
팁 | 이것은 아마도 내가 본 최고의 NumPy 그래픽 튜토리얼일 것입니다!

- Python当打之年앞으로
- 2023-08-10 16:08:121317검색

이 글에서는 NumPy의 주요 용도와 NumPy가 처리하는 다양한 유형의 데이터(테이블, 이미지, 텍스트 등)를 표시하는 방법을 소개합니다. 기계 학습 모델의 입력이 됩니다.
배열에 대한 산술 연산
데이터와 1이라고 하는 두 개의 NumPy 배열을 만들어 보겠습니다.

두 배열을 계산하려면 추가하려면 간단히 데이터를 입력하세요. + 해당 위치에 데이터를 추가하는 것(즉, 데이터의 각 행을 추가하는 것) 이 작업은 배열을 읽기 위해 반복하는 메소드 코드보다 더 간결합니다.
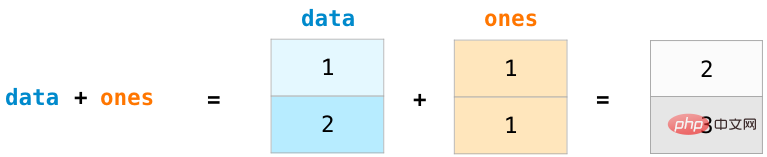
물론, 이를 바탕으로 뺄셈, 곱셈, 나눗셈 등의 연산도 구현할 수 있습니다.

많은 경우 배열과 단일 값에 대한 연산(벡터와 스칼라 간의 연산이라고도 함)을 수행하려고 합니다. 예: 배열이 거리를 마일 단위로 나타내는 경우 목표는 이를 킬로미터로 변환하는 것입니다. 간단히 데이터 * 1.6으로 작성할 수 있습니다.

NumPy는 이 작업에 배열의 각 요소를 곱해야 한다는 것을 배열 브로드캐스팅을 통해 알고 있습니다.
배열 슬라이싱 작업
아래와 같이 Python 목록 작업과 같이 NumPy 배열을 인덱싱하고 슬라이스할 수 있습니다. y 편리하게도 데이터를 압축하고 배열의 일부 특성 값을 계산할 수 있는 집계 함수:

min, max 및 sum과 같은 함수 외에도 평균( 평균), prod(데이터 곱셈)는 모든 요소의 곱, std(표준편차) 등을 계산합니다. 위의 모든 예는 1차원의 벡터를 다룹니다. 그 외에도 NumPy의 아름다움의 핵심 부분은 지금까지 본 모든 기능을 모든 차원에 적용할 수 있는 능력입니다.
NumPy의 행렬 연산2개를 전달하여 행렬을 만들 수 있습니다. 차원 목록을 Numpy로 변환합니다.

또한 위에서 언급한 ones(), zeros() 및 random.random()을 사용하여 행렬을 만들 수도 있습니다. 행렬의 크기를 설명하는 튜플을 전달하면 됩니다.

행렬에 대한 산술 연산
같은 크기의 두 행렬에 대해 산술 연산자(+-*/)를 사용하여 더하거나 곱할 수 있습니다. NumPy는 이러한 작업에 위치별 작업을 사용합니다.
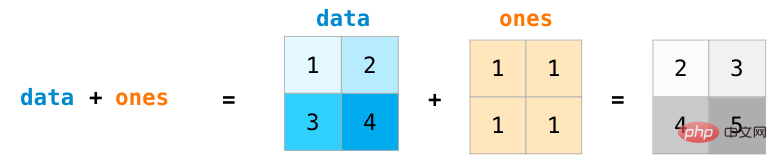
크기가 다른 행렬의 경우 두 행렬의 차원이 1일 때만 이러한 산술 연산을 수행할 수 있습니다(예를 들어 행렬에 열 또는 행이 하나만 있는 경우). 이 경우 NumPy는 브로드캐스트 규칙을 사용합니다. (방송) 연산 처리용. NumPy는 행렬 사이의 내적 연산을 수행하는 데 사용할 수 있는 dot() 메서드를 제공합니다.

행렬 차원은 위 그림의 하단에 추가되어 두 가지를 강조합니다. 연산의 행렬은 열에 있고 행은 동일해야 합니다. 이 작업은 다음과 같이 도표화할 수 있습니다.

행렬의 슬라이싱 및 집계
인덱싱 및 슬라이싱 기능은 행렬을 조작할 때 더욱 유용해집니다. 다양한 차원의 인덱스 연산을 사용하여 데이터를 슬라이싱할 수 있습니다.
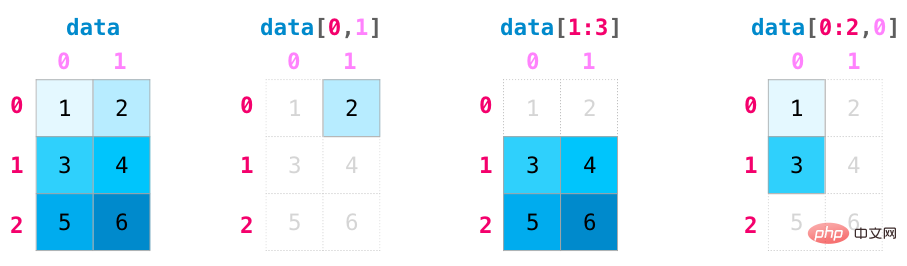
벡터를 집계하는 것처럼 행렬도 집계할 수 있습니다. 모두 행렬 값에 포함되어 있으며 다음과 같은 작업도 가능합니다. 축 매개변수를 사용하여 지정합니다. 행과 열의 집계:

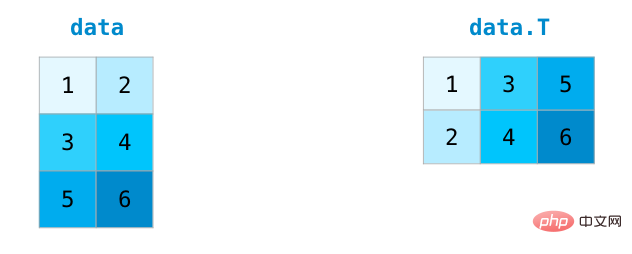
행렬의 전치 및 재구성
행렬을 처리할 때 행렬을 전치해야 하는 경우가 종종 있습니다. 두 행렬의 내적을 계산하는 것입니다. NumPy 배열의 속성 T를 사용하여 행렬의 전치를 얻을 수 있습니다.
더 복잡한 사용 사례에서는 행렬의 차원을 변경해야 할 수도 있습니다. 이는 기계 학습 응용 프로그램에서 일반적입니다. 예를 들어 모델의 입력 행렬 모양이 데이터 세트와 다른 경우 NumPy의 reshape() 메서드를 사용할 수 있습니다. 행렬에 필요한 새 차원을 전달하기만 하면 됩니다. -1을 전달할 수도 있으며 NumPy는 행렬을 기반으로 올바른 크기를 추론할 수 있습니다.
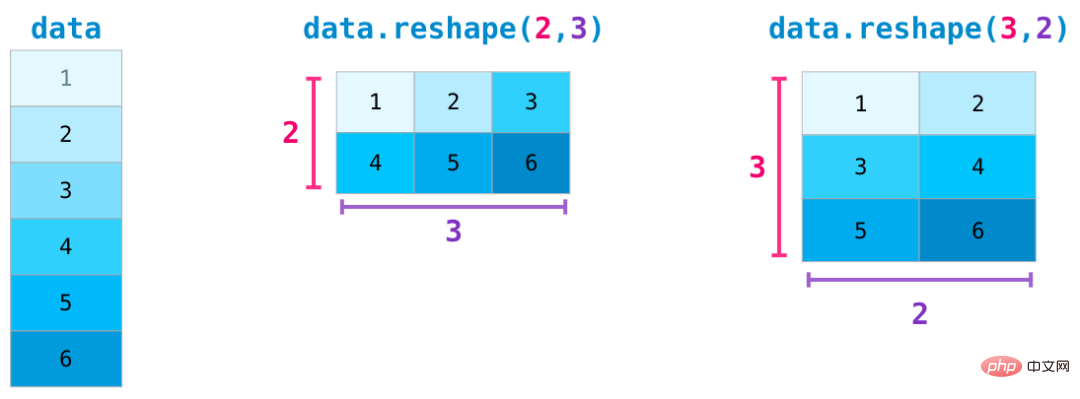
위의 모든 함수는 다차원 데이터에 적용 가능하며, 그 중심 데이터 구조를 ndarray(N차원 배열)이라고 합니다.

아래와 같이 차원을 변경하는 것은 단지 NumPy 함수의 매개변수에 쉼표를 추가하는 문제일 뿐입니다.
NumPy의 주요 사용 사례는 행렬과 벡터로 작동하는 수학 공식을 구현하는 것입니다. 이는 NumPy가 Python에서 일반적으로 사용되는 이유이기도 합니다. 예를 들어 평균 제곱 오류는 회귀 문제를 처리하는 지도 기계 학습 모델의 핵심입니다.
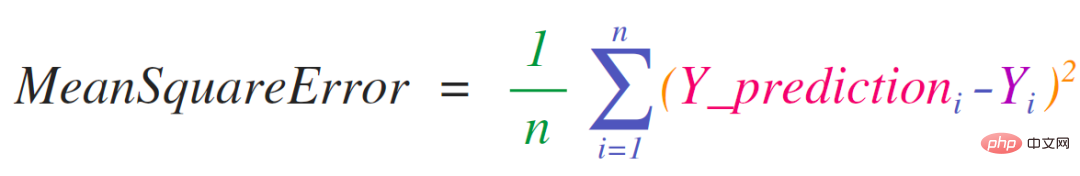
평균 제곱 오류는 NumPy에서 쉽게 구현할 수 있습니다.

이것의 장점은 numpy가 예측과 레이블에 포함된 특정 값을 고려할 필요가 없다는 것입니다. DigestBacteria는 예제를 통해 위 코드 줄의 네 가지 작업을 단계별로 진행합니다.

예측 벡터와 레이블 벡터 모두 세 가지 값을 포함합니다. 이는 n의 값이 3이라는 것을 의미합니다. 뺄셈을 수행하면 다음과 같은 값이 생성됩니다.

그런 다음 벡터에 있는 각 값의 제곱을 계산할 수 있습니다.

이제 다음 값을 합산합니다.

최종적으로 이 예측에 대한 오류 값과 모델 품질 점수를 얻습니다.
매일 스프레드시트, 이미지, 오디오 등과 같이 접하게 되는 데이터 유형을 어떻게 표현합니까? Numpy는 이 문제를 해결할 수 있습니다.
테이블 및 스프레드시트
스프레드시트 또는 데이터시트는 모두 2차원 행렬입니다. 스프레드시트의 각 워크시트는 자체 변수가 될 수 있습니다. Python의 유사한 구조는 NumPy를 사용하여 실제로 구축된 pandas 데이터 프레임입니다.
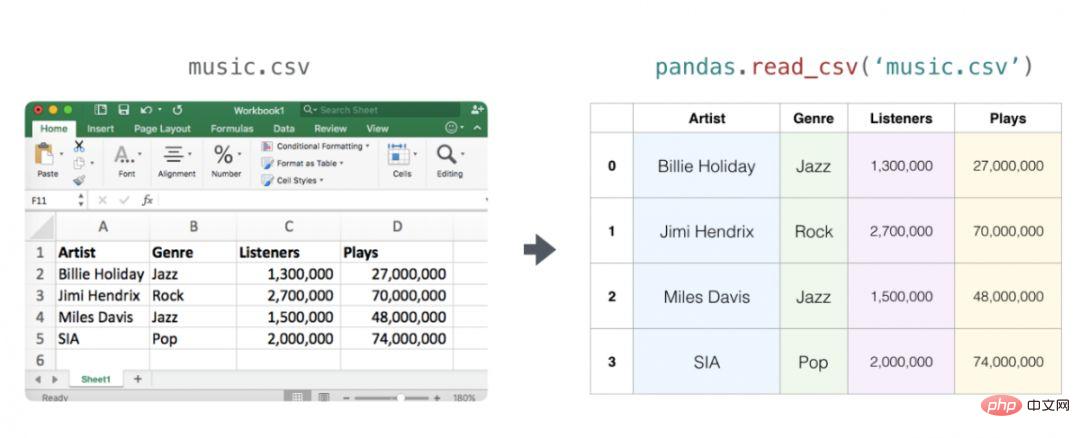
오디오 및 시계열
오디오 파일은 샘플의 1차원 배열입니다. 각 샘플은 오디오 신호의 작은 세그먼트를 나타내는 숫자입니다. CD 품질 오디오는 초당 44,100개의 샘플을 가질 수 있으며, 각 샘플은 -65535에서 65536 사이의 정수입니다. 즉, 10초짜리 CD 품질 WAVE 파일이 있으면 이를 길이 10 * 44,100 = 441,000개 샘플의 NumPy 배열에 로드할 수 있습니다. 오디오의 첫 번째 순간을 추출하고 싶으십니까? 파일을 audio라고 부르는 NumPy 배열에 로드하고 audio[:44100]를 가로채기만 하면 됩니다.
다음은 오디오 파일입니다.
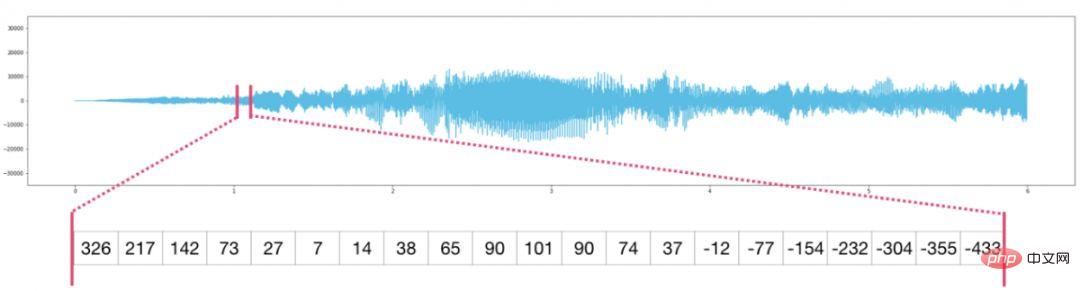
시계열 데이터(예: 시간 경과에 따른 주가 시퀀스)도 마찬가지입니다.
Image
이미지는 크기(높이 × 너비)의 픽셀 매트릭스입니다. 이미지가 흑백인 경우(회색조 이미지라고도 함) 각 픽셀은 단일 숫자(보통 0(검은색)에서 255(흰색) 사이)로 표시될 수 있습니다. 이미지를 처리하는 경우 NumPy의 image[:10,:10]를 사용하여 이미지의 왼쪽 상단 모서리에 있는 10 x 10 픽셀 영역을 자를 수 있습니다.
다음은 이미지 파일의 일부입니다.
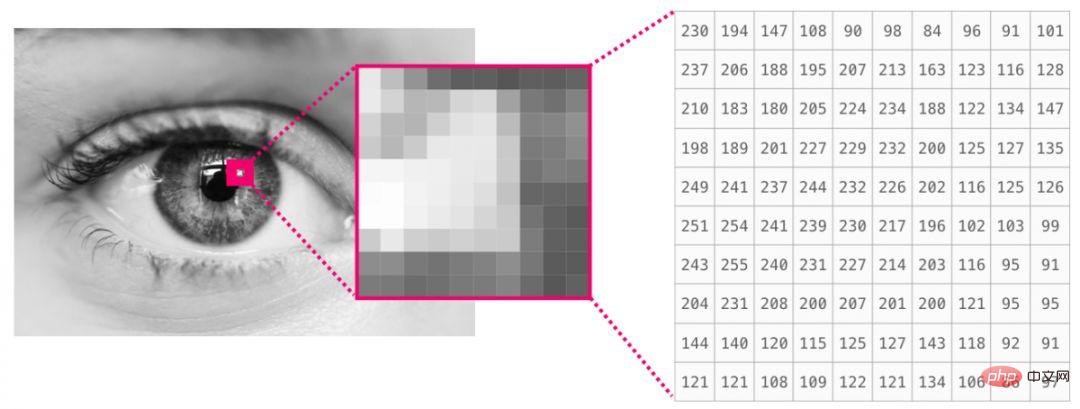
이미지가 컬러인 경우 각 픽셀은 빨간색, 녹색, 파란색의 세 가지 숫자로 표시됩니다. 이 경우에는 세 번째 차원이 필요합니다(각 셀은 하나의 숫자만 포함할 수 있으므로). 따라서 컬러 이미지는 크기(높이 x 너비 x 3)를 갖는 ndarray로 표시됩니다.

Language
텍스트를 다루면 상황이 달라집니다. 텍스트를 숫자로 표현하려면 어휘(모델이 알고 있는 모든 고유 단어 목록) 구축과 임베딩의 두 단계가 필요합니다. 이 (번역된) 고대 인용문을 숫자로 표현하는 단계를 살펴보겠습니다. "나보다 먼저 온 음유시인이 어떤 주제도 노래하지 않은 채로 두었나요?" 이 전장 시인의 시를 수치로 표현합니다. 모델이 작은 데이터세트를 처리하도록 하고 이 데이터세트를 사용하여 어휘(71,290단어)를 구축할 수 있습니다. 그런 다음 문장을 일련의 "단어" 토큰(공통 규칙에 따른 단어 또는 단어 부분)으로 나눌 수 있습니다. 그런 다음 각 단어를 어휘: 이 ID는 여전히 모델에 귀중한 정보를 제공하지 않습니다. 따라서 일련의 단어를 모델에 공급하기 전에 토큰/단어를 임베딩으로 대체해야 합니다(이 경우 50차원 word2vec 임베딩 사용). 이 NumPy 배열의 크기는 [embedding_dimension x 시퀀스_길이]임을 알 수 있습니다. 실제로 이러한 값은 반드시 이렇게 표시되지는 않지만 시각적 일관성을 위해 이렇게 표시합니다. 성능상의 이유로 딥 러닝 모델은 배치 크기의 첫 번째 차원을 유지하는 경향이 있습니다(여러 예제를 병렬로 훈련하면 모델이 더 빠르게 훈련될 수 있기 때문입니다). 분명히 이것은 reshape()를 사용하기에 좋은 곳입니다. 예를 들어 BERT와 같은 모델은 입력 행렬이 [batch_size, 시퀀스_길이, embedding_size] 형태일 것으로 예상합니다. 모델이 다양하고 유용한 작업을 처리하고 수행할 수 있는 숫자 모음입니다. 모델 학습(또는 예측)을 위한 추가 예제로 채울 수 있는 많은 행을 비워 두었습니다. 


위 내용은 팁 | 이것은 아마도 내가 본 최고의 NumPy 그래픽 튜토리얼일 것입니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!