
집 >Java >Java인터뷰 질문들 >면접관: Redis 데이터 편향, 핫스팟 및 기타 문제를 해결하는 방법
면접관: Redis 데이터 편향, 핫스팟 및 기타 문제를 해결하는 방법
- Java后端技术全栈앞으로
- 2023-08-15 16:43:081731검색
Redis는 주류 기술로서 많은 응용 시나리오를 가지고 있습니다. 대, 중, 소규모 공장과의 많은 인터뷰에서 핵심 검사 내용으로 나열되었습니다.
몇일 전 Planet 친구가 공부하던 중 우연히 만났습니다. 다음과 같은 질문에 톰님 상담하러 왔어요
이러한 문제는 상대적으로 빈번하고 직장에서 자주 접하는 문제인 점을 고려하여 체계적으로 설명하기 위해 글을 작성하겠습니다
문제 설명:
문의드립니다. : Redis를 검토할 때 몇 가지 질문이 있습니다. 다음을 살펴보십시오.
Redis 클러스터에 데이터 왜곡과 고르지 않은 데이터 분포가 있는 경우 이를 해결하는 방법은 무엇입니까?
hotKey를 처리할 때 k-1, k-2..., 이러한 복사본을 균등하게 쓰려면 어떻게 해야 합니까? 균등하게 접근하는 방법은 무엇입니까?
redis는 해시 슬롯을 사용하여 클러스터를 유지합니다. 일관된 해싱과 유사하게 전체 마이그레이션을 피할 수 있습니다. 일관된 해싱을 사용하지 않는 이유는 무엇입니까?
답변:
성능 가속기로서 분산 캐시는 시스템 최적화에 매우 중요한 역할을 합니다. 로컬 캐시에 비해 네트워크 전송을 추가하고 1ms 미만의 시간이 소요되지만 중앙 집중식으로 관리할 수 있다는 장점이 있으며 매우 큰 저장 용량을 지원합니다.
분산 캐시 분야에서 Redis는 현재 널리 사용되고 있습니다. 이 프레임워크는 순수 메모리 저장소, 단일 스레드 명령 실행, 풍부한 기본 데이터 구조, 다차원의 데이터 저장 및 검색 지원입니다.
물론, 데이터 양이 많으면 데이터 왜곡, 데이터 핫스팟 등 다양한 문제가 발생합니다.
데이터 왜곡이란 무엇인가요?
단일 머신의 하드웨어 구성에는 상한이 있습니다. 일반적으로 분산 아키텍처를 사용하여 여러 머신의 클러스터를 구성합니다. 아래 그림의 클러스터는 세 개의 Redis 독립형 머신으로 구성됩니다. 클라이언트는 특정 라우팅 전략을 통해 특정 인스턴스에 읽기 및 쓰기 요청을 전달합니다.
비즈니스 데이터의 특수성으로 인해 지정된 샤딩 규칙에 따라 여러 인스턴스의 데이터가 고르지 않게 분산되어 계산을 위해 하나 또는 여러 머신 노드에 집중되어 부하가 발생할 수 있습니다. 다른 노드는 유휴 상태로 대기하므로 전체 효율성이 저하됩니다.
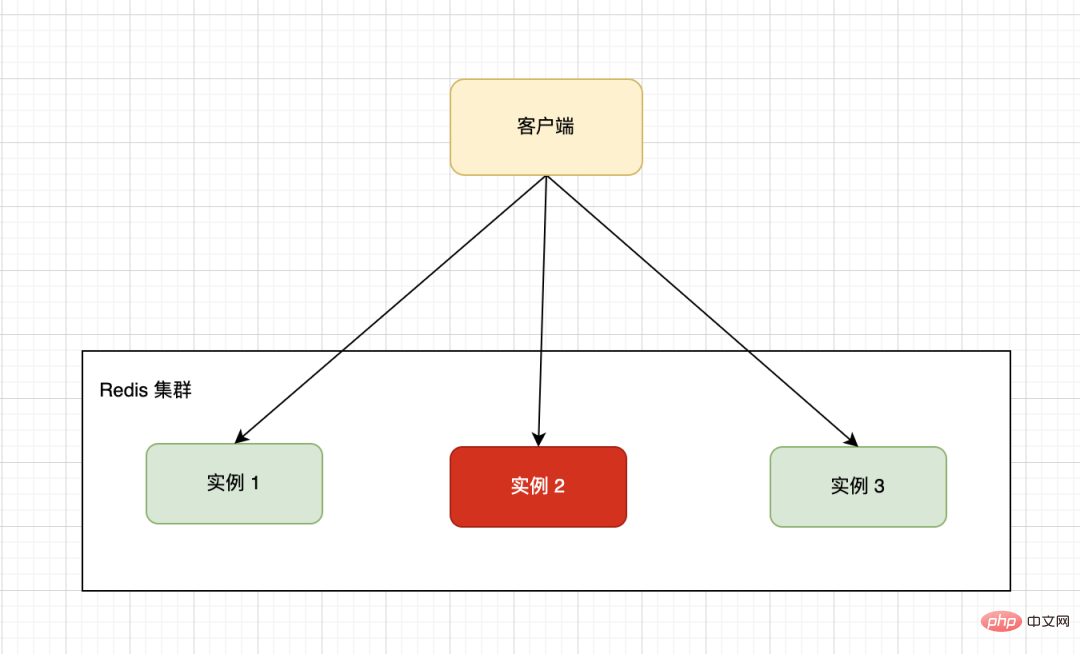
데이터 왜곡의 이유는 무엇인가요?
1. 큰 키가 있습니다
예를 들어 문자열 형식의 bigKey 데이터를 하나 이상 저장하면 많은 메모리를 차지합니다.
Tom 형제는 개발 중에 발생하는 문제를 해결하기 위해 JSON 형식을 사용하여 여러 비즈니스 데이터를 하나의 값으로 병합한 결과 이 키-값의 용량이 제한되었습니다. 쌍은 수백 M에 도달했습니다.
큰 키를 자주 읽고 쓰면 메모리 리소스가 많이 소모되고 네트워크 전송에 큰 부담이 가해지며 결과적으로 요청 응답 속도가 느려지고 눈사태 효과가 발생하며 결국 다양한 시스템 시간 초과 경보가 발생합니다.
해결책:
방법은 매우 간단합니다. <code style='font-family: SFMono-Regular, Consolas, "Liberation Mono", Menlo, Courier, monospace;background-color: rgba(0, 0, 0, 0.06);border-width: 1px;border-style: solid;border-color: rgba(0, 0, 0, 0.08);border-radius: 2px;padding-right: 2px;padding-left: 2px;'><span style="font-size: 16px;">化整为零</span>的策略,将一个bigKey拆分为多个小key,独立维护,成本会降低很多。当然这个拆也讲究些原则,既要考虑业务场景也要考虑访问场景,将关联紧密的放到一起。
比如:有个RPC接口内部对 Redis 有依赖,之前访问一次就可以拿到全部数据,拆分将要控制单值的大小,也要控制访问的次数,毕竟调用次数增多了,会拉大整体的接口响应时间。
浙江的政府机构都在提倡优化流程,最多跑一次,都是一个道理。

2、HashTag 使用不当
Redis 采用单线程执行命令,从而保证了原子性。当采用集群部署后,为了解决mset、lua 脚本等对多key 批量操作,为了保证不同的 key 能路由到同一个 Redis 实例上,引入了 HashTag 机制。
用法也很简单,使用<span style="font-size: 16px;">{}</span>부분으로 나누기 전략은 bigKey를 여러 개의 작은 키로 분할하여 독립적으로 유지 관리하는 것인데, 그러면 비용이 많이 절감됩니다. 물론 이 분해에서는 비즈니스 시나리오와 액세스 시나리오를 모두 고려하고 밀접하게 결합하는 몇 가지 원칙에도 주의를 기울일 필요가 있습니다.
예를 들어 Redis에 내부적으로 의존하는 RPC 인터페이스가 있습니다. 이전에는 한 번 액세스하면 모든 데이터를 얻을 수 있었습니다. 분할하면 결국 단일 값의 크기와 액세스 횟수가 제어됩니다. , 호출 수가 증가하면 전체 인터페이스 응답 시간이 길어지는 문제가 발생합니다.
2. HashTag
🎜🎜🎜🎜Redis는 단일 스레드를 사용하여 명령을 실행하므로 다음을 보장합니다. 원자성 . 클러스터 배포가 채택되면 mset 및 lua 스크립트와 같은 다중 키 배치 작업을 해결하고 다른 키가 동일한 Redis 인스턴스로 라우팅될 수 있도록 해시태그 🎜 메커니즘이 도입되었습니다. 🎜🎜🎜🎜 사용법도 매우 간단합니다. 🎜 🎜 {}🎜🎜중괄호, 중괄호 안의 문자열 해시만 계산하도록 키를 지정하여 서로 다른 키의 키-값 쌍을 동일한 해시 슬롯에 삽입합니다. 🎜🎜🎜🎜🎜예: 🎜🎜🎜🎜192.168.0.1:6380> CLUSTER KEYSLOT testtag
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT {testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey1{testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey2{testtag}
(integer) 764🎜🎜🎜비즈니스 코드를 확인하여 HashTag가 도입되었는지 그리고 너무 많은 키가 하나의 인스턴스로 라우팅되는지 확인하세요. 특정 시나리오에 따라 분할하는 방법을 고려하세요. 🎜🎜🎜🎜RocketMQ와 마찬가지로 많은 경우 파티션이 순서대로 유지되는 한 비즈니스 요구 사항을 충족할 수 있습니다. 실제 실무에서는 문제를 해결하기 위해 문제를 해결하기보다는 이 균형점을 찾아야 합니다. 🎜🎜3. 슬롯의 불균일한 분포
Redis 클러스터 배포 방식을 채택하면 클러스터의 데이터베이스는 16384개의 슬롯(슬롯)으로 나뉘며 데이터베이스의 각 키는 이 16384개의 슬롯에 속합니다. , 클러스터의 각 노드는 0개 또는 최대 16,384개의 슬롯을 처리할 수 있습니다.
저장 및 액세스의 균일성을 보장하기 위해 상대적으로 큰 슬롯을 약간 유휴 상태인 머신으로 수동으로 마이그레이션할 수 있습니다.
캐시 핫스팟이란 무엇인가요?
캐시 핫스팟은 대부분 또는 심지어 모든 비즈니스 요청이 동일한 캐시 데이터에 도달하여 캐시 서버에 큰 부담을 주고 심지어 단일 시스템의 로드 제한을 초과하여 서버가 다운되는 것을 의미합니다.
해결책:
1. 여러 복사본을 만드세요
키 뒤에 일련 번호를 입력할 수 있습니다(예: key#01, key#02 ). . . 키#10의 여러 복사본, 이러한 처리된 키는 여러 캐시 노드에 있습니다.
클라이언트가 접속할 때마다 원본 키를 기준으로 샤드 수의 상한과 난수를 이어붙여 라우팅할 수 없는 인스턴스 노드로 요청을 라우팅하면 됩니다.
참고: 캐시는 일반적으로 중앙 집중식 캐시 오류를 방지하기 위해 캐시 만료 시간을 동일하게 설정하지 않으려고 사전 설정에 따라 임의의 숫자를 추가할 수 있습니다.
데이터 라우팅의 균일성은 해시 알고리즘으로 보장됩니다.
2. 로컬 메모리 캐시
핫스팟 데이터를 클라이언트의 로컬 메모리에 캐시하고 만료 시간을 설정합니다. 각 읽기 요청에 대해 먼저 데이터가 로컬 캐시에 있는지 확인하고, 존재하지 않으면 직접 반환합니다. 그런 다음 분산 캐시 서버에 액세스합니다.
로컬 메모리 캐시는 캐시 서버를 완전히 "해방"시키며 캐시 서버에 어떠한 압력도 가하지 않습니다.
단점: 최신 캐시 데이터를 실시간으로 감지하는 것이 다소 번거롭고, 데이터 불일치가 발생할 수 있습니다. 만료 시간을 비교적 짧게 설정하고 수동 업데이트를 사용할 수 있습니다. 물론, 데이터가 변경되었음을 감지하면 모니터링 메커니즘을 사용하여 적시에 로컬 캐시를 업데이트할 수도 있습니다.
key
通过<strong>CRC16<span style="color: rgb(17, 124, 238);font-size: 18px;"></span></strong>
校验后对16384<p style="min-height: 24px;margin-bottom: 24px;"></p>取模来决定放置哪个槽。集群的每个节点负责一parthash槽,举个例子,比如当前集群有3个节点,那么 <code style='font-family: SFMono-Regular, Consolas, "Liberation Mono", Menlo, Courier, monospace;background-color: rgba(0, 0, 0, 0.06);border-width: 1px;border-style: solid;border-color: rgba(0, 0, 0, 0.08);border-radius: 2px;padding-right: 2px;padding-left: 2px;'><span style="font-size: 16px;">key</span>通过<span style="font-size: 16px;">CRC16</span>校验后对<span style="font-size: 16px;">16384</span>取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么 <span style="font-size: 16px;">node-1</span> 包含 0 到 5460 号哈希槽,<span style="font-size: 16px;">node-2</span> 包含 5461 到 10922 号哈希槽,<span style="font-size: 16px;">node-3</span>node- 1 包含 0 到 5460 号哈希槽,<p style="min-height: 24px;margin-bottom: 24px;">node-2<br></p>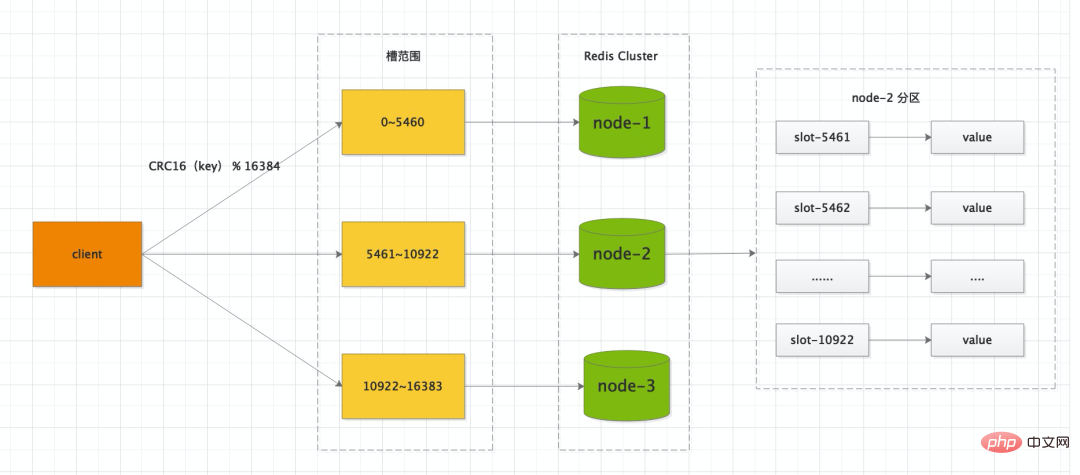 包含 5461 到 10922 号哈希槽,
包含 5461 到 10922 号哈希槽,<p style="min-height: 24px;margin-bottom: 24px;">node-3<br></p>包含 10922 到 16383 号哈希槽。
一致性哈希算法是 1997년年麻省緥文院的 Karger 等人提出了,为的就是解决分布式缓存的问题。
一致性哈希算法本质上也是一种取模算法,不同于按服务器数weight取模,一致性哈希是对固定值 2^32 取模。
公式 = hash(key) % 2^32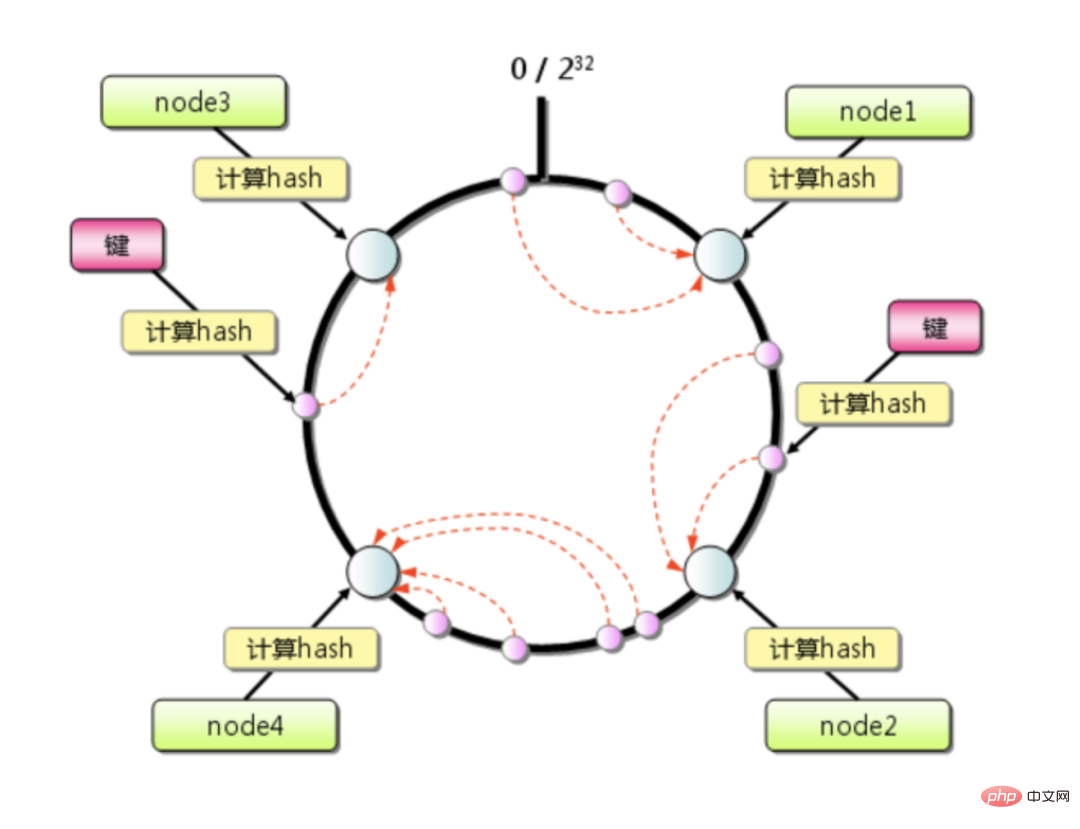
일관된 해시 알고리즘은 확장 또는 축소로 인한 캐시 오류 문제를 크게 완화하며 이 노드가 담당하는 키의 작은 세그먼트에만 영향을 미칩니다. 클러스터에 머신이 많지 않고 단일 머신의 부하 수준이 일반적으로 매우 높은 경우 특정 노드의 가동 중지 시간으로 인한 압력으로 인해 눈사태 효과가 쉽게 발생할 수 있습니다.
예:
Redis 클러스터에는 총 4개의 머신이 있습니다. 데이터가 균등하게 분산되어 있다고 가정하면 각 머신이 갑자기 트래픽의 4분의 1을 부담하게 됩니다. 정지되면 시계 방향의 다음 머신은 추가 트래픽의 1/4을 감당하고 결국에는 트래픽의 절반을 감당하게 되는데 이는 여전히 약간 무섭습니다.
그러나 <span style="font-size: 16px;">CRC16</span>CRC16 계산 후 슬롯과 인스턴스 간의 결합 관계를 결합하여 확장이든 축소이든 해당 노드의 키만 원활하게 마이그레이션하면 되며 새로운 슬롯 매핑 관계는 별도의 작업 없이 브로드캐스팅되어 저장됩니다. 캐시 무효화 생성, 높은 유연성.
또한 서버 노드 구성에 차이가 있는 경우 서로 다른 노드에 할당된 슬롯 번호를 사용자 정의하고 서로 다른 노드의 로드 기능을 조정할 수 있어 매우 편리합니다.
위 내용은 면접관: Redis 데이터 편향, 핫스팟 및 기타 문제를 해결하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!