
알리 자이언트 모델이 다시 오픈소스로 공개되었습니다! 이는 완전한 이미지 이해 및 객체 인식 기능을 갖추고 있으며 일반 문제 세트 7B를 기반으로 훈련되었으며 상업적 응용이 가능합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-09-03 13:01:08739검색
Alibaba가 새로운 대형 모델을 오픈소스화했는데 매우 흥미롭습니다~
Tongyi Qianwen-7B(Qwen-7B)에 이어 Alibaba Cloud가 대형 시각적 언어 모델 Qwen-VL을 출시했습니다. 온라인에 접속하자마자 직접 오픈 소스로 제공됩니다.

Qwen-VL은 Tongyi Qianwen-7B를 기반으로 한 대형 멀티모달 모델입니다. 특히 이미지, 텍스트 및 감지 프레임과 같은 다중 입력을 지원하며 텍스트를 출력할 수 있을 뿐만 아니라 감지 프레임도 가능합니다. 출력
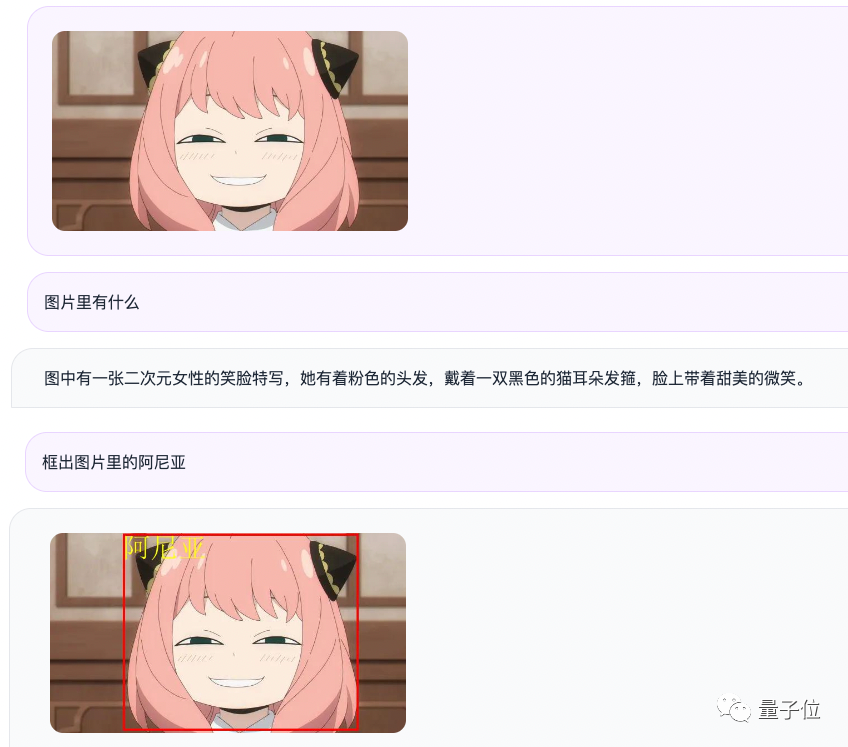
예를 들어, 질문과 답변 형식을 통해 Aniya의 사진을 입력하면 Qwen-VL-Chat은 사진의 내용을 요약하고 사진에서 Aniya를 정확하게 찾을 수 있습니다
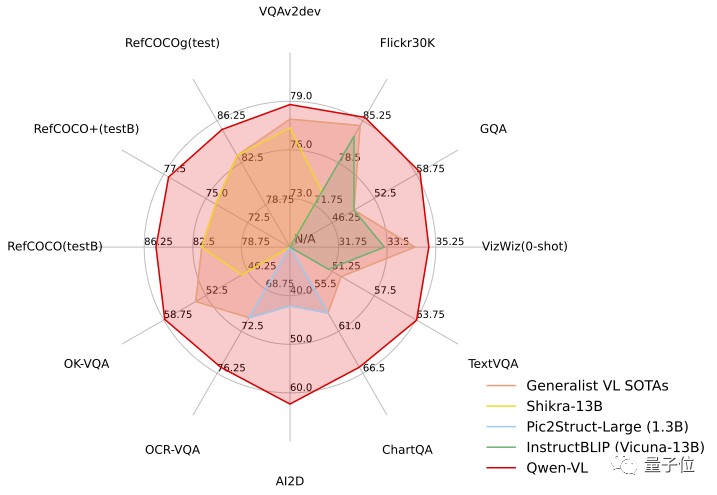
테스트 작업에서 Qwen-VL은 다중 모드 작업의 4가지 주요 범주(Zero-shot Caption/VQA/DocVQA/Grounding)에 대한 표준 영어 평가에서 1위를 차지하며 "Hexagonal Warrior"의 강점을 입증했습니다.
오픈소스 소식이 나오자마자 큰 관심을 끌었습니다

구체적인 성능을 살펴보겠습니다!
중국 오픈 도메인 포지셔닝을 지원하는 최초의 일반 모델
우선 Qwen-VL 시리즈 모델의 특징을 전반적으로 살펴보겠습니다.
- 다국어 대화: 다국어 대화 지원, 종료 -사진 속 중국어와 영어를 완벽하게 지원합니다. 이중 언어 긴 텍스트 인식
- 다중 사진 인터리브 대화: 다중 사진 입력 및 비교, 지정된 그림 질문 및 답변, 다중 사진 문학 창작 등을 지원합니다. 중국 개방형 도메인 포지셔닝을 지원하는 최초의 일반 모델: 중국 개방형 도메인 언어 표현을 통해 감지 프레임 주석, 즉 대상 개체를 그림에서 정확하게 찾을 수 있습니다.
- 세밀한 인식 및 이해: 에서 사용하는 224 해상도와 비교. 기타 오픈 소스 LVLM
- (대규모 시각적 언어 모델) , Qwen- VL은 최초의 오픈 소스 448 해상도 LVLM 모델입니다. 해상도가 높을수록 세밀한 텍스트 인식, 문서 질문 응답 및 감지 상자 주석이 향상될 수 있습니다. 원래 의미를 변경하지 않고 다시 작성해야 하는 내용은 다음과 같습니다. Qwen-VL은 지식 질문 및 답변, 이미지 질문 및 답변, 문서 질문 및 답변, 세밀한 시각적 위치 지정 등과 같은 시나리오에서 사용할 수 있습니다. .
예를 들어 외국인 친구가 중국어로 의사를 만나러 병원에 갔을 때 내비게이션 지도가 헷갈리고 해당 진료과로 가는 방법을 모를 때 직접 사진을 줄 수 있습니다. 그리고 Qwen-VL에게 질문하고 사진 정보를 바탕으로 번역기 역할을 하게 해주세요
 여러 장의 사진을 다시 입력하고 비교 테스트
여러 장의 사진을 다시 입력하고 비교 테스트
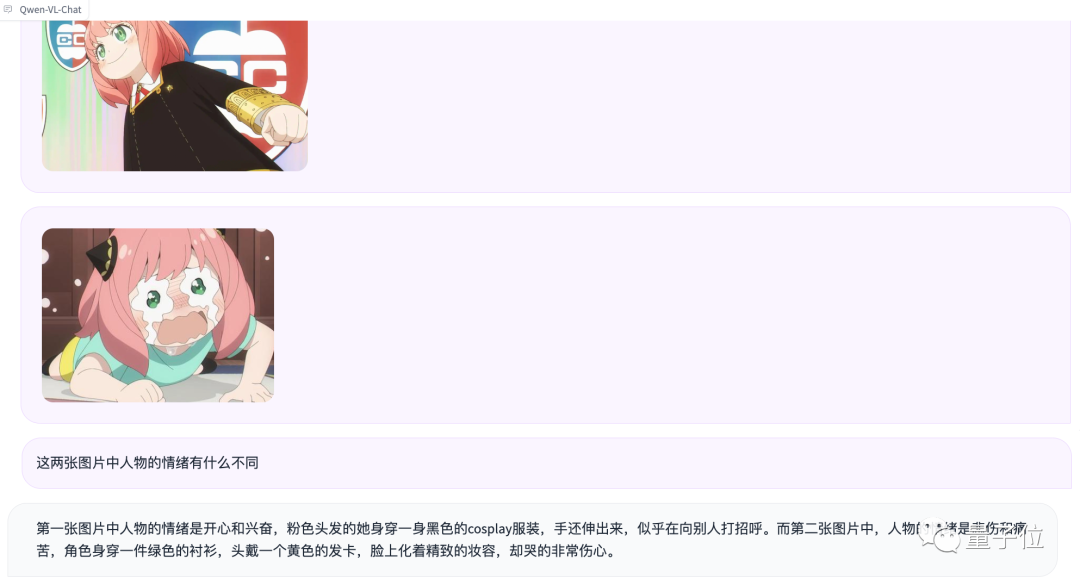 아니야는 인식하지 못했지만 감정 판단은 꽤 정확했습니다(메뉴얼 개 머리)
아니야는 인식하지 못했지만 감정 판단은 꽤 정확했습니다(메뉴얼 개 머리)
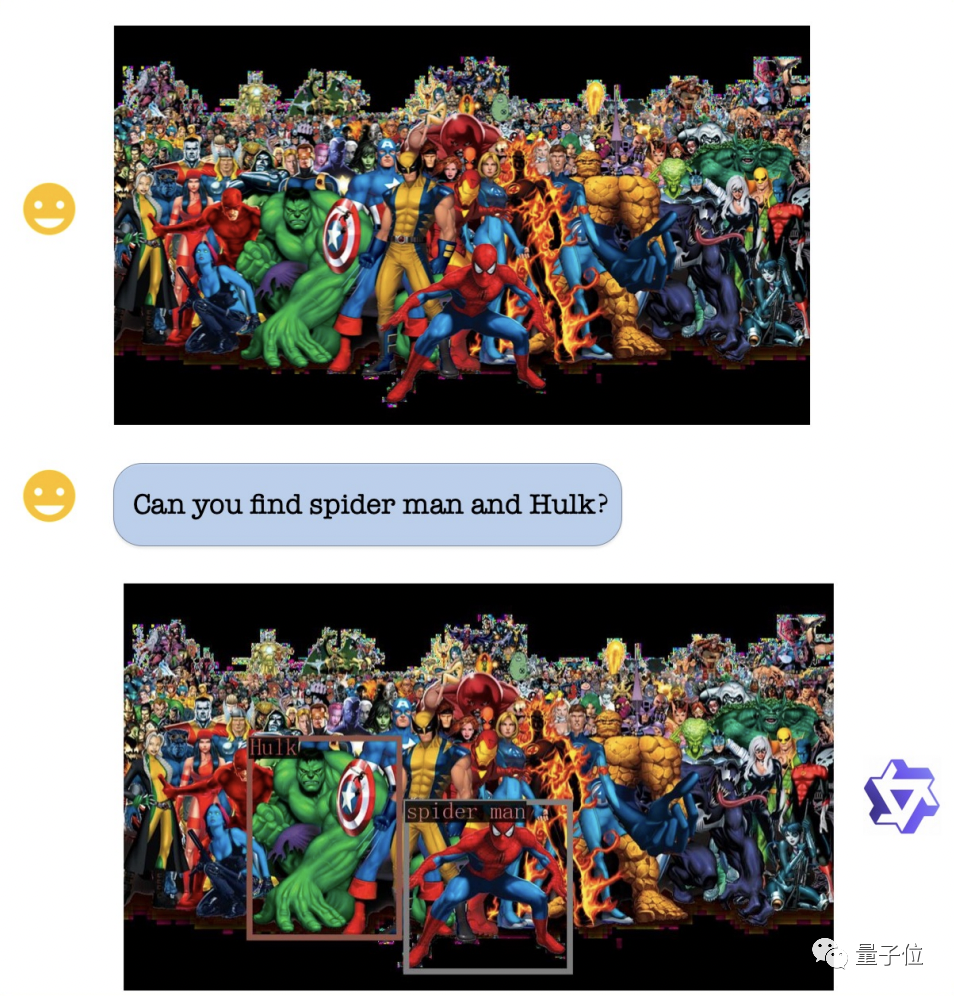
시각적 위치 파악 능력 측면에서, 그림이 매우 복잡하고 캐릭터가 많더라도 Qwen-VL은 요구 사항에 따라 수행할 수 있습니다. 헐크와 스파이더맨을 정확하게 식별할 수 있습니다.
 Qwen- VL은 기술 세부 사항에서 Qwen-7B를 기본 언어 모델로 사용하며, 시각적 인코더 ViT와 위치 인식 시각적 언어 어댑터를 도입하여 모델이 시각적 신호 입력을 지원할 수 있습니다
Qwen- VL은 기술 세부 사항에서 Qwen-7B를 기본 언어 모델로 사용하며, 시각적 인코더 ViT와 위치 인식 시각적 언어 어댑터를 도입하여 모델이 시각적 신호 입력을 지원할 수 있습니다
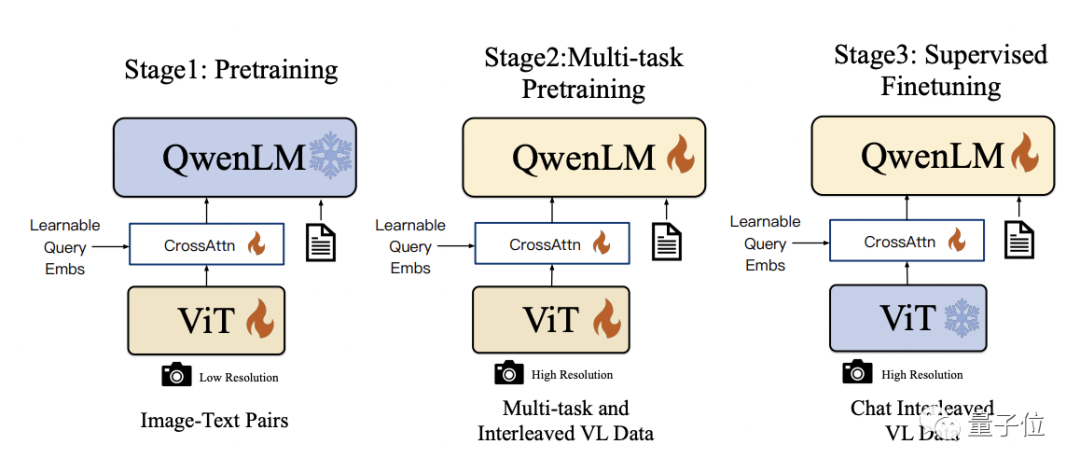
구체적인 훈련 과정은 세 단계로 나뉩니다:
- 사전 훈련: 시각적 인코더와 시각적 언어 어댑터만 최적화하고 언어 모델을 고정합니다. 대규모 이미지-텍스트 쌍 데이터를 사용하여 입력 이미지 해상도는 224x224입니다.
- 다중 작업 사전 학습: 다중 작업 공동 사전 학습을 위해 VQA, 텍스트 VQA, 참조 이해 등 더 높은 해상도(448x448) 다중 작업 시각적 언어 데이터를 도입합니다.
- 감독된 미세 조정: 시각적 인코더를 고정하고 언어 모델 및 어댑터를 최적화합니다. 신속한 조정을 위해 대화 상호 작용 데이터를 사용하여 대화형 기능을 갖춘 최종 Qwen-VL-Chat 모델을 얻습니다.
Qwen-VL의 표준 영어 평가에서 연구원들은 다중 모달 작업의 네 가지 주요 범주(Zero-shot Caption/VQA/DocVQA/Grounding)를 테스트했습니다.
결과에 따르면 Qwen-VL이 가장 좋습니다. 동일한 크기의 오픈 소스 LVLM
과 비교할 때 결과가 달성되었습니다. 또한 연구원들은 GPT-4 채점 메커니즘을 기반으로 테스트 세트 TouchStone을 구축했습니다.


Qwen-VL-Chat은 이번 비교 테스트에서 최첨단 기술(SOTA)을 달성했습니다
Qwen-VL에 관심이 있으시면 매직 커뮤니티에서 데모를 찾아보실 수 있습니다 그리고 포옹얼굴도 직접 체험해 보세요. 링크는 기사 마지막 부분에 나와 있습니다
Qwen-VL은 연구원과 개발자의 2차 개발을 지원하고 상업적 사용을 허용합니다. 하지만 상업적으로 사용하려면 먼저 설문지 신청서를 작성해야 합니다
프로젝트 링크: https://modelscope.cn/models/qwen/Qwen-VL/summary
https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary
https://huggingface.co/Qwen/Qwen-VL
https://huggingface.co/Qwen/Qwen -VL-Chat
https://github.com/QwenLM/Qwen-VL
논문을 보려면 다음 링크를 클릭하세요: https://arxiv.org/abs/2308.12966
위 내용은 알리 자이언트 모델이 다시 오픈소스로 공개되었습니다! 이는 완전한 이미지 이해 및 객체 인식 기능을 갖추고 있으며 일반 문제 세트 7B를 기반으로 훈련되었으며 상업적 응용이 가능합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!