
4 H100이 필요하지 않습니다! 340억 개의 매개변수 Code Llama는 Mac에서 실행 가능하며 초당 20개의 토큰으로 코드 생성에 가장 적합합니다.

- PHPz앞으로
- 2023-09-19 13:05:01963검색
오픈 소스 커뮤니티의 개발자인 Georgi Gerganov는 M2 Ultra에서 전체 F16 정밀도로 34B Code Llama 모델을 실행할 수 있으며 추론 속도가 20 토큰/초를 초과한다는 사실을 발견했습니다.
M2 Ultra의 대역폭은 800GB/s이며, 다른 사람들은 일반적으로 이를 달성하기 위해 4개의 고급 GPU를 사용해야 합니다
이에 대한 실제 대답은 추측적 샘플링입니다.
George의 발견은 즉시 인공 지능 업계의 거물들 사이에서 토론을 촉발시켰습니다
Karpathy는 리트윗하고 "LLM의 추측 실행은 탁월한 추론 시간 최적화입니다."라고 말했습니다.

추론을 가속화하는 "추측 샘플링"
이 예에서 Georgi는 Q4 7B 양자 드래프트 모델(즉, Code Llama 7B)을 사용하여 추측 디코딩을 수행한 다음 M2 Ultra에서 Code Llama34B를 사용했습니다. 생성하다.
간단히 말하면 '소형 모델'로 초안을 만든 뒤 '대형 모델'로 확인하고 수정하는 방식으로 전체 작업 속도를 높일 수 있습니다.

GitHub 주소: https://twitter.com/ggerganov/status/1697262700165013689
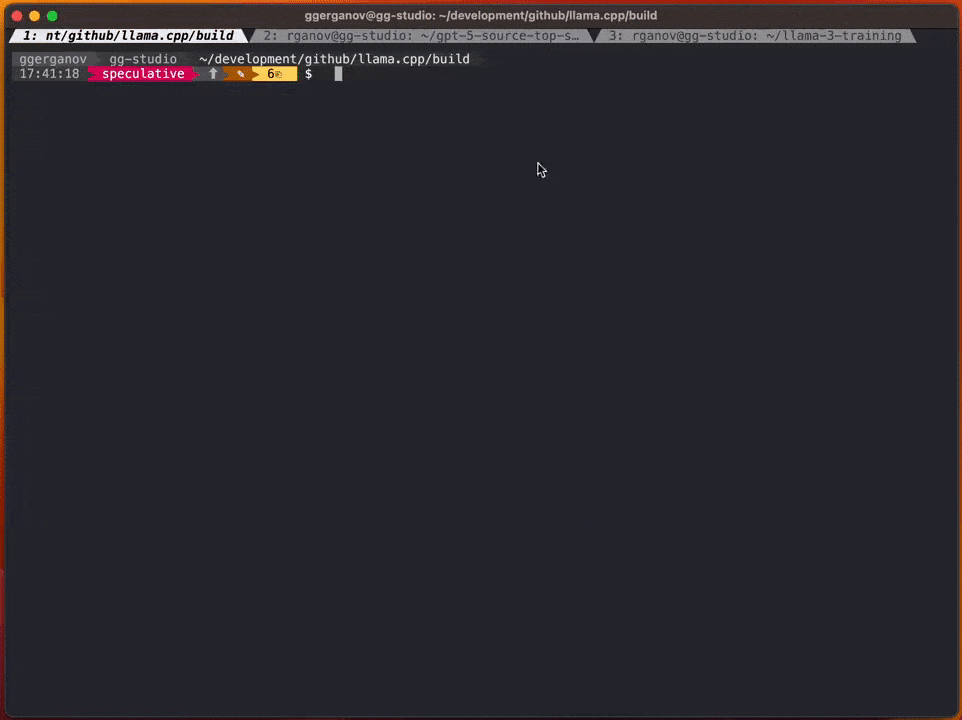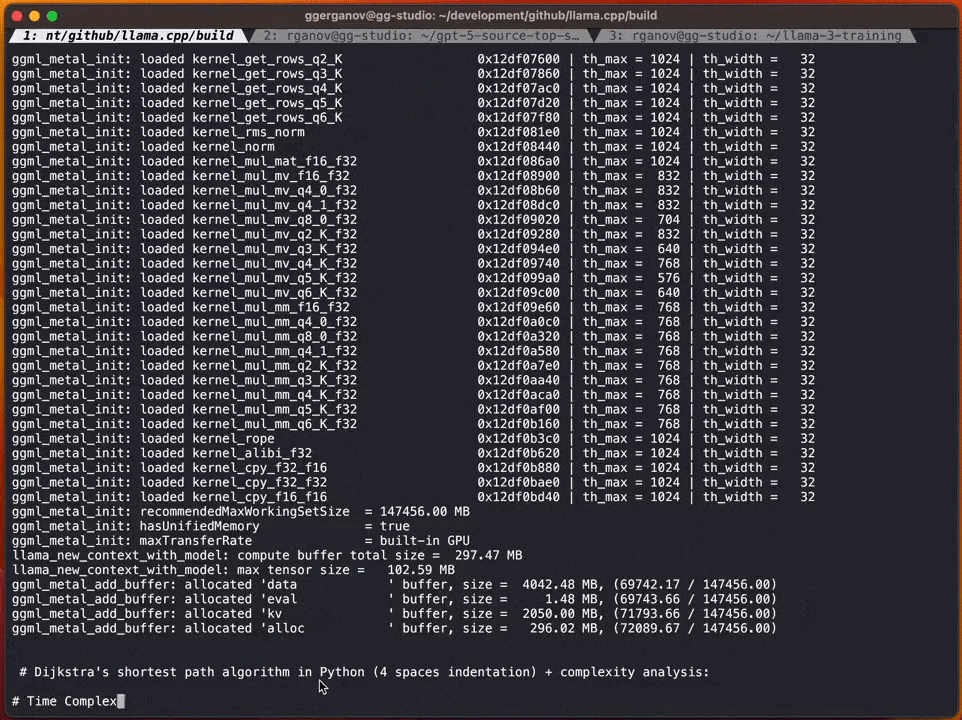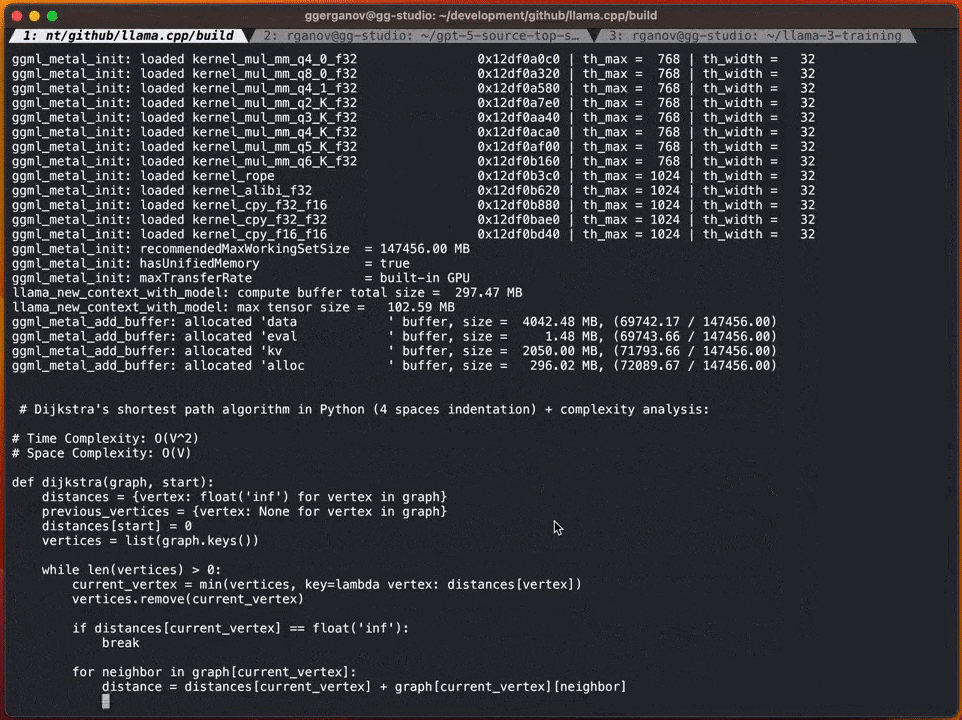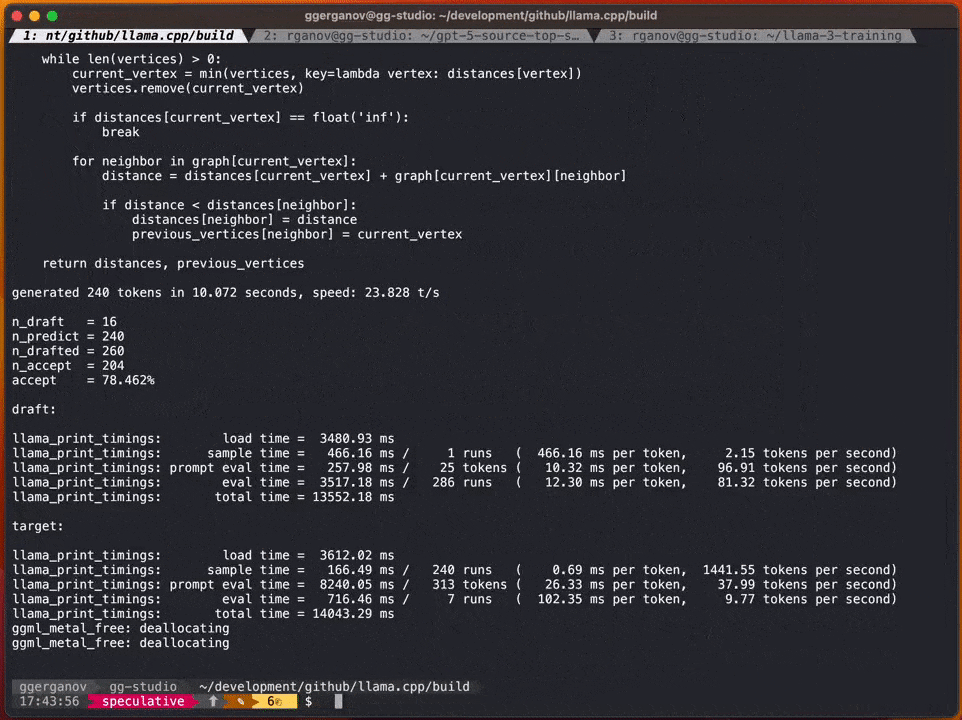
Georgi에 따르면 이 모델의 속도는 다음과 같습니다.
F 16 34B: 약. 초당 10개 토큰
다시 작성해야 할 내용은 다음과 같습니다. Q4 7B: 초당 ~80개 토큰
다음은 추측 샘플링을 사용하지 않는 표준 F16 샘플링 예입니다.
추측적 샘플링 전략을 추가하면 속도는 초당 약 20마르크에 도달할 수 있습니다
Georgi에 따르면 콘텐츠 생성 속도는 다를 수 있습니다. 하지만 이 접근 방식은 초안 모델을 통해 대부분의 어휘를 정확하게 추측할 수 있기 때문에 코드 생성 측면에서 매우 효과적인 것으로 보입니다.
"문법 샘플링"을 사용하는 사용 사례도 이로부터 큰 이점을 얻을 가능성이 높습니다

Speculation 샘플링은 어떻게 빠른 추론을 가능하게 합니까?
Karpathy는 Google Brain, UC Berkeley 및 DeepMind의 세 가지 이전 연구를 바탕으로 설명했습니다.

논문을 보려면 다음 링크를 클릭하세요: https://arxiv.org/pdf/2211.17192.pdf

논문 주소: https://arxiv.org/pdf/ 1811.03115.pdf

문서 주소: https://arxiv.org/pdf/2302.01318.pdf
이는 다음과 같은 비직관적인 관찰에 따라 달라집니다. 입력 토큰 시간은 K개의 입력 토큰에 대해 LLM을 일괄 전달하는 데 필요한 시간과 같습니다(K는 생각보다 큽니다).
이 직관적이지 않은 사실은 샘플링이 메모리에 의해 심각하게 제한되고 대부분의 "작업"이 계산되지 않지만 Transformer의 가중치는 처리를 위해 VRAM에서 온칩 캐시로 읽혀지기 때문입니다.

모든 가중치를 읽는 작업을 수행하려면 이를 전체 배치의 입력 벡터에 적용하는 것이 좋습니다.
이 사실을 순진하게 활용하여 K 토큰을 한 번에 샘플링할 수 없는 이유는 모든 N 토큰이 이는 모두 N-1단계에서 샘플링한 토큰에 따라 다릅니다. 이는 직렬 종속성이므로 기본 구현은 왼쪽에서 오른쪽으로 하나씩 진행됩니다.
이제 영리한 아이디어는 작고 저렴한 초안 모델을 사용하여 먼저 K 마커로 구성된 후보 시퀀스("초안")를 생성하는 것입니다. 그런 다음 이 모든 정보를 큰 모델에 함께 일괄 공급합니다.
위 방법에 따르면 이는 토큰 하나만 입력하는 것과 거의 비슷합니다.
그런 다음 왼쪽에서 오른쪽으로 모델을 검사하고 샘플 토큰으로 예측한 로짓을 검사합니다. 초안과 일치하는 샘플을 사용하면 즉시 다음 토큰으로 이동할 수 있습니다.
이견이 있는 경우 초안 모델을 포기하고 일회성 작업(초안 모델 샘플링 및 후속 토큰에 대한 전달 수행)을 수행하는 비용을 부담합니다.
이것은 실제로 잘 작동합니다. 그 이유는 대부분의 경우 초안 토큰이 허용되며, 이는 간단한 토큰이므로 더 작은 초안 모델이라도 이를 허용할 수 있기 때문입니다.
이러한 단순 토큰이 승인되면 이 부분은 건너뛰겠습니다. 대형 모델이 동의하지 않는 난이도 토큰은 원래 속도로 "되돌아가지만" 실제로는 추가 작업으로 인해 속도가 느려집니다.
요약하자면, LLM은 추론 중에 메모리가 제한되어 있기 때문에 이 이상한 트릭이 작동합니다. "배치 크기 1"의 경우 관심 있는 단일 시퀀스가 샘플링되는데, 이는 대부분의 "로컬 LLM" 사용 사례의 경우입니다. 게다가 대부분의 토큰은 "단순"합니다.
HuggingFace의 공동 창업자는 1년 반 전에는 340억 개의 매개변수 모델이 데이터 센터 외부에서는 매우 크고 관리하기 어려워 보였다고 말했습니다. 이제는 노트북 하나만으로 쉽게 처리할 수 있습니다.

오늘날의 LLM은 단일 혁신 지점이 아니라 효과적으로 함께 작동하기 위해 여러 중요한 구성 요소가 필요한 시스템입니다. 추측적 디코딩은 시스템 관점에서 생각하는 데 도움이 되는 훌륭한 예입니다.
위 내용은 4 H100이 필요하지 않습니다! 340억 개의 매개변수 Code Llama는 Mac에서 실행 가능하며 초당 20개의 토큰으로 코드 생성에 가장 적합합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!