
집 >Java >Java인터뷰 질문들 >5개의 문자열 면접 질문, 10% 미만의 사람들이 모두 올바르게 답할 수 있습니다! (답변 포함)
5개의 문자열 면접 질문, 10% 미만의 사람들이 모두 올바르게 답할 수 있습니다! (답변 포함)
- Java后端技术全栈앞으로
- 2023-08-23 14:49:391624검색
Java StringJava String类的 5 道面试题,这五道题,我自己在面试过程中亲身经历过几道题目,本篇就带你了解这些题的答案为什么是这样。
st1和st2是否相等?
public class Demo2_String {
public static void main(String[] args) {
String st1 = "abc";
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
}输出结果:
第一行:true 第二行:true
分析
先看第一个打印语句,在Java中==这个符号是比较运算符,它可以基本数据类型和引用数据类型是否相等,如果是基本数据类型,==比较的是值是否相等,如果是引用数据类型,== 카테고리의 5가지 면접 질문. 저는 면접 과정에서 이 5가지 질문 중 몇 가지를 개인적으로 경험했습니다. 이 기사는 이러한 질문에 대한 답변이 왜 이런 것인지 이해하는 데 도움이 될 것입니다.
String st1 = new String(“abc”);🎜출력 결과: 🎜
첫 번째 줄: true 두 번째 줄: true
==이 기호는 기본 데이터 유형과 참조 데이터 유형이 동일한지 여부를 판별할 수 있는 비교 연산자입니다. 기본 데이터 유형인 경우 == 값이 같은지 비교합니다. 참조 데이터 유형인 경우 , ==는 메모리 주소가 두 개체는 동일합니다. 🎜🎜문자열은 8가지 기본 데이터 유형에 속하지 않습니다. 위에서 문자열 객체는 참조 데이터 유형에 속합니다. 위에서 "abc"는 두 문자열 객체 st1과 st2에 동시에 할당되어 동일한 주소를 가리킵니다. first print 문에서 == 비교의 출력 결과가 true입니다.
그런 다음 두 번째 print 문에서 같음 비교를 살펴보겠습니다. 우리는 같음이 상위 클래스 Object의 메서드이고 이 같음 메서드가 String 클래스에서 다시 작성되었음을 알 수 있습니다. 🎜🎜🎜在JDK API 1.6文档中找到String类下的equals方法,点击进去可以看到这么一句话“将此字符串与指定的对象比较。当且仅当该参数不为null,并且是与此对象表示相同字符序列的String 对象时,结果才为 true。” 注意这个相同字符序列,在后面介绍的比较两个数组,列表,字典是否相等,都是这个逻辑去写代码实现。
由于st1和st2的值都是“abc”,两者指向同一个对象,当前字符序列相同,所以第二行打印结果也为true。下面我们来画一个内存图来表示上面的代码,看起来更加有说服力。
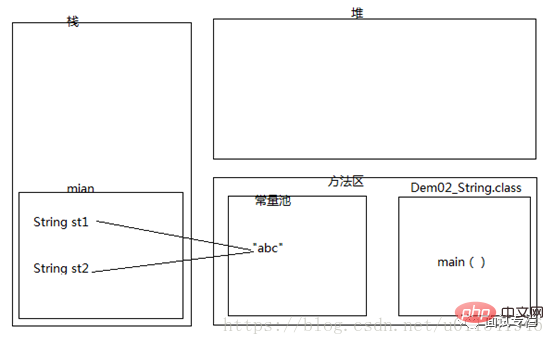
内存过程大致如下:
1)运行先编译,然后当前类Demo2_String.class文件加载进入内存的方法区
2)第二步,main方法压入栈内存
3)常量池创建一个“abc”对象,产生一个内存地址
4)然后把“abc”内存地址赋值给main方法里的成员变量st1,这个时候st1根据内存地址,指向了常量池中的“abc”。
5)前面一篇提到,常量池有这个特点,如果发现已经存在,就不在创建重复的对象
6)运行到代码 Stringst2 =”abc”, 由于常量池存在“abc”,所以不会再创建,直接把“abc”内存地址赋值给了st2
7)最后st1和st2都指向了内存中同一个地址,所以两者是完全相同的。
到底创建了几个对象?
String st1 = new String(“abc”);
答案是:在内存中创建两个对象,一个在堆内存,一个在常量池,堆内存对象是常量池对象的一个拷贝副本。
分析
我们下面直接来一个内存图。
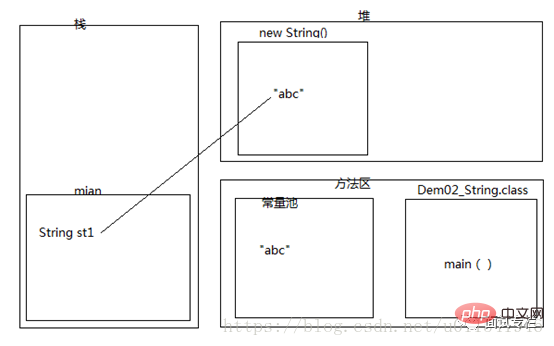
当我们看到了new这个关键字,就要想到,new出来的对象都是存储在堆内存。然后我们来解释堆中对象为什么是常量池的对象的拷贝副本。
“abc”属于字符串,字符串属于常量,所以应该在常量池中创建,所以第一个创建的对象就是在常量池里的“abc”。
第二个对象在堆内存为啥是一个拷贝的副本呢,这个就需要在JDK API 1.6找到String(String original)这个构造方法的注释:初始化一个新创建的 String 对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。所以,答案就出来了,两个对象。
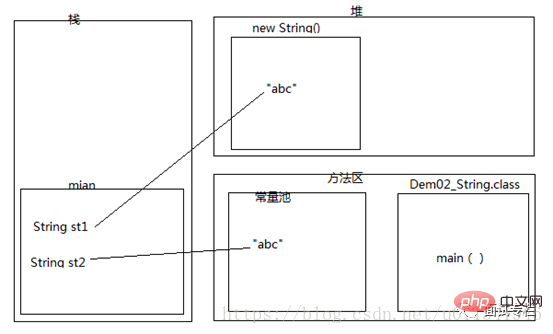
st1和st2是否相等?
package string;
public class Demo2_String {
public static void main(String[] args) {
String st1 = new String("abc");
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
}答案:false 和 true 由于有前面两道题目内存分析的经验和理论,所以,我能快速得出上面的答案。
==比较的st1和st2对象的内存地址,由于st1指向的是堆内存的地址,st2看到“abc”已经在常量池存在,就不会再新建,所以st2指向了常量池的内存地址,所以==判断结果输出false,两者不相等。
第二个equals比较,比较是两个字符串序列是否相等,由于就一个“abc”,所以完全相等。
内存图如下
st1和st2是否相等?
public class Demo2_String {
public static void main(String[] args) {
String st1 = "a" + "b" + "c";
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
}答案是:true 和 true 分析:“a”,”b”,”c”三个本来就是字符串常量,进行+符号拼接之后变成了“abc”,“abc”本身就是字符串常量(Java中有常量优化机制),所以常量池立马会创建一个“abc”的字符串常量对象,在进行st2=”abc”,这个时候,常量池存在“abc”,所以不再创建。所以,不管比较内存地址还是比较字符串序列,都相等。
判断一下st2和st3是否相等
public class Demo2_String {
public static void main(String[] args) {
String st1 = "ab";
String st2 = "abc";
String st3 = st1 + "c";
System.out.println(st2 == st3);
System.out.println(st2.equals(st3));
}
}答案:
false falsetrue
analytic
위의 첫 번째 대답은 false이고 두 번째는 true이고 두 번째는 true입니다. 비교 중 하나는 "abc"이고 다른 하나는 접합하여 얻은 "abc"이므로 동등 비교입니다. , 이것은 출력이 사실입니다. 우리는 그것을 매우 잘 이해합니다. 그래서 첫 번째 판단이 왜 거짓인지, 우리는 혼란스럽습니다. 마찬가지로 아래에서는 API 주석과 메모리 다이어그램을 사용하여 이것이 동일하지 않은 이유를 설명합니다.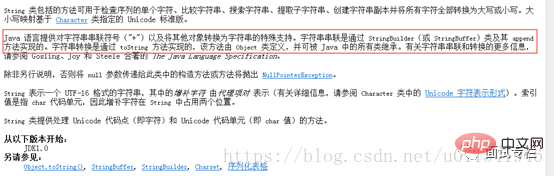 먼저 JDK API 1.6의 String 소개를 열고 아래 그림에서 문장을 찾아보세요.
먼저 JDK API 1.6의 String 소개를 열고 아래 그림에서 문장을 찾아보세요.
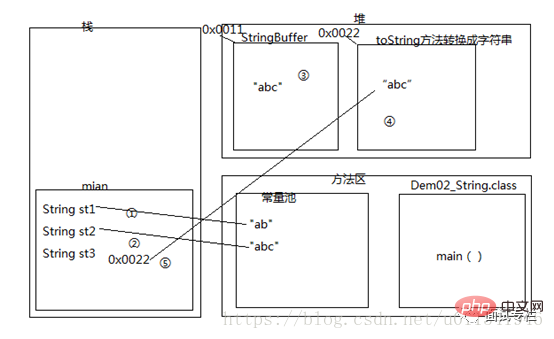 위 댓글은 이 스플라이싱의 원리를 설명하면 내부의 StringBuilder 또는 StringBuffer 클래스와 Append 메서드가 스플라이싱을 구현한 후 toString()을 호출하여 스플라이싱된 객체를 문자열 객체로 변환하고 마지막으로 주소를 할당한다는 것입니다. 문자열 객체를 변수로 변환합니다. 이러한 이해를 바탕으로 분석을 위한 메모리 다이어그램을 그려보자.
위 댓글은 이 스플라이싱의 원리를 설명하면 내부의 StringBuilder 또는 StringBuffer 클래스와 Append 메서드가 스플라이싱을 구현한 후 toString()을 호출하여 스플라이싱된 객체를 문자열 객체로 변환하고 마지막으로 주소를 할당한다는 것입니다. 문자열 객체를 변수로 변환합니다. 이러한 이해를 바탕으로 분석을 위한 메모리 다이어그램을 그려보자.
Summary
올바른 결과를 얻으려면 JDK API의 일부 주석과 원리, 메모리 그래프 분석을 숙지해야 합니다. 메모리 그래프를 그리는 것이 이해하는 데 도움이 되었다고 인정합니다. 대답..왜 그러는거야?
위 내용은 5개의 문자열 면접 질문, 10% 미만의 사람들이 모두 올바르게 답할 수 있습니다! (답변 포함)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!