
GET3D의 생성 모델에 대한 심층적인 5분 기술 강연

- 王林앞으로
- 2023-09-01 19:01:061357검색
Part 01●
서문
최근에는 Midjourney와 Stable Diffusion으로 대표되는 인공지능 이미지 생성 툴이 등장하면서 2D 인공지능 이미지 생성 기술은 실제 프로젝트에서 많은 디자이너들이 사용하는 보조 툴이 되었습니다. 다양한 비즈니스 시나리오에 적용되어 점점 더 실용적인 가치를 창출합니다. 동시에, 메타버스(Metaverse)의 등장으로 많은 산업이 대규모의 3D 가상 세계를 만드는 방향으로 움직이고 있으며, 게임, 로봇공학, 건축, 산업 등 산업에서는 다양하고 고품질의 3D 콘텐츠가 점점 중요해지고 있습니다. 그리고 소셜 플랫폼. 그러나 3D 자산을 수동으로 생성하려면 시간이 많이 걸리고 특정 예술 및 모델링 기술이 필요합니다. 주요 과제 중 하나는 규모 문제입니다. 3D 시장에서 찾을 수 있는 3D 모델의 수가 많음에도 불구하고 게임이나 영화에서 모두 다르게 보이는 캐릭터나 건물 그룹을 채우려면 여전히 아티스트의 상당한 투자가 필요합니다. 시간. 결과적으로 3D 콘텐츠의 수량, 품질, 다양성 측면에서 확장할 수 있는 콘텐츠 제작 도구의 필요성이 점점 더 분명해지고 있습니다.
 Pictures
Pictures
그림 1을 참조하세요. 이것은 메타버스 공간의 사진입니다( 출처: 영화 "주먹왕 랄프 2")
2D 생성 모델이 고해상도 이미지 합성에서 사실적인 품질을 달성했다는 사실 덕분에 이러한 발전은 3D 콘텐츠 생성에 대한 연구에도 영감을 주었습니다. 초기 방법은 2D CNN 생성기를 3D 복셀 그리드로 직접 확장하는 것을 목표로 했지만 3D 컨볼루션의 높은 메모리 공간과 계산 복잡성으로 인해 고해상도 생성 프로세스가 방해를 받았습니다. 대안으로 다른 연구에서는 포인트 클라우드, 암시적 또는 옥트리 표현을 탐색했습니다. 그러나 이러한 작업은 주로 형상 생성에 중점을 두고 외관을 무시합니다. 표준 그래픽 엔진과 호환되도록 출력 표현도 후처리해야 합니다.
콘텐츠 제작에 실용적이려면 이상적인 3D 생성 모델이 다음 요구 사항을 충족해야 합니다.
기하학적으로 3D 그래픽을 생성할 수 있는 능력이 있어야 합니다. 세부 사항 및 임의 토폴로지 모양의 능력
콘텐츠 재작성: (b) 출력은 Blender 및 Maya와 같은 표준 그래픽 소프트웨어에서 사용되는 일반적인 표현인 텍스처 메쉬여야 합니다.
2D 이미지를 그대로 사용하여 감독할 수 있습니다. 명시적인 3D 형상보다 훨씬 작음 보다 일반적으로
Part 02
3D 생성 모델 소개
콘텐츠 제작 프로세스를 촉진하고 실용적인 응용을 가능하게 하기 위해 생성 3D 네트워크는 고품질의 다양한 3D를 생성할 수 있는 활발한 연구 분야가 되었습니다. 자산. 다음과 같은 최첨단 모델을 포함하여 매년 ICCV, NeurlPS, ICML과 같은 컨퍼런스에서 많은 3D 생성 모델이 발표됩니다.
Textured3DGAN은 질감이 있는 3D 메시를 생성하는 컨볼루셔널 방법을 확장한 생성 모델입니다. 2D 감독 하에 GAN을 사용하여 물리적 이미지에서 텍스처 메쉬를 생성하는 방법을 학습할 수 있습니다. 이전 방법과 비교하여 Textured3DGAN은 포즈 추정 단계의 핵심 사항에 대한 요구 사항을 완화하고 ImageNet
DIB-R과 같은 레이블이 없는 이미지 컬렉션 및 새로운 카테고리/데이터 세트에 대한 방법을 일반화합니다. 하단의 PyTorch 머신러닝 프레임워크. 이 렌더러는 3D Deep Learning PyTorch GitHub 저장소(Kaolin)에 추가되었습니다. 이 방법을 사용하면 이미지의 모든 픽셀에 대한 그라데이션을 분석적으로 계산할 수 있습니다. 핵심 아이디어는 전경 래스터화를 로컬 속성의 가중치 보간으로 처리하고 배경 래스터화를 전역 기하학의 거리 기반 집계로 처리하는 것입니다. 이런 방식으로 단일 이미지에서 모양, 질감, 빛과 같은 정보를 예측할 수 있습니다.
PolyGen: PolyGen은 메시를 직접 모델링하기 위한 Transformer 아키텍처 기반의 자동 회귀 생성 모델입니다. 모델은 메쉬의 정점과 면을 차례로 예측합니다. 우리는 ShapeNet Core V2 데이터 세트를 사용하여 모델을 훈련했으며 결과는 이미 인간이 구성한 메시 모델과 매우 유사합니다.
SurfGen: 명시적 표면 판별자를 사용한 적대적 3D 형상 합성. 엔드투엔드 훈련 모델은 다양한 토폴로지를 사용하여 충실도가 높은 3D 모양을 생성할 수 있습니다.
GET3D는 이미지 학습을 통해 고품질의 3D 질감 모양을 생성할 수 있는 생성 모델입니다. 핵심은 미분 가능한 표면 모델링, 미분 가능한 렌더링 및 2D 생성적 적대 네트워크입니다. 2D 이미지 모음을 학습함으로써 GET3D는 복잡한 토폴로지, 풍부한 기하학적 세부 사항 및 충실도가 높은 텍스처
 images
images
를 사용하여 명시적으로 질감이 있는 3D 메쉬를 직접 생성할 수 있습니다. (출처: GET3D 종이 공식 웹사이트 https://nv-tlabs.github.io/GET3D/)
GET3D는 ShapeNet, Turbosquid 및 Renderpeople과 같은 복잡한 형상을 가진 여러 모델을 사용하는 최근 제안된 3D 생성 모델입니다. 의자, 오토바이, 자동차, 사람, 건물 등 3D 형상을 무제한으로 생성해 최첨단 성능을 발휘합니다
Part 03
GET3D
 Pictures
Pictures
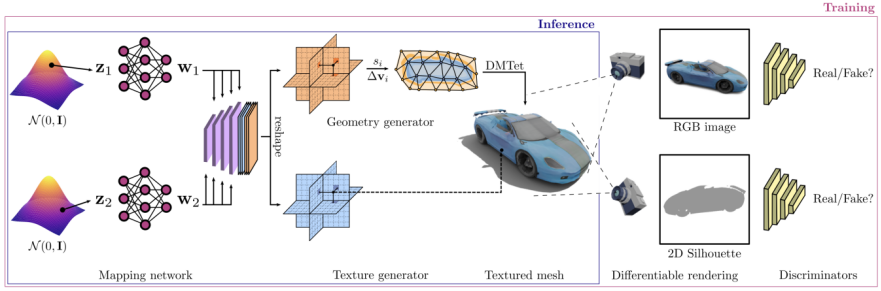
GET3D 아키텍처의 아키텍처와 특성은 GET3D paper 공식 웹사이트에서 가져온 것입니다. 그림 3은 아키텍처를 보여줍니다
A 3D SDF(Directed Distance Field)는 두 가지 잠재적인 인코딩을 통해 생성됩니다. 그런 다음 DMTet(Deep Marching Tetrahedra)를 사용하여 SDF에서 3D 표면 메쉬를 추출하고 표면 포인트 클라우드의 텍스처 필드를 쿼리하여 색상을 얻습니다. 전체 프로세스는 2D 이미지에 정의된 적대적 손실을 사용하여 학습됩니다. 특히, 래스터화 기반 미분 가능 렌더러를 사용하여 RGB 이미지와 윤곽선을 얻습니다. 마지막으로 입력이 진짜인지 가짜인지 구별하기 위해 각각 RGB 이미지와 윤곽선에 대해 두 개의 2D 판별자가 사용됩니다. 전체 모델을 엔드 투 엔드로 훈련할 수 있습니다.
GET3D는 다른 측면에서도 매우 유연하며 명시적인 메시를 출력으로 표현하는 것 외에 다음을 포함한 다른 작업에 쉽게 적응할 수 있습니다.
별도의 지오메트리 및 텍스처 구현: 지오메트리 간의 우수한 디커플링 텍스처가 달성되어 형상 잠재 코드와 텍스처 잠재 코드의 의미 있는 보간이 가능합니다.
잠재 공간에서 무작위 이동을 수행하여 다양한 클래스의 모양 간에 부드러운 전환을 생성하고 해당 3D 모양을 생성하여 달성합니다.
새로운 생성 모양: 로컬 잠재 코드에 약간의 노이즈를 추가하여 로컬로 유사하지만 약간 다른 모양을 생성함으로써 교란될 수 있습니다.
비지도 재료 생성: DIBR++와 결합하여 완전히 비지도 방식으로 재료를 생성하고 의미 있는 뷰를 생성합니다. -종속 조명 효과
텍스트 기반 모양 생성: StyleGAN NADA를 결합하여 계산적으로 렌더링된 2D 이미지와 사용자 제공 텍스트를 활용합니다. 방향성 CLIP 손실을 사용하여 3D 생성기를 미세 조정하면 사용자는 다음을 통해 의미 있는 많은 모양을 생성할 수 있습니다. 텍스트 프롬프트
 Pictures
Pictures
텍스트를 기반으로 도형을 생성하는 과정을 보여주는 그림 4를 참조하세요. 이 그림의 출처는 GET3D 논문의 공식 웹사이트이며, URL은 https://nv-tlabs.github.io/GET3D/
Part 04
Summary
하지만 GET3D는 실용적인 3D를 향해 한발 더 나아갔습니다. 텍스처 모양 생성 모델 중요한 단계이지만 여전히 몇 가지 제한 사항이 있습니다. 특히 훈련 과정은 여전히 2D 실루엣과 카메라 분포에 대한 지식에 의존합니다. 따라서 현재 GET3D는 합성 데이터를 기반으로만 평가할 수 있습니다. 유망한 확장은 인스턴스 분할 및 카메라 포즈 추정의 발전을 활용하여 이 문제를 완화하고 GET3D를 실제 데이터로 확장하는 것입니다. GET3D는 현재 카테고리에 따라서만 학습되며, 카테고리 간의 다양성을 더 잘 표현하기 위해 향후 여러 카테고리로 확장될 예정입니다. 이 연구가 사람들이 인공 지능을 사용하여 3D 콘텐츠를 무료로 만드는 데 한 걸음 더 다가갈 수 있기를 바랍니다
위 내용은 GET3D의 생성 모델에 대한 심층적인 5분 기술 강연의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!