
집 >Java >Java인터뷰 질문들 >지난주에 XX보험 인터뷰했는데 멋있었어요! ! !
지난주에 XX보험 인터뷰했는데 멋있었어요! ! !
- Java后端技术全栈앞으로
- 2023-08-25 15:44:191723검색
지난주에 일행 중 한 친구가 핑안보험에 면접을 갔습니다. 결과가 좀 아쉽기도 하지만, 말씀하신 것처럼 당황하지 않으셨으면 좋겠습니다. 면접은 기본적으로 모두 OK입니다. 뒷면의 문제를 잘 읽어보셨으니 열심히 해주세요!
이외에도 궁금하신 점이 있으시면 편하게 오셔서 함께 논의하고 발전해 나가시기 바랍니다.
너무 멀리 가지 말고 본론으로 들어가겠습니다. 아래는 이 학생이 정리한 기술 면접 질문과 참고 답변입니다.
Java의 스레드로부터 안전한 클래스는 무엇인가요?
Vector、Hashtable、StringBuffer. 그들은 모두 스레드 안전성을 달성하기 위해 메서드에 동기화 잠금을 추가합니다.
또한 JUC 패키지에는 모든 컬렉션 클래스가 있습니다
ArrayBlockingQueue 、ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque等,这些也是线程안전한。ArrayBlockingQueue 、ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque等,这些也是线程安全的。
幸好这么回答就算结束了,面试官也没再问了,不然JUC下的这几个我真回答不上来。
Java创建对象有几种方式?
这个问题相对还是简单的,能说上个123应该都没问题了。
Java
幸好这么回答就算结束了,면试官也没再问了,不然JUC下的这几个我真回答不上来。
Java创建对象有几种方式?
🎜这个问题상对还是简单的,能说上个123应该ت没问题了。🎜
Java中提供了以下 4种어떤 방법으로든:🎜new는 리플렉션 메커니즘을 통해 새 개체를 생성합니다 복제 메커니즘을 사용하여 직렬화 메커니즘을 통해
Object의 일반적인 메서드는 무엇인가요?
당시엔 String, equals, hashCode, wait,notify,notifyAll만 기억났는데. 다른 것은 생각하지 않았습니다. 면접관은 괜찮을 것 같다는 인상을 주면서 계속 고개를 끄덕였습니다.
java.lang.Object
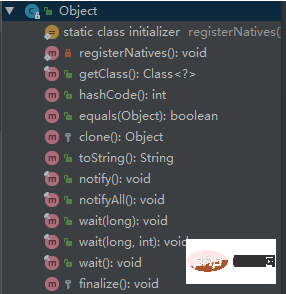
해당 메소드의 의미는 다음과 같습니다.
clone 메서드
개체의 얕은 복사본을 구현하는 보호 메서드입니다. 이 메서드는 Cloneable 인터페이스가 구현된 경우에만 호출할 수 있습니다. 그렇지 않으면 CloneNotSupportedException 예외도 Cloneable과 해당 멤버를 구현해야 합니다. 변수는 참조 유형입니다. Cloneable을 구현한 다음 clone 메서드를 재정의해야 합니다.
finalize 메서드
이 메서드는 가비지 수집기와 관련이 있으며 개체를 재활용할 수 있는지 확인하는 마지막 단계는 이 메서드가 재정의되었는지 확인하는 것입니다.
equals method
이 방법은 매우 자주 사용됩니다. 일반적으로 같음과 ==는 다르지만 Object에서는 동일합니다. 서브클래스는 일반적으로 이 메서드를 재정의합니다.
hashCode 메서드
이 메서드는 해시 검색에 사용됩니다. 일반적으로 equals 메서드를 재정의하려면 hashCode 메서드를 다시 작성해야 합니다. 이 메서드는 해시 함수가 있는 일부 컬렉션에서 사용됩니다.
일반적으로 obj1.equals(obj2)==true。可以推出 obj1.hashCode()==obj2.hashCode()를 만족해야 하지만, hashCode가 동일하다고 해서 반드시 동등을 만족하는 것은 아닙니다. 그러나 효율성을 높이기 위해서는 위의 두 조건을 최대한 동일하게 만들도록 노력해야 합니다.
JDK 1.6 및 1.7에서는 기본적으로 난수를 반환합니다. JDK 1.8에서는 기본적으로 현재 스레드와 관련된 난수 + 3개의 특정 값을 사용하며, 난수를 얻기 위해 Marsaglia의 xorshift 체계 난수 알고리즘을 사용합니다.
wait 메소드
는 동기화와 함께 사용됩니다. 대기 메소드는 현재 스레드가 객체의 잠금을 기다리도록 합니다. 즉, 객체의 잠금이 있어야 합니다. 물체. wait() 메서드는 잠금을 획득하거나 중단될 때까지 기다립니다. wait(long timeout)은 타임아웃 간격을 설정하고 지정된 시간 내에 잠금을 획득하지 못한 경우 반환합니다.
이 메서드를 호출한 후 현재 스레드는 다음 이벤트가 발생할 때까지 절전 상태에 들어갑니다.
객체의 알림 메소드를 호출한 다른 스레드 스레드를 중단하기 위해 인터럽트를 호출한 다른 스레드; . 이때 스레드가 중단되면 InterruptedException이 발생합니다. - notify 메소드 는 동기화와 함께 사용됩니다. 이 메소드는 객체의
에 있는 스레드를 깨웁니다(동기화 큐의 스레드는 CPU를 선점하는 스레드를 위한 것이고, 대기 중인 스레드는 큐는 깨어난 스레드를 기다리는 것을 의미합니다).
notifyAll 메서드
는 동기화와 함께 사용됩니다. 이 메서드는 이 개체의 대기열에 대기 중인 모든 스레드를 깨웁니다.
hashCode 방식과 Equals 방식의 관계는 무엇인가요
이 질문을 했을 때 면접관이 제 기초를 의심하고 있다는 느낌이 들었지만 이 질문은 그래도 가능합니다. 답변을 받다.
a.equals(b)가 "true"를 반환하면 hashCode()는 동일해야 합니다. hashCode()必须相等。
如果a.equals(b)返回“false”,那么a和b的hashCode()
hashCode()는 같을 수도 있고 다를 수도 있습니다. 🎜해시코드의 역할
정말 일련의 질문이고, 차례로 답변이 이상적이지는 않지만 관련성이 있습니다.
Java에는 두 가지 유형의 컬렉션이 있습니다. , 한 유형은 목록이고 다른 유형은 설정입니다. 전자는 질서 있고 반복 가능한 반면, 후자는 무질서하고 반복 불가능합니다. 요소를 세트에 삽입할 때 요소가 이미 존재하는지 확인하는 방법은 무엇입니까? 그러나 요소가 너무 많으면 이 방법이 더 꽉 차게 됩니다. Java的集合有两类,一类是List,还有一类是Set。前者有序可重复,后者无序不重复。当我们在set中插入的时候怎么判断是否已经存在该元素呢,可以通过equals方法。但是如果元素太多,用这样的方法就会比较满。
于是有人发明了哈希算法来提高集合中查找元素的效率。这种方式将集合分成若干个存储区域,每个对象可以计算出一个哈希码,可以将哈希码分组,每组分别对应某个存储区域,根据一个对象的哈希码就可以确定该对象应该存储的那个区域。
hashCode方法可以这样理解:它返回的就是根据对象的内存地址换算出的一个值。这样一来,当集合要添加新的元素时,先调用这个元素的hashCode
hashCode 메소드는 다음과 같이 이해될 수 있습니다. : it 반환되는 것은 객체의 메모리 주소를 기준으로 계산된 값입니다. 이러한 방식으로 새 요소가 컬렉션에 추가되면 해당 요소의 hashCode 메소드를 사용하면 배치해야 할 물리적 위치를 즉시 찾을 수 있습니다. 이 위치에 요소가 없으면 비교 없이 이 위치에 직접 저장할 수 있습니다. 이 위치에 이미 요소가 있으면 해당 요소의 equals 메서드를 호출하여 새 요소와 비교합니다. 저장되지 않습니다. 동일하지 않은 경우 다른 주소를 해시합니다. 이런 방식으로, 실제로 equals 메소드를 호출하는 횟수는 거의 한두 번으로 크게 줄어듭니다. 🎜Spring Boot의 자동 조립 원리에 대해 이야기해 볼까요
이 질문도 이력서에 써있으니까
Spring Boot,所以被问到也是正常的,不过我面试前还是看过一些,回答的还行,面试官说差不多是这个意思。
在Spring Boot中有个很关键的注解@SpringBootApplication ,其中这个注解又可以等同于
- @SpringBootConfiguration
- @EnableAutoConfiguration
- @ComponentScan
여기서@EnableAutoConfiguration이 핵심입니다(활성화 자동 구성) 내부적으로 실제로 META-INF/봄. 팩토리 파일 정보를 확인한 다음 EnableAutoConfiguration은 핵심 데이터이며 IOC 컨테이너에 로드되어 자동 구성 기능을 구현합니다! @EnableAutoConfiguration是关键(启用自动配置),内部实际上就去加载META-INF/spring.factories文件的信息,然后筛选出以EnableAutoConfiguration为key的数据,加载到IOC容器中,实现自动配置功能!
数据库事务的隔离级别有哪些?
这种问题,背背八股文,网上一堆堆。
数据库事务的隔离级别有4种,由低到高分别为Read uncommitted 、Read committed、Repeatable read、Serializable
데이터베이스 트랜잭션의 격리 수준은 무엇입니까?
🎜 데이터베이스 트랜잭션에는 낮은 수준에서 높은 수준까지 4가지 격리 수준이 있습니다.이런 종류의 질문에 대해서는 8가지를 기억하세요. 다리가 있는 에세이, 온라인에 많이 있습니다.
커밋되지 않은 읽기 、커밋된 읽기, 반복 읽기 코드 >, <code style="margin-right: 2px;margin-left: 2px;padding: 2px 4px;font-size: 14px;border-radius: 4px; background-color: rgba(27, 31, 35, 0.05 ) ;font-family: " operator mono consolas monaco menlo monospace break-all rgb>직렬화 가능. 🎜커밋되지 않은 읽기( 커밋되지 않은 읽기) : 이 격리 수준에서는 다른 트랜잭션이 이 트랜잭션의 커밋되지 않은 수정 사항을 볼 수 있으며 이로 인해 더티 읽기 문제가 발생합니다(다른 트랜잭션의 커밋되지 않은 부분을 읽은 다음 트랜잭션이 롤백됨).READ COMMITTED) : 다른 트랜잭션은 읽기만 가능합니다. 이 격리 수준에서는 동일한 트랜잭션에서 두 번 읽은 후 얻은 결과가 실제로 다릅니다. "READ UNCOMMITTED):这个隔离级别下,其他事务可以看到本事务没有提交的部分修改,因此会造成脏读的问题(读取到了其他事务未提交的部分,而之后该事务进行了回滚);已提交读( READ COMMITTED):其他事务只能读取到本事务已经提交的部分,这个隔离级别有不可重复读的问题,在同一个事务内的两次读取,拿到的结果竟然不一样,因为另外一个事务对数据进行了修改;"可重复读( REPEATABLE READ)。可重复读隔离级别解决了上面不可重复读的问题,但是仍然有一个新问题,就是幻读。当你读取id> 10 的数据行时,对涉及到的所有行加上了读锁,此时例外一个事务新插入了一条id=11的数据,因为是新插入的,所以不会触发上面的锁的排斥,那么进行本事务进行下一次的查询时会发现有一条id=11的数据,而上次的查询操作并没有获取到,再进行插入就会有主键冲突的问题;可串行化( SERIALIZABLE
반복 읽기). 반복 읽기 격리 수준은 위의 반복 불가능 읽기 문제를 해결하지만 여전히 팬텀 읽기라는 새로운 문제가 있습니다. id>10인 데이터 행을 읽으면 관련된 모든 행에 읽기 잠금이 추가됩니다. 이때 트랜잭션은 id=11인 데이터를 새로 삽입하므로 위의 내용은 발생하지 않습니다. 잠금이 배타적이면 이 트랜잭션의 다음 쿼리를 수행할 때 ID가 11인 데이터 조각을 찾을 수 있지만 마지막 쿼리 작업에서는 이를 얻지 못했습니다. 기본 키 충돌 문제
Serialized(직렬화 가능 ). 이는 위에서 언급한 모든 문제를 해결할 수 있는 가장 높은 격리 수준으로, 모든 작업을 순차적으로 실행하도록 강제하여 동시성 성능이 급격히 저하되므로 일반적으로 사용되지 않습니다.
MySQL의 인덱스에 대한 이해를 알려주세요🎜🎜🎜🎜🎜🎜이 질문은 알겠습니다. 아는 만큼 알려주세요. 다들 준비하는 걸 보니 저는 꽤 준비가 잘 되어 있었어요. 제 답변이 꽤 좋은 것 같아서 지수의 장단점을 함께 답변해 봤습니다. 🎜
Index는 MySQL이 효율적으로 데이터를 얻을 수 있게 해주는 데이터 구조입니다. 보다 일반적으로 말하면, 데이터베이스 인덱스는 책 앞부분의 목차와 같으며, 이는 데이터베이스 쿼리 속도를 높일 수 있습니다.
장점
데이터베이스 테이블의 각 데이터 행의 고유성을 보장할 수 있습니다. 데이터의 인덱싱 속도를 크게 높일 수 있습니다. 특히 데이터 참조를 구현할 때 테이블 간 연결을 가속화합니다. 특히 완전성 측면에서 의미가 깊습니다 데이터 검색을 위해 그룹화 및 정렬 절을 사용할 경우 쿼리에서 그룹화 및 정렬 시간도 크게 줄일 수 있습니다 인덱스를 사용하면 시간 쿼리 프로세스 중에 최적화 숨김기를 사용합니다. 시스템 성능 향상
단점
인덱스 생성 및 유지 관리에 시간이 걸리고, 데이터 양이 많아질수록 시간이 늘어납니다. 인덱스는 데이터 외에 물리적인 공간을 차지해야 합니다. 테이블이 점유하므로 각 인덱스도 일정량의 물리적 공간을 차지합니다. 클러스터형 인덱스를 구축해야 하는 경우 필요한 공간은 더 커집니다. 테이블에 데이터를 추가, 삭제, 수정할 때 인덱스는 반드시 또한 동적으로 유지 관리되므로 정수의 유지 관리 속도가 줄어듭니다
어떤 SQL 최적화 방법에 익숙합니까?
이 부분은 Tian 형제의 Knowledge Planet에서 "Essential MySQL Database Knowledge for Java Programmers"를 읽으면서 배웠습니다. Tian 형제가 컴파일을 많이 했기 때문에 일부만 이야기했습니다. 좋은 기억이군.
1. select *
2를 사용하지 마세요. 대신 하위 쿼리(왼쪽 조인, 오른쪽 조인, 내부 조인)를 사용해 보세요.
3. IN 또는 NOT IN 사용을 줄이고, 존재하지 않음을 사용하세요. 아니면 연관된 쿼리문을 교체하세요
4. 또는 쿼리 대신에 Union 또는 Union All을 사용해 보세요(중복된 데이터가 없거나 중복된 데이터를 제거할 필요가 없다는 것이 확인되면 Union All이 더 좋습니다)
5 . where 절에서 사용하지 마십시오. != 또는 a8093152e673feb7aba1828c43532094 연산자를 사용하십시오. 그렇지 않으면 엔진이 인덱스 사용을 포기하고 전체 테이블 스캔을 수행합니다.
6. where 절에 있는 필드의 null 값을 판단하지 마십시오. 그렇지 않으면 엔진이 인덱스 사용을 포기하고 다음과 같이 전체 테이블 스캔을 수행합니다. 여기서 num은 null입니다. num의 기본값은 0입니다. 테이블의 num 열에 null 값이 없는지 확인한 후 다음과 같이 쿼리합니다. select id from t where num=0
SQL 쿼리는 MySQL에서 어떻게 실행되나요?
NND, 저는 MySQL에 대해 너무 많이 물어보는 걸 좋아하는데, 이 질문이 저를 정말 혼란스럽게 만들었고, 면접관은 말도 안되는 이야기를 한 후 조금 초조해졌습니다. 돌아와서 Tian Ge's Knowledge Planet을 살펴보니 역시 거의 똑같은 면접 질문이었는데, 준비가 안 됐다고 자책했습니다.
예를 들어 다음 SQL 문(면접관이 현장에서 제공한SQL):
select 字段1,字段2 from 表 where id=996
링크를 가져오고 MySQL에서 커넥터를 사용하세요. 쿼리 캐시, 키는 SQL 문, 값은 쿼리 결과이며, 발견되면 직접 반환됩니다. MySQL 8.0 버전에서는 쿼리 캐시가 삭제되어 MySQL 8.0 버전 이후에는 이 기능이 존재하지 않습니다. Analyzer, 어휘 분석과 구문 분석으로 구분됩니다. 이 단계에서는 일부 SQL 구문 분석 및 구문 확인만 수행합니다. 따라서 이 단계에서는 일반적인 문법 오류가 발생합니다. Optimizer는 테이블에 여러 인덱스가 있거나 명령문에 다중 테이블 연결(조인)이 있는 경우 사용할 인덱스를 결정하며 각 테이블의 연결 순서를 결정합니다. Executor, 분석기를 통해 수행하려는 작업을 SQL에 알리고, 최적화 프로그램을 통해 수행할 작업을 확인한 다음 명령문 실행을 시작하세요. 명령문을 실행할 때 이 권한이 있는지 여부도 확인해야 합니다. 권한이 없으면 권한이 없다는 오류가 직접 반환됩니다. 테이블을 열고 인터페이스를 사용하세요. 테이블의 엔진 정의에 따라 테이블의 첫 번째 행을 가져오기 위해 엔진에서 제공하는 ID가 1인지 확인합니다. 그렇다면 직접 반환하고, 다음 행으로 이동하기 위해 엔진 인터페이스를 계속 호출하지 않으면 테이블의 마지막 행을 가져올 때까지 동일한 판단을 반복하고 마지막으로 반환합니다.
996이 무슨 뜻인지 궁금합니다. 귀하의 회사가 996인가요? 아무렇지도 않게 말해보세요
JVM에서 힙과 스택의 차이점은 무엇인가요?
이것은 나쁘지 않습니다. JVM 지식이 있으면 대답할 수 있습니다. Brother Tian이 편집한 JVM 런타임 데이터 영역에 대한 설명은 매우 훌륭합니다.
둘 사이의 본질적인 차이점은 스택은 스레드 전용이고 힙은 스레드가 공유한다는 것입니다.
스택은 로직을 나타내는 런타임 단위입니다. 스택은 힙에 기본 데이터 유형과 객체 참조를 포함하는 스레드에 해당합니다.
힙은 데이터를 나타내는 저장 단위입니다. 여러 스택이 공유될 수 있습니다(기본 데이터 유형, 멤버의 참조 및 참조 개체 포함). 영역은 연속적이지 않으며 조각이 있습니다.
1) 다양한 기능
스택 메모리는 로컬 변수 및 메소드 호출을 저장하는 데 사용되는 반면 힙 메모리는 Java에서 객체를 저장하는 데 사용됩니다. 멤버 변수, 지역 변수, 클래스 변수 등 이들이 가리키는 객체는 힙 메모리에 저장됩니다.
2) 다른 공유
스택 메모리는 스레드 전용입니다. 힙 메모리는 모든 스레드에 공통됩니다.
3) 예외 오류는 다릅니다
스택 메모리나 힙 메모리가 부족하면 예외가 발생합니다.
스택 공간 부족: java.lang.StackOverFlowError.
힙 공간 부족: java.lang.OutOfMemoryError.
4), 공간 크기
스택의 공간 크기는 힙의 공간 크기보다 훨씬 작습니다.
클래스 로딩 메커니즘에 대해 잘 알고 계시나요?
이것은 단지 연속 면접 질문입니다
JVM 클래스 로딩은 아래 그림과 같이 로딩, 검증, 준비, 파싱, 초기화, 사용, 제거의 5가지 프로세스로 나뉩니다.
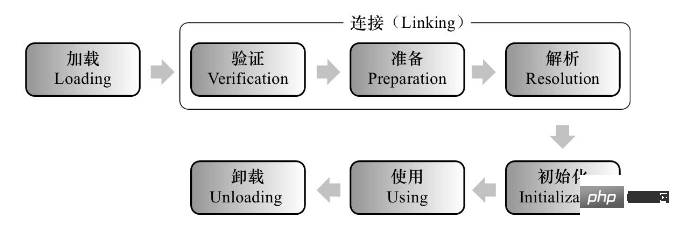
로드, 검증, 준비, 파싱, 초기화의 5가지 프로세스에 대한 구체적인 동작을 살펴보겠습니다.
Loading
Loading은 주로 .class 파일(반드시 .class일 필요는 없음. 네트워크에서 얻은 ZIP 패키지일 수 있음)의 이진 바이트 스트림을 JVM으로 읽는 것입니다. 로딩 단계 동안 JVM은 세 가지 작업을 완료해야 합니다. 1) 클래스의 정규화된 이름을 통해 클래스의 이진 바이트 스트림을 얻습니다. 2) 바이트 스트림으로 표시되는 정적 저장 구조를 런타임 데이터 구조로 변환합니다. 3) 메소드 영역에서 이 클래스의 다양한 데이터에 대한 액세스 항목으로 메모리에 이 클래스의 java.lang.Class 객체를 생성합니다.
Connection
Verification
확인은 주로 로드된 바이트 스트림이 JVM 사양을 준수하는지 확인하는 연결 단계의 첫 번째 단계입니다. 확인 단계에서는 확인 작업의 다음 4단계를 완료합니다. 1) 파일 형식 확인 2) 메타데이터 확인(Java 언어 사양을 준수하는지 여부) 3) 바이트코드 확인(프로그램 의미 체계가 합법적이고 논리적인지 확인) 4) 기호 참조 검증 (다음 단계의 분석이 정상적으로 실행될 수 있는지 확인)
준비
메소드 영역에서는 정적 변수에 대한 메모리를 주로 할당하고 기본 초기값을 설정한다.
Resolution
은 가상 머신이 상수 풀의 기호 참조를 직접 참조로 바꾸는 프로세스입니다.
초기화
초기화 단계는 클래스 로딩 프로세스의 마지막 단계로 주로 프로그램의 할당문에 따라 클래스 변수에 값을 적극적으로 할당합니다. 참고: 1) 상위 클래스가 있고 상위 클래스가 초기화되면 상위 클래스를 먼저 초기화합니다. 2) 그런 다음 하위 클래스 초기화 문을 수행합니다.
Full GC를 실행할 수 있는 조건은 무엇인가요?
가비지 수집 알고리즘 등에 대해 물어볼 줄 알았는데 여기까지 질문하게 되었습니다. 저는 아직 준비가 안되어 있어서 아무렇지도 않게 두 가지만 말씀드렸는데 면접관님이 많이 불만족스러워하시는 것 같더라고요. 뭐, 돌아가서 잘 준비하세요.
일반적으로 Full GC를 유발하는 5가지 시나리오가 있습니다.
(1) System.gc时,系统建议执行Full GC을 호출하지만 반드시 실행되는 것은 아닙니다.
(2) Old Generation의 공간이 부족합니다.
(3) 부족한 공간을 제거하는 방법
(4) Minor GC 통과 후 Old Generation의 평균 크기 > Old Generation의 사용 가능한 메모리
(5) Eden 영역에서 Space 영역에서 To Space 영역으로 복사할 때 To Space의 사용 가능한 메모리보다 객체 크기가 커지면 해당 객체는 Old Generation으로 전송되며 Old Generation의 사용 가능한 메모리는 물체 크기보다 작습니다. 즉, Old Generation이 New Generation의 객체를 Old Generation에 저장할 수 없을 때 Full GC가 시작됩니다.
온라인 시스템 CPU가 너무 높은데 어떻게 해야 하나요?
이 질문에 대한 답변은 그다지 만족스럽지 않습니다. Tian 형제가 문서를 편집했다는 것을 알고 있지만 아직 집에가는 길에 읽은 후에는 이것이 가능하다는 것을 알았습니다. 인터뷰를 위해 기억했습니다. 질문에 대답하지 않았습니다. 돌아가서 더 열심히하십시오. 면접관이 와서 말했습니다. 오늘 인터뷰는 여기서 마치겠습니다. 여기서 기다리세요.
잠시 후 미소를 지으며 아름다운 HR이 오셨는데, (문제가 심각하지 않은 줄 알았는데) 결과적으로...
당신은 "YY, 면접 상황에 대해 면접관님께서 피드백을 주셨는데요. 종합적으로 살펴보겠습니다. 먼저 돌아가세요. 나중에 전화해서 결과를 알려드리겠습니다."
(기사)...n일이 넘었는데 소식이 없더군요.
일반적인 작업은 다음과 같습니다.
1. top oder by with P: 1040 // 먼저 프로세스 로드별로 정렬하여 axLoad(pid)
2를 찾습니다. top -Hp 프로세스 PID: 1073 // 해당 로드를 찾습니다. thread PID
3. printf "0x%xn" Thread PID: 0x431 // 나중에 jstack 로그 검색을 준비하기 위해 스레드 PID를 16진수로 변환합니다
4. jstack 프로세스 PID | vim +/hex thread PID - // 예: jstack 1040|vim +/0x431 -
Summary
전체 면접 과정이 비교적 쉬웠고 면접관님도 친절하셨습니다. 꽤 괜찮네요. 2년차 일을 하는 사람으로서 한 번도 본 적이 없는 질문이 있는데, 면접관님이 준비한 질문이 있는 것 같습니다. , 반드시 직접 경험해야 할 필요는 없습니다.
위 내용은 지난주에 XX보험 인터뷰했는데 멋있었어요! ! !의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!