
Interspeech 2023에 여러 논문이 선정되었으며 Huoshan Speech는 다양한 유형의 실제 문제를 효과적으로 해결했습니다.

- 王林앞으로
- 2023-09-18 11:09:081077검색
최근 Interspeech 2023에 Volcano Voice 팀의 여러 논문이 선정되어 짧은 비디오 음성 인식, 교차 언어 음색 및 스타일, 구두 유창성 평가 등 다양한 응용 분야의 혁신적인 혁신을 다루고 있습니다. 인터스피치(Interspeech)는 국제음성통신협회(ISCA)가 주관하는 음성 연구 분야 최고 학회 중 하나로, 세계 최대 규모의 종합 음성 신호 처리 행사로도 알려지며 전 세계 언어 분야 사람들의 폭넓은 관심을 받아왔다.

Interspeech2023이벤트 사이트
단문 비디오 음성 인식 개선을 위한 무작위 문장 연결 기반 데이터 증강(Random Utterance Concatenation Based Data Augmentation for Improving Short-video Speech Recognition)
보통 예를 들어, 엔드투엔드 자동 음성 인식(ASR) 프레임워크의 한계 중 하나는 훈련 길이와 테스트 문장의 길이가 일치하지 않으면 성능에 영향을 미칠 수 있다는 것입니다. 본 논문에서 Huoshan Speech 팀은 짧은 비디오 ASR 작업에서 훈련 및 테스트 문장 길이 불일치 문제를 완화하기 위한 프런트 엔드 데이터 향상으로 즉각적인 무작위 문장 연결(RUC)을 기반으로 하는 데이터 향상 방법을 제안합니다.
특히 팀은 다음과 같은 관찰이 혁신적인 실천에 중요한 역할을 한다는 것을 발견했습니다. 일반적으로 짧은 비디오 자발적 음성의 훈련 문장은 사람이 전사한 문장보다 훨씬 짧습니다(평균 약 3초). 활동 감지 프런트엔드에서 생성된 테스트 문은 훨씬 더 깁니다(평균 약 10초). 따라서 이러한 불일치는 성능 저하로 이어질 수 있습니다.
Volcano Speech 팀은 실증적 목적을 위해 15개 언어의 다중 클래스 ASR 모델을 사용했다고 밝혔습니다. 이들 언어에 대한 데이터 세트는 1,000~30,000시간 범위입니다. 모델 미세 조정 단계에서는 여러 데이터에서 실시간으로 샘플링하고 접합한 데이터도 추가했습니다. 증강되지 않은 데이터와 비교하여 이 방법은 모든 언어에서 5.72%의 평균 상대 단어 오류율 감소를 달성합니다.
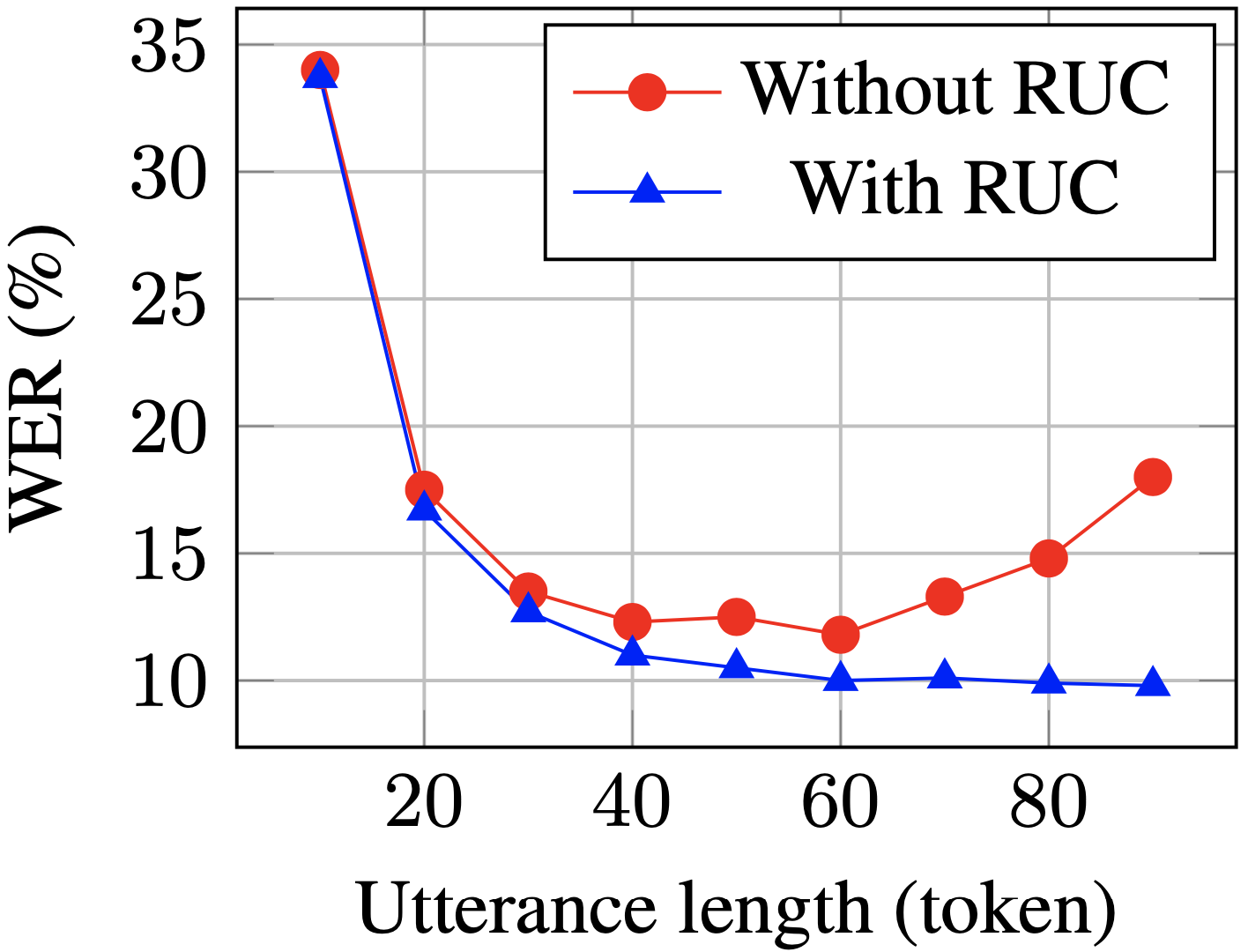
테스트 세트의 긴 문장의 WER은 RUC(파란색 대 빨간색)로 훈련한 후 크게 감소합니다. )
실험적 관찰에 따르면 RUC 방법은 긴 문장의 인식 능력을 크게 향상시키는 반면, 짧은 문장의 성능은 저하하지 않습니다. 추가 분석에서는 제안된 데이터 증대 방법이 길이 정규화 변화에 대한 ASR 모델의 민감도를 줄일 수 있다는 사실을 발견했습니다. 이는 ASR 모델이 다양한 환경에서 더욱 강력하다는 것을 의미할 수 있습니다. 요약하자면, RUC 데이터 향상 방법은 작동이 간단하지만 그 효과는 상당합니다
음성학적 및 운율 인식을 기반으로 한 유창성 점수 비원어민 유창성 점수를 위한 자기 지도 학습 접근 방식
중요한 것 중 하나 제2언어 학습자의 언어 능력을 평가하는 기준은 말하기 유창성이다. 유창한 발음이란 말을 할 때 멈춤, 머뭇거림, 자기 교정 등의 비정상적인 현상이 많이 발생하지 않고 쉽고 정상적으로 말을 할 수 있는 능력을 주요 특징으로 합니다. 대부분의 제2외국어 학습자는 일반적으로 원어민보다 느리게 말하고 더 자주 멈춥니다. Volcano Speech 팀은 음성 유창성을 평가하기 위해 음성과 운율을 기반으로 한 자기주도 모델링 방법을 제안했습니다. 구체적으로 사전 학습 단계에서 모델의 입력 시퀀스 특성(음향 특성, 음소 ID, 음소 지속 시간)을 고려했습니다. 마스킹되고, 마스킹된 특징이 모델에 입력되며, 문맥 관련 인코더를 사용하여 타이밍 정보를 기반으로 마스킹된 부분의 음소 ID 및 음소 지속 시간 정보를 복원함으로써 모델이 더욱 강력한 발화 및 운율을 갖게 됩니다. 표현 능력.
이 솔루션은 시퀀스 모델링 프레임워크에서 원래 기간, 음소 및 음향 정보의 세 가지 기능을 마스크하고 재구성하여 기계가 유창성 점수에 더 잘 사용되는 컨텍스트의 음성 및 기간 표현을 자동으로 학습할 수 있도록 합니다.
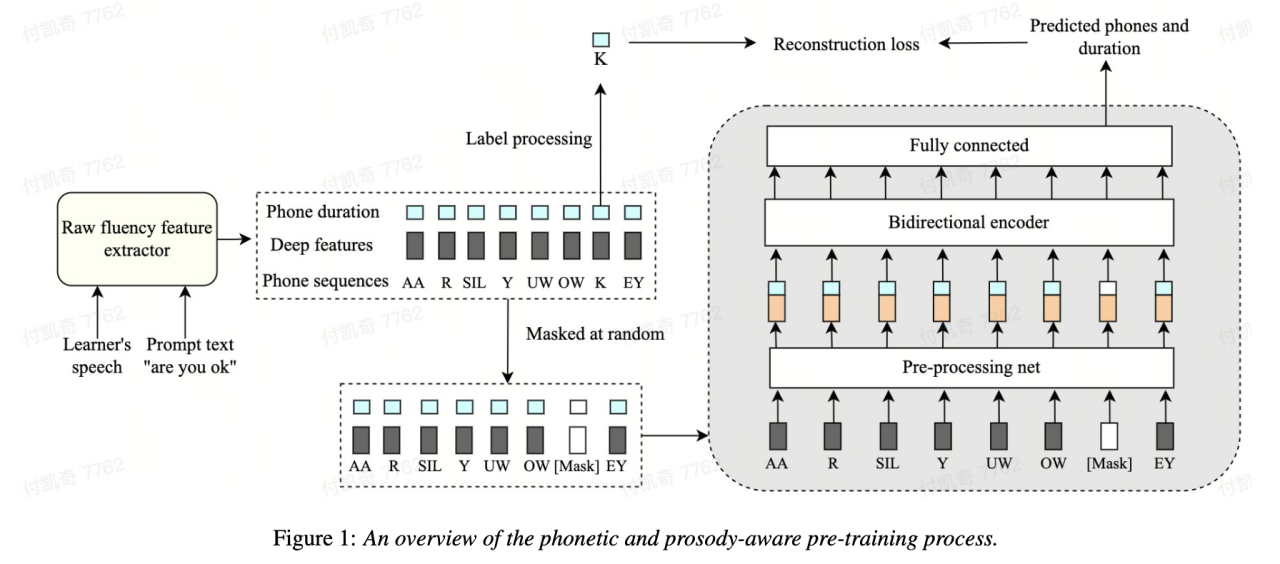
0.833에 도달했습니다. 전문가와 전문가의 상관관계는 0.831입니다. 오픈 소스 데이터 세트에서 기계 예측 결과와 인간 전문가 점수 간의 상관 관계는 0.835에 도달했으며 성능은 이 작업에 대해 과거에 제안된 일부 자기 감독 방법을 초과했습니다. 적용 시나리오 측면에서 이 방법은 구술 시험, 다양한 온라인 구술 연습 등 자동 유창성 평가가 필요한 시나리오에 적용할 수 있습니다. 자동 발음 평가에서 비원어민 음성의 기여도 분리
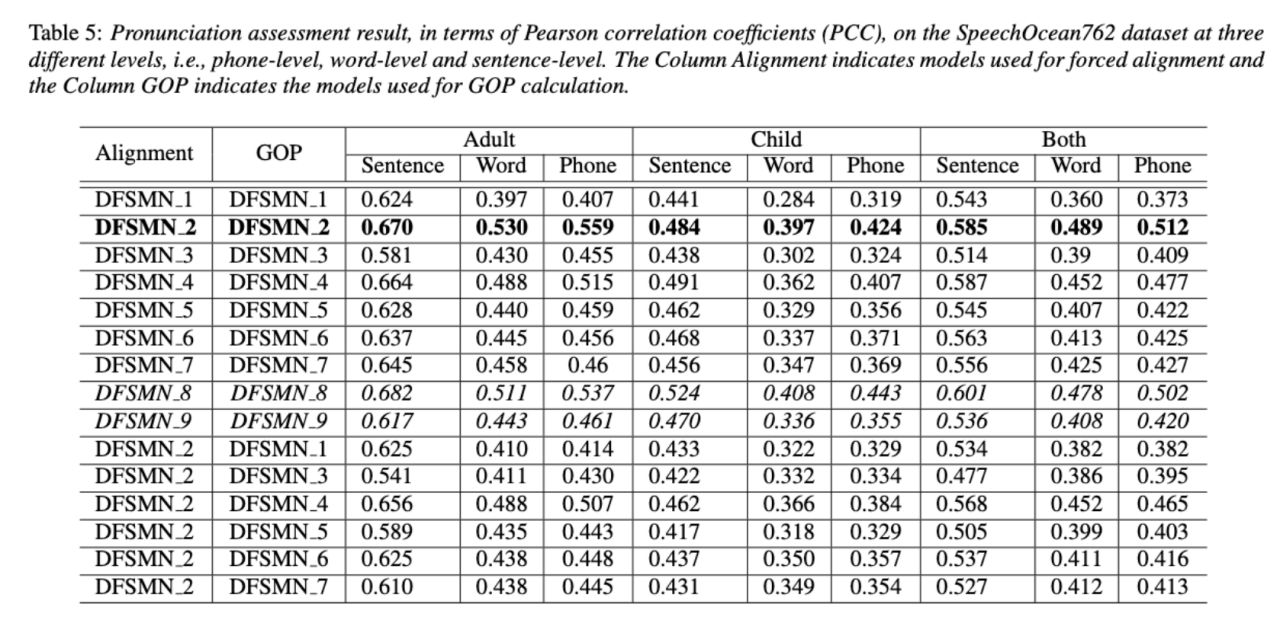
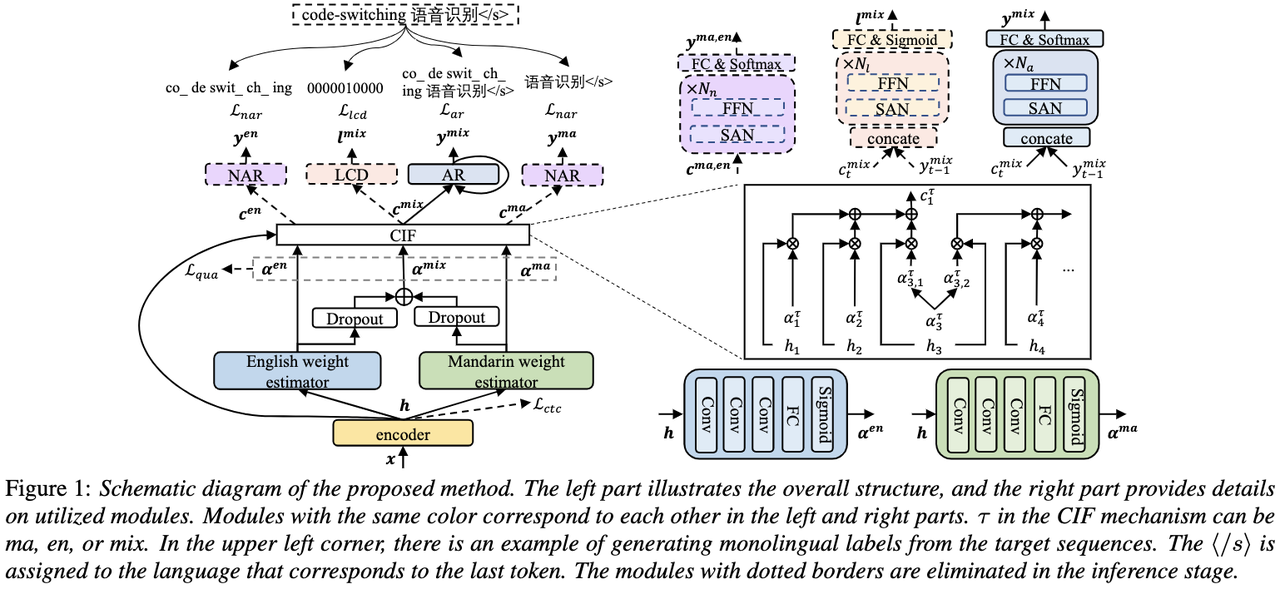
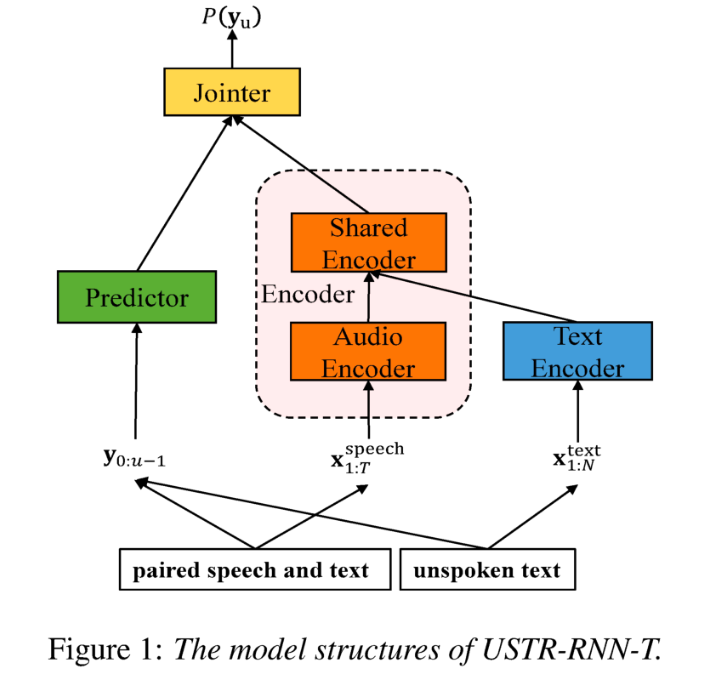
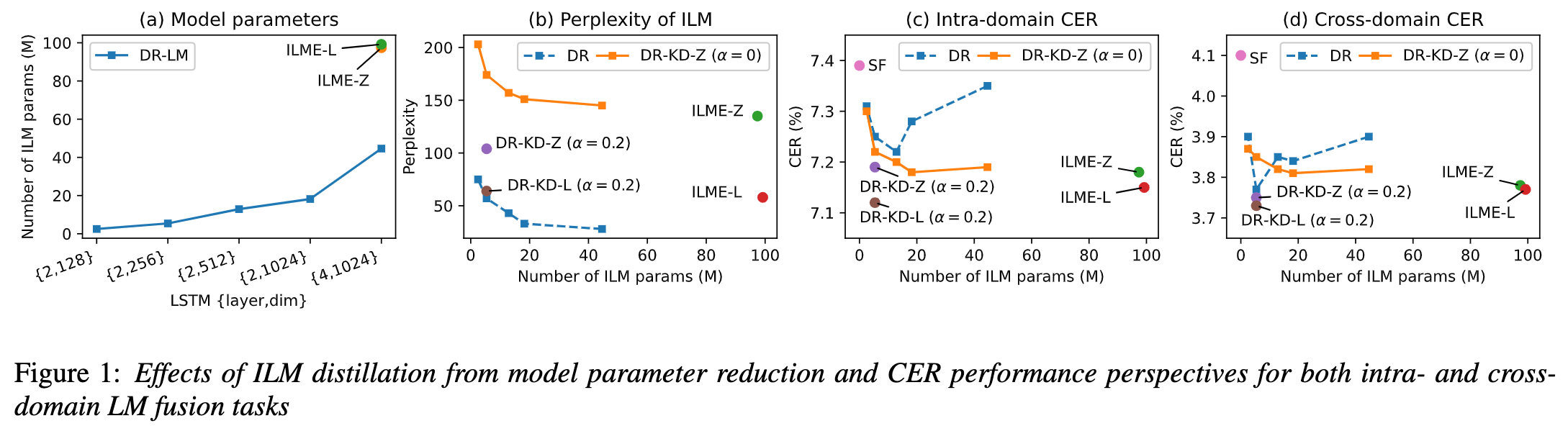
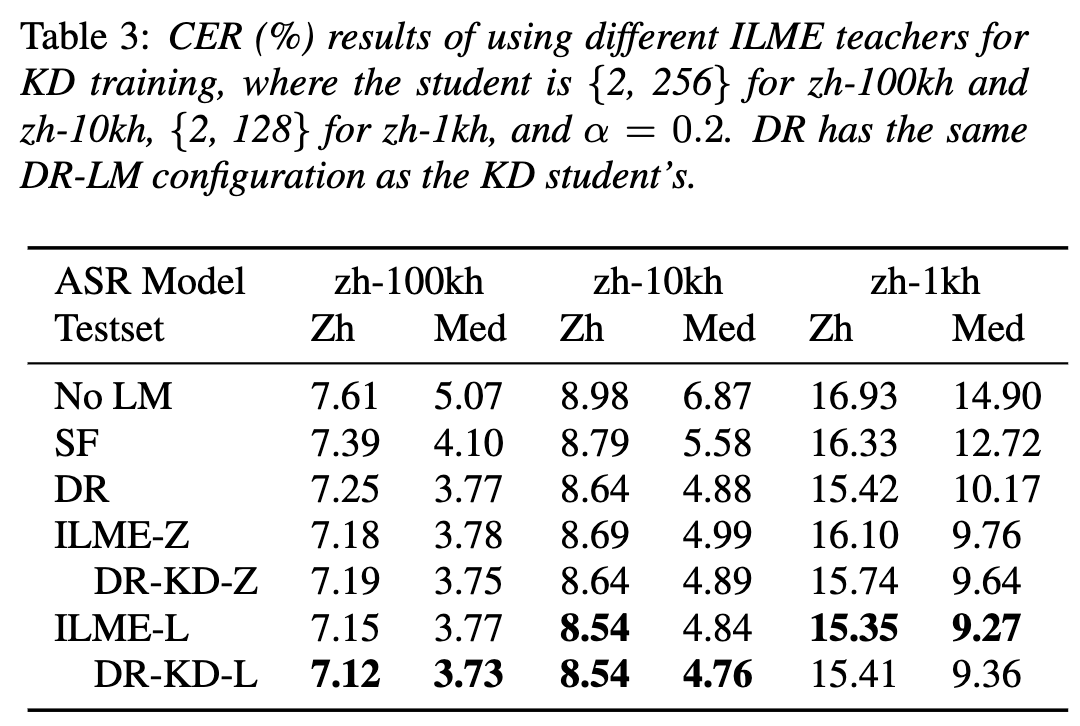
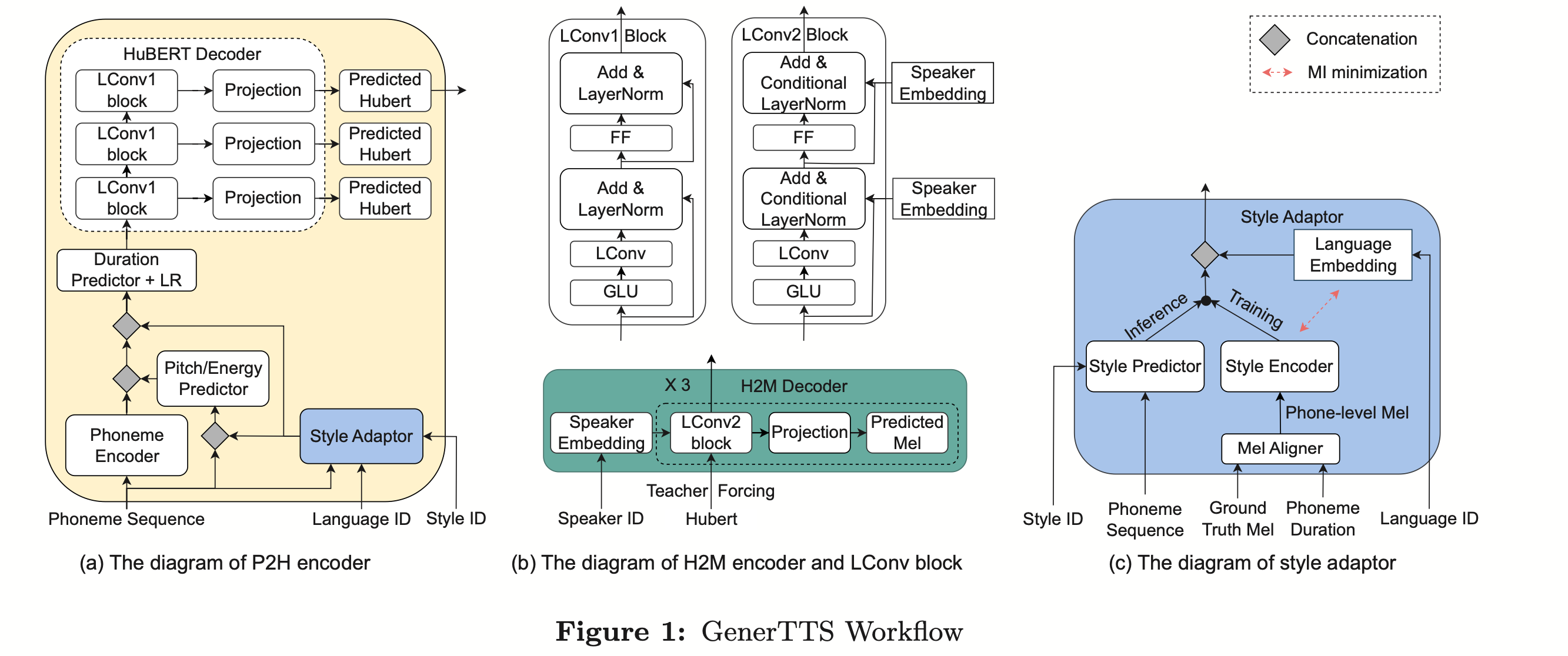
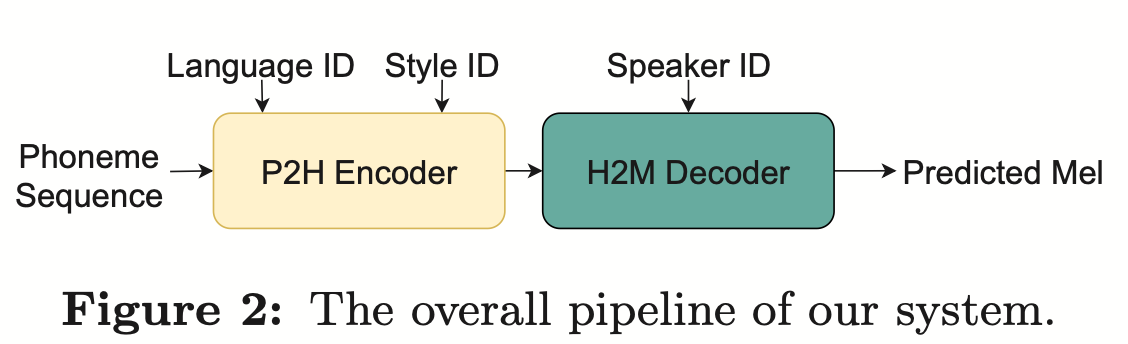
(자동 발음 평가에서 비원어민 음성의 기여도 분리)비원어민 발음 평가의 기본 아이디어는 학습자 발음과 원어민 발음의 편차를 수량화하는 것입니다. 따라서 발음 평가에 사용되는 초기 음향 모델은 일반적으로 훈련을 위해 대상 언어 데이터만 사용하지만 최근 일부 연구에서는 비원어민 발음을 데이터에 통합하는 것이 모델 훈련에 통합됩니다. 비원어민 음성을 L2 ASR에 통합하는 목적과 비원어민 평가 또는 발음 오류 감지 사이에는 근본적인 차이가 있습니다. 전자의 목표는 최적의 ASR을 달성하기 위해 가능한 한 비원어민 데이터에 모델을 적용하는 것입니다. 후자는 두 가지 관점의 균형을 요구합니다. 즉, 비원어민 음성의 인식 정확도가 높고 비원어민 발음의 발음 수준에 대한 객관적인 평가가 필요합니다. 화산 음성 팀은 발음 평가에서 비원어민 음성의 기여도를 두 가지 관점, 즉 정렬 정확도와 평가 성능에서 연구하는 것을 목표로 합니다. 이를 위해 그들은 위의 그림과 같이 음향 모델을 훈련할 때 서로 다른 데이터 조합과 텍스트 전사 형식을 설계했습니다 위 두 표는 각각 음향 모델 성능의 다양한 조합에 대한 정렬 정확도와 평가를 보여줍니다. . 실험 결과는 음향 모델 훈련 중에 수동으로 주석이 달린 음소 시퀀스가 있는 비원어민 언어 데이터만 사용하면 비원어민 음성을 정렬하고 발음 평가에서 가장 높은 정확도를 얻을 수 있음을 보여줍니다. 특히 훈련에서 모국어 데이터 절반과 비원어 데이터(인간 주석이 달린 음소 시퀀스)를 절반으로 혼합하는 것은 약간 더 나쁠 수 있지만 인간 주석이 달린 음소 시퀀스와 함께 비원어 데이터만 사용하는 것과 비슷합니다. 게다가 위의 혼합 사례는 모국어 데이터로 발음을 평가할 때 더 잘 수행됩니다. 제한된 리소스로 10시간의 비모국어 데이터를 추가하면 모국어 데이터만 사용한 음향 모델 훈련에 비해 사용된 텍스트 전사 유형에 관계없이 정렬 정확도와 평가 성능이 크게 향상되었습니다. 이 연구는 음성 평가 분야의 데이터 응용에 중요한 지침이 됩니다. 엔드 투 엔드 음성 인식에서 비피크 CTC프레임 분류기 최적화(프레임 개선-)를 통해 타임스탬프 문제를 해결합니다. level Classifier for Word Timing with Non-peaky CTC in End-to-End 자동 음성 인식) 자동 음성 인식(ASR) 분야의 엔드 투 엔드 시스템은 하이브리드 시스템에 필적하는 성능을 보여주었습니다. ASR의 부산물인 타임스탬프는 특히 자막 생성 및 계산 지원 발음 훈련과 같은 시나리오에서 매우 중요합니다. 이 문서는 타임스탬프를 얻기 위해 엔드투엔드 시스템에서 프레임 수준 분류기를 최적화하는 것을 목표로 합니다. . 이에 팀에서는 프레임 수준 분류기를 훈련하기 위해 CTC(Connectionist Temporal Classification) 손실을 도입했으며, CTC의 스파이크 현상을 완화하기 위해 레이블 사전 정보를 도입했습니다. 또한 Mel 필터의 출력을 ASR과 결합했습니다. 인코더를 입력 기능으로 사용합니다. 내부 중국어 실험에서 이 방법은 단어 타임스탬프 200ms에서 95.68%/94.18%의 정확도를 달성한 반면, 기존 하이브리드 시스템은 93.0%/90.22%에 불과했습니다. 또한 이전의 엔드 투 엔드 접근 방식과 비교하여 팀은 7개 내부 언어에서 4.80%/8.02%의 절대적인 성능 향상을 달성했습니다. 이 실험은 LibriSpeech에 대해서만 수행되었지만 프레임별 지식 증류 접근 방식을 통해 단어 타이밍의 정확성도 더욱 향상되었습니다. 이 연구 결과는 라벨 우선순위를 도입하고 다양한 수준의 기능을 융합함으로써 엔드투엔드 음성 인식 시스템의 타임스탬프 성능을 효과적으로 최적화할 수 있음을 보여줍니다. 내부 중국어 실험에서 이 방법은 하이브리드 시스템 및 이전의 엔드투엔드 방법과 비교하여 상당한 개선을 이루었습니다. 또한 이 방법은 지식 증류 방법을 적용하여 다국어에 대한 명백한 이점을 보여 주며 더욱 향상된 단어를 제공합니다. 타이밍 정확성. 이러한 결과는 자막 생성, 발음 훈련 등의 활용에 큰 의미가 있을 뿐만 아니라, 자동 음성 인식 기술 개발에 유용한 탐색 방향을 제시한다. 언어별 음향 경계 학습 기반 중국어-영어 혼합 음성 인식(Language-special Acoustic Boundary Learning for Mandarin-English Code-switching Speech Recognition ) 재작성된 내용: 우리 모두 알고 있듯이 코드 스위칭(CS의 주요 목표)은 서로 다른 언어나 기술 분야 간의 효과적인 의사소통을 촉진하는 것입니다. CS는 문장에서 두 개 이상의 언어를 교대로 사용해야 하지만 여러 언어의 단어나 구문을 병합하면 음성 인식에 오류와 혼란이 발생할 수 있으며 이로 인해 CSSR(코드 전환 음성 인식)이 더욱 어려워집니다. 임무 일반적인 엔드투엔드 ASR 모델은 인코더, 디코더 및 정렬 메커니즘으로 구성됩니다. 기존 End-to-End CSASR 모델의 대부분은 인코더 및 디코더 구조 최적화에만 초점을 맞추고 정렬 메커니즘의 언어 관련 설계가 필요한지 거의 논의하지 않습니다. 기존 작업의 대부분은 중국어와 영어 혼합 시나리오의 모델링 단위로 중국어 문자와 영어 하위 단어의 혼합을 사용합니다. 표준 중국어 문자는 일반적으로 표준 중국어의 단일 음절을 나타내며 명확한 음향 경계를 갖는 반면, 영어 하위 단어는 음향 지식을 참조하지 않고 얻어지므로 음향 경계가 모호할 수 있습니다. CSASR 시스템에서 중국어와 영어 사이의 좋은 음향 경계(정렬)를 얻기 위해서는 언어 관련 음향 경계 학습이 매우 필요합니다. 따라서 우리는 CIF 모델을 개선하고 CSASR 작업을 위한 언어별 음향 경계 학습 방법을 제안했습니다. 모델 아키텍처에 대한 자세한 내용은 아래 그림을 참조하세요 모델은 인코더, LSWE(언어 차별화 가중치 추정기), CIF 모듈, AR(자동 회귀) 디코더, 비자동 회귀( NAR) 디코더 및 언어 변경 감지(LCD) 모듈. 인코더, 자동회귀 디코더 및 CIF의 계산 프로세스는 원래 CIF 기반 ASR 방법과 동일합니다. 언어별 가중치 추정기는 비자동회귀(NAR) 디코더의 모델링을 완료합니다. LCD(언어 변경 감지) 모듈은 모델 훈련을 지원하도록 설계되었으며 더 이상 디코딩 단계에 유지되지 않습니다. 실험 결과에 따르면 이 방법은 오픈 소스 중국어-영어의 두 테스트 세트 에서 새로운 결과를 달성한 것으로 나타났습니다. 혼합 데이터 세트 SEAME. SOTA 효과는 각각 16.29% 및 22.81% MER입니다. 더 큰 데이터 볼륨에 대한 이 방법의 효과를 추가로 검증하기 위해 팀은 9,000시간의 내부 데이터 세트에 대한 실험을 수행했으며 최종적으로 7.9%의 상대적 MER 이득을 달성했습니다. 이 논문은 CSASR 과제에서 언어 차별화를 위한 음향 경계 학습에 대한 첫 번째 작업이기도 한 것으로 이해됩니다. : 통합 표현 및 일반 텍스트 기반 ASR 도메인 적응(Transducer의 통합 음성 텍스트 표현을 사용하는 텍스트 전용 도메인 적응)우리 모두 알고 있듯이 도메인 마이그레이션 ASR에서는 항상 매우 중요한 작업이지만, 대상 도메인에서 쌍을 이루는 음성 데이터를 얻는 것은 시간과 비용이 많이 들기 때문에 많은 작품에서는 인식 효과를 높이기 위해 대상 도메인과 관련된 텍스트 데이터를 사용합니다. 전통적인 방법 중 TTS는 훈련 주기와 관련 데이터의 저장 비용을 증가시키는 반면, ILME 및 Shallow fusion과 같은 방법은 추론의 복잡성을 증가시킵니다. 이 작업을 기반으로 팀은 RNN-T를 기반으로 Encoder를 Audio Encoder와 Shared Encoder로 나누고 Text Encoder를 도입하여 RNN을 사용한 Shared Encoder 학습을 통해 음성 신호와 유사한 표현을 학습했습니다. -T 손실을 USTR(Unified Speech-Text Representation)이라고 합니다. "텍스트 인코더 부분의 경우 문자 시퀀스, 전화 시퀀스 및 하위 단어 시퀀스를 포함한 다양한 유형의 표현을 탐색했습니다. 최종 결과는 전화 시퀀스가 가장 좋은 효과가 있음을 보여주었습니다. 훈련 방법에 대해서는 이 기사에서 방법을 탐색합니다. 주어진 RNN- T 모델의 다단계 훈련 방법과 완전 무작위 초기화를 통한 단일 단계 훈련 방법을 기반으로 합니다. " (Knowledge Distillation Approach for Efficient Internal Language Model Estimation) ILME(내부 언어 모델 추정)는 기존의 얕은 융합에 비해 엔드 투 엔드 ASR 언어 모델 융합에서 효율성이 입증되었지만 ILME는 내부 언어 모델 계산을 추가로 도입하여 추론 비용을 높입니다. 내부 언어 모델을 추정하기 위해서는 ASR 디코더를 기반으로 추가적인 순방향 계산이 필요하거나 Density Ratio 방식을 기반으로 ASR 훈련 세트 텍스트를 내부 언어로 사용하여 독립 언어 모델(DR-LM)을 훈련합니다. 모델의 근사치. ASR 디코더를 기반으로 한 ILME 방법은 추정을 위해 ASR 매개변수를 직접 사용하기 때문에 일반적으로 밀도비 방법보다 더 나은 성능을 얻을 수 있지만, ASR 디코더의 매개변수 양에 따라 계산량이 달라집니다. 밀도비 방법의 장점은 다음과 같습니다. DR-LM의 크기는 효율적인 내부 언어 모델 추정을 가능하게 합니다. 이러한 이유로 Volcano Voice 팀은 밀도 비율 방법의 프레임워크 하에서 ASR 디코더 기반의 ILME 방법을 교사로 사용하여 DR-LM을 추출하고 학습함으로써 ILME의 계산 비용을 크게 줄이면서 유지하는 것을 제안했습니다. ILME의 성능. 실험 결과에 따르면 이 방법은 내부 언어 모델 매개 변수를 95%까지 줄일 수 있으며 ASR 디코더 기반 ILME 방법과 성능면에서 비슷합니다. 더 나은 성능을 가진 ILME 방법을 교사로 사용하면 해당 학생 모델도 더 나은 결과를 얻을 수 있습니다. 유사한 계산량을 사용하는 기존 밀도 비율 방법과 비교할 때 이 방법은 리소스가 많은 시나리오에서 약간 더 나은 성능을 제공합니다. 리소스가 적은 도메인 간 마이그레이션 시나리오에서는 CER 이득이 8%에 도달할 수 있으며 더 강력합니다. fusion Weights GenerTTS: 교차 언어 텍스트 음성 변환의 음색 및 스타일 일반화를 위한 발음 분리 언어 간 음색 및 스타일 일반화 가능한 음성 합성(TTS)은 특정 참조 음색으로 음성을 합성하는 것을 목표로 합니다. 또는 대상 언어로 훈련되지 않은 스타일. 특정 화자에 대한 다국어 음성 데이터를 얻는 것이 종종 어렵기 때문에 음색과 발음을 분리하는 데 어려움이 있으며, 음성 스타일에는 언어 독립적인 부분과 언어 종속적인 부분이 모두 포함되어 있기 때문에 발음이 혼합되어 있는 경우가 많습니다. 이러한 문제를 해결하기 위해 Volcano Voice 팀은 GenerTTS를 제안했습니다. 그들은 음색과 발음/스타일 사이의 연결을 분리하기 위해 HuBERT 기반 정보 병목 현상을 신중하게 설계했습니다. 동시에 스타일과 언어 간의 상호 정보를 최소화하여 스타일에서 언어별 정보를 제거합니다. 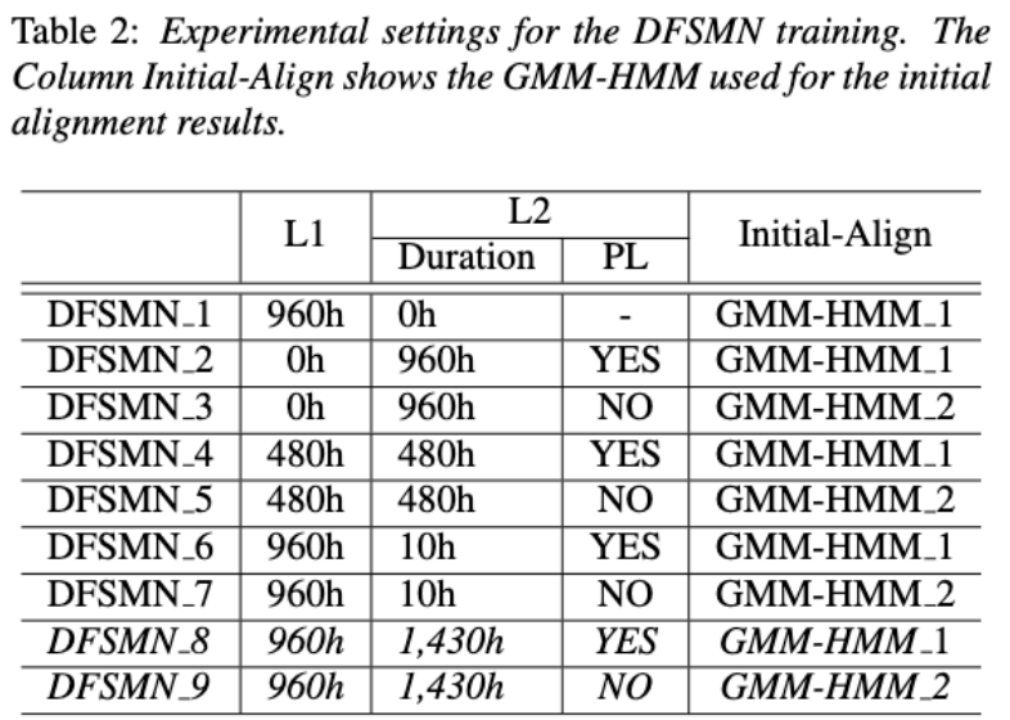


 구체적으로 팀은 LibriSpeech 데이터 세트를 소스 도메인으로 사용하고 주석이 달린 텍스트를 사용했습니다. 도메인 마이그레이션 실험을 위한 일반 텍스트인 SPGISpeech. 실험 결과는 목표 분야에서 이 방법의 효과가 기본적으로 TTS의 효과와 동일할 수 있음을 보여줍니다. 단일 단계 훈련 효과는 기본적으로 다중 단계와 동일합니다. USTR 방법은 LM이 동일한 텍스트 학습 코퍼스를 사용하더라도 ILME와 같은 플러그인 언어 모델의 성능을 더욱 향상시킬 수 있습니다. 마지막으로, 외부 언어 모델을 결합하지 않은 대상 도메인 테스트 세트에서 이 방법은 기준 WER 23.55% -> 13.25%에 비해 43.7%의 상대적 감소를 달성했습니다.
구체적으로 팀은 LibriSpeech 데이터 세트를 소스 도메인으로 사용하고 주석이 달린 텍스트를 사용했습니다. 도메인 마이그레이션 실험을 위한 일반 텍스트인 SPGISpeech. 실험 결과는 목표 분야에서 이 방법의 효과가 기본적으로 TTS의 효과와 동일할 수 있음을 보여줍니다. 단일 단계 훈련 효과는 기본적으로 다중 단계와 동일합니다. USTR 방법은 LM이 동일한 텍스트 학습 코퍼스를 사용하더라도 ILME와 같은 플러그인 언어 모델의 성능을 더욱 향상시킬 수 있습니다. 마지막으로, 외부 언어 모델을 결합하지 않은 대상 도메인 테스트 세트에서 이 방법은 기준 WER 23.55% -> 13.25%에 비해 43.7%의 상대적 감소를 달성했습니다. 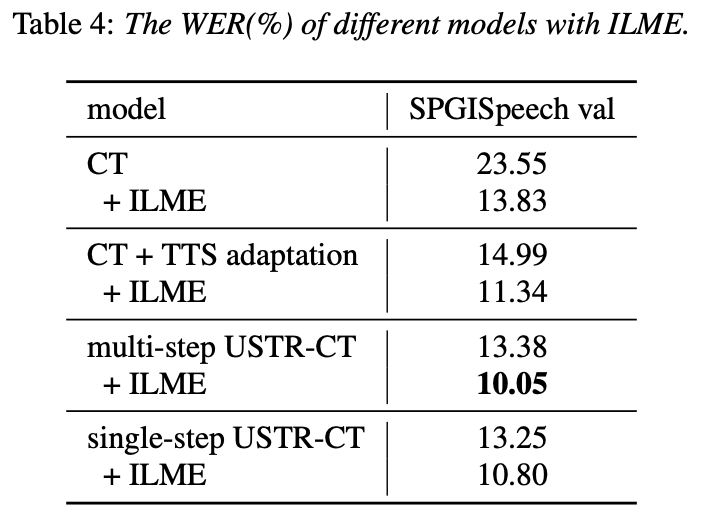
 Volcano Voice 팀은 항상 ByteDance의 내부 비즈니스 라인에 고품질 음성 AI 기술 역량과 풀 스택 음성 제품 솔루션을 제공하고 Volcano 엔진을 통해 외부 서비스를 제공해 왔습니다. 2017년 설립 이후, 팀은 업계 최고의 AI 지능형 음성 기술 연구 개발에 주력해 왔으며, 더 큰 사용자 가치를 달성하기 위해 AI와 비즈니스 시나리오의 효율적인 조합을 지속적으로 탐색하고 있습니다.
Volcano Voice 팀은 항상 ByteDance의 내부 비즈니스 라인에 고품질 음성 AI 기술 역량과 풀 스택 음성 제품 솔루션을 제공하고 Volcano 엔진을 통해 외부 서비스를 제공해 왔습니다. 2017년 설립 이후, 팀은 업계 최고의 AI 지능형 음성 기술 연구 개발에 주력해 왔으며, 더 큰 사용자 가치를 달성하기 위해 AI와 비즈니스 시나리오의 효율적인 조합을 지속적으로 탐색하고 있습니다.
위 내용은 Interspeech 2023에 여러 논문이 선정되었으며 Huoshan Speech는 다양한 유형의 실제 문제를 효과적으로 해결했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!