
ACM MM 2023 | DiffBFR: Meitu와 중국 과학기술대학교가 공동으로 제안한 소음 억제 얼굴 복원 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-09-03 08:05:101058검색
BFR(Blind Face Restoration)의 목표는 낮은 품질의 얼굴 이미지에서 고품질의 얼굴 이미지를 복원하는 것입니다. 이는 컴퓨터 비전 및 그래픽 분야에서 중요한 작업으로 감시 영상 복원, 오래된 사진 복원, 얼굴 영상 초해상도 등 다양한 시나리오에서 널리 사용됩니다. 그러나 이 작업은 결정적이지 않기 때문에 매우 어렵습니다. 품질 저하로 인해 이미지 품질이 손상되고 흐림, 노이즈, 다운샘플링 및 압축 아티팩트와 같은 이미지 정보가 손실될 수도 있습니다. 이전 BFR 방법은 일반적으로 생성적 사전확률, 참조 사전확률, 기하학적 사전확률을 포함한 다양한 얼굴별 사전확률을 설계하여 이러한 문제를 해결하기 위해 생성적 적대 네트워크(GAN)에 의존했습니다. 이러한 방법은 최첨단 수준에 도달했지만 세부 사항을 복원하면서 사실적인 질감을 얻는 목표를 완전히 달성할 수는 없습니다.
이미지 복원 과정에서 얼굴 이미지의 데이터 세트는 일반적으로 고차원 공간에 분산되어 있습니다. 및 분산 기능 차원은 롱테일 분포를 나타냅니다. 이미지 분류 작업의 롱테일 분포와 달리, 이미지 복원에서의 롱테일 지역적 특징은 점, 주름, 색조 등 정체성에 미치는 영향은 작지만 시각적 효과에 큰 영향을 미치는 속성을 말합니다.
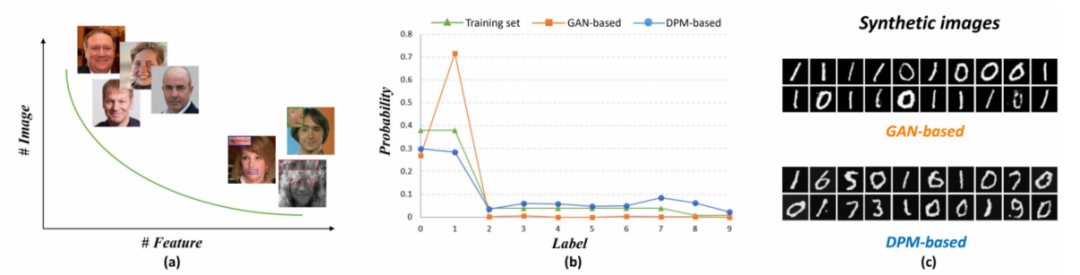
그림 1에 따르면 원래 의미를 변경하지 않기 위해 실험 결과를 중국어로 다시 작성해야 한다는 단순성이 표시됩니다. 이전 GAN 기반 방법은 머리 및 꼬리 샘플을 처리할 때 명백한 문제가 있음을 알 수 있습니다. 동시에 롱테일 분포가 발생하며 이미지를 복구할 때 오버슈팅이 발생하고 디테일이 손실됩니다. 확산 확률 모델(DPM) 기반 방법은 롱테일 분포에 더 잘 적합하고 실제 데이터 분포에 적합하면서도 꼬리 특성을 유지할 수 있습니다
Meitu 이미징 연구소(MT Lab)는 중국과학원대학교 연구진과 협력하여 새로운 맹인 얼굴 이미지 복구 방법인 DiffBFR을 제안했습니다. 이 방법은 DPM 기술을 기반으로 하며 성공적으로 달성했습니다. 눈먼 얼굴 이미지 복원, 저품질(LQ) 얼굴 이미지를 고품질(HQ) 선명한 이미지로 복구
 다시 작성해야 할 내용은 다음과 같습니다. 논문 링크: https://arxiv.org/ abs/2305.04517
다시 작성해야 할 내용은 다음과 같습니다. 논문 링크: https://arxiv.org/ abs/2305.04517
이 연구에서는 롱테일 문제를 처리할 때 GAN(Generative Adversarial Networks)과 DPM(Deep Partial Models)이라는 두 가지 생성 모델의 적응성을 탐구합니다. 적절한 얼굴 복원 모듈을 설계하면 보다 정확한 세부 정보를 얻을 수 있으며, 이를 통해 생성 방법에서 발생할 수 있는 얼굴의 과도한 스무딩 현상을 줄이고 복원의 정밀도와 정확성을 향상시킬 수 있습니다. 이 연구 논문은 ACM MM 2023
DPM 기반 블라인드 얼굴 이미지 복구 방법 - DiffBFR연구에서 확산 모델이 훈련 모드 붕괴를 피하고 긴 영상을 생성하는 피팅에서 GAN 방법보다 더 나은 것으로 나타났습니다. 꼬리 분포. 따라서 DiffBFR은 얼굴 사전 정보의 임베딩을 향상시키기 위해 확산 확률 모델을 선택하고 이를 기본 프레임워크로 사용하여 DPM을 솔루션으로 선택합니다. 확산 모델은 임의의 분포 범위 내에서 고품질의 이미지를 생성할 수 있는 강력한 능력을 갖고 있기 때문입니다
논문에서 발견한 얼굴 데이터셋의 특징의 롱테일 분포와 과거의 over-smoothing 문제를 해결하기 위해 GAN 기반 방법으로, 이 연구에서는 대략적인 롱테일 분포에 더 잘 맞고 수리 과정에서 과도한 평활화 문제를 극복하기 위한 합리적인 설계를 탐구했습니다. MNIST 데이터 세트(그림 1)에서 동일한 매개변수 크기를 사용하여 GAN과 DPM의 간단한 실험을 통해 DPM 방법은 롱테일 분포에 합리적으로 적합하지만 GAN은 머리 특징에 너무 많은 관심을 기울이고 무시한다는 사실을 발견했습니다. 결과적으로 꼬리 특징을 생성할 수 없습니다. 따라서 DPM은 BFR
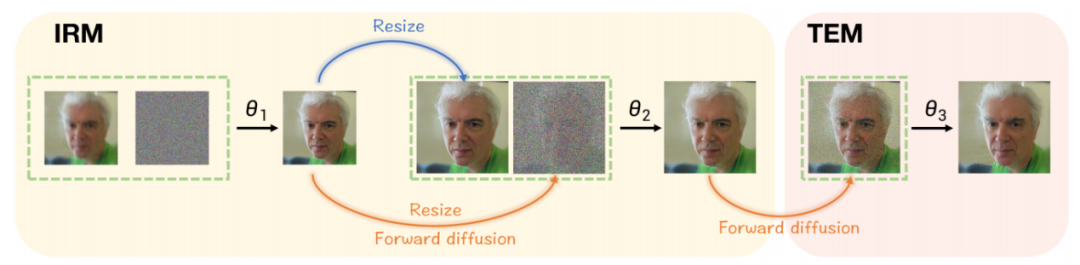
에 대한 솔루션으로 선택되었습니다. DiffBFR은 두 가지 중간 변수를 도입하여 두 가지 특정 복구 모듈을 제안합니다. 이 디자인은 먼저 LQ 이미지에서 신원 정보를 복구한 다음 실제 얼굴 분포를 기반으로 텍스처 세부 정보를 향상시키는 2단계 접근 방식을 채택합니다. 이 디자인은 두 가지 주요 부분으로 구성됩니다.
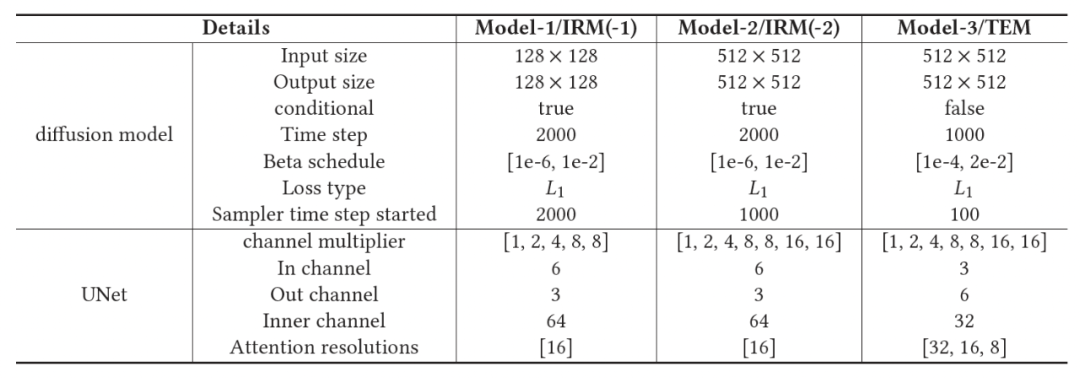
(1) IRM(신원 복원 모듈):이 모듈의 목적은 결과에서 얼굴 세부 정보를 보존하는 것입니다. 동시에 저품질 영상에 노이즈의 일부를 추가하여 역과정으로 순수 가우스 랜덤 분포를 사용하는 노이즈 제거 방법을 대체하는 잘린 샘플링 방법이 제안되었습니다. 이 논문은 이러한 변경이 DPM의 이론적 증거 하한(ELBO)을 축소하여 보다 원래의 세부 사항을 복원한다는 것을 이론적으로 증명합니다. 이론적 증거를 바탕으로 샘플링 효과를 향상시키고 고해상도 이미지를 직접 생성하는 훈련 난이도를 줄이기 위해 입력 크기가 다른 두 개의 계단식 조건부 확산 모델이 도입되었습니다. 동시에, 조건부 입력의 품질이 높을수록 실제 데이터 분포에 가까워지고 복원된 이미지가 더 정확하다는 것이 추가로 입증되었습니다. 이것이 DiffBFR이 저해상도 이미지를 먼저 복원하는 이유이기도 합니다
(2) 텍스처 강화 모듈(TEM):이미지를 다듬는 데 사용되는 방법은 무조건 확산 모델을 도입하는 것입니다. 이 모델은 저품질 이미지와 완전히 독립적이므로 복원된 결과를 실제 이미지 데이터에 더 가깝게 만듭니다. 이 논문은 순전히 고품질 이미지에 대해 훈련된 무조건 확산 모델이 픽셀 수준 공간에서 출력 이미지의 올바른 분포에 기여한다는 것을 이론적으로 증명합니다. 즉, 이 모델을 사용한 후 인페인팅된 이미지의 분포는 사용 전보다 낮은 FID를 가지며 전체적으로 고품질 이미지의 분포와 더 유사합니다. 구체적으로, 샘플링의 시간 단계 절단에 의해 식별 정보가 유지되고 픽셀 수준 텍스처가 연마됩니다. DiffBFR의 샘플링 추론 단계는 그림 2에 표시되며 샘플링 추론 프로세스의 개략도는 그림 3에 표시됩니다. 다시 작성해야 할 내용은 다음과 같습니다. 그림 3은 DiffBFR 방법의 샘플링 추론 과정의 개략도를 보여줍니다. DiffBFR 방법
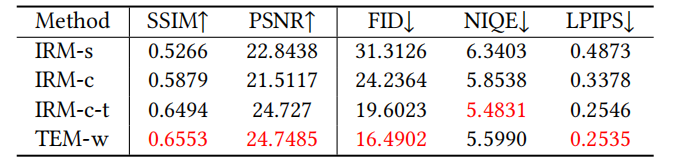
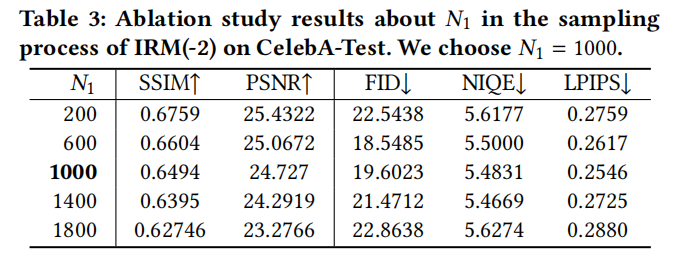
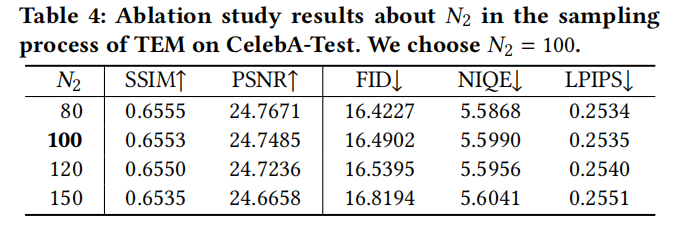
GAN 기반 BFR 방법과 DPM 기반 방법의 시각화 효과를 비교하면 다음과 같습니다. 그림 4 그림 5에서 BFR에 대한 SOTA 방식의 성능을 비교합니다 그림 6에서 BFR 방식의 시각화 비교를 보여줍니다 모델에서는 시각화를 통해 IRM과 TEM의 성능을 비교할 수 있습니다. 그림 8 모델에서는 IRM과 TEM의 성능을 비교합니다. 다시 작성해야 하는 내용은 다음과 같습니다. 다양한 매개변수에서 그림 9의 IRM 성능을 비교합니다 그림 10의 경우 다양한 매개변수의 성능을 비교해야 합니다. 재작성된 내용은 다음과 같습니다. 그림 11은 DiffBFR의 각 모듈에 대한 매개변수 설정을 보여줍니다. 본 논문에서는 기존 GAN 기반 훈련 방법의 문제점을 해결하기 위해 확산 모델 기반의 블라인드 저하 얼굴 이미지 복원 모델 DiffBFR을 제안합니다. 모드 충돌 및 롱테일 사라지는 문제. 확산 모델에 사전 지식을 삽입함으로써 심각하게 저하된 임의의 얼굴 이미지로부터 고품질의 선명한 복원 이미지를 생성할 수 있습니다. 구체적으로 본 연구에서는 현실 복원과 세부 복원에 각각 사용되는 IRM과 TEM이라는 두 가지 모듈을 제안합니다. 이론적 도출과 실험적 이미지 시연을 통해 모델의 우수성을 입증하고, 기존의 최첨단 방법과 정성적, 정량적 비교가 이루어집니다 다시 작성해야 할 것은: 연구팀 본 논문은 메이투 이미징 연구소(MT Lab)와 중국과학원 대학교 연구원들이 공동으로 제안한 것입니다. Meitu 이미징 연구소(MT Lab)는 2010년에 설립되었습니다. Meitu 팀은 컴퓨터 비전, 딥 러닝, 증강 현실 및 기타 분야의 알고리즘 연구, 엔지니어링 개발 및 제품 구현에 중점을 두고 있습니다. 팀은 설립 이후 컴퓨터 비전 분야의 연구를 탐구하는 데 전념해 왔으며 2013년부터 Meitu의 소프트웨어 및 하드웨어 제품에 대한 기술 지원을 제공하기 위해 딥 러닝을 배포하기 시작했습니다. 동시에 이미징 산업의 여러 수직 분야에 대한 대상 SaaS 서비스도 제공하고, 최첨단 이미징 기술을 통해 Meitu 인공 지능 제품의 생태학적 발전을 촉진합니다. CVPR, ICCV, ECCV 등 최고의 국제대회에 참가해 10회 이상의 우승과 준우승을 기록했으며, 48편 이상의 국제학술대회 논문을 발표했습니다. 메이투 이미징 연구소(MT Lab)는 오랫동안 이미징 분야의 연구 개발에 전념해 왔으며 풍부한 기술 보유량을 축적했으며 사진, 비디오, 디자인 및 디지털 피플 분야에서 풍부한 기술 구현 경험을 보유하고 있습니다
 원래의 의미를 바꾸지 않기 위해 실험 결과를 중국어로 다시 작성해야 합니다
원래의 의미를 바꾸지 않기 위해 실험 결과를 중국어로 다시 작성해야 합니다



 요약은 정보를 결합하거나 아이디어를 간결하고 명확하게 재구성하는 과정입니다. 원래의 의미를 바꾸지는 않지만, 다른 어휘와 문장 구조를 사용하여 동일한 개념을 제시합니다. 요약의 목적은 독자가 전달된 정보를 더 쉽게 이해하고 소화할 수 있도록 더 명확하고 간결한 프레젠테이션을 제공하는 것입니다. 요약은 학술 논문, 비즈니스 보고서, 일상 커뮤니케이션 등 다양한 상황에서 중요한 아이디어와 결론을 전달하는 데 유용합니다. 요약하면, 요약은 정보를 보다 효과적으로 전달하고 이해하는 데 도움을 줄 수 있는 중요한 의사소통 도구입니다.
요약은 정보를 결합하거나 아이디어를 간결하고 명확하게 재구성하는 과정입니다. 원래의 의미를 바꾸지는 않지만, 다른 어휘와 문장 구조를 사용하여 동일한 개념을 제시합니다. 요약의 목적은 독자가 전달된 정보를 더 쉽게 이해하고 소화할 수 있도록 더 명확하고 간결한 프레젠테이션을 제공하는 것입니다. 요약은 학술 논문, 비즈니스 보고서, 일상 커뮤니케이션 등 다양한 상황에서 중요한 아이디어와 결론을 전달하는 데 유용합니다. 요약하면, 요약은 정보를 보다 효과적으로 전달하고 이해하는 데 도움을 줄 수 있는 중요한 의사소통 도구입니다.
위 내용은 ACM MM 2023 | DiffBFR: Meitu와 중국 과학기술대학교가 공동으로 제안한 소음 억제 얼굴 복원 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!