
Interspeech 2023 | Volcano 엔진 스트리밍 오디오 기술 음성 향상 및 AI 오디오 코딩

- 王林앞으로
- 2023-09-11 12:57:02971검색

배경 소개
다중 장치, 다중 사람, 다중 소음 시나리오 등 다양하고 복잡한 오디오 및 비디오 통신 시나리오를 처리하기 위해 스트리밍 미디어 통신 기술은 점차 사람들의 삶에 없어서는 안될 기술이 되었습니다. . 더 나은 주관적 경험을 달성하고 사용자가 명확하고 진실하게 들을 수 있도록 하기 위해 스트리밍 오디오 기술 솔루션은 심층 신경망 기술 솔루션을 사용하여 기존 기계 학습과 AI 기반 음성 향상 솔루션을 결합하여 음성 잡음 감소 및 반향 제거를 달성합니다. 실시간 통신에서 오디오 품질을 보호하기 위해 음성 제거 및 오디오 인코딩 및 디코딩 등을 방해합니다.
Interspeech는 음성 신호 처리 연구 분야의 대표적인 국제 학회로서 항상 음향학 분야의 가장 최첨단 연구 방향을 제시해 왔습니다. Interspeech 2023에는 오디오 신호 음성 향상 알고리즘과 관련된 다수의 논문이 포함되어 있습니다. , 화산 엔진 스트리밍 오디오 음성 향상, AI 기반 인코딩 및 디코딩, 반향 제거, 비지도 적응형 음성 향상을 포함하여 팀이 진행한 총 4개의 연구 논문이 컨퍼런스에서 승인되었습니다.
비지도 적응형 음성 향상 분야에서 ByteDance와 NPU의 공동 팀이 올해 CHiME(다중 소스 환경의 컴퓨터 청각)의 비지도 도메인 적응형 대화 음성 향상(비지도 도메인) 하위 작업을 성공적으로 완료했다는 점은 언급할 가치가 있습니다. 대화 음성 향상을 위한 적응(UDASE) 챌린지가 우승했습니다(https://www.chimechallenge.org/current/task2/results). CHiME 챌린지는 프랑스 컴퓨터과학과 자동화 연구소, 영국 셰필드 대학, 미국 미쓰비시전자연구소 등 유명 연구기관이 2011년 시작한 중요한 국제대회다. 음성 연구 분야의 원격 문제에 도전하는 대회가 올해로 7회째 개최되었습니다. 이전 CHiME 대회 참가팀으로는 영국 케임브리지대학교, 미국 카네기멜론대학교, 일본 존스홉킨스대학교, NTT, Hitachi Academia Sinica 등 국제적으로 유명한 대학 및 연구기관, 칭화대학교, 중국과학원, 중국과학원 음향연구소, NPU, iFlytek 등 국내 최고 대학 및 연구기관.
이 기사에서는 이 네 가지 논문이 해결하는 핵심 시나리오 문제와 기술 솔루션을 소개하고, AI 인코더, 반향 제거 및 비지도 적응형 음성 기반 음성 향상 분야에서 Volcano Engine 스트리밍 오디오 팀의 생각과 실무를 공유합니다. 상승.
학습 가능한 콤 필터를 기반으로 한 경량 음성 조화 향상 방법
논문 주소: https://www.isca-speech.org/archive/interspeech_2023/le23_interspeech.html
Background
제한됨 대기 시간 및 컴퓨팅 리소스로 인해 실시간 오디오 및 비디오 통신 시나리오의 음성 향상은 일반적으로 필터 뱅크를 기반으로 하는 입력 기능을 사용합니다. Mel 및 ERB와 같은 필터 뱅크를 통해 원래 스펙트럼은 더 낮은 차원의 하위 대역으로 압축됩니다. 서브밴드 영역에서 딥러닝 기반 음성 향상 모델의 출력은 서브밴드의 음성 이득이며, 이는 목표 음성 에너지의 비율을 나타냅니다. 그러나 압축된 하위 대역 도메인의 향상된 오디오는 스펙트럼 세부 정보의 손실로 인해 흐릿해지며 종종 고조파를 향상시키기 위해 후처리가 필요합니다. RNNoise와 PercepNet은 고조파를 향상시키기 위해 콤 필터를 사용하지만 기본 주파수 추정과 콤 필터 게인 계산 및 모델 분리로 인해 엔드 투 엔드를 최적화할 수 없습니다. DeepFilterNet은 시간-주파수 영역 필터를 사용하여 상호 고조파 잡음을 억제합니다. 그러나 음성의 기본 주파수 정보를 명시적으로 활용하지는 않습니다. 위의 문제점에 대응하여, 연구팀은 기본 주파수 추정과 콤 필터링을 결합한 학습 가능한 콤 필터 기반의 음성 고조파 향상 방법을 제안했으며, 콤 필터의 이득은 단대단으로 최적화될 수 있습니다. 실험에 따르면 이 방법은 기존 방법과 비슷한 계산량으로 더 나은 고조파 향상을 달성할 수 있습니다.
모델 프레임워크 구조
기본 주파수 추정기(F0 Estimator)
기본 주파수 추정의 어려움을 줄이고 전체 링크가 End-to-End로 작동할 수 있도록 하기 위해 추정할 목표 기본 주파수 범위를 다음과 같이 이산화합니다. N개의 이산 기본 주파수 , 분류기를 사용하여 추정됩니다. 무성음 프레임을 나타내기 위해 1차원이 추가되고, 최종 모델 출력은 N+1 차원의 확률입니다. CREPE와 일관되게 팀은 훈련 목표로 Gaussian Smooth 기능을 사용하고 손실 함수로 Binary Cross Entropy를 사용합니다.
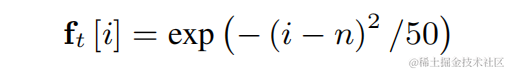
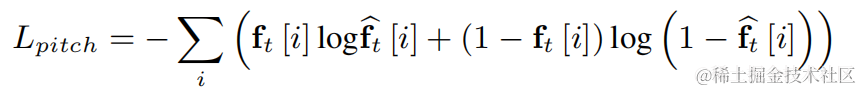
Learnable Comb Filter
위의 개별 기반 주파수 각각에 대해 팀은 FIR을 사용합니다. 변조된 펄스열로 표현될 수 있는 빗 필터링을 위한 PercepNet과 유사한 필터:
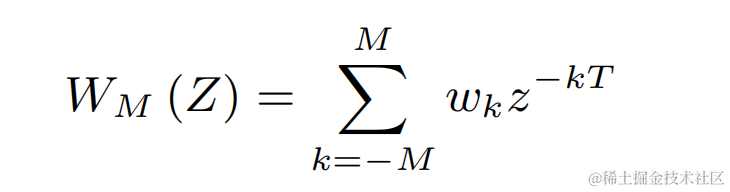
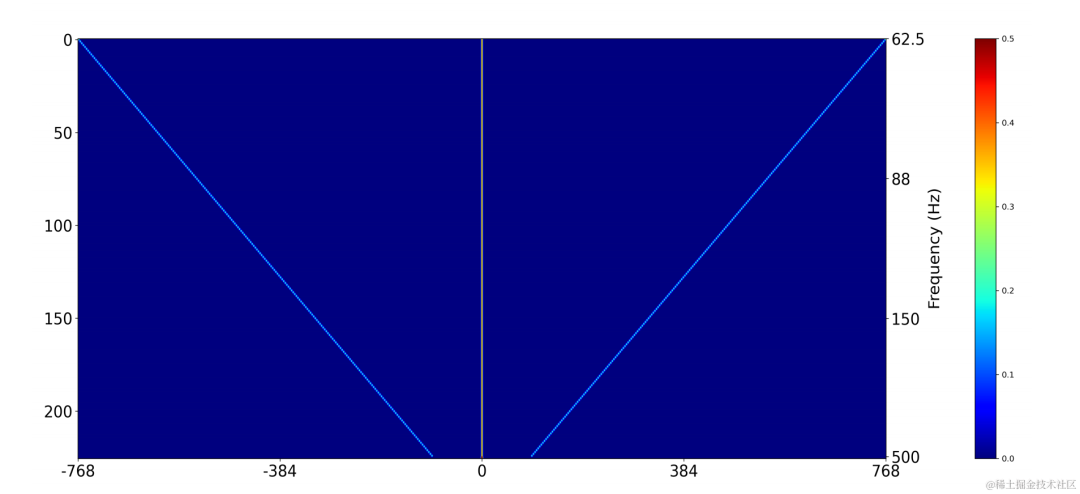
2차원 컨볼루션 레이어(Conv2D)를 사용하여 훈련 중에 모든 이산 기본 주파수의 필터링 결과를 동시에 계산합니다. 2차원 컨볼루션의 가중치는 아래 그림의 행렬로 표현될 수 있습니다. 행렬은 N+1입니다. 위의 필터 초기화:
대상 기본 주파수의 원-핫 라벨과 2차원 컨볼루션의 출력을 곱하여 각 프레임의 기본 주파수에 해당하는 필터링 결과를 얻습니다. :

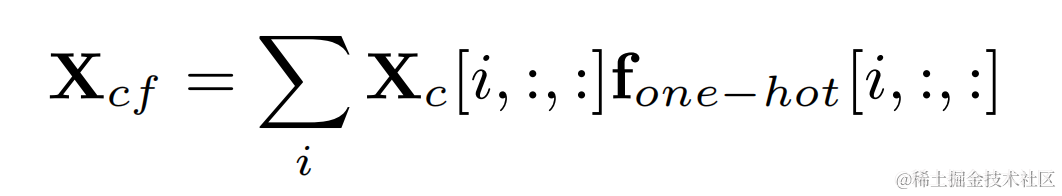
고조파 강화 후 오디오 원래 오디오 가중치를 더하고 하위 대역 게인을 곱하여 최종 출력을 얻습니다.
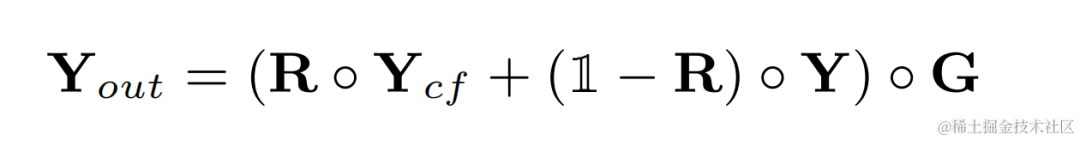
추론 중에 각 프레임은 하나의 필터링 결과만 계산하면 됩니다. 기본 주파수이므로 이 방법의 계산 비용이 낮습니다.
모델 구조
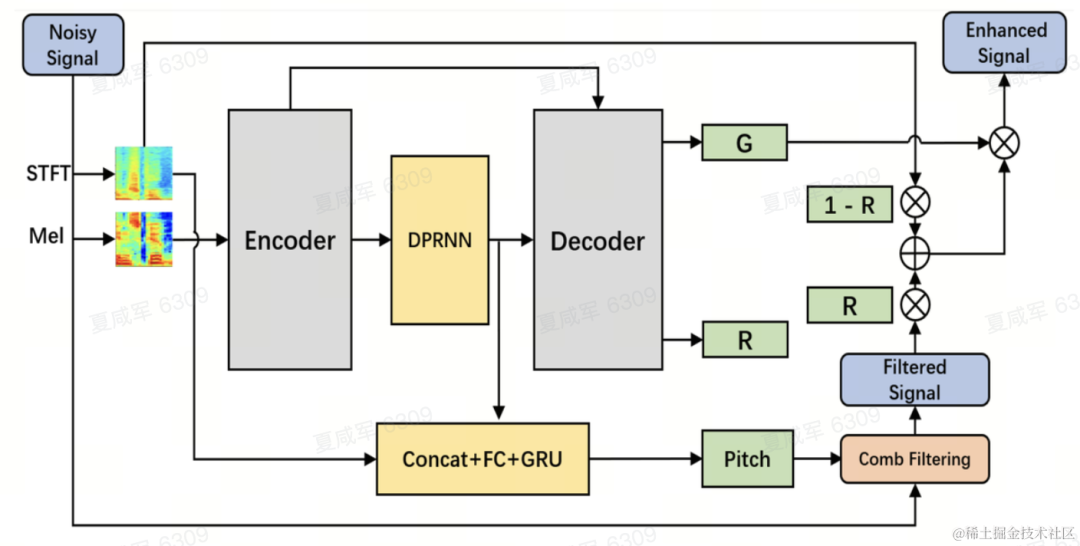
팀에서는 DPCRN(Dual-Path Convolutional Recurrent Network)을 음성 향상 모델의 백본으로 사용하고 기본 주파수 추정기를 추가합니다. 인코더와 디코더는 깊이 분리 가능한 컨볼루션을 사용하여 대칭 구조를 형성합니다. 디코더는 각각 부대역 이득 G와 가중 계수 R을 출력하는 두 개의 병렬 분기를 갖습니다. 기본 주파수 추정기에 대한 입력은 DPRNN 모듈과 선형 스펙트럼의 출력입니다. 본 모델의 계산량은 약 300M MAC이고, 그 중 콤 필터링 계산량은 약 0.53M MAC이다.
모델 훈련
실험에서는 훈련에 VCTK-DEMAND와 DNS4 챌린지 데이터세트를 사용했고, 다중 작업 학습에는 음성 향상과 기본 주파수 추정의 손실 함수를 사용했습니다.
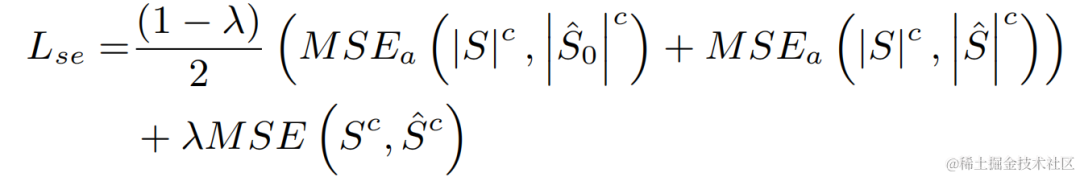
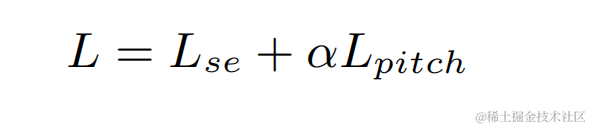
실험 결과
스트리밍 오디오 팀은 제안된 학습 가능한 콤 필터 모델을 PercepNet의 콤 필터와 DeepFilterNet의 필터 알고리즘을 각각 DPCRN-PN 및 DPCRN-DF라고 합니다. VCTK 테스트 세트에서는 본 논문에서 제안하는 방법이 기존 방법에 비해 장점을 보인다.
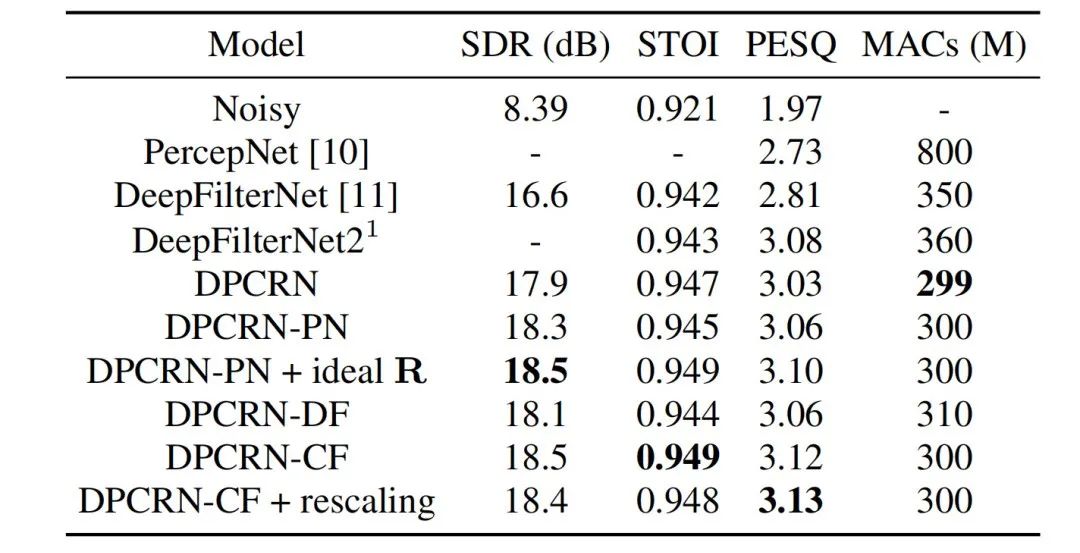
동시에 팀에서는 기본 주파수 추정 및 학습 가능한 필터에 대한 절제 실험을 수행했습니다. 실험 결과, 신호 처리 기반의 기본 주파수 추정 알고리즘과 필터 가중치를 사용하는 것보다 end-to-end 학습이 더 나은 결과를 생성하는 것으로 나타났습니다.
Intra-BRNN 및 GB-RVQ를 기반으로 한 종단 간 신경망 오디오 인코더
논문 주소: https://www.isca-speech.org/archive/pdfs/interspeech_2023/xu23_interspeech.pdf
배경
최근에는 저비트레이트 음성 코딩 작업에 많은 신경망 모델이 사용되었습니다. 그러나 일부 엔드 투 엔드 모델은 프레임 내 관련 정보를 최대한 활용하지 못하며 도입된 양자화기의 크기가 큽니다. 양자화 오류로 인해 인코딩 후 오디오 품질이 저하됩니다. 스트리밍 오디오팀은 엔드투엔드 신경망 오디오 인코더의 품질을 향상시키기 위해 엔드투엔드 신경망 음성 코덱, 즉 CBRC(Convolutional and BiDirectional Recurrent Neural Codec)를 제안했습니다. CBRC는 1D-CNN(1차원 컨볼루션)과 Intra-BRNN(프레임 내 양방향 순환 신경망)의 인터리브 구조를 사용하여 프레임 내 상관 관계를 보다 효과적으로 활용합니다. 또한 팀은 양자화 노이즈를 줄이기 위해 CBRC의 GB-RVQ(그룹별 및 빔 검색 잔여 벡터 양자화기)를 사용합니다. CBRC는 추가 시스템 지연 없이 20ms 프레임 길이의 16kHz 오디오를 인코딩하며 실시간 통신 시나리오에 적합합니다. 실험 결과 비트율 3kbps의 CBRC 인코딩이 12kbps의 Opus보다 음성 품질이 더 좋은 것으로 나타났습니다.
모델 프레임 구조
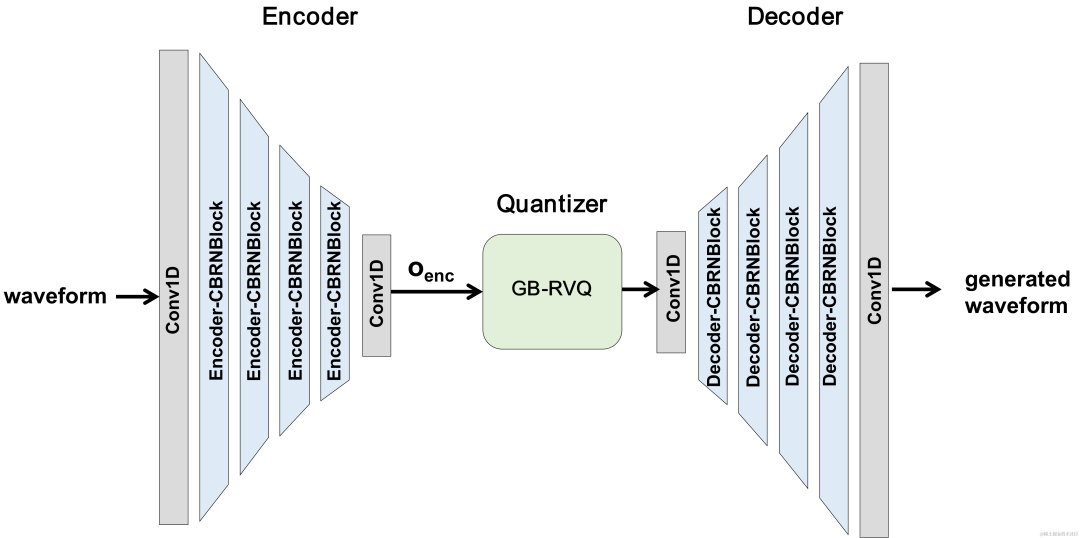
CBRC 전체 구조
인코더 및 디코더 네트워크 구조
인코더는 4개의 계단식 CBRNBlock을 사용하여 오디오 특징을 추출합니다. 각 CBRNBlock은 특징 추출을 위한 3개의 ResidualUnit과 다운샘플링 속도를 제어하는 1차원 컨볼루션으로 구성됩니다. 인코더의 기능이 다운샘플링될 때마다 기능 채널 수가 두 배로 늘어납니다. ResidualUnit은 Residual Convolution 모듈과 Residual 양방향 순환 네트워크로 구성되며, Convolution 계층은 Causal Convolution을 사용하는 반면 Intra-BRNN의 양방향 GRU 구조는 20ms 프레임 내 오디오 기능만 처리합니다. 디코더 네트워크는 업샘플링을 위해 1차원 전치 콘볼루션을 사용하는 인코더의 미러 구조입니다. 1D-CNN과 Intra-BRNN의 인터리브 구조를 통해 인코더와 디코더는 추가 지연 없이 20ms 오디오 프레임 내 상관 관계를 최대한 활용할 수 있습니다.
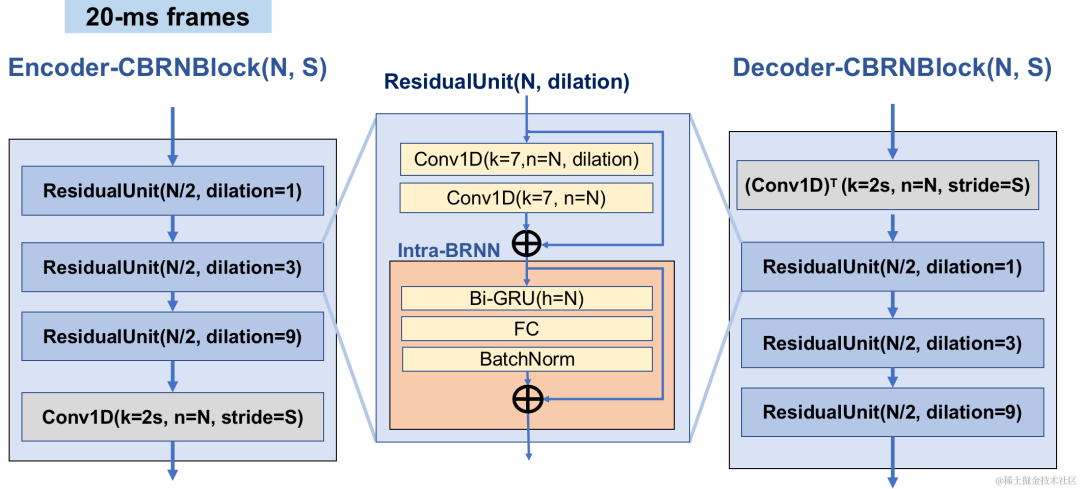
CBRNBlock 구조
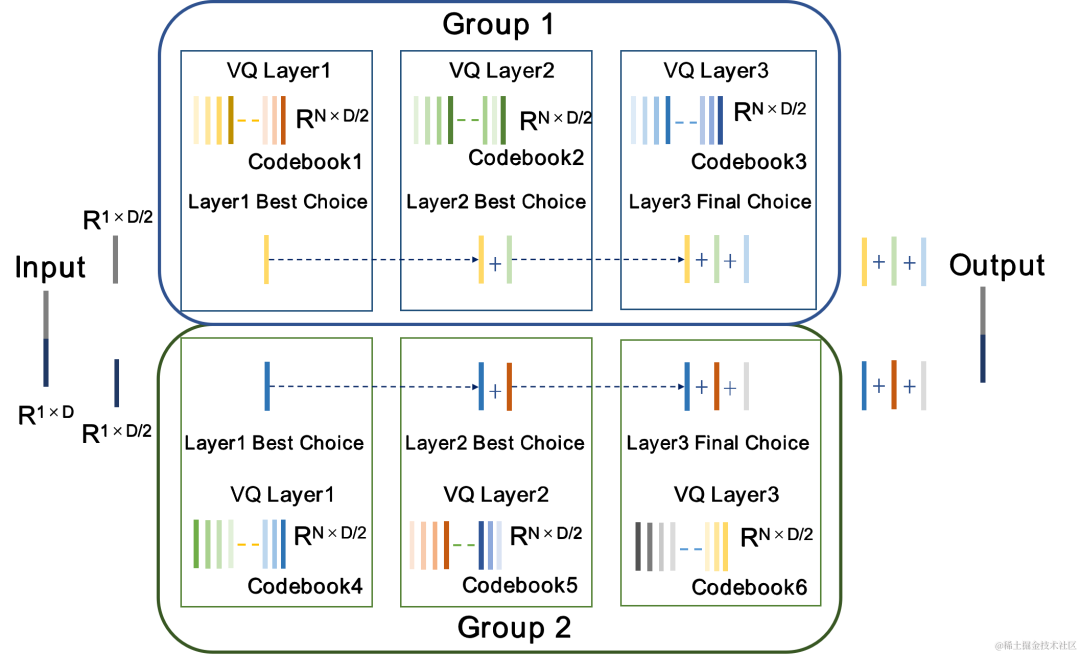
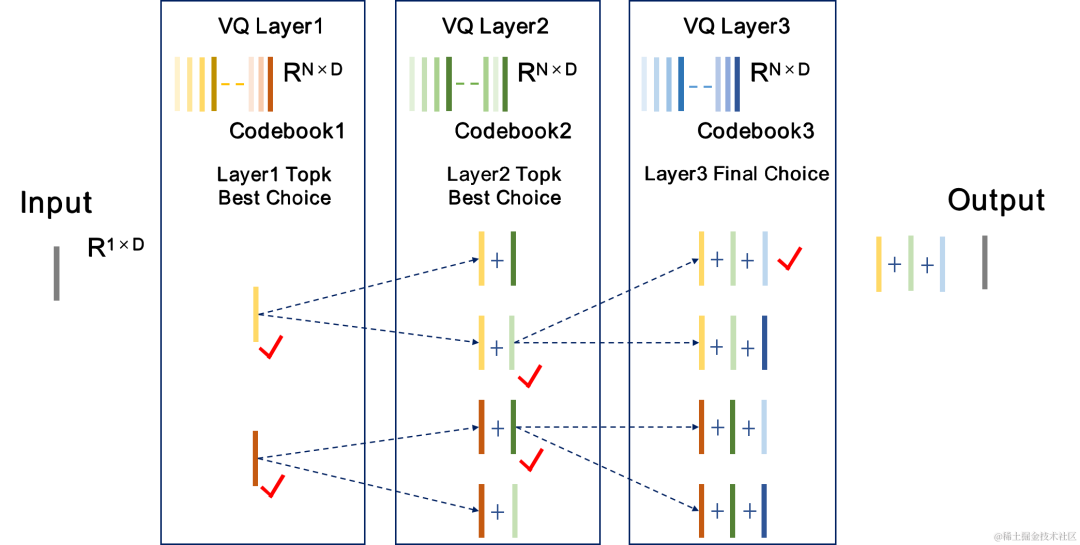
그룹 및 빔 검색 잔여 벡터 양자화기 GB-RVQ
CBRC는 잔여 벡터 양자화기(Residual Vector Quantizer, RVQ)를 사용하여 코딩 네트워크 출력 기능을 지정된 비트 전송률로 양자화하고 압축합니다. . RVQ는 다중 계층 벡터 양자화기(VQ)의 캐스케이드를 사용하여 특징을 압축합니다. VQ의 각 계층은 이전 VQ 계층의 양자화 잔여분을 양자화합니다. 이는 동시에 VQ의 단일 계층의 코드북 매개변수 양을 크게 줄일 수 있습니다. 비트율. 팀은 CBRC에서 두 가지 더 나은 양자화기 구조, 즉 그룹별 RVQ와 빔 검색 잔여 벡터 양자화기(빔 검색 RVQ)를 제안했습니다.
그룹별 RVQ |
빔 검색 RVQ |
||||||||
|
그룹별 RVQ는 인코더 출력을 그룹화하고 그룹화된 RVQ를 사용하여 그룹화된 특징을 독립적으로 정량화한 다음 그룹화된 양자화된 출력을 입력 디코더에 접합합니다. 그룹별 RVQ는 그룹 양자화를 사용하여 코드북 매개변수와 양자화기의 계산 복잡성을 줄이는 동시에 CBRC 종단 간 훈련의 어려움을 줄여 CBRC 인코딩 오디오의 품질을 향상시킵니다. 팀은 신경 오디오 인코더의 엔드투엔드 훈련에 Beam-search RVQ를 도입했으며, Beam-search 알고리즘을 사용하여 RVQ에서 양자화 경로 오류가 가장 작은 코드북 조합을 선택하여 양자화 오류를 줄였습니다. 양자화기. 원래의 RVQ 알고리즘은 VQ 양자화의 각 레이어에서 오차가 가장 작은 코드북을 출력으로 선택하지만, VQ 양자화의 각 레이어에 대한 최적의 코드북 조합이 반드시 전역적으로 최적의 코드북 조합이 될 수는 없습니다. 팀은 빔 검색 RVQ를 사용하여 최소 양자화 경로 오류 기준을 기반으로 VQ의 각 계층에서 k개의 최적 양자화 경로를 유지함으로써 더 큰 양자화 검색 공간에서 더 나은 코드북 조합을 선택할 수 있도록 하고 양자화 오류를 줄입니다.
모델 훈련실험에서는 LibriTTS 데이터 세트의 16kHz 음성 245시간을 훈련에 사용했으며, 음성 진폭에 랜덤 게인을 곱한 후 모델에 입력했습니다. 훈련의 손실 함수는 스펙트럼 재구성 다중 규모 손실, 판별기 적대적 손실 및 특징 손실, VQ 양자화 손실 및 지각 손실로 구성됩니다.
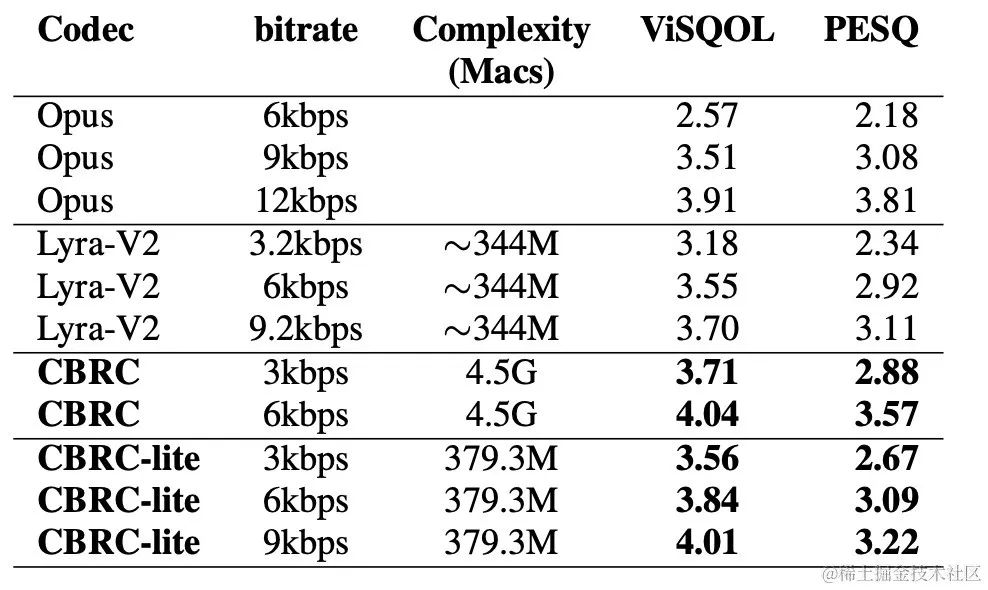
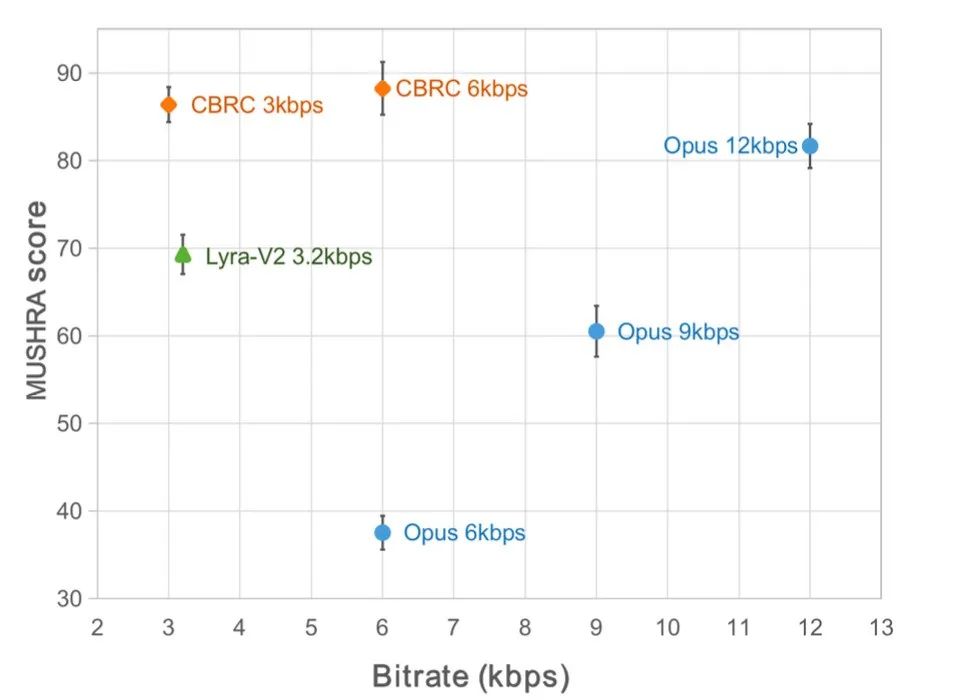
실험 결과주관적 및 객관적 점수CBRC 인코딩 음성 품질을 평가하기 위해 10개의 다국어 오디오 비교 세트를 구성하고 이 비교 세트를 사용하여 다른 오디오 코덱과 비교했습니다. 계산 복잡성의 영향을 줄이기 위해 팀은 계산 복잡성이 Lyra-V2보다 약간 높은 경량 CBRC-lite를 설계했습니다. 주관적인 청취 비교 결과에서 3kbps에서 CBRC의 음질은 Opus의 12kbps를 능가하고, Lyra-V2에서도 3.2kbps를 능가하는 것을 알 수 있어 제안 방법의 유효성을 보여준다. CBRC 인코딩 오디오 샘플은 https://bytedance.feishu.cn/docx/OqtjdQNhZoAbNoxMuntcErcInmb에서 제공됩니다.
절제 실험팀은 Intra-BRNN, Group-wise RVQ 및 Beam-search RVQ에 대한 절제 실험을 설계했습니다. 실험 결과에 따르면 인코더와 디코더 모두에서 Intra-BRNN을 사용하면 음성 품질이 크게 향상될 수 있습니다. 또한, 연구팀은 RVQ에서 코드북 사용 빈도를 계산하고 엔트로피 디코딩을 계산하여 다양한 네트워크 구조에서 코드북 사용률을 비교했습니다. Intra-BRNN을 사용하는 CBRC는 완전 컨벌루션 구조와 비교하여 잠재적인 인코딩 비트율을 4.94kbps에서 5.13kbps로 증가시킵니다. 마찬가지로 CBRC에서 그룹별 RVQ 및 빔 검색 RVQ를 사용하면 인코딩된 음성의 품질을 크게 향상시킬 수 있으며, 신경망 자체의 계산 복잡성과 비교할 때 GB-RVQ로 인한 복잡성 증가는 거의 무시할 수 있습니다.
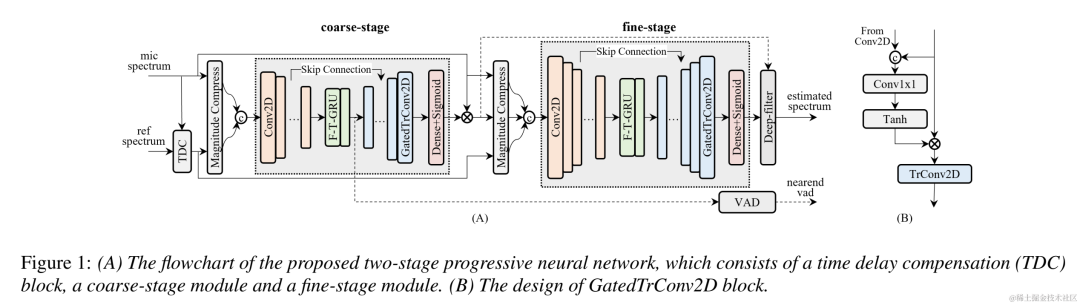
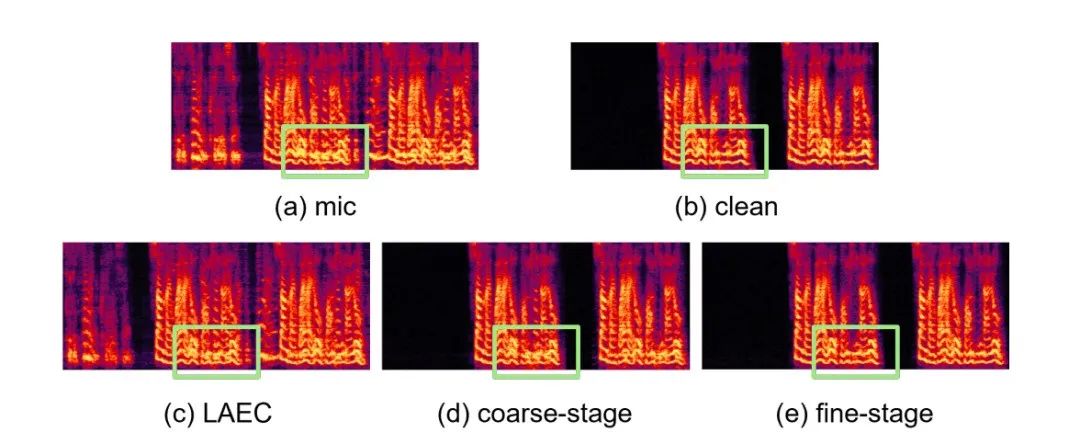
샘플 사운드원본 오디오 arctic_a0023_16k, ByteDance 기술 팀, 5초 es 01_l_1 6k, ByteDance 기술팀, 10초 CBRC 3kbps arctic_a0023_16k_CBRC_3kbps, Bytedance 기술팀, 5초 es01_l_16k_CBRC_3kbps, Bytedance 기술팀, 10초 CBRC-lite 3kbps arctic_a0023_16k_CBRC_lite_3kbps, 바이트댄스 기술 팀, 5초 es01_l_16k_CBRC_lite_3kbps, Bytedance 기술팀, 10초 2단계 프로그레시브 신경망 기반 에코 제거 방법논문 주소: https: //www.isca-speech.org/archive /pdfs/interspeech_2023/chen23e_interspeech.pdf Background핸즈프리 통신 시스템에서 음향 반향은 성가신 배경 간섭입니다. 에코는 상대방 신호가 스피커에서 재생된 후 가까운 마이크에 의해 녹음될 때 발생합니다. AEC(음향 반향 제거)는 마이크에서 포착된 원치 않는 반향을 억제하도록 설계되었습니다. 현실 세계에는 실시간 통신, 스마트 교실, 차량 핸즈프리 시스템 등 반향 제거가 필요한 애플리케이션이 많이 있습니다. 최근에는 딥 러닝(DL) 방법을 사용하는 데이터 기반 AEC 모델이 더욱 강력하고 강력한 것으로 입증되었습니다. 이러한 방법은 AEC를 감독 학습 문제로 공식화합니다. 여기서 입력 신호와 근위 목표 신호 간의 매핑 기능은 심층 신경망(DNN)을 통해 학습됩니다. 그러나 실제 에코 경로는 매우 복잡하므로 DNN의 모델링 기능에 대한 요구 사항이 더 높습니다. 네트워크의 모델링 부담을 줄이기 위해 대부분의 기존 DL 기반 AEC 방법은 프런트엔드 LAEC(선형 반향 제거) 모듈을 채택하여 에코의 선형 성분을 대부분 억제합니다. 그러나 LAEC 모듈에는 두 가지 단점이 있습니다. 1) 부적절한 LAEC는 근거리 음성의 일부 왜곡을 일으킬 수 있으며, 2) LAEC 수렴 프로세스로 인해 선형 반향 억제 성능이 불안정해집니다. LAEC는 자체 최적화되므로 LAEC의 단점으로 인해 후속 신경망에 추가적인 학습 부담이 발생합니다. LAEC의 영향을 피하고 더 나은 근거리 음성 품질을 유지하기 위해 이 논문에서는 엔드투엔드 DL을 기반으로 하는 새로운 2단계 처리 모델을 탐색하고 거친 단계(coarse-stage) 및 미세 단계(fine)를 제안합니다. -grained 반향 제거 작업에는 미세 단계 2단계 캐스케이드 신경망(TSPNN)이 사용됩니다. 많은 실험 결과는 제안된 2단계 에코 제거 방법이 다른 주류 방법보다 더 나은 성능을 달성할 수 있음을 보여줍니다. 모델 프레임워크 구조아래 그림과 같이 TSPNN은 주로 TDC(Time Delay Compensation Module), 거친 처리 모듈(Coarse-stage) 및 Fine-grained 처리 모듈(Fine-stage)의 세 부분으로 구성됩니다. . TDC는 입력 원단 기준 신호(ref)와 근거리 마이크 신호(mic)를 정렬하는 역할을 담당하며 이는 후속 모델 수렴에 도움이 됩니다. 대략 단계는 마이크에서 대부분의 에코와 잡음을 제거하는 역할을 담당하여 후속 미세 단계 단계에서 모델 학습 부담을 크게 줄입니다. 동시에, 거친 단계는 다중 작업 학습을 위한 VAD(음성 활동 감지) 작업을 결합하여 모델의 근단 음성 인식을 강화하고 근단 음성에 대한 손상을 줄입니다. 미세 스테이지는 잔여 에코와 잡음을 추가로 제거하고 인접 주파수 지점 정보를 결합하여 가까운 목표 신호를 더 잘 재구성하는 역할을 합니다.
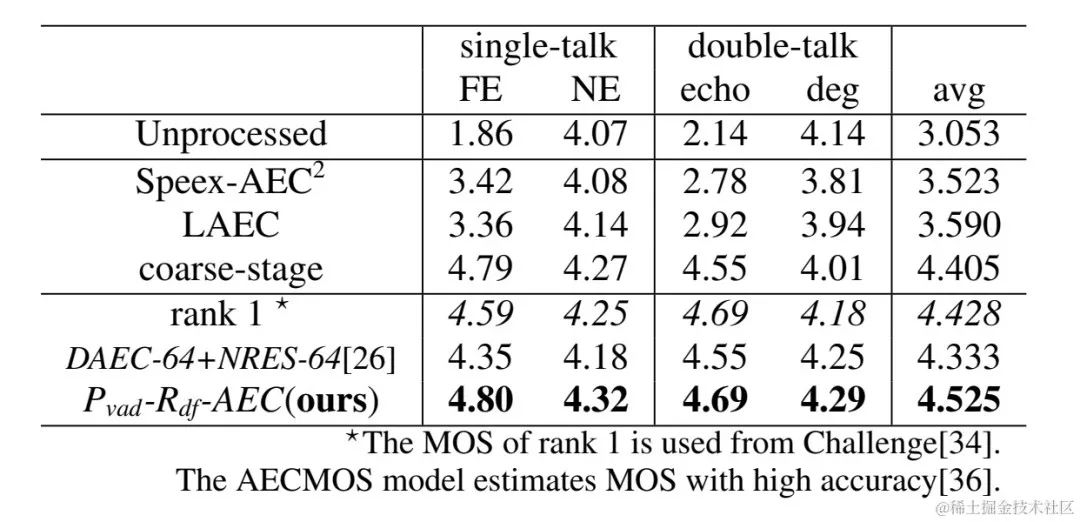
각 단계의 모델을 독립적으로 최적화하여 발생하는 최적이 아닌 솔루션을 피하기 위해 이 기사에서는 계단식 최적화 형식을 사용하여 거친 단계와 미세 단계를 동시에 최적화하는 동시에 문제가 발생하지 않도록 대략 단계의 제약 조건을 완화합니다. 가까운 언어 손상에. 또한, 모델이 근단 음성 인식 능력을 가질 수 있도록 하기 위해, 본 발명에서는 다중 작업 학습을 위한 VAD 작업을 도입하고, 손실 함수에 VAD의 손실을 추가한다. 최종 손실 함수는 다음과 같습니다. 여기서 는 목표 근단 신호 복합 스펙트럼을 나타내고, 대략 단계 및 미세 단계 추정 근단 신호 복합 스펙트럼은 각각 대략 단계에 의해 추정된 근단 음성 활성 상태를 나타냅니다. , Near-End Speech 활동 감지 라벨 은 주로 훈련 단계의 다양한 단계에 대한 주의 정도를 조정하는 데 사용되는 제어 스칼라입니다. 본 발명은 조대기에 대한 제약을 완화하고 조대기 근위단의 손상을 효과적으로 방지하기 위해 을 제한합니다. 실험 결과실험 데이터Volcano Engine 스트리밍 오디오 팀이 제안한 2단계 에코 제거 시스템을 다른 방법과도 비교한 결과, 제안한 시스템이 다른 주류 방법보다 더 나은 결과를 얻을 수 있음이 나타났습니다.
구체적인 예
CHiME-7 UDASE(비지도 도메인 적응형 음성 향상) 챌린지 챔피언 솔루션논문 주소: https://www.chimechallenge.org/current/task2/documents/Zhang_NB.pdf 배경:최근에는 신경망의 발전과 데이터 기반 딥러닝으로 기술이 발전함에 따라 음성 향상 기술에 대한 연구는 점차 딥러닝 기반 방법으로 전환되었으며, 심층 신경망을 기반으로 한 음성 향상 모델이 점점 더 많이 제안되었습니다. 그러나 이러한 모델의 대부분은 지도 학습을 기반으로 하며 훈련을 위해 많은 양의 쌍 데이터가 필요합니다. 그러나 실제 시나리오에서는 잡음이 많은 장면의 음성과 쌍을 이루는 깨끗한 음성 태그를 간섭 없이 동시에 캡처하는 것이 불가능합니다. 데이터 시뮬레이션은 일반적으로 깨끗한 음성과 다양한 소음을 별도로 수집한 다음 특정 신호에 따라 결합하는 데 사용됩니다. -대 잡음 비율은 잡음이 있는 주파수를 생성하기 위해 혼합됩니다. 이로 인해 훈련 시나리오와 실제 적용 시나리오 간의 불일치가 발생하고 실제 적용에서는 모델 성능이 저하됩니다. 위의 도메인 불일치 문제를 더 잘 해결하기 위해 실제 장면에서 대량의 레이블이 지정되지 않은 데이터를 사용하는 비지도 및 자기 감독 음성 향상 기술이 제안되었습니다. CHiME 챌린지 트랙 2는 훈련 데이터와 실제 응용 시나리오 간의 불일치로 인해 인위적으로 생성된 레이블이 지정된 데이터에서 훈련된 음성 향상 모델의 성능 저하 문제를 극복하기 위해 레이블이 지정되지 않은 데이터를 사용하는 것을 목표로 합니다. 연구의 초점은 대상을 사용하는 방법입니다. 도메인의 데이터와 세트 외부의 라벨링된 데이터는 대상 도메인의 향상 결과를 향상시키는 데 사용됩니다. 모델 프레임워크 구조:
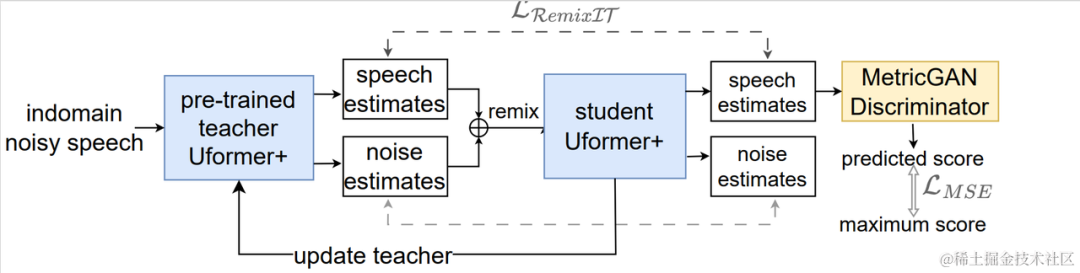
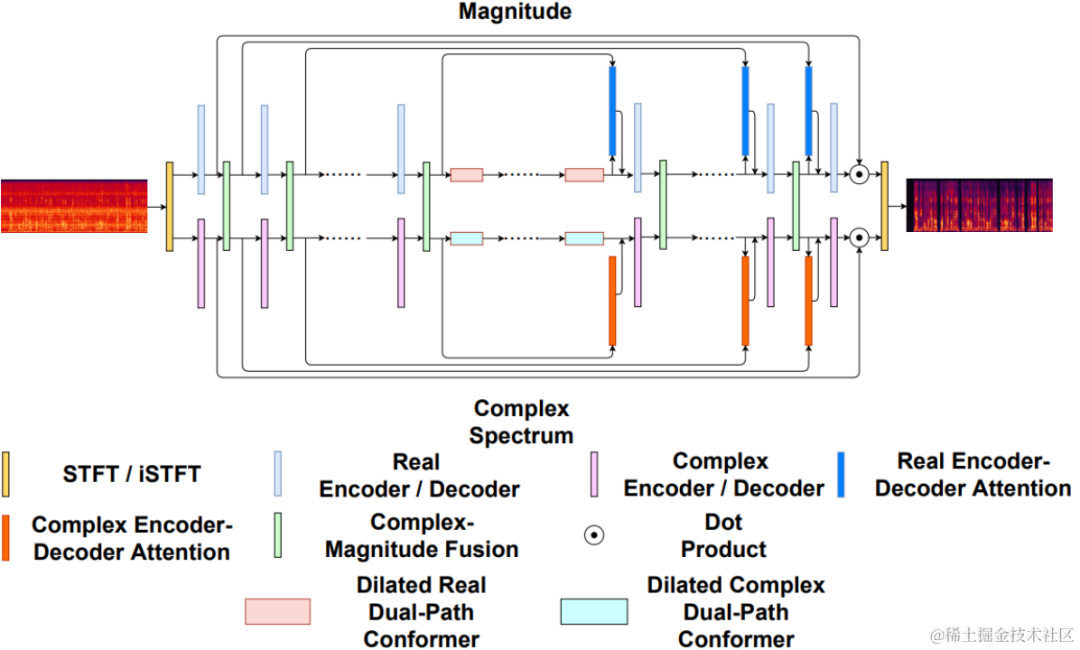
비지도 도메인 적응형 음성 향상 시스템 흐름도 위 그림에서 볼 수 있듯이 제안된 프레임워크는 교사-학생 네트워크입니다. 먼저, 도메인 내 데이터에 대한 음성 활동 감지, UNA-GAN, 시뮬레이션된 방 충격 반응, 동적 소음 및 기타 기술을 사용하여 대상 도메인에 가장 가까운 레이블이 지정된 데이터 세트를 생성하고 교사 소음 감소 네트워크 Uformer+를 사전 훈련합니다. 도메인 외부의 레이블이 지정된 데이터 세트. 그런 다음 이 프레임워크는 도메인의 레이블이 없는 데이터에 대한 학생 네트워크를 업데이트하는 데 사용됩니다. 즉, 사전 훈련된 교사 네트워크를 사용하여 잡음이 있는 오디오에서 의사 레이블로 깨끗한 음성과 잡음을 추정하고 무작위로 리믹스합니다. 의사 레이블을 사용하여 학생 네트워크에 대한 교육 데이터 입력을 감독합니다. 학생 네트워크에서 생성된 깨끗한 음성 품질 점수는 사전 훈련된 MetricGAN 판별자를 사용하여 추정되며 손실은 학생 네트워크가 더 높은 품질의 깨끗한 오디오를 생성하도록 안내하기 위해 가장 높은 점수로 계산됩니다. 각 훈련 단계 후에 학생 네트워크의 매개변수는 더 높은 품질의 지도 학습 의사 라벨을 얻기 위해 특정 가중치를 갖는 교사 네트워크로 업데이트됩니다. Uformer+ 네트워크Uformer+는 Uformer 네트워크를 기반으로 MetricGAN을 추가하여 개선되었습니다. Uformer는 Unet 구조를 기반으로 한 복소 실수 이중 경로 변환기 네트워크로, 진폭 스펙트럼 분기와 복소 스펙트럼 분기라는 두 개의 병렬 분기가 있습니다. 네트워크 구조는 아래 그림에 나와 있습니다. 진폭 분기는 주요 노이즈 억제 기능에 사용되며 대부분의 노이즈를 효과적으로 억제할 수 있습니다. 복합 분기는 스펙트럼 세부 사항 및 위상 편차와 같은 손실을 보상하기 위한 보조 역할을 합니다. MetricGAN의 주요 아이디어는 신경망을 사용하여 미분 불가능한 음성 품질 평가 지표를 시뮬레이션하여 훈련 및 실제 적용 중에 일관되지 않은 평가 지표로 인해 발생하는 오류를 줄이기 위해 네트워크 훈련에 사용할 수 있도록 하는 것입니다. 여기서 팀은 MetricGAN 네트워크 추정의 대상으로 PESQ(Perceptual Speech Quality Evaluation)를 사용합니다.
Uformer 네트워크 구조 다이어그램 RemixIT-G 프레임워크RemixIT-G는 교사-학생 네트워크입니다. 먼저 도메인 외부의 레이블이 지정된 데이터에 대해 교사 Uformer+ 모델을 사전 훈련하고 사전 훈련된 교사 모델을 사용합니다. 도메인에서 잡음이 있는 오디오를 디코딩합니다. 다음으로, 추정된 잡음과 음성의 순서를 동일한 배치 내에서 스크램블하고, 잡음과 음성을 스크램블된 순서로 리믹스하여 시끄러운 오디오로 리믹스하여 학생 네트워크 훈련을 위한 입력으로 사용합니다. 교사 네트워크가 의사 라벨로 추정한 소음 및 음성입니다. 학생 네트워크는 리믹스된 시끄러운 오디오를 디코딩하고, 소음과 음성을 추정하고, 의사 레이블을 사용하여 손실을 계산하고, 학생 네트워크 매개변수를 업데이트합니다. 학생 네트워크에서 추정한 음성은 사전 훈련된 MetricGAN 판별기에 입력되어 PESQ를 예측하고 PESQ의 최대값으로 손실을 계산하여 학생 네트워크 매개변수를 업데이트합니다. 모든 교육 데이터가 한 번의 반복을 완료한 후 교사 네트워크의 매개변수는 다음 공식에 따라 업데이트됩니다. 교사 네트워크의 K차 교육 매개변수는 어디에 있습니까? 는 K-의 매개변수입니다. 학생 네트워크 2차. 즉, Student 네트워크의 매개변수가 일정한 가중치를 가지고 Teacher 네트워크에 추가됩니다. 데이터 증강 방법 UNA-GAN
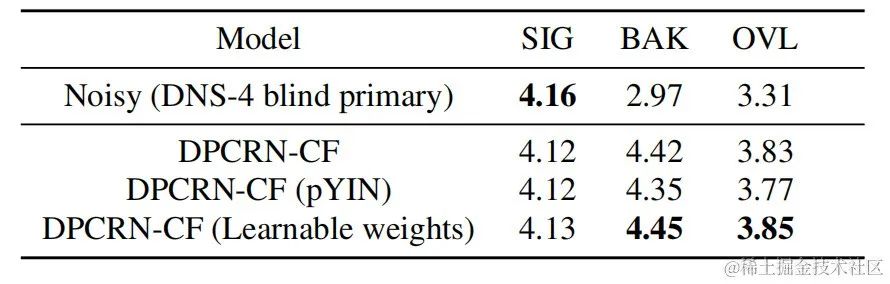
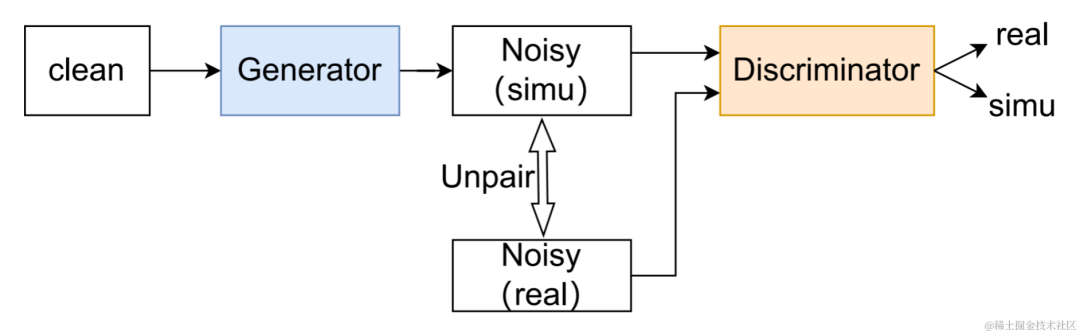
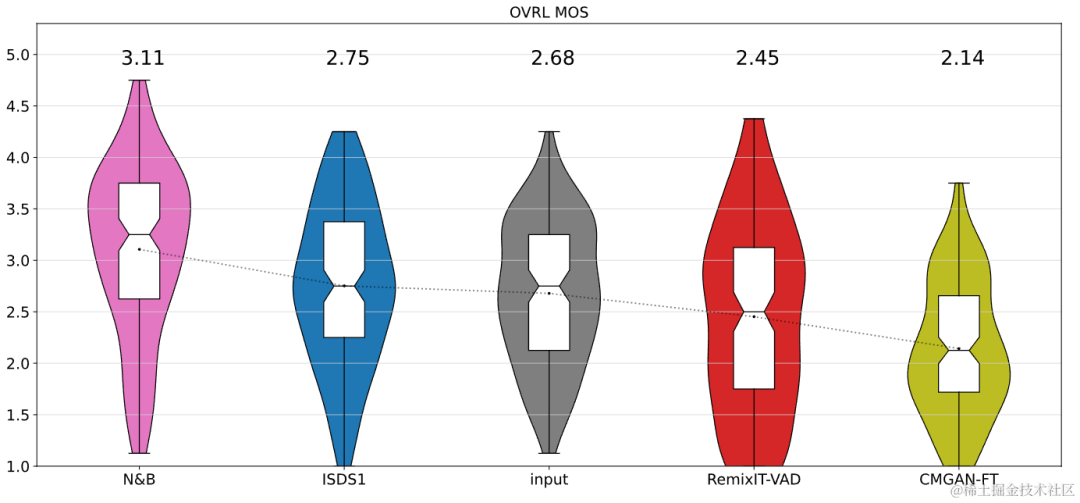
UNA-GAN 구조 다이어그램 비지도 잡음 적응형 데이터 증강 네트워크 UNA-GAN은 생성적 적대 네트워크를 기반으로 한 잡음 오디오 생성 모델입니다. 독립적인 잡음 데이터를 얻을 수 없는 경우, 영역 내의 잡음이 있는 오디오만을 사용하여 깨끗한 음성을 영역 내 잡음이 있는 잡음이 있는 오디오로 직접 변환하는 것이 목적입니다. 생성기는 깨끗한 음성을 입력하고 시뮬레이션된 시끄러운 오디오를 출력합니다. 판별기는 생성된 잡음 오디오 또는 실제 잡음 오디오를 도메인에 입력하고 입력 오디오가 실제 장면에서 나온 것인지 아니면 시뮬레이션에 의해 생성된 것인지 결정합니다. 판별기는 주로 배경 소음의 분포를 기준으로 소스를 구별하며, 이 과정에서 인간의 음성은 유효하지 않은 정보로 처리됩니다. 위의 적대적 훈련 프로세스를 수행함으로써 생성기는 입력 깨끗한 오디오에 도메인 내 잡음을 직접 추가하여 판별자를 혼란스럽게 하려고 시도합니다. 판별기는 잡음이 있는 오디오의 소스를 구별하려고 시도합니다. 생성기가 너무 많은 잡음을 추가하는 것을 방지하고 입력 오디오에서 사람의 음성을 가리기 위해 대조 학습이 사용됩니다. 샘플 256은 생성된 잡음이 있는 오디오와 입력된 깨끗한 음성에 해당하는 위치를 차단합니다. 동일한 위치에 있는 블록 쌍은 긍정적인 예로 간주되고, 다른 위치에 있는 블록 쌍은 부정적인 예로 간주됩니다. 양수 및 음수 예제를 사용하여 교차 엔트로피 손실을 계산합니다. 실험 결과결과는 제안된 Uformer+가 기본 Sudo rm-rf보다 더 강력한 성능을 가지며, 데이터 증강 방법 UNA-GAN도 도메인에서 잡음이 많은 오디오를 생성하는 기능을 가지고 있음을 보여줍니다. 도메인 적응 프레임워크 RemixIT 기준선은 SI-SDR에서 큰 개선을 달성했지만 DNS-MOS에서는 성능이 좋지 않습니다. 팀이 제안한 개선 사항 RemixIT-G는 두 지표 모두에서 동시에 효과적인 개선을 달성했으며 경쟁 블라인드 테스트 세트에서 가장 높은 주관적 청취 MOS 점수를 달성했습니다. 최종 청취 테스트 결과는 아래 그림과 같습니다.
요약 및 전망위에서는 스피커별 소음 감소, AI 인코더, 반향 제거 및 비지도 적응형 음성 향상 방향에 대한 딥 러닝을 기반으로 Volcano Engine 스트리밍 오디오 팀이 만든 몇 가지 솔루션과 효과를 소개합니다. , 다양한 터미널에서 경량 및 복잡성이 낮은 모델을 배포하고 실행하는 방법과 다중 장치 효과의 견고성과 같은 미래 시나리오는 여전히 여러 방향에서 과제에 직면해 있습니다. 이러한 과제는 앞으로도 스트리밍 오디오 팀의 초점이 될 것입니다. .연구방향. |

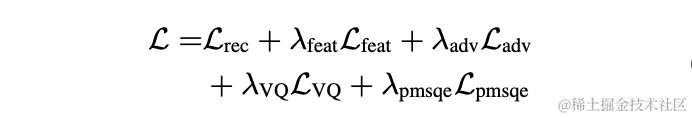


위 내용은 Interspeech 2023 | Volcano 엔진 스트리밍 오디오 기술 음성 향상 및 AI 오디오 코딩의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!