
Google DeepMind: 대규모 모델과 강화 학습을 결합하여 로봇이 세상을 인식할 수 있는 지능형 두뇌 생성

- WBOY앞으로
- 2023-09-22 09:53:141100검색
로봇 학습 방법을 개발할 때 크고 다양한 데이터 세트를 강력한 표현 모델(예: Transformer)과 통합하고 결합할 수 있다면 일반화 능력이 있고 널리 적용 가능한 전략을 개발하여 로봇이 학습할 수 있을 것으로 기대됩니다. 다양한 작업을 매우 잘 처리합니다. 예를 들어, 이러한 전략을 통해 로봇은 자연어 지시를 따르고, 다단계 동작을 수행하고, 다양한 환경과 목표에 적응하고, 심지어 다른 로봇 형태에도 적용할 수 있습니다.
그러나 최근 로봇 학습 분야에 등장하는 강력한 모델들은 모두 지도 학습 방법을 사용하여 훈련됩니다. 따라서 결과 전략의 성능은 인간 시연자가 고품질 시연 데이터를 제공할 수 있는 정도로 제한됩니다. 이 제한에는 두 가지 이유가 있습니다.
- 먼저, 우리는 로봇 시스템이 인간 원격 조작자보다 더 능숙하고 하드웨어의 모든 잠재력을 활용하여 작업을 빠르고 원활하며 안정적으로 완료하기를 원합니다.
- 둘째, 고품질 시연에만 전적으로 의존하기보다는 로봇 시스템이 자동으로 경험을 축적하는 데 더 능숙해지기를 바랍니다.
원칙적으로 강화학습은 이 두 가지 능력을 동시에 제공할 수 있습니다.
최근에는 로봇 잡기 및 쌓기 기능, 인간이 지정한 보상으로 다양한 작업 학습, 다중 학습과 같은 다양한 응용 시나리오에서 대규모 로봇 강화 학습이 성공할 수 있음을 보여주는 몇 가지 유망한 개발이 있었습니다. - 태스킹 정책, 목표 기반 정책 학습, 로봇 탐색. 그러나 연구에 따르면 Transformer와 같은 강력한 모델을 훈련하는 데 강화 학습을 사용하면 대규모
Google DeepMind는 최근 다양한 실제 모델을 기반으로 모델을 변환하는 것을 목표로 하는 Q-Transformer를 제안했습니다. 세계 데이터 강력한 Transformer

- Paper: https://q-transformer.github.io/assets/q-transformer.pdf를 기반으로 대규모 로봇 학습과 현대적인 정책 아키텍처를 결합합니다.
- 프로젝트: https://q-transformer.github.io/
원칙적으로 Transformer를 사용하여 ResNets 또는 더 작은 컨볼루션과 같은 기존 아키텍처를 직접 대체하지만 신경망)은 개념적으로 간단합니다. 그러나 이 아키텍처를 효과적으로 활용할 수 있는 방식을 설계하는 것은 매우 어렵습니다. 대규모 모델은 대규모의 다양한 데이터 세트를 사용할 수 있는 경우에만 효과적일 수 있습니다. 소규모의 좁은 범위 모델은 이러한 기능이 필요하지 않으며 이로부터 이점을 얻습니다.
이전 연구에서는 시뮬레이션 데이터를 사용하여 이러한 데이터 세트를 생성했습니다. , 그러나 가장 대표적인 데이터는 현실 세계에서 나온 것입니다.
따라서 DeepMind는 이번 연구의 초점이 Transformer를 오프라인 강화학습을 통해 활용하고 기존에 수집된 대용량 데이터 세트를 통합하는 것이라고 밝혔습니다.
오프라인 강화학습 방법은 기존 데이터를 훈련에 활용하는 것이며, 그 목표는 주어진 데이터 세트에 대해 가장 효율적인 가능한 전략을 도출하는 것입니다. 물론 이 데이터 세트는 자동으로 수집된 추가 데이터를 통해 향상될 수도 있지만 훈련 프로세스는 데이터 수집 프로세스와 분리되어 대규모 로봇 애플리케이션을 위한 추가 워크플로를 제공합니다
Transformer 모델을 사용하여 구현됨 강화 학습에서 , 또 다른 큰 문제는 이러한 모델을 효과적으로 훈련할 수 있는 강화학습 시스템을 설계하는 것입니다. 효과적인 오프라인 강화 학습 방법은 시차 업데이트를 통해 Q-함수 추정을 수행하는 경우가 많습니다. Transformer는 이산 토큰 시퀀스를 모델링하므로 Q 함수 추정 문제는 이산 토큰 시퀀스 모델링 문제로 변환될 수 있으며 시퀀스의 각 토큰에 대해 적절한 손실 함수가 설계될 수 있습니다.
딥마인드가 채택한 방식은 액션 베이스의 기하급수적 폭발을 피하기 위한 차원별 이산화 방식입니다. 구체적으로, 행동 공간의 각 차원은 강화 학습에서 독립적인 시간 단계로 처리됩니다. 이산화의 다양한 구간은 다양한 작업에 해당합니다. 이러한 차원별 이산화 방식을 사용하면 보수적인 정규화와 함께 간단한 이산 동작 Q-학습 방법을 사용하여 분포 변환 상황을 처리할 수 있습니다.
DeepMind는 사용되지 않는 동작의 가치를 최소화하는 것을 목표로 하는 특수한 정규화를 제안합니다. 연구에 따르면 이 방법은 좁은 범위의 데모와 유사한 데이터를 효과적으로 학습할 수 있으며 탐색 노이즈가 있는 더 넓은 범위의 데이터도 학습할 수 있는 것으로 나타났습니다
마지막으로 몬테카를로와 n단계 회귀를 시간적 차이 백업과 결합한 하이브리드 업데이트 메커니즘도 사용합니다. 결과는 이 접근법이 대규모 로봇 학습 문제에 대한 Transformer 기반 오프라인 강화 학습 방법의 성능을 향상시킬 수 있음을 보여줍니다.
이 연구의 주요 기여는 Transformer 아키텍처를 기반으로 한 로봇의 오프라인 강화 학습 방법인 Q-Transformer입니다. Q-Transformer는 Q 값을 차원별로 토큰화하며 실제 데이터를 포함한 대규모의 다양한 로봇 공학 데이터 세트에 성공적으로 적용되었습니다. 그림 1은 Q-Transformer

DeepMind의 구성 요소를 보여줍니다. DeepMind는 엄격한 비교와 실제 검증을 목표로 시뮬레이션 실험과 대규모 실제 실험을 포함한 실험적 평가를 수행했습니다. 그 중 대규모 텍스트 기반 멀티 태스킹 학습 전략을 채택하고 Q-Transformer의 효과를 검증했습니다
실제 실험에서 그들이 사용한 데이터 세트에는 38,000개의 성공적인 데모와 20,000개의 A 시나리오가 포함되어 있었습니다. 자동 수집에 실패했습니다. 700개 이상의 작업에 대해 13개의 로봇이 데이터를 수집했습니다. Q-Transformer는 이전에 제안된 Decision Transformer와 같은 Transformer 기반 모델뿐만 아니라 대규모 로봇 강화 학습을 위해 이전에 제안된 아키텍처보다 성능이 뛰어납니다.
방법 개요
Transformer를 Q 학습에 사용하기 위해 DeepMind에서 취한 접근 방식은 작업 공간을 이산화하고 자동 회귀 처리하는 것입니다.
TD 학습을 사용하여 Q 기능을 학습하려면 고전적인 방법을 기반으로 합니다. on Bell Mann 업데이트 규칙
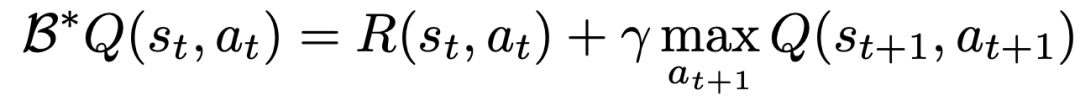
연구원들은 문제의 원래 MDP를 Q로 처리되는 각 행동 차원으로 변환하여 각 행동 차원에 대해 수행할 수 있도록 Bellman 업데이트를 수정했습니다. -단계 MDP.
구체적으로, 주어진 액션 차원 d_A에 대해 새로운 Bellman 업데이트 규칙은 다음과 같이 표현될 수 있습니다:
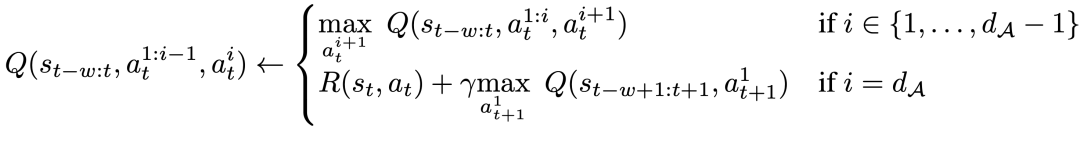
이는 각 중간 액션 차원에 대해 동일하게 주어진 상태의 경우, 다음 동작 차원을 최대화하고 마지막 동작 차원에는 다음 상태의 첫 번째 동작 차원을 사용합니다. 이러한 분해를 통해 Bellman 업데이트의 최대화가 다루기 쉬운 상태로 유지되는 동시에 원래 MDP 문제가 계속 해결될 수 있음을 보장합니다.
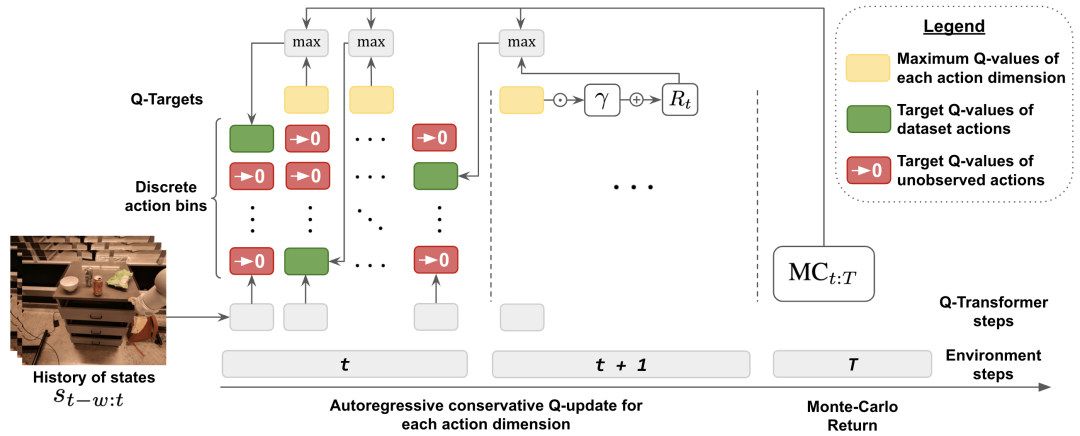
오프라인 학습 중 분포 변화를 고려하기 위해 DeepMind는 보이지 않는 행동의 가치를 최소화하는 간단한 정규화 기술도 도입합니다.
학습 속도를 높이기 위해 몬테카를로 리턴 방식도 사용했습니다. 이 접근 방식은 특정 에피소드(에피소드)에 대해 복귀를 사용할 뿐만 아니라 차원 최대화를 건너뛸 수 있는 n단계 복귀도 사용합니다.
실험 결과
실험에서 DeepMind는 Q-Transformer를 평가했습니다. 다양한 실제 작업. 동시에 작업당 100명의 인간 데모로 데이터를 제한했습니다.
데모에서는 데모 외에도 자동으로 수집되는 실패 이벤트 스니펫을 추가하여 데이터세트를 생성했습니다. 이 데이터세트에는 데모에서 나온 38,000개의 긍정적인 예와 자동으로 수집된 20,000개의 부정적인 예가 포함되어 있습니다.
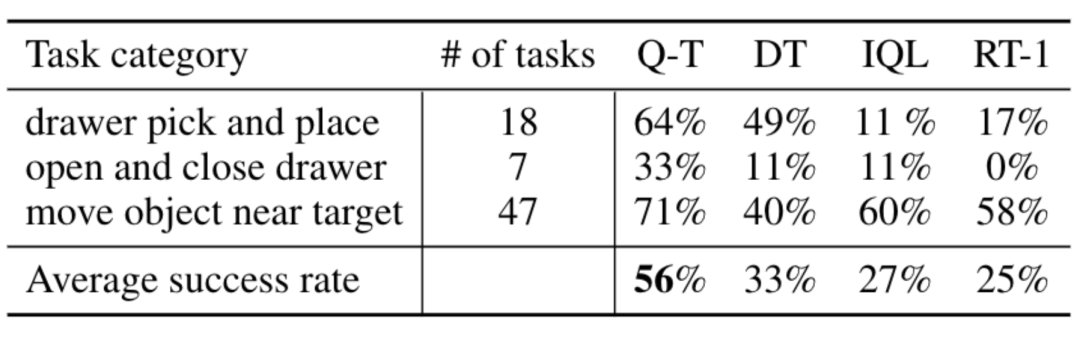

RT-1, IQL 및 Decision Transformer(DT)와 같은 기본 방법과 비교하여 Q-Transformer는 자동 이벤트 조각을 효과적으로 활용하여 서랍에서 항목을 집거나 놓기, 객체를 근처로 이동하는 등 스킬 사용 능력을 크게 향상시킬 수 있습니다. 대상, 서랍을 열고 닫습니다.
연구원들은 또한 어려운 시뮬레이션 개체 검색 작업에서 새로 제안된 방법을 테스트했습니다. 이 작업에서는 데이터의 약 8%만이 긍정적인 예이고 나머지는 노이즈로 가득 찬 부정적인 예였습니다.
이 작업에서 QT-Opt, IQL, AW-Opt 및 Q-Transformer와 같은 Q-학습 방법은 일반적으로 동적 프로그래밍을 활용하여 정책을 학습하고 최적화를 위한 부정적인 예를 활용할 수 있기 때문에 더 나은 성능을 발휘합니다.
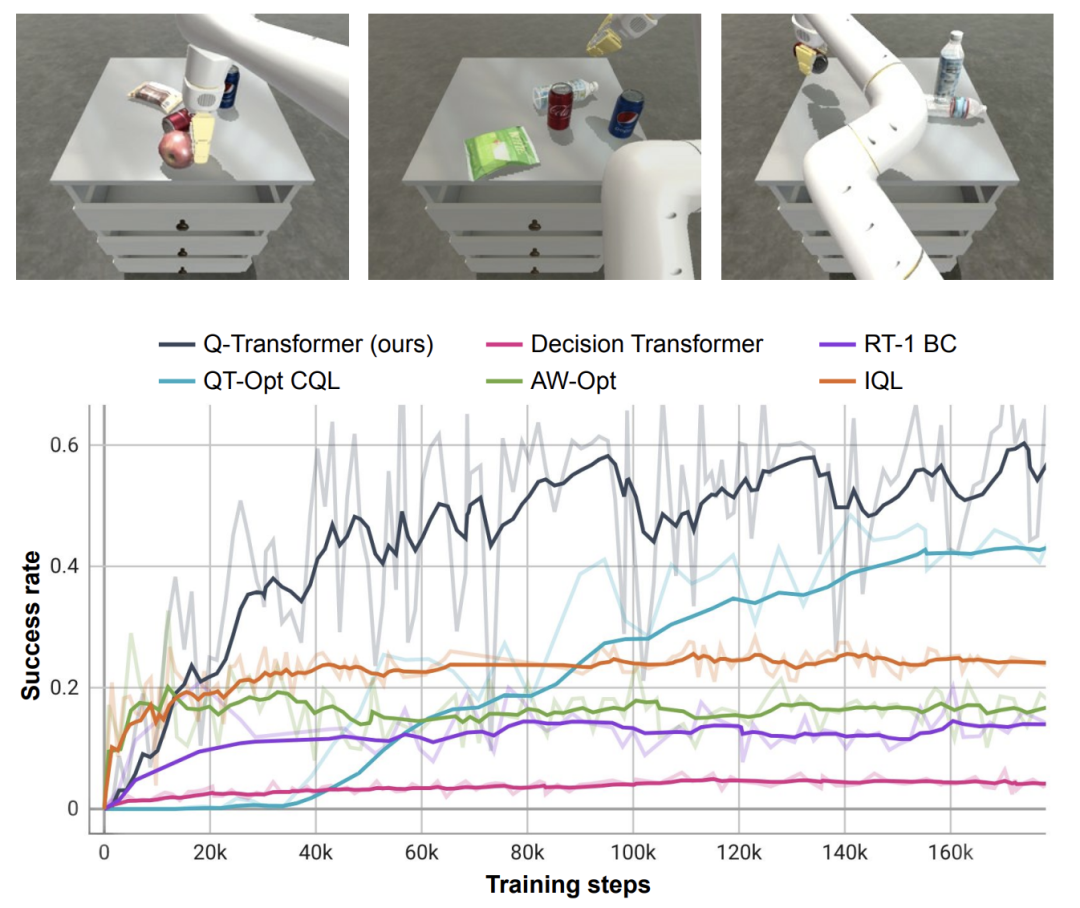
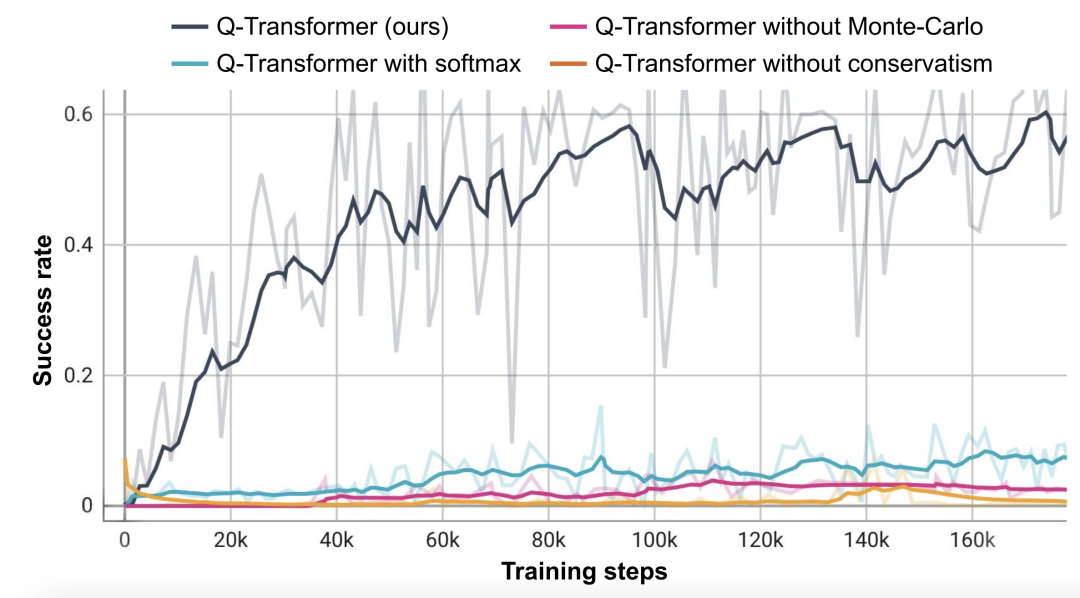
이 객체 검색 작업을 기반으로 연구원들은 절제 실험을 수행했으며 보수적 정규화와 MC 반환이 모두 성능을 유지하는 데 중요하다는 것을 발견했습니다. Softmax 정규화 프로그램으로 전환하면 정책이 데이터 배포에 너무 많이 제한되므로 성능이 훨씬 더 나빠집니다. 이는 여기서 DeepMind가 선택한 정규화가 이 작업에 더 잘 대처할 수 있음을 보여줍니다.
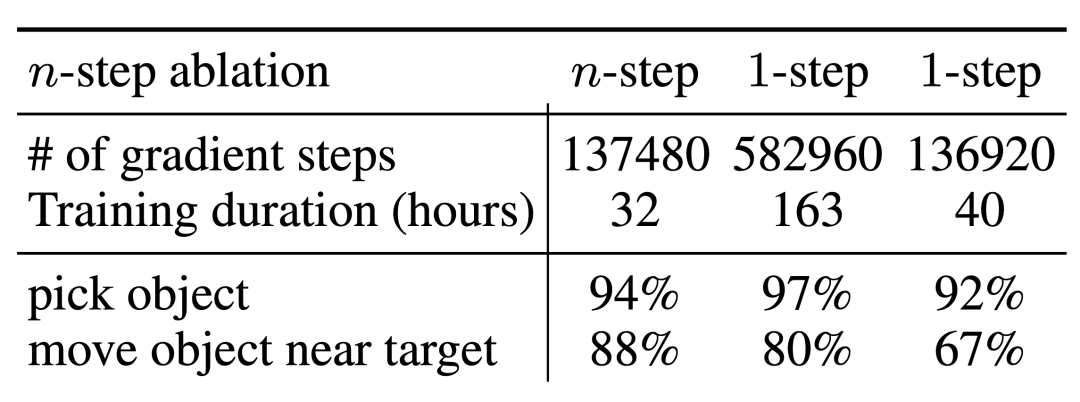
n단계 수익에 대한 제거 실험에서는 편향이 발생할 수 있지만 이 방법은 훨씬 적은 경사 단계에서 동등한 고성능을 달성하여 많은 문제를 효과적으로 처리할 수 있음을 발견했습니다.
연구원들은 또한 더 큰 데이터 세트에서 Q-Transformer를 실행해 보았습니다. 긍정적인 예의 수를 115,000개로, 부정적인 예의 수를 185,000개로 확장하여 300,000개의 이벤트 클립이 포함된 데이터 세트를 얻었습니다. 이 대규모 데이터 세트를 사용하여 Q-Transformer는 여전히 RT-1 BC 벤치마크

보다 훨씬 더 나은 학습과 성능을 발휘할 수 있었습니다. 마지막으로 Q-Transformer 훈련된 Q 함수를 어포던스 모델( 어포던스 모델)로 사용했습니다. SayCan
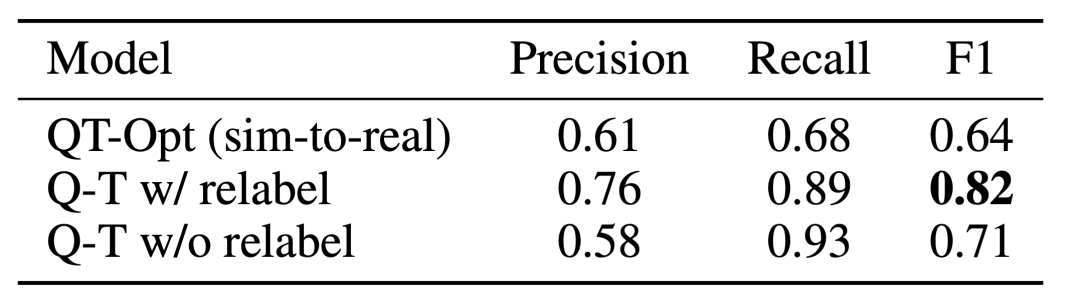
Q-Transformer와 유사한 언어 플래너와 결합 어포던스 추정의 효과는 더 이상 샘플링되지 않는 경우 QT-Opt를 사용하여 훈련된 이전 Q 함수로 인한 것입니다. 훈련 중에 현재 작업의 부정적인 예로 표시되며 효과는 훨씬 더 좋을 수 있습니다. Q-Transformer에는 QT-Opt 훈련에 사용되는 시뮬레이션-실제 훈련이 필요하지 않으므로 적합한 시뮬레이션이 부족한 경우 Q-Transformer를 사용하는 것이 더 쉽습니다.
완전한 "계획 + 실행" 시스템을 테스트하기 위해 Q-Transformer를 사용하여 어포던스 추정과 실제 정책 실행을 동시에 실험한 결과 이전 QT-Opt와 RT-1 조합보다 성능이 뛰어난 것으로 나타났습니다.
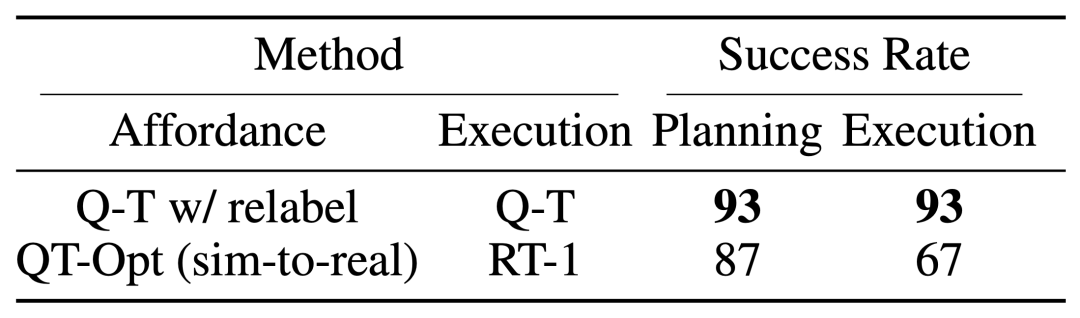
주어진 이미지의 작업 어포던스 값 예시에서 볼 수 있듯이 Q-Transformer는 다운스트림 "계획 + 실행" 프레임워크에서 고품질 어포던스 값을 제공할 수 있습니다
부탁드립니다 자세한 내용은 원본 기사를 읽어보세요
위 내용은 Google DeepMind: 대규모 모델과 강화 학습을 결합하여 로봇이 세상을 인식할 수 있는 지능형 두뇌 생성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!