 설정합니다. , 모든 조건 정보가 생성될 시퀀스에 완전히 흡수될 수 있도록 합니다.
내용을 다시 작성하려면 원문을 중국어로 변환해야 합니다. 다시 작성한 후의 모습은 다음과 같습니다. 연구 설계 및 실험 결과
HumanML3D [4] 및 KIT-ML [5]의 두 가지 데이터 세트에서 ReMoDiffuse를 평가했습니다. 실험 결과(표 1 및 2)는 텍스트 일관성 및 동작 품질의 관점에서 제안된 ReMoDiffuse 프레임워크의 강력한 성능과 장점을 보여줍니다
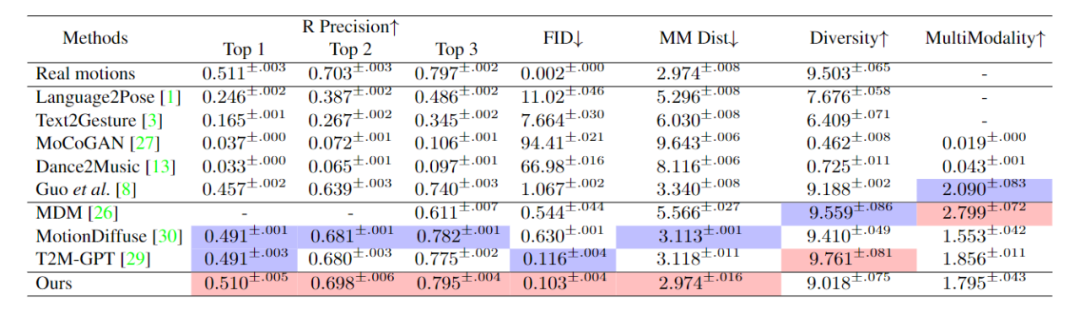 표 1. HumanML3D 테스트 세트에서 다양한 방법의 성능
표 1. HumanML3D 테스트 세트에서 다양한 방법의 성능
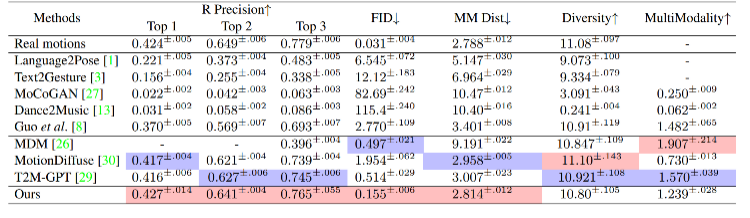 표 2. KIT-ML 테스트 세트의 다양한 방법의 성능
표 2. KIT-ML 테스트 세트의 다양한 방법의 성능
다음은 ReMoDiffuse의 강력한 성능을 보여주는 몇 가지 예입니다(그림 4). 예를 들어, "사람이 원으로 점프합니다"라는 텍스트가 있는 경우 이전 방법과 비교할 때 ReMoDiffuse만이 "점프" 모션과 "원" 경로를 정확하게 캡처할 수 있습니다. 이는 ReMoDiffuse가 효과적으로 텍스트 세부 정보를 캡처하고 지정된 동작 지속 시간에 콘텐츠를 정렬할 수 있음을 보여줍니다
 그림 4. ReMoDiffuse에서 생성된 동작 시퀀스와 다른 방법으로 생성된 동작 시퀀스의 비교
그림 4. ReMoDiffuse에서 생성된 동작 시퀀스와 다른 방법으로 생성된 동작 시퀀스의 비교
우리는 시각적으로 Guo 등의 방법[4], MotionDiffuse[1], MDM[6] 및 ReMoDiffuse에 의해 생성된 해당 동작 시퀀스를 표시하고 설문지 형식으로 테스트 참가자의 의견을 수집했습니다. 결과 분포는 그림 5에 나와 있습니다. 대부분의 경우 테스트 참가자는 우리 방법에 의해 생성된 동작 시퀀스, 즉 ReMoDiffuse에 의해 생성된 동작 시퀀스가 4가지 알고리즘 중에서 주어진 텍스트 설명과 가장 일치한다고 믿고 있음을 결과에서 분명히 알 수 있습니다. 또한 가장 자연스럽고 부드럽습니다.
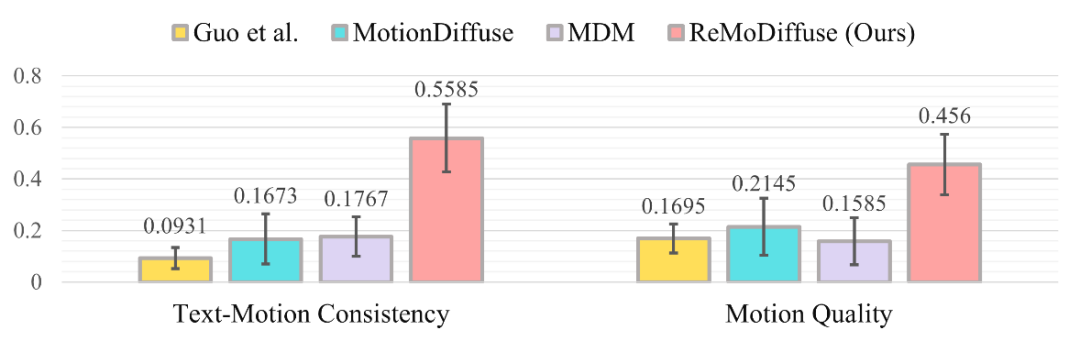 그림 5: 사용자 설문 조사 결과 분포
그림 5: 사용자 설문 조사 결과 분포
인용문
Ming Yuan Zhang, Cai Zhonggang, Pan Liang, Hong Fangzhou, Guo Xinying, Yang Lei 및 Liu Ziwe 나. Motiondiffuse: 확산 모델을 기반으로 한 텍스트 기반 인간 모션 생성. arXiv 사전 인쇄 arXiv:2208.15001, 2022
[2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. arXiv 사전 인쇄 arXiv:2103.00020, 2021.
[3] Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi 및 Hongsheng Li. 컴퓨터 비전 응용에 관한 IEEE/CVF 겨울 컨퍼런스, 페이지 3531–3539, 2021.
[4] Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li 및 Li Cheng. 텍스트의 자연스러운 3D 인간 동작. 컴퓨터 비전 및 패턴 인식에 관한 IEEE/CVF 컨퍼런스 진행, 5152–5161페이지, 2022.
다시 작성해야 하는 내용은 다음과 같습니다. [5] Matthias Plappert, Christian Mandery 그리고 타밈 아스포르. "운동 언어 데이터 세트". 빅 데이터, 4(4):236-252, 2016
[6] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or 및 Amit H Bermano 인간 모션 확산 모델. 학습 표현에 관한 국제 컨퍼런스, 2022.
위 내용은 ICCV 2023 | 인간 행동 생성을 재구성하고 확산 모델과 검색 전략을 통합하는 새로운 패러다임인 ReMoDiffuse가 등장합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!