
Langchain, ChromaDB 및 GPT 3.5를 기반으로 검색 강화 생성 구현

- 王林앞으로
- 2023-09-14 14:21:111817검색
Translator | Zhu Xianzhong
Chonglou | Reviewer
Abstract:이 블로그에서는 )의 검색 방법에 대해 알아봅니다. 프롬프트 엔지니어링 기술과 은 Langchain, ChromaDB 및 GPT 3.5 의 조합을 기반으로 이 기술을 구현합니다.
동기 부여
GPT-3와 같은 변환기 기반 빅 데이터 모델의 등장으로 자연어 처리(NLP) 분야는 큰 발전을 이루었습니다. 이러한 언어 모델은 인간과 유사한 텍스트를 생성할 수 있으며 이미 챗봇, 콘텐츠 생성 및 번역 등 다양한 애플리케이션을 보유하고 있습니다 . 그러나 전문적이고 고객별 정보로 구성된 기업 응용 프로그램 시나리오 의 경우 기존 언어 모델이 요구 사항을 충족하지 못할 수 있습니다 . 반면에 새로운 말뭉치를 사용하여 이러한 모델을 미세 조정하는 데는 비용과 시간이 많이 소요될 수 있습니다. 이 문제를 해결하기 위해 검색 증강 생성(RAG: 검색 증강 생성)이라는 기술을 사용할 수 있습니다.
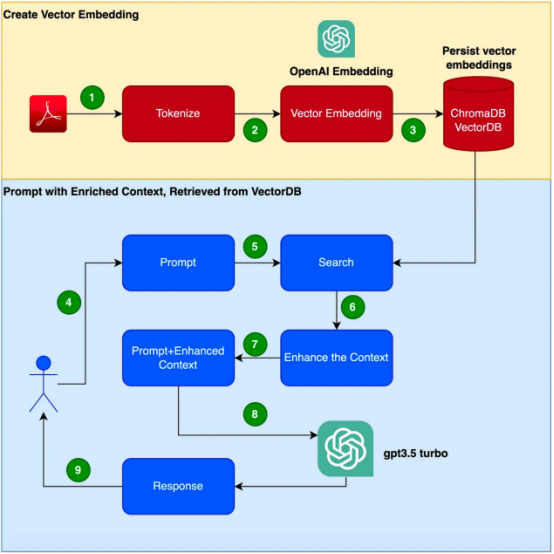
이 블로그에서는 이 Retrieval Enhanced Generation (RAG) 기술 이 어떻게 작동하는지 살펴보겠습니다. 실제 합격 전투예는 이 기술의 효과를 증명하는 데 사용됩니다. 이 예에서는 제품 매뉴얼에 대응하기 위한 추가 자료로 GPT-3.5 Turbo를 사용한다는 점에 유의해야 합니다.
특정 제품에 대한 문의에 응답할 수 있는 챗봇 을 개발하는 임무를 맡고 있다고 상상해 보세요. 이 제품에는 특히 기업용 제품을 위한 고유한 사용 설명서가 있습니다. GPT-3와 같은 기존 언어 모델은 일반 데이터에 대해 훈련되는 경우가 많으며 이 특정 제품을 이해하지 못할 수도 있습니다. 반면에 새로운 코퍼스를 사용하여 모델을 미세 조정하는 것이 해결책인 것 같습니다. 그러나 이 접근 방식은 상당한 비용과 리소스 요구 사항을 초래합니다.
검색 증강 생성(RAG) 소개
검색 증강 생성(RAG)은 특정 도메인에서 적절한 상황별 응답을 생성하는 문제를 해결하는 보다 효율적인 방법을 제공합니다. 전체 언어 모델을 미세 조정하기 위해 새로운 코퍼스를 사용하는 대신 RAG는 검색 기능을 사용하여 필요할 때 관련 정보에 액세스합니다. 검색 메커니즘과 언어 모델을 결합함으로써 RAG는 외부 컨텍스트를 활용하여 응답을 향상시킵니다. 이 외부 컨텍스트는 벡터 임베딩
으로 제공될 수 있습니다. 이 문서에서는 애플리케이션을 생성하기 위해 아래 단계가 제공됩니다 . 이 예에서는 Focusrite Clarett 사용 설명서를 추가 자료로 사용한다는 점에 유의해야 합니다. Focusrite Clarett은 오디오 녹음 및 재생을 위한 간단한 USB 오디오 인터페이스입니다. 링크 https://fael-downloads-prod.focusrite.com/customer/prod/downloads/Clarett%208Pre%20USB%20User%20Guide%20V2%20English%20-%20EN.pdf에서 다운로드하실 수 있습니다. 매뉴얼. 우리 구현 사례 을 캡슐화 하여 모든 을 방지할 수 있는 가상 환경을 설정해 보겠습니다. 시스템에서 발생할 수 있는 버전/라이브러리/종속성 충돌. 이제 다음 명령을 실행하여 새로운 Python 가상 환경 을 생성합니다. 에서 OpenAI에 등록하면 OpenAIKey를 무료로 생성할 수 있습니다. 회원가입 후 로그인 후 스크린샷과 같이 API 옵션을 선택하세요. 현재 스크린샷을 찍고 변경사항). when, 계정 설정으로 이동하여 "API 키보기"를 선택하십시오. )”을 선택하시면 아래와 같은 팝업창이 뜹니다. 이름을 제공하면 키가 생성됩니다. 이 작업을 하면 클립보드에 복사하여 안전한 장소 에 저장해야 하는 고유한 키가 생성됩니다.
다음 종속성 라이브러리 설치먼저 필요한 다양한 종속성을 설치해 보겠습니다. 우리는 다음 라이브러리를 사용할 것입니다: 一旦成功安装了这些依赖项,请创建一个环境变量来存储在最后一步中创建的OpenAI密钥。 接下来,让我们开始编程。 在下面的代码中,我们会引入所有需要使用的依赖库和函数 在下面的代码中,阅读PDF,将文档标记化并拆分为标记。 在下面的代码中,我们将创建一个色度集合,一个用于存储色度数据库的本地目录。然后,我们创建一个向量嵌入并将其存储在ChromaDB数据库中。 执行此代码后,您应该会看到创建了一个存储向量嵌入的文件夹。 现在,我们将向量嵌入存储在ChromaDB中。下面,让我们使用LangChain中的ConversationalRetrievalChain API来启动聊天历史记录组件。我们将传递由GPT 3.5 Turbo启动的OpenAI对象和我们创建的VectorDB。我们将传递ConversationBufferMemory,它用于存储消息。 既然我们已经初始化了会话检索链,那么接下来我们就可以使用它进行聊天/问答了。在下面的代码中,我们接受用户输入(问题),直到用户键入“done”。然后,我们将问题传递给LLM以获得回复并打印出来。 这是输出的屏幕截图。 正如你从本文中所看到的,检索增强生成是一项伟大的技术,它将GPT-3等语言模型的优势与信息检索的能力相结合。通过使用特定于上下文的信息丰富输入,检索增强生成使语言模型能够生成更准确和与上下文相关的响应。在微调可能不实用的企业应用场景中,检索增强生成提供了一种高效、经济高效的解决方案,可以与用户进行量身定制、知情的交互。 朱先忠是51CTO社区的编辑,也是51CTO专家博客和讲师。他还是潍坊一所高校的计算机教师,是自由编程界的老兵 原文标题:Prompt Engineering: Retrieval Augmented Generation(RAG),作者:A B Vijay Kumar
실습
가상 환경 설정
pip install virtualenvpython3 -m venv ./venvsource venv/bin/activate
OpenAI 키 생성 다음으로, 
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
export OPENAI_API_KEY=<openai-key></openai-key>
从用户手册PDF创建向量嵌入并将其存储在ChromaDB中
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData, embeddings, collection_name=collection_name, persist_directory=persist_directory )vectDB.persist()
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm( OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
chat_history = []qry = ""while qry != 'done': qry = input('Question: ') if qry != exit: response = chatQA({"question": qry, "chat_history": chat_history}) print(response["answer"])

小结
译者介绍
위 내용은 Langchain, ChromaDB 및 GPT 3.5를 기반으로 검색 강화 생성 구현의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!