
크롤러|파이썬은 B 스테이션의 소녀들의 사진을 크롤링하여 학습 동기를 부여합니다!

- Python当打之年앞으로
- 2023-08-09 17:11:321141검색
다이렉트 오픈 B역(빌리빌리)에서 '여동생'을 검색하세요. ':
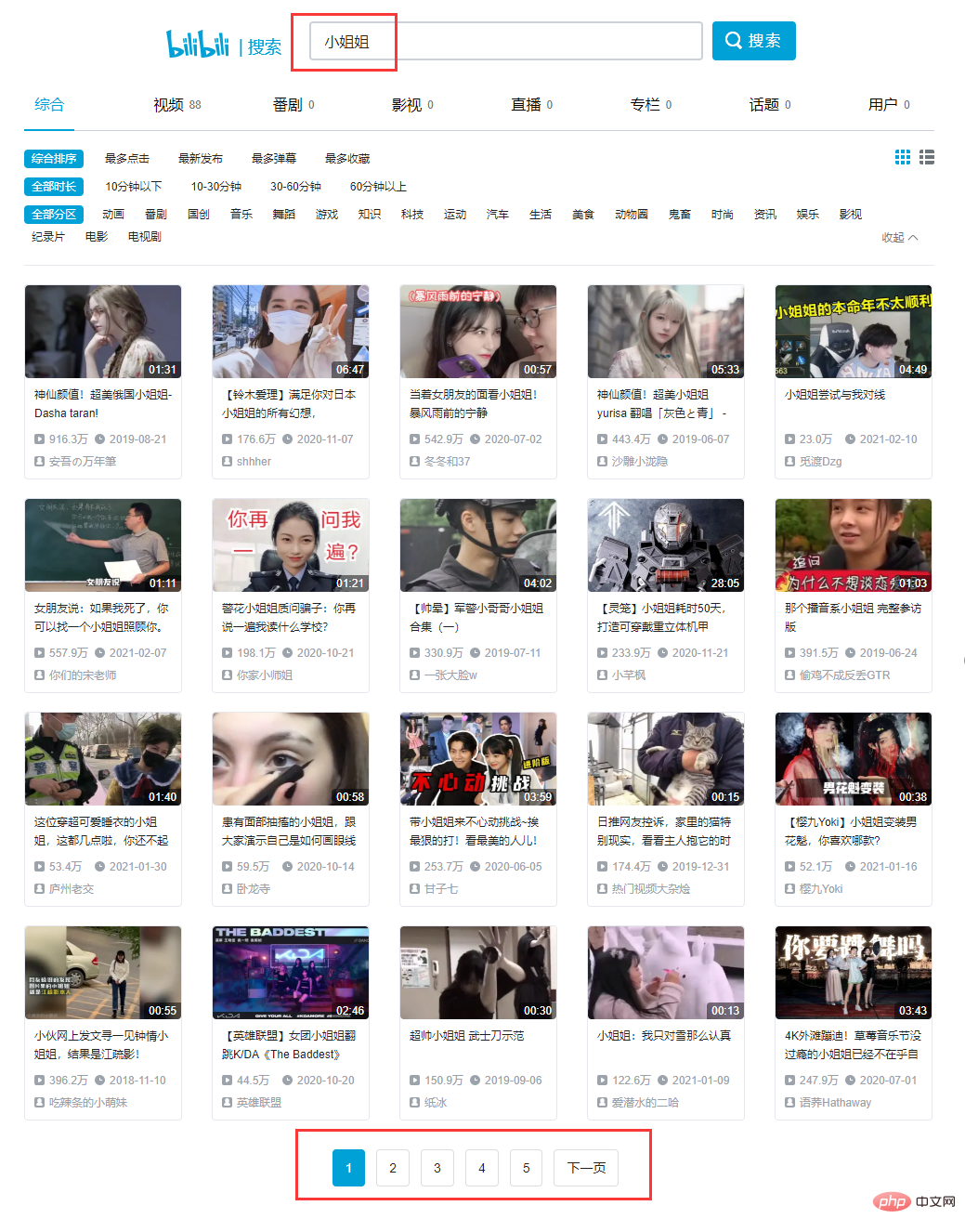
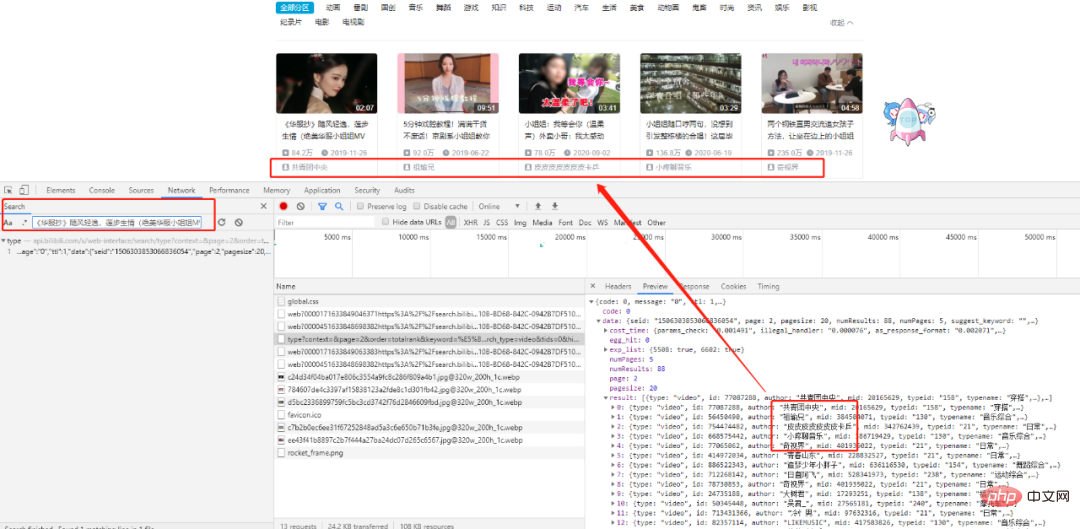
다음과 같이 헤더를 확인하세요.
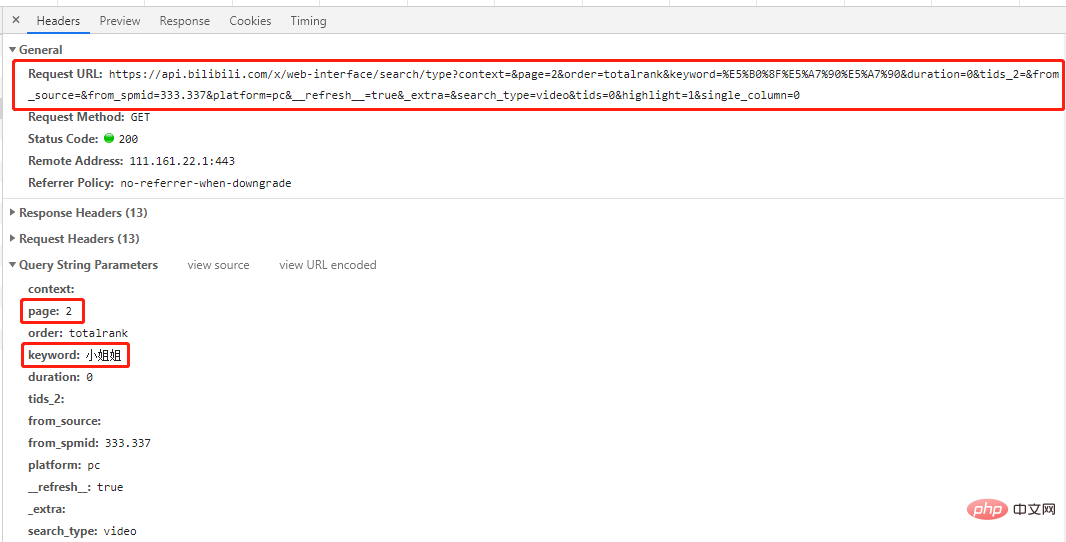 get 요청
get 요청
이며 요청의 항목 수는
그리고 keywordtwo 항목은 각각 요청한 페이지 번호와 키워드에 해당합니다. 패턴을 찾으려면 몇 페이지를 더 확인하세요. # 第一页
'https://api.bilibili.com/x/web-interface/search/all/v2?context=&page=1&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&tids=0&highlight=1&single_column=0'
# 第二页
'https://api.bilibili.com/x/web-interface/search/type?context=&page=2&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0'
# 第三页
'https://api.bilibili.com/x/web-interface/search/type?context=&page=3&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0'
첫 번째 페이지를 제외하고 다른 페이지의 URL에서는 페이지 매개변수만 다른 것을 볼 수 있습니다 그럼 한번 시도해 보겠습니다페이지 1도 다른 페이지의 URL을 사용하여 요청한 결과입니다. 원하는 결과를 얻을 수 있습니다(직접 시도해 보세요).
결론: 모든 페이지 URL에 대해 페이지 매개변수만 다르고 나머지는 동일합니다.
# 导包 import re import time import json import random import requests from fake_useragent import UserAgent
2.2 获取页面信息
# 获取页面信息
def get_datas(url,headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = chardet.detect(r.content)['encoding']
datas = json.loads(r.text)
return datas# 获取图片链接信息
def get_hrefs(datas):
titles,hrefs = [],[]
for data in datas['data']['result']:
# 标题
title = data['title']
# 时长
duration = data['duration']
# 播放量
video_review =data['video_review']
# 发布时间
date_rls = data['pubdate']
pubdate = time.strftime('%Y-%m-%d %H:%M', time.localtime(date_rls))
# 作者
author = data['author']
# 图片链接
link_pic = data['pic']
href_pic = 'https:' + link_pic
titles.append(title)
hrefs.append(href_pic)
return titles, hrefs代码解析了视频标题,时长,播放量,发布时间,作者,图片链接等参数,这里我们只取标题和图片链接,其他参数可根据需要自行增,删。
# 保存图片
def download_jpg(titles, hrefs):
path = "D:/B站小姐姐/"
if not os.path.exists(path):
os.mkdir(path)
for i in range(len(hrefs)):
title_t = titles[i].replace('/','').replace(',','').replace('?','')
title_t = title_t.replace(' ','').replace('|','').replace('。','')
filename = '{}{}.jpg'.format(path,title_t)
with open(filename, 'wb') as f:
req = requests.get(url=hrefs[i], headers=headers)
f.write(req.content)
time.sleep(random.uniform(1.5,3.4))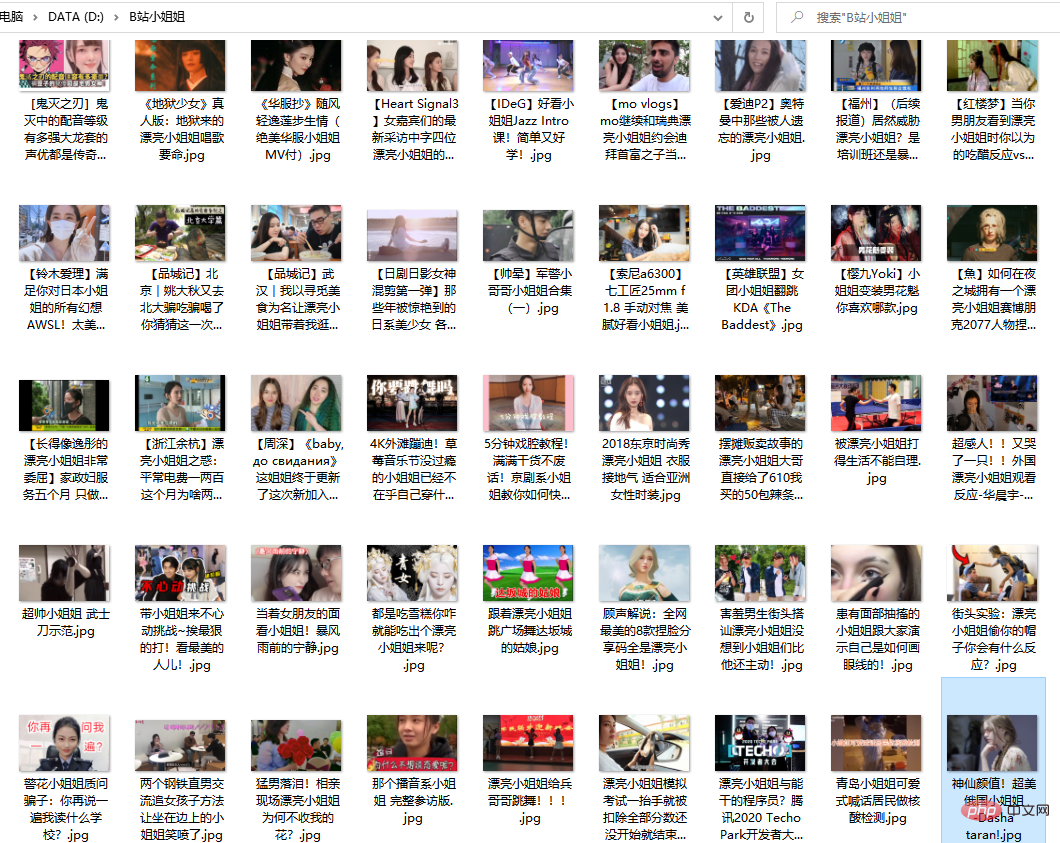
위 내용은 크롤러|파이썬은 B 스테이션의 소녀들의 사진을 크롤링하여 학습 동기를 부여합니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!