
크롤러 | HD 배경화면 일괄 다운로드(소스 코드 + 도구 포함)

- Python当打之年앞으로
- 2023-08-10 15:46:011587검색
Unsplash는 무료 고품질 사진 웹사이트입니다 , 모두 실제 사진 사진이며, 사진 해상도도 매우 커서 디자이너 친구를 위한 것입니다. 누구에게나 매우 좋은 소재이며 일부 일러스트레이션 카피라이팅 친구들에게도 매우 실용적입니다. 배경화면으로도 좋습니다. 해당 기능 코드는 exe 도구로 패키징되어 있습니다. 코드 + 도구 획득 방법은 기사 마지막에 첨부되어 있습니다.
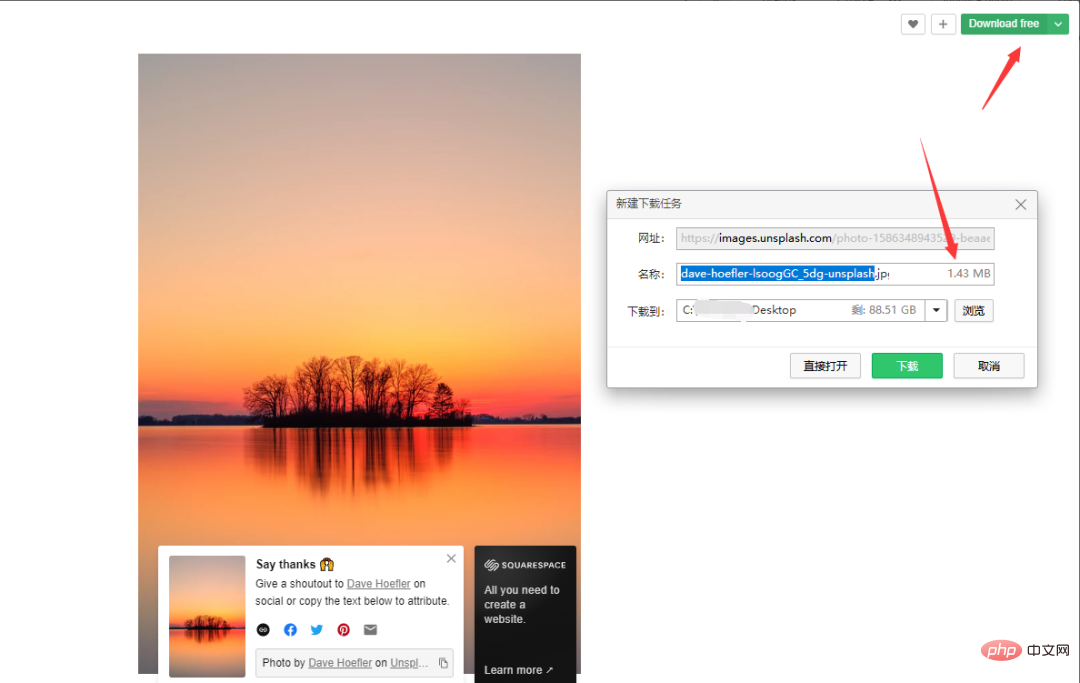
먼저 수동 다운로드 과정을 살펴보겠습니다. 이미지를 마우스 오른쪽 버튼으로 클릭하여 다른 이름으로 저장하는 대신, 저장 방법을 마우스 오른쪽 버튼으로 클릭하여 얻은 이미지가 일정 비율로 압축되어 선명도가 향상됩니다. 많이 줄었습니다. 자연을 예로 들어 무료 다운로드를 클릭하고 다운로드 경로를 선택하세요. 이미지 크기는 1.43M입니다.
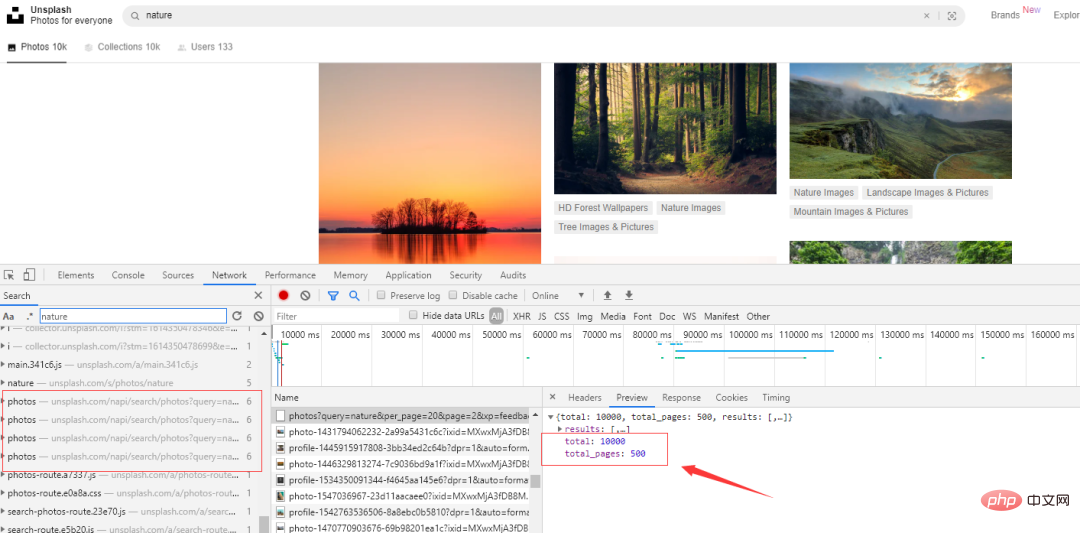
몇번의 작업 후에 아래로 내리면 웹페이지에서 다음 요청을 발행하는 것을 발견했습니다. 그 중 하나를 클릭하면 사진을 볼 수 있습니다. 총 수: 10000, 총 페이지 수: 500.
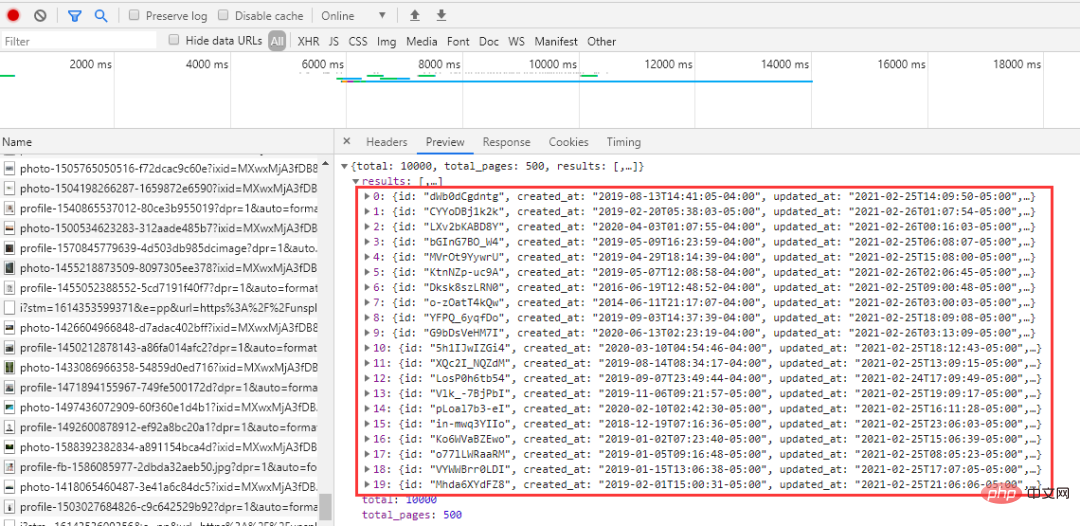
몇 개의 URL을 꺼내서 살펴보겠습니다.

위 링크는 페이지 매개변수만 다르고 순서대로 증가하고 있어 비교적 친숙합니다. . 요청하면 순서대로 이동됩니다.
페이지 번호 문제가 해결되었습니다. 다음으로 각 사진의 링크를 분석합니다. :
import time import random import json import requests from fake_useragent import UserAgent
시간: 타이밍 random: 난수 생성
json: json 형식 데이터 처리
requests: 웹 페이지 요청
fake_useragent:代理
ua = UserAgent(verify_ssl=False)
headers = {'User-Agent': ua.random}def getpicurls(i,headers):
picurls = []
url = 'https://unsplash.com/napi/search/photos?query=nature&per_page=20&page={}&xp=feedback-loop-v2%3Aexperiment'.format(i)
r = requests.get(url, headers=headers, timeout=5)
time.sleep(random.uniform(3.1, 4.5))
r.raise_for_status()
r.encoding = r.apparent_encoding
allinfo = json.loads(r.text)
results = allinfo['results']
for result in results:
href = result['urls']['full']
picurls.append(href)
return picurlsdef getpic(count,url):
r = requests.get(url, headers=headers, timeout=5)
with open('pictures/{}.jpg'.format(count), 'wb') as f:
f.write(r.content)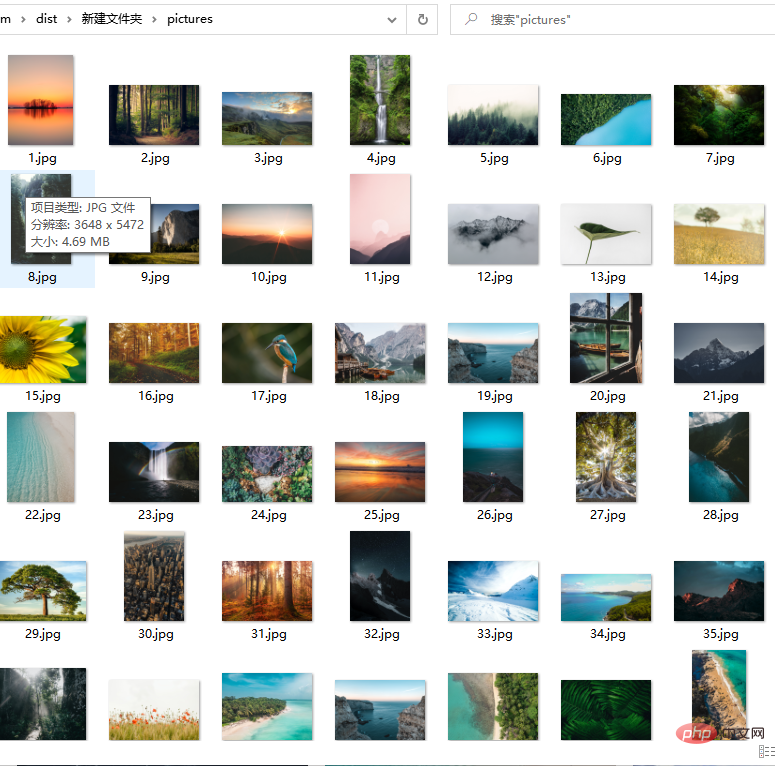
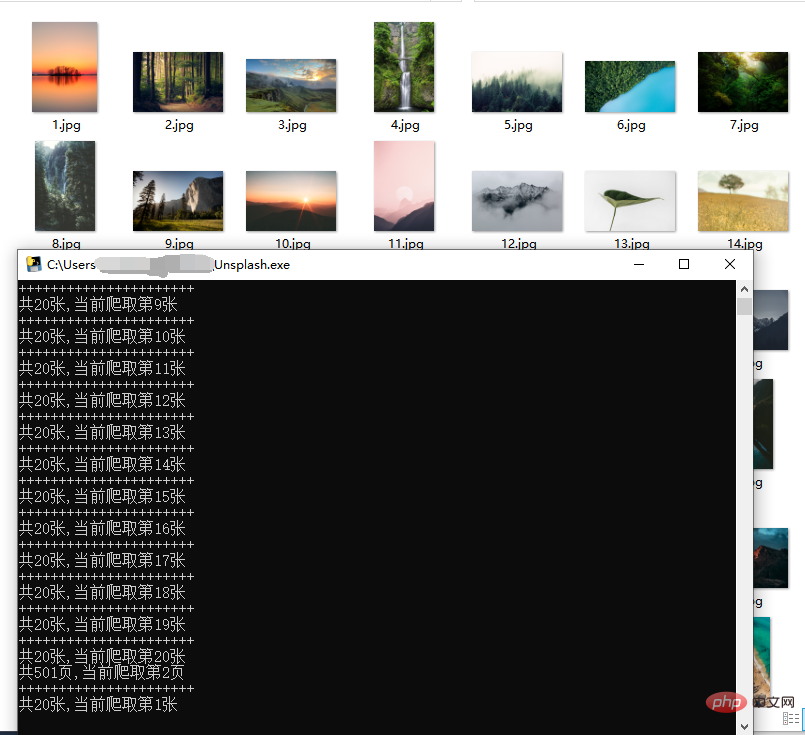
네트워크 순서에 영향을 주지 않도록 자주 크롤링하지 마세요!
사진은 인터넷에서 가져온 고화질 사진입니다. 크롤링 속도는 네트워크와 관련이 있으며 일반적으로 너무 빠르지는 않습니다.
프록시 풀을 구축하면 더 빠르게 크롤링할 수 있습니다.
위 내용은 크롤러 | HD 배경화면 일괄 다운로드(소스 코드 + 도구 포함)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!