
Spring Boot는 MySQL 읽기-쓰기 분리 기술을 구현합니다.
- Java后端技术全栈앞으로
- 2023-08-15 16:52:561493검색
읽기 및 쓰기 분리를 구현하는 방법은 Spring Boot 프로젝트이며 데이터베이스는 MySQL이고 지속성 레이어는 MyBatis를 사용합니다.
실제로 이를 구현하는 것은 매우 간단합니다. 먼저 질문에 대해 생각해 보세요.
고동시성 시나리오에서는 데이터베이스에 어떤 최적화 방법이 있습니까?
읽기-쓰기 분리, 캐싱, 마스터-슬레이브 아키텍처 클러스터, 하위 데이터베이스 및 하위 테이블 등의 구현 방법이 일반적으로 사용됩니다.
인터넷 애플리케이션에서는 대부분 독서를 많이 하고, 글쓰기를 적게 하고 있습니다. 메인 도서관과 독서 도서관, 두 개의 도서관이 마련되어 있습니다.
메인 라이브러리는 쓰기를 담당하고, 슬레이브 라이브러리는 읽기를 주로 담당합니다. 데이터 소스에서 읽기 및 쓰기 기능을 분리하여 읽기 및 쓰기 충돌을 줄이는 것이 목적입니다. , 데이터베이스 부하 완화 및 데이터베이스 보호를 달성할 수 있습니다. 실제 사용 시 쓰기와 관련된 모든 부분은 메인 라이브러리로 직접 전환되고, 읽기 부분은 읽기 라이브러리로 직접 전환되는 것이 전형적인 읽기-쓰기 분리 기술이다.
이 글에서는 읽기와 쓰기의 분리에 초점을 맞추고 이를 구현하는 방법을 살펴보겠습니다.
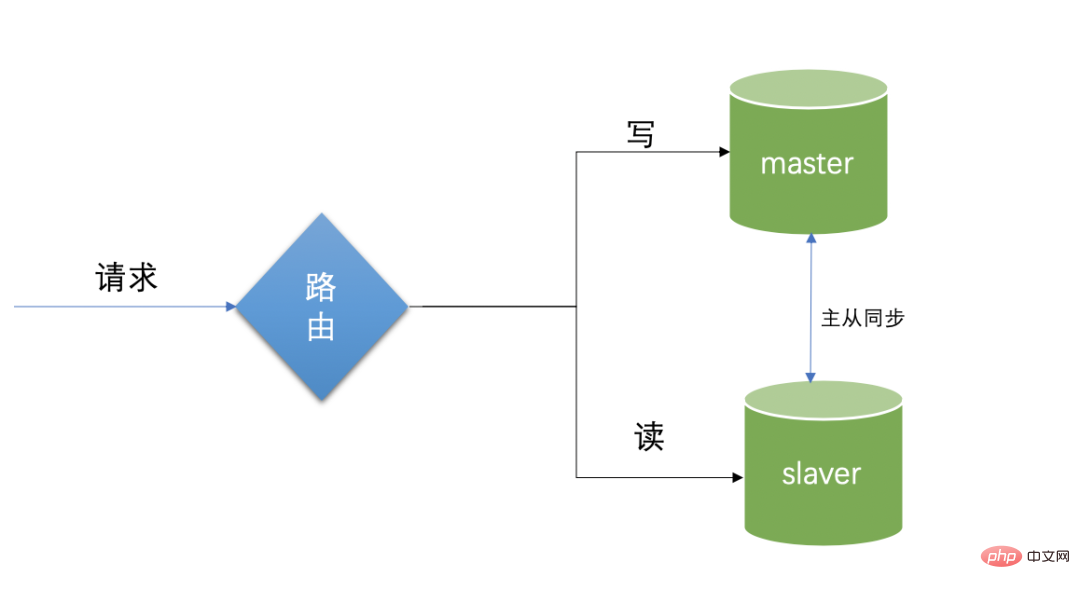
마스터-슬레이브 동기화의 한계: 마스터 데이터베이스와 슬레이브 데이터베이스로 나누어지며, 마스터 데이터베이스는 데이터 쓰기를 담당합니다. 데이터는 슬레이브 데이터베이스에 자동으로 동기화됩니다. 슬레이브 데이터베이스는 읽기 요청이 오면 읽기 데이터베이스에서 직접 데이터를 읽고, 마스터 데이터베이스는 자동으로 데이터를 슬레이브 데이터베이스에 복사합니다. 하지만 이 블로그에서는 운영 및 유지보수 작업에 더 중점을 두기 때문에 이 부분의 구성 지식을 소개하지 않습니다.
여기에 문제가 있습니다.
마스터-슬레이브 복제의 지연 문제. 메인 데이터베이스에 쓸 때 갑자기 읽기 요청이 오고 이때 데이터가 완전히 동기화되지 않아 읽기 요청이 나타납니다. 데이터를 읽을 수 없거나 읽은 데이터가 원래 값보다 작습니다. 가장 간단한 특정 솔루션은 읽기 요청을 일시적으로 메인 라이브러리로 지정하는 것이지만 동시에 마스터-슬레이브 분리 의미의 일부도 상실합니다. 즉, 데이터 일관성 시나리오의 엄격한 의미에서 읽기-쓰기 분리는 읽기-쓰기 분리 사용의 단점으로 인해 업데이트의 적시성에 주의해야 합니다.
좋습니다. 이 부분은 단지 이해를 돕기 위한 것입니다. 다음으로 Java 코드를 통해 읽기 및 쓰기 분리를 달성하는 방법을 살펴보겠습니다.
참고: 이 프로젝트에는 Spring Boot, spring-aop, spring-jdbc, aspectjweaver 등의 종속성을 도입해야 합니다.
프로그래머: 30일 밖에 안 남았는데 어떻게 준비해야 하나요?
1: 마스터-슬레이브 데이터 소스 구성
마스터-슬레이브 데이터베이스 구성은 일반적으로 구성 파일에 기록됩니다. @ConfigurationProperties 주석을 통해 구성 파일(일반적으로 이름: application.Properties)는 특정 클래스 속성에 매핑되어 작성된 값을 읽고 특정 코드 구성에 주입합니다. 습관이 관례보다 크다는 원칙에 따라 우리 모두는 메인 라이브러리에 다음과 같이 주석을 답니다. master, 슬레이브 라이브러리는 슬레이브로 표시됩니다. application.Properties)里的属性映射到具体的类属性上,从而读取到写入的值注入到具体的代码配置中,按照习惯大于约定的原则,主库我们都是注为 master,从库注为 slave。
本项目采用了阿里的 druid 数据库连接池,使用 build 建造者模式创建 DataSource 对象,DataSource 就是代码层面抽象出来的数据源,接着需要配置 sessionFactory、sqlTemplate、事务管理器等。
/**
* 主从配置
*/
@Configuration
@MapperScan(basePackages = "com.wyq.mysqlreadwriteseparate.mapper", sqlSessionTemplateRef = "sqlTemplate")
public class DataSourceConfig {
/**
* 主库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource master() {
return DruidDataSourceBuilder.create().build();
}
/**
* 从库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaver() {
return DruidDataSourceBuilder.create().build();
}
/**
* 实例化数据源路由
*/
@Bean
public DataSourceRouter dynamicDB(@Qualifier("master") DataSource masterDataSource,
@Autowired(required = false) @Qualifier("slaver") DataSource slaveDataSource) {
DataSourceRouter dynamicDataSource = new DataSourceRouter();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceEnum.MASTER.getDataSourceName(), masterDataSource);
if (slaveDataSource != null) {
targetDataSources.put(DataSourceEnum.SLAVE.getDataSourceName(), slaveDataSource);
}
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource);
return dynamicDataSource;
}
/**
* 配置sessionFactory
* @param dynamicDataSource
* @return
* @throws Exception
*/
@Bean
public SqlSessionFactory sessionFactory(@Qualifier("dynamicDB") DataSource dynamicDataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setMapperLocations(
new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*Mapper.xml"));
bean.setDataSource(dynamicDataSource);
return bean.getObject();
}
/**
* 创建sqlTemplate
* @param sqlSessionFactory
* @return
*/
@Bean
public SqlSessionTemplate sqlTemplate(@Qualifier("sessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
/**
* 事务配置
*
* @param dynamicDataSource
* @return
*/
@Bean(name = "dataSourceTx")
public DataSourceTransactionManager dataSourceTransactionManager(@Qualifier("dynamicDB") DataSource dynamicDataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dynamicDataSource);
return dataSourceTransactionManager;
}
}二: 数据源路由的配置
路由在主从分离是非常重要的,基本是读写切换的核心。Spring 提供了 AbstractRoutingDataSource 根据用户定义的规则选择当前的数据源,作用就是在执行查询之前,设置使用的数据源,实现动态路由的数据源,在每次数据库查询操作前执行它的抽象方法 determineCurrentLookupKey()
public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}🎜🎜🎜둘: 데이터 소스 라우팅 구성🎜🎜 🎜🎜🎜라우팅은 마스터-슬레이브 분리에서 매우 중요하며 기본적으로 읽기-쓰기 전환의 핵심입니다. Spring은 AbstractRoutingDataSource 사용자 정의 규칙에 따라 현재 데이터 소스를 선택하는 기능은 쿼리를 실행하기 전에 사용되는 데이터 소스를 설정하고, 동적 라우팅의 데이터 소스를 구현하고, 각 데이터베이스 쿼리 작업 전에 해당 추상 메서드를 실행하는 것입니다.determineCurrentLookupKey() 사용할 데이터 소스를 결정합니다. 🎜🎜전역 데이터 소스 관리자를 갖기 위해서는 전역 변수로 이해되고 언제든지 액세스할 수 있는 데이터베이스 컨텍스트 관리자인 DataSourceContextHolder를 도입해야 합니다(아래 자세한 소개 참조). 현재 데이터를 저장합니다. 🎜public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}三:数据源上下文环境
数据源上下文保存器,便于程序中可以随时取到当前的数据源,它主要利用 ThreadLocal 封装,因为 ThreadLocal 是线程隔离的,天然具有线程安全的优势。这里暴露了 set 和 get、clear 方法,set 方法用于赋值当前的数据源名,get 方法用于获取当前的数据源名称,clear 方法用于清除 ThreadLocal 中的内容,因为 ThreadLocal 的 key 是 weakReference 是有内存泄漏风险的,通过 remove 方法防止内存泄漏。
/**
* 利用ThreadLocal封装的保存数据源上线的上下文context
*/
public class DataSourceContextHolder {
private static final ThreadLocal<String> context = new ThreadLocal<>();
/**
* 赋值
*
* @param datasourceType
*/
public static void set(String datasourceType) {
context.set(datasourceType);
}
/**
* 获取值
* @return
*/
public static String get() {
return context.get();
}
public static void clear() {
context.remove();
}
}四:切换注解和 Aop 配置
首先我们来定义一个@DataSourceSwitcher 注解,拥有两个属性
① 当前的数据源② 是否清除当前的数据源,并且只能放在方法上,(不可以放在类上,也没必要放在类上,因为我们在进行数据源切换的时候肯定是方法操作),该注解的主要作用就是进行数据源的切换,在 dao 层进行操作数据库的时候,可以在方法上注明表示的是当前使用哪个数据源。
@DataSourceSwitcher 注解的定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface DataSourceSwitcher {
/**
* 默认数据源
* @return
*/
DataSourceEnum value() default DataSourceEnum.MASTER;
/**
* 清除
* @return
*/
boolean clear() default true;
}DataSourceAop配置:
为了赋予@DataSourceSwitcher 注解能够切换数据源的能力,我们需要使用 AOP,然后使用@Aroud 注解找到方法上有@DataSourceSwitcher.class 的方法,然后取注解上配置的数据源的值,设置到 DataSourceContextHolder 中,就实现了将当前方法上配置的数据源注入到全局作用域当中。
@Slf4j
@Aspect
@Order(value = 1)
@Component
public class DataSourceContextAop {
@Around("@annotation(com.wyq.mysqlreadwriteseparate.annotation.DataSourceSwitcher)")
public Object setDynamicDataSource(ProceedingJoinPoint pjp) throws Throwable {
boolean clear = false;
try {
Method method = this.getMethod(pjp);
DataSourceSwitcher dataSourceSwitcher = method.getAnnotation(DataSourceSwitcher.class);
clear = dataSourceSwitcher.clear();
DataSourceContextHolder.set(dataSourceSwitcher.value().getDataSourceName());
log.info("数据源切换至:{}", dataSourceSwitcher.value().getDataSourceName());
return pjp.proceed();
} finally {
if (clear) {
DataSourceContextHolder.clear();
}
}
}
private Method getMethod(JoinPoint pjp) {
MethodSignature signature = (MethodSignature) pjp.getSignature();
return signature.getMethod();
}
}五:用法以及测试
在配置好了读写分离之后,就可以在代码中使用了,一般而言我们使用在 service 层或者 dao 层,在需要查询的方法上添加@DataSourceSwitcher(DataSourceEnum.SLAVE),它表示该方法下所有的操作都走的是读库。在需要 update 或者 insert 的时候使用@DataSourceSwitcher(DataSourceEnum.MASTER)表示接下来将会走写库。
其实还有一种更为自动的写法,可以根据方法的前缀来配置 AOP 自动切换数据源,比如 update、insert、fresh 等前缀的方法名一律自动设置为写库。select、get、query 等前缀的方法名一律配置为读库,这是一种更为自动的配置写法。缺点就是方法名需要按照 aop 配置的严格来定义,否则就会失效。
@Service
public class OrderService {
@Resource
private OrderMapper orderMapper;
/**
* 读操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.SLAVE)
public List<Order> getOrder(String orderId) {
return orderMapper.listOrders(orderId);
}
/**
* 写操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.MASTER)
public List<Order> insertOrder(Long orderId) {
Order order = new Order();
order.setOrderId(orderId);
return orderMapper.saveOrder(order);
}
}六:总结
还是画张图来简单总结一下:
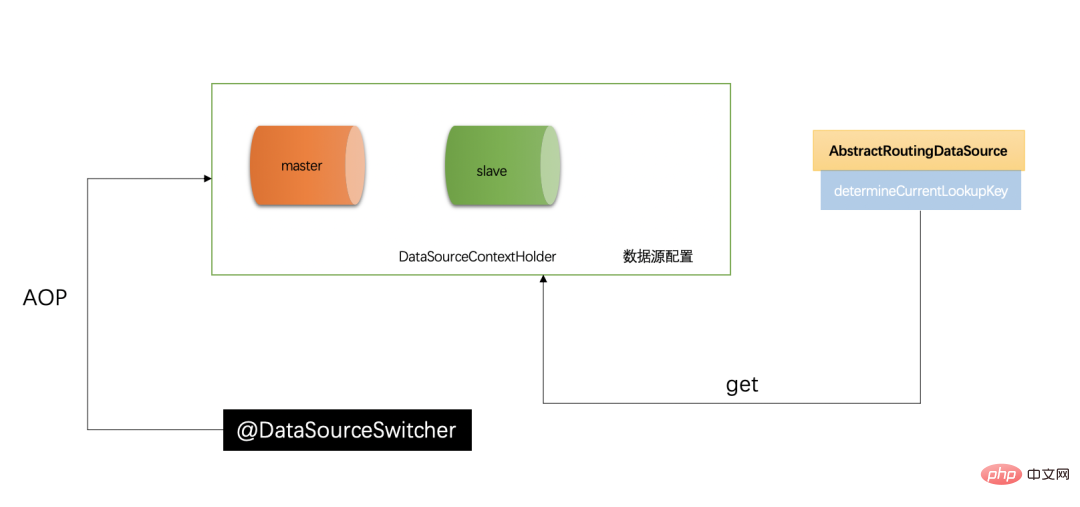
이 기사에서는 데이터베이스 읽기-쓰기 분리를 구현하는 방법을 소개합니다. 읽기-쓰기 분리의 핵심은 상속되어야 하는 데이터 라우팅이라는 점에 유의하세요. AbstractRoutingDataSource,复写它的 determineCurrentLookupKey ()方法。同时需要注意全局的上下文管理器 DataSourceContextHolder는 데이터 소스 컨텍스트를 저장하는 메인 클래스이기도 합니다. 라우팅 방법에서 찾은 데이터 소스 값입니다. 이는 데이터 소스의 전송 스테이션과 동일하며 jdbc-Template의 하위 계층과 결합되어 데이터 소스, 트랜잭션 등을 생성 및 관리하므로 데이터베이스 읽기 및 쓰기 분리가 완벽하게 실현됩니다.
위 내용은 Spring Boot는 MySQL 읽기-쓰기 분리 기술을 구현합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!