
팁 | Python은 PDF 송장을 자동으로 일괄 추출하고 구성합니다.

- Python当打之年앞으로
- 2023-08-10 15:58:202251검색
이 기사에서는 금융계 여성이 제기한 실제 수요이기도 한 PDF 기반 Python 사무 자동화 케이스 솔루션을 공유합니다.
요구 사항 설명
특정 폴더 아래에 여러 개의 PDF 유형 송장이 있습니다
각 송장 PDF는 순수한 이미지 유형이며, 내부의 텍스트 정보는 수동으로 복사할 수 없습니다(실제로 대부분의 송장은 복사할 수 있습니다). 본문의 일부이지만 그림으로 설명하겠습니다) 대략 아래 그림과 같습니다. 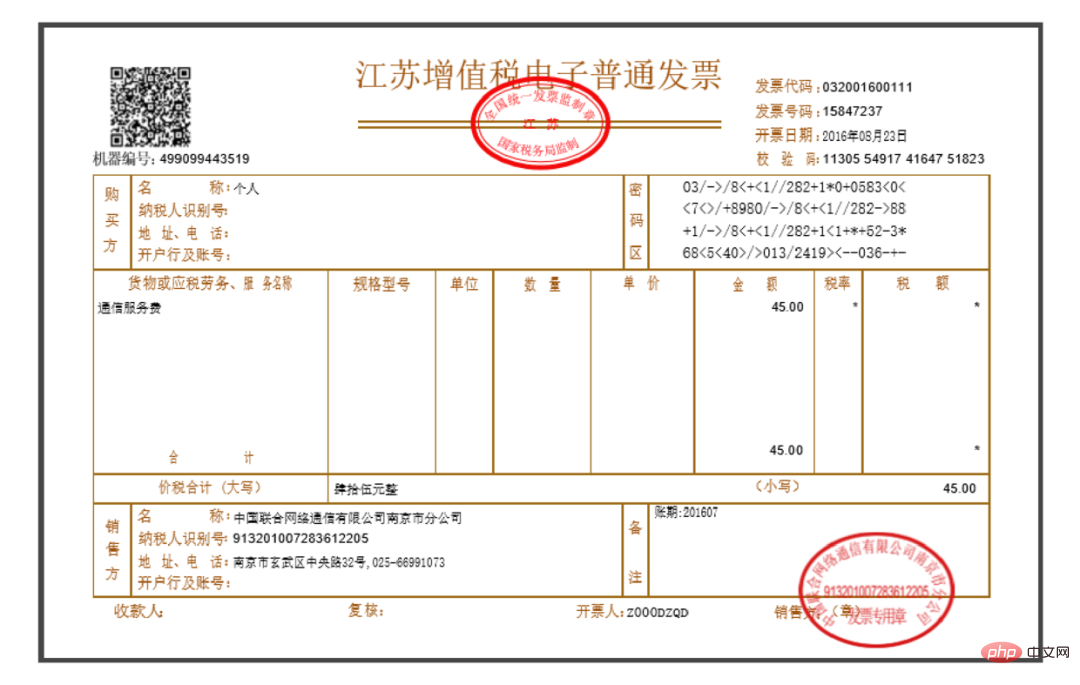
충족해야 할 요구 사항은 다음과 같습니다. 총액, 납세자 식별 번호 및 발급자 를 얻습니다. , 즉, 다음 세 개의 상자 위치: 
마지막으로 일괄 작업과 결합하여 위의 정보를 얻은 후 Excel에 저장합니다! 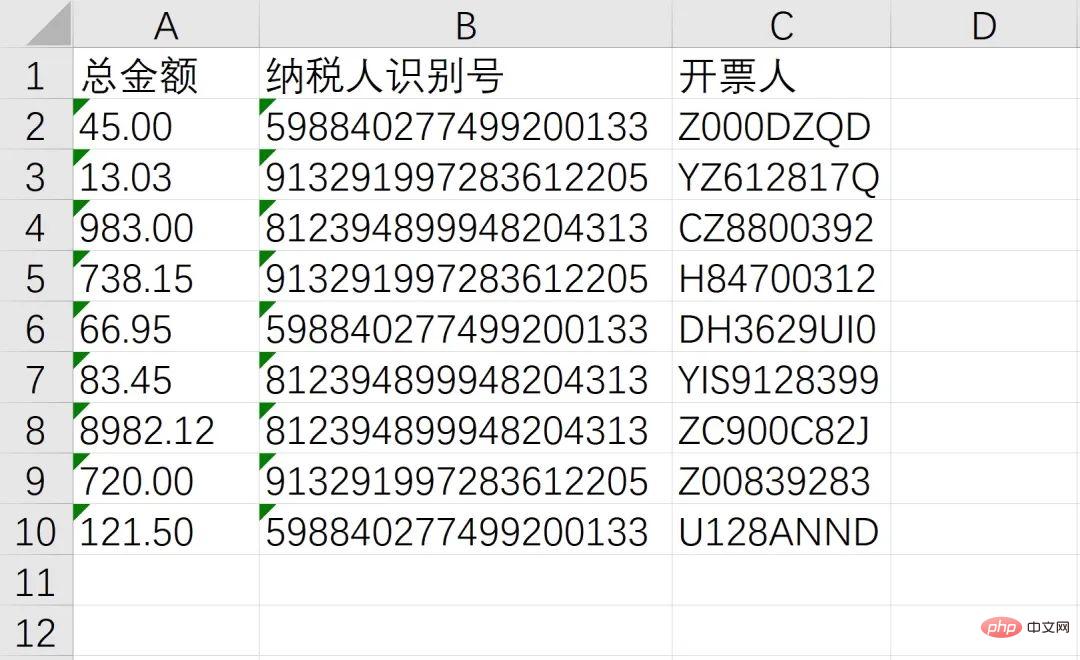
아이디어 및 코드 구현
요구 사항은 본질적으로 이미지 인식 문제입니다. PDF의 콘텐츠는 이미지 유형이고 기존 방법으로는 텍스트를 직접 추출할 수 없기 때문입니다. 해결책은 광학 문자 인식(OCR)을 사용하여 사진 속 텍스트를 인식하는 것입니다. 그러나 동시에 PDF는 결국 그림이 아니라는 점에 유의해야 합니다. OCR을 완료하려면 OCR 자체 외에도 다운로드해야 합니다. Ghostscript 和 ImageMagick 用来完成类型转换。已 Windows 시스템을 예로 들면 다음을 설치해야 합니다. 컴퓨터에 있는 다음 세 가지 소프트웨어:
Ghostscript32 位
Ghostscript 32 位ImageMagick 32 位tesseract-OCR 32 位三个软件的下载安装没有特殊的地方(tesseract 配置稍复杂但网络有上诸多教程,这里不再赘述),读者可自行搜索下载及配置,下面讲解代码。首先导入需要的模块:
from wand.image import Image from PIL import Image as PI import pyocr import pyocr.builders import io import re import os import shutil
具体的模块用途可以参考下面具体代码。其中 wand 和 pyocr 由于是非标准库需要自行额外安装。打开命令行输入:
pip install wand pip install pyocr
本需求还涉及对接 Excel,可考虑利用 openpyxl 库的 Workbook 用以创建新的 Excel 文件:
from openpyxl import Workbook
需求中的 发票.pdf 放在桌面上。可通过下面基于 os 模块的代码获取桌面路径:
# 获取桌面路径包装成一个函数
def GetDesktopPath():
return os.path.join(os.path.expanduser("~"), 'Desktop')
path = GetDesktopPath() + r'\发票.pdf'获取配置好的 tesseract
ImageMagick 32位🎜🎜tesseract- OCR 32位3个软件的下载安装没有特殊的地方(tesseract 配置稍复杂但网络有上诸多教程,这里不再赘述),读者可自行搜索下载及配置,下면讲解代码。首先导入需要的模块:🎜
tool = pyocr.get_available_tools()[0]
具体的模块用途可以参考하면具体代码。其中 지팡이 와 pyocr 由于是不标准库需要自行额外安装。打开命令行输入:🎜
image_pdf = Image(filename=path, resolution=300) image_jpeg = image_pdf.convert('jpeg')
本需求还涉及对接 Excel,可考虑利用 openpyxl 库의 통합 문서 用以创建新的 Excel 文件:🎜
image_lst = []
for img in image_jpeg.sequence:
img_page = Image(image=img)
image_lst.append(img_page.make_blob('jpeg'))需求中的 发票.pdf 放在桌面上。可通过下면基于 os 模块的代码获取桌面路径:🎜new_img = PI.open(io.BytesIO(image_lst[0])) new_img.show()
获取配置好的 tesseract 便于后면调사용:🎜
tool = pyocr.get_available_tools()[0]
通过 wand 模块将 PDF 文件转化为分辨率为 300 的 jpeg 图片形式:
image_pdf = Image(filename=path, resolution=300) image_jpeg = image_pdf.convert('jpeg')
将图片解析为二进制矩阵:
image_lst = []
for img in image_jpeg.sequence:
img_page = Image(image=img)
image_lst.append(img_page.make_blob('jpeg'))用 io 模块的 BytesIO 方法读取二进制内容为图片形式:
new_img = PI.open(io.BytesIO(image_lst[0])) new_img.show()
接下来分别截取需要提取部位字符串的图片了,尽量让图片中只有需要识别的部分,获取识别出来容易简单处理获得需要的内容。
首先以总金额为例,截取图片用 image.crop((left, top, right, bottom)) 四个参数需要反复调试才能确定。经确定四个参数分别是 1600 760 1830 900,尝试截取和预览图片:
### 解析1Z开头码 left = 350 top = 600 right = 1300 bottom = 730 image_obj1 = new_img.crop((left, top, right, bottom)) image_obj1.show()
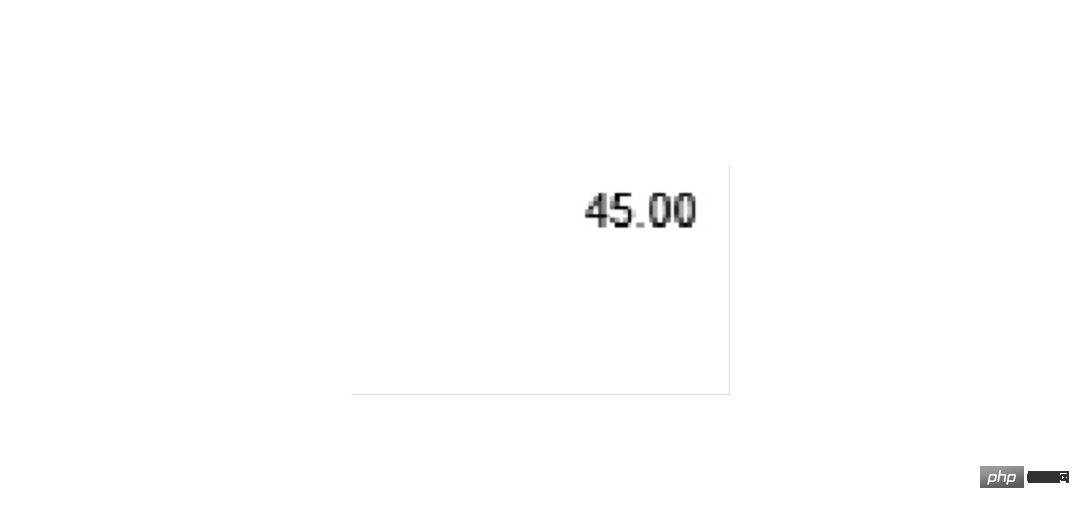
截取成功后可以交给 OCR 了,代码为 tool.image_to_string()
txt1= tool.image_to_string(image_obj1) print(txt1)

同样,通过方位的调试就可以准确切割到需要的部分进行识别:
left = 560 top = 1260 right = 900 bottom = 1320 image_obj2 = new_img.crop((left, top, right, bottom)) # image_obj2.show() txt2 = tool.image_to_string(image_obj2) # print(txt2)
最后是开票人的识别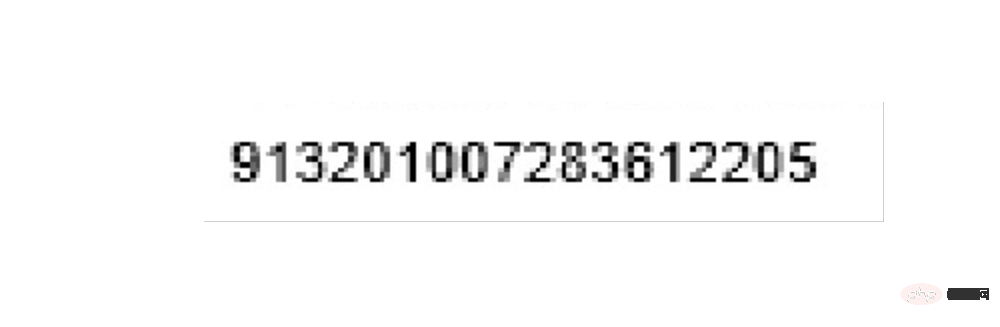
left = 1420 top = 1420 right = 1700 bottom = 1500 image_obj3 = new_img.crop((left, top, right, bottom)) # image_obj3.show() txt3 = tool.image_to_string(image_obj3) # print(txt3)
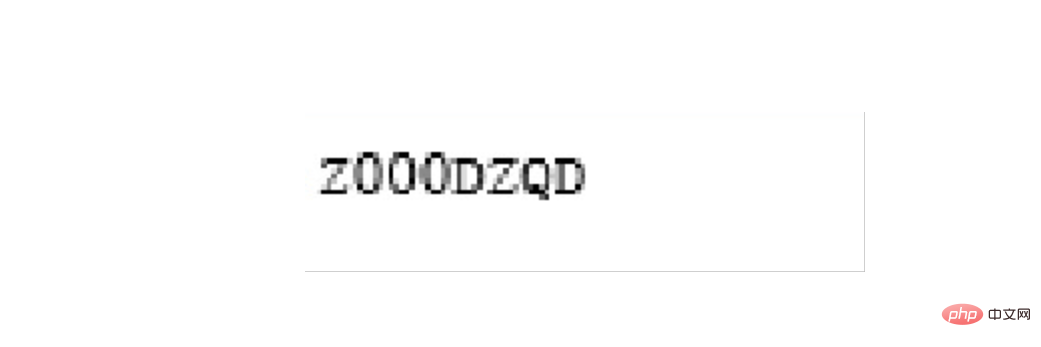
需要确认识别的内容是否正确,如果识别正确率欠佳可以考虑通过图片处理技术消除噪声,也可以去官网下载更高精度的训练包提高识别的正确性
至此,我们成功的识别了总金额、纳税人识别号、开票人三个消息,接下来就通过非常熟悉的 openpyxl 写入Excel,并使用 os 模块实现批量操作即可
workbook = Workbook() sheet = workbook.active header = ['总金额', '纳税人识别号', '开票人'] sheet.append(header) sheet.append([txt1, txt2, txt3]) workbook.save(GetDesktopPath() + r'\汇总.xlsx')
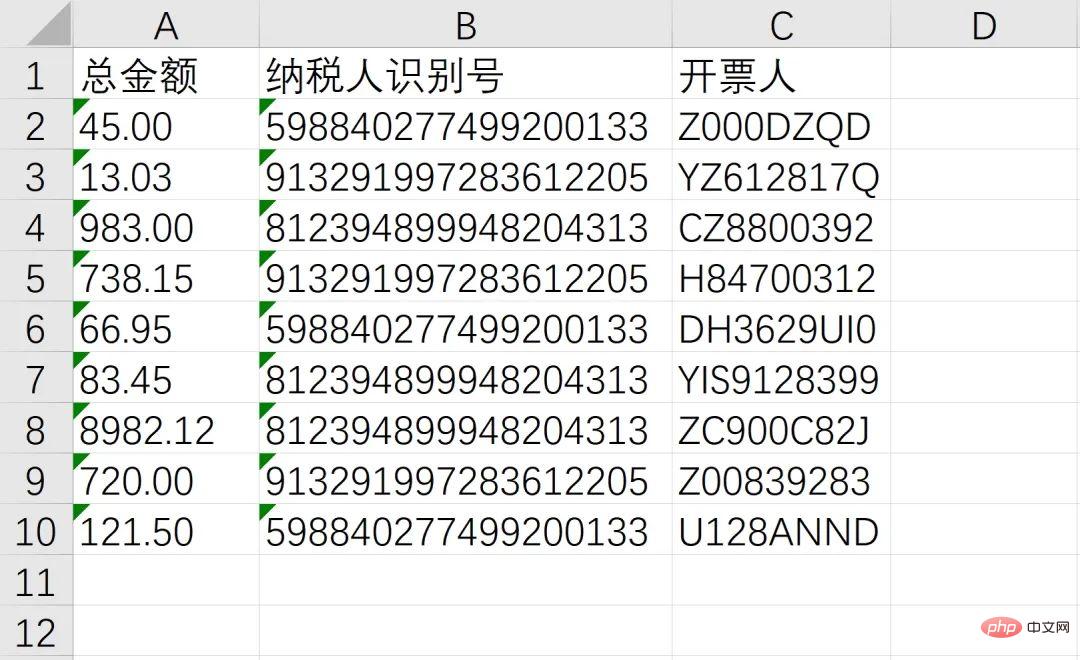
综上,整个需求就成功实现,从效果来看还是非常不错的!完整源码可由文中代码组合而成(已全部分享在文中),感兴趣的读者可以自己尝试!
最后想说的是,其实本文的案例可以衍生出很多实用的办公自动化脚本,例如
批量计算发票金额并重命名文件夹 根据发票类型批量分类 根据发票批量制作报销单 ··· ···
위 내용은 팁 | Python은 PDF 송장을 자동으로 일괄 추출하고 구성합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!